计算机操作系统笔记(4)
第四章存储器管理
4.1存储器的层次结构
存储器:
- 功能:保存数据
- 发展方向:高速、大容量和小体积
存储组织
存储组织是指在存储技术和CPU寻址技术许可的范围内组织合理的存储结构
一般的结构:“寄存器-内存-外存”结构 或 “寄存器-缓存-内存-外存”结构
层次结构

微机中的存储层次组织:
- 访问速度越慢,容量越大,价格越便宜
- 最佳状态应是各层次的存储器都处于均衡的繁忙状态
存储管理功能
- 存储分配和回收
- 地址变换
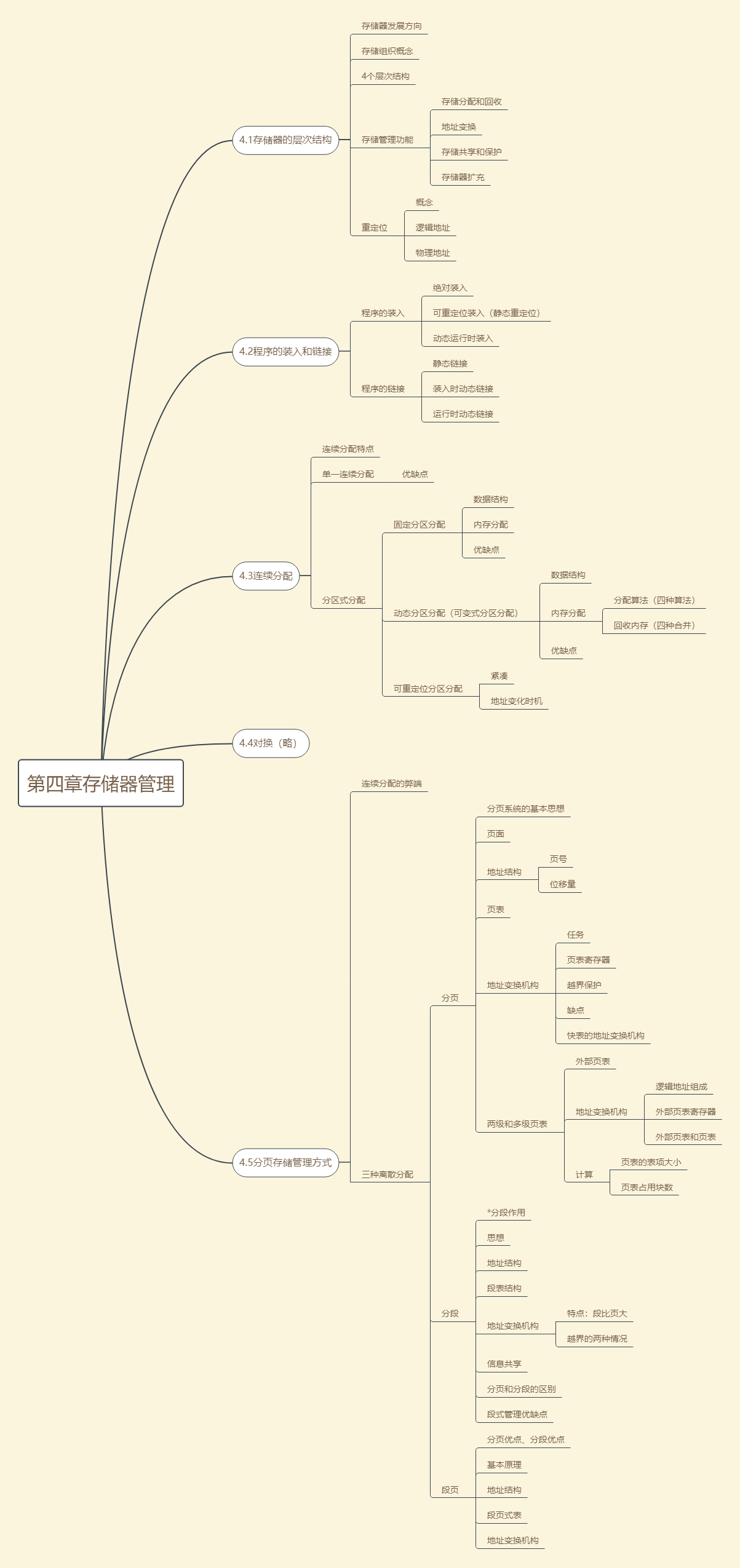
生成可执行文件的链接技术
程序加载时的重定位技术
进程运行时硬件和软件的地址变换技术 - 存储共享和保护
代码、数据共享
地址空间访问权限 - 存储器扩充
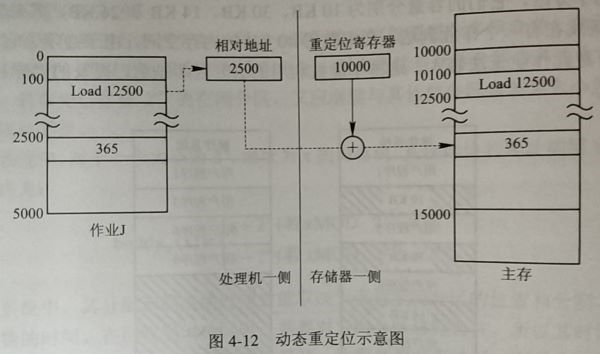
重定位
概念:实现逻辑地址(相对地址)到物理地址(绝对地址)的映射
逻辑地址:编译链接后形成的可装入程序中,地址都是从0开始,程序中的其它地址都是相对于起始地址计算的,这些地址称为逻辑地址
物理地址:主存内存储信息的一系列物理单元地址
4.2程序的装入和链接
程序的装入
三种装入:
- 绝对装入
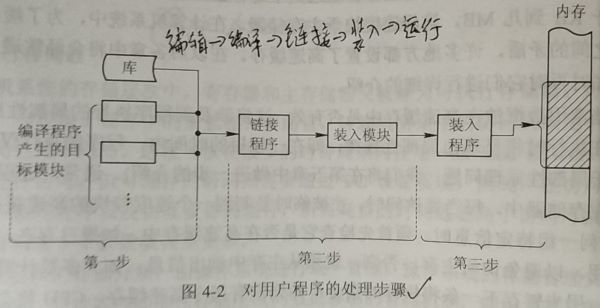
概念:编译后,装入前已产生了绝对地址(内存地址),装入时不再作地址重定位 - 可重定位装入(静态重定位)
概念:地址转换在装入时一次完成,由软件实现(重定位装入程序完成)
变化:数据地址和指令地址均发生了变化。
缺点:不允许程序在运行时移动在内存中的位置
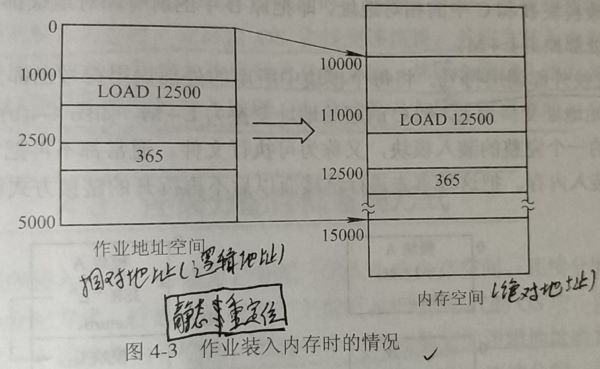
- 动态运行时装入
概念:动态重定位在执行时才完成相对—绝对地址的转换且有硬件的支持,能保证进程的可移动性
程序的链接
三种链接:
- 静态链接
要解决的问题:
对相对地址的修改
变换外部调用符号

- 装入时动态链接
优点:
便于修改和更新
便于实现对目标模块的共享 - 运行时动态链接
4.3连续分配
特点:进程在内存占用连续的存储空间
分为两大类:
- 单一连续分配(用于单用户,单任务的操作系统中)
- 分区式分配
往下又有三类:固定式、可变式、可重定位分区分配
单一连续分配
概念:内存划为系统区和用户区,在用户区中仅装有一道用户程序占用整个用户区空间
优点:易于管理
缺点:造成内存浪费
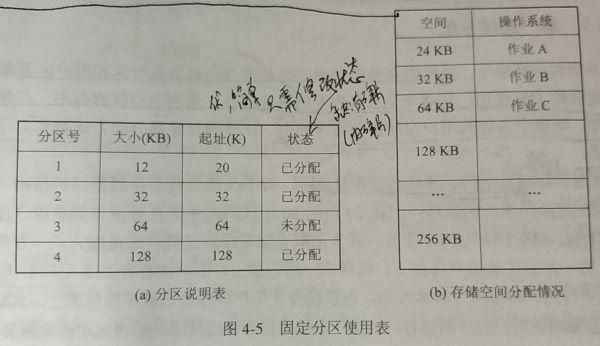
固定分区分配
概念:内存划分为n个分区,可同时装入n个作业/任务。(多道)
分区大小:相等、不等(利用率更高)
数据结构:分区说明表
内存分配:建立一张分区说明表,将分区按大小排序,并将其地址、分配标识作记录
优点:操作简单
缺点:有内碎片(分区内的碎片)
动态分区分配(可变式分区分配)
概念:根据进程的实际需要,动态地为之分配内存空间
数据结构:空闲分区表(链)
优点:分区大小和数量可变
缺点:有外碎片(分区外的碎片)
注:作业的起始地址和大小记录在PCB表当中
分配内存:
- *回收内存:
利用某种算法,从空闲分区表(链)中找到所需大小的分区 - 分配算法(基于顺序搜索):
首次适应算法(FF):找到第一个大小满足的分区来分配
循环首次适应算法(NF):从1中上次找到的空闲分区的下一个开始查找
最佳适应算法(BF):找到能满足要求的最小空闲分区来分配(分区按大小递增排序,分区释放时需插入到适当位置)
最坏适应算法(WF):找到最大的空闲分区来分配 - 回收内存
考虑空闲区位置的四种情况:
上邻(合并,改大小)
下邻(合并,改大小、首址)
上、下邻(合并,改大小)
不相邻(新建一新表项)
可重定位分区分配
紧凑:通过作业移动将原来分散的小分区拼接成一个大分区,作业的移动需重定位。是动态分配(因作业已经装入)

*动态重定位的实现:
变化:在每次访问内存单元前才进行地址变换,数据地址和指令地址不一定会都发生变化
*动态重定位分区分配算法:与动态分区分配算法相似,只不过增加了紧凑的功能
4.4对换
略
4.5~4.6属于离散分配
4.5分页存储管理方式
连续分配的弊端:产生碎片,使用紧凑方式解决又会增加系统开销
三种离散分配:分页、分段、段页
页面与页表
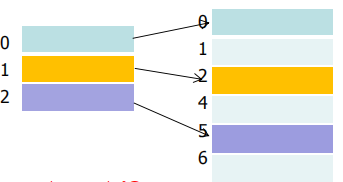
分页系统的基本思想:
- 内存分块,从0开始编号
- 作业分页,页与块等长,从0开始编号
- 内存以块为单位分配,块可不相邻
页面:
- 页面和物理块:逻辑空间和物理空间
- 页面大小:要适中(过小,页表可能很长,换入/出效率低;过大,使页内碎片增大)
地址结构:
- 分页地址的地址结构:

- 相关计算:
\(P=INT[\frac{A}{L}], d=[A]\) \(MOD\) \(L\)
(A:逻辑地址,L:页面大小,P:页号,d:页内地址,INT:取整函数,MOD:取余函数)
通常十进制的计算就用这种方法,若题目给定二进制/十六进制则用数串来拆分计算比较方便
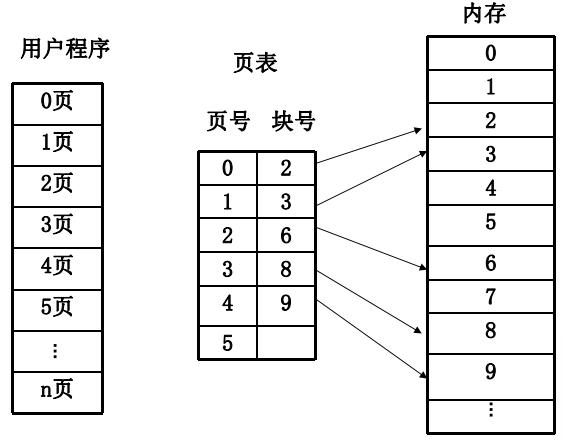
页表:实现从页号到物理块号的映射
地址变换机构
基本任务:完成逻辑地址到物理地址的映射
- 页号->块号(通过页表完成)
- 业内地址->块内地址
基本地址变换机构:
- 越界保护:逻辑地址相对于始址的长度超过页表长度
- 每个进程对应一张页表
页表的长度、始址信息存放在PCB中,执行时再装入页表寄存器(页表寄存器只有一个) - 缺点:页表驻留在内存中,需要两次访问主存(访问页表,访问绝对地址内容),速度降低近1/2
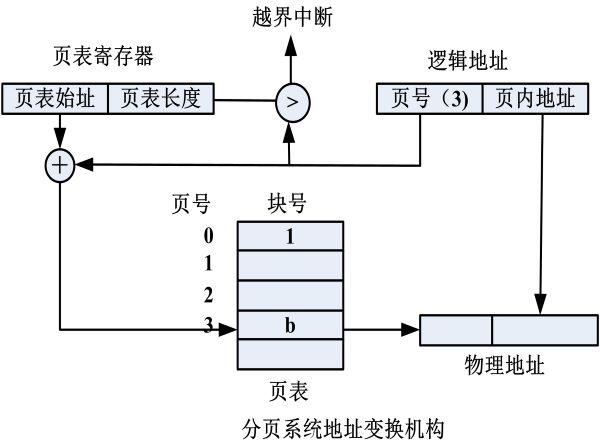
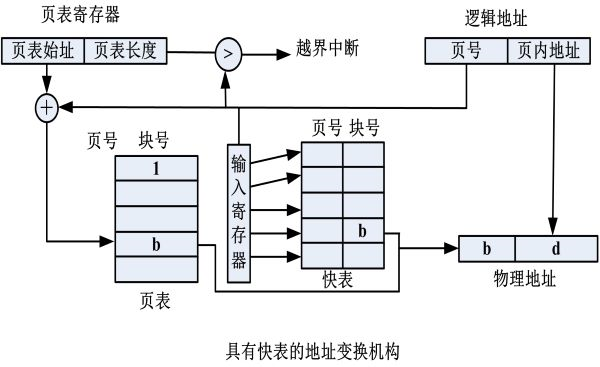
具有快表的地址变换机构
- 快表:在地址变换机构中增设的高速缓冲寄存器(存放当前访问的页表项)
- 过程:先在快表中找匹配的页号,找不到再访问内存的页表,并且将读出的物理块号送入快表
- 特点:速度快,但成本高,不能太多
两级和多级页表
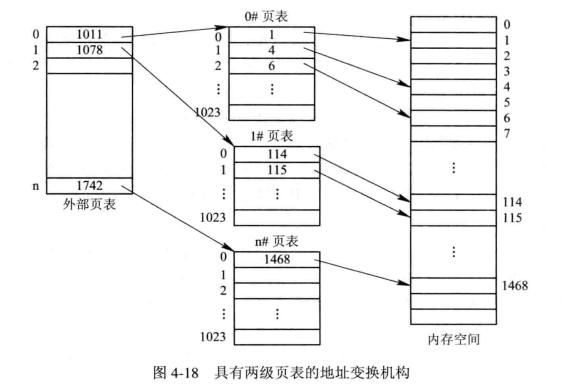
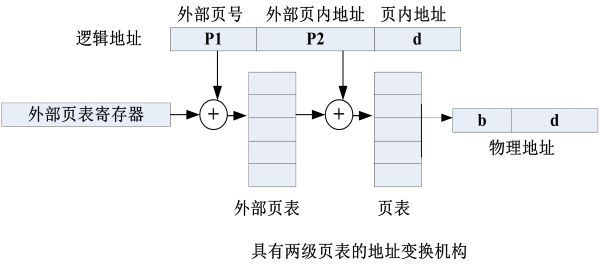
- 两级页表:页表可能很大(超过一页),将其离散放在不同块中,并建一“外部页表”来管理这些离散页表块(页表超过一块就有必要建立外部页表)
(页表的表项大小 = log2(物理空间块数)位 = log2(物理空间大小 / 块大小)位,(均上取整))
(页表占用块数 = 页表的表项大小 x 逻辑空间块数 / 块大小)
4.6分段存储管理方式
页是物理单位,段是逻辑单位
分段作用:
便于:编程、分段共享、分段保护、动态链接、动态增长
分段思想:
- 按程序的逻辑结构,将程序的地址空间划分为若干段,各段大小可不相同
(每个段具有逻辑意义和功能) - 内存以段位单位分配,这些段在内存中可以不相邻接
地址结构:
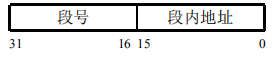
段表:
段表记录了该段在内存中的起始地址和段的长度
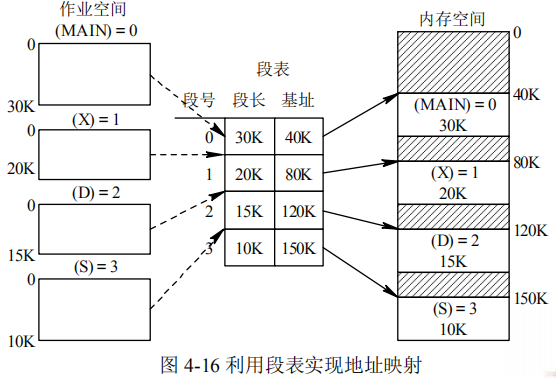
地址变换机构:
- 段比页大,因而段表项的数目比页表项的数目少,能减少存取数据的时间
- 越界的两种情况:段号超过段表长度、位移量超过段表中对应记录的段长
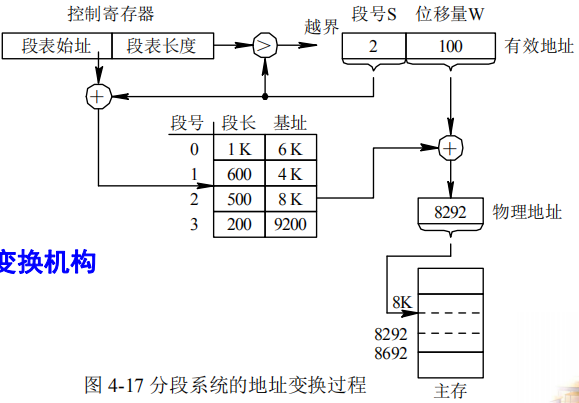
信息共享:
允许若干个进程共享一个或多个分段
(分段系统的共享比分页系统的更简单更方便)
分页和分段的主要区别:
- 页是信息的物理单位,段是逻辑单位
- 页长度固定,段长度不固定(用户指定)
- 分页的用户程序地址空间是一维的,分段的用户程序的地址空间是二维的(段名+段内地址)
段式管理的优缺点:
- 优点:
各段可独立编译
可采用不同的保护措施
便于共享某些段 - 缺点:
段长受限制
段长不定,造成空闲区上内存的浪费
段作为一个整体调入调出,操作时间长
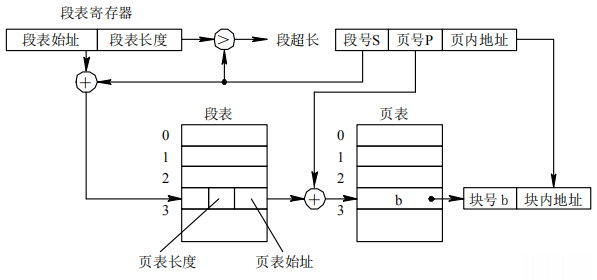
4.7段页式存储管理方式
分页优点:提高内存利用率
分段优点:方便用户,易于共享、保护,动态链接
段页式系统基本原理:
- 内存分为长度相等的若干块
- 作业分段,段内分页,页长等于块长
- 内存以块为单位分配
地址结构:

段页式表:
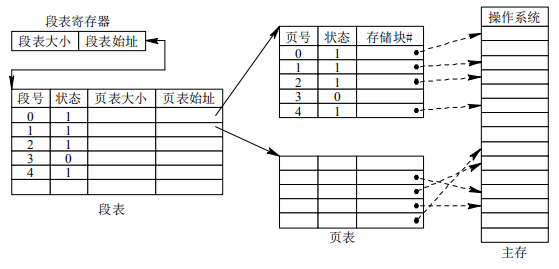
地址变换机构:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号