笔记大部分内容来自于书《概率论与数理统计》,侵删
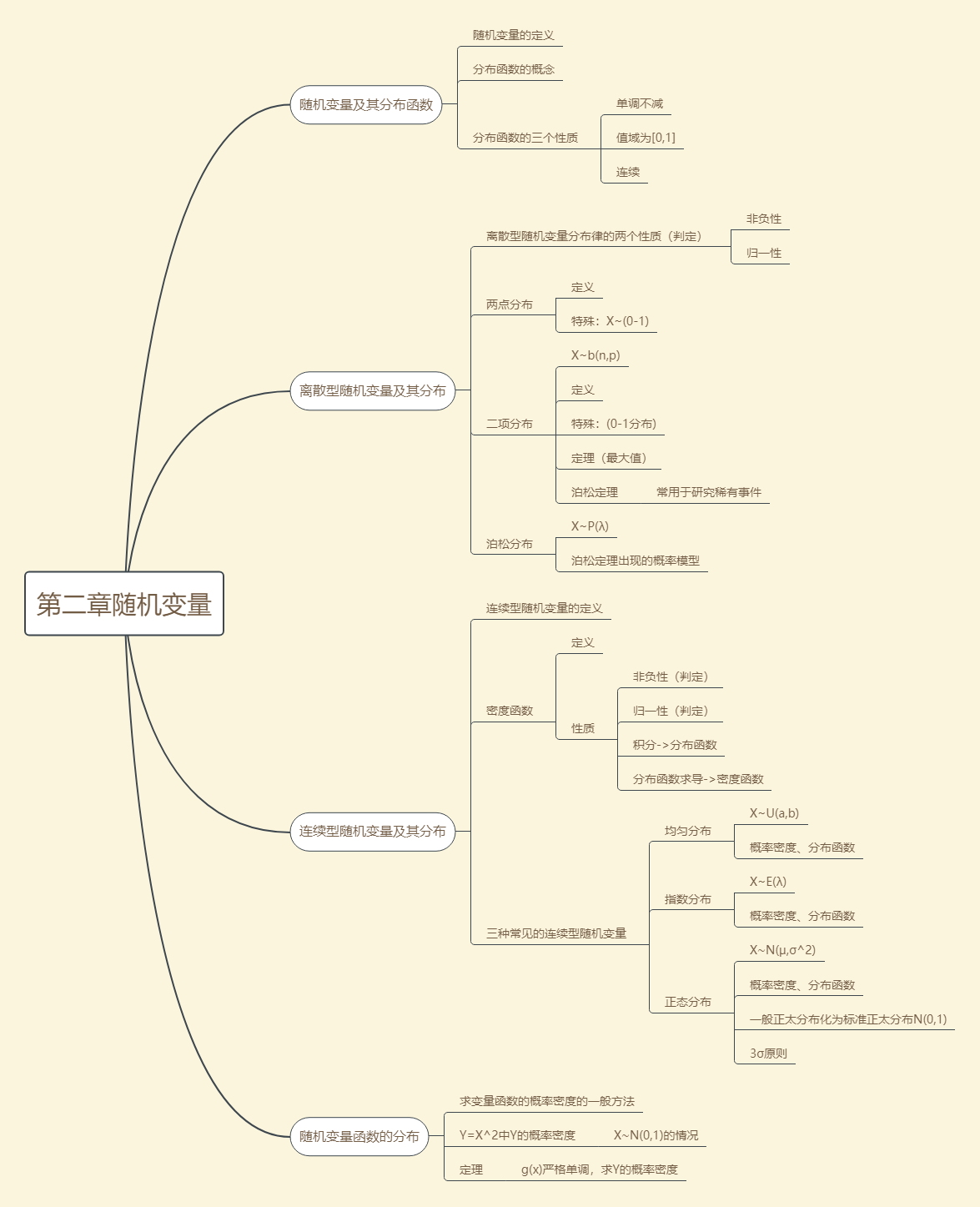
第二章随机变量
2.1随机变量及其分布函数
随机变量:对样本空间Ω的每一个元素e,有一个实数X(e)与之对应,这样定义在Ω上的实值单值函数X=X(e)就称为随机变量
样本空间->实数轴上的值/范围,P(实数轴上的值/范围)->概率
X的分布函数:X是随机变量,x是任意实数,函数F(x)=P{X≤x}称为X的分布函数
对任意实数x1,x2(x1<x2),有P{x1<X≤x2}=P{X≤x2}−P{X≤x1}=F(x2)−F(x1)
分布函数具有的基本性质:
- F(x)为单调不递减函数
- 0≤F(x)≤1,且
limx−>+∞F(x)=1,常记为F(+∞)=1
limx−>−∞F(x)=0,常记为F(−∞)=0
- F(x+0)=F(x),即F(x)为右连续
2.2离散型随机变量及其分布
离散型随机变量:随机变量的取值为有限个或可数无穷多个
离散型随机变量X的概率分布(分布律):P{X=xk}=pk,k=1,2,...
任一离散型随机变量的分布律{pk}两个基本性质
- 非负性(pk≥0,k=1,2,...)
- 归一性(∑∞k=1pk=1)
反过来,具有上述两个性质的数列{pk},一定可以作为某一个离散型随机变量的分布律
两点分布:
若随机变量X只可能取x1与x2两值,它的分布律为
P{X=x1}=1−p,0<p<1
P{X=x2}=p
则称X服从参数为p的两点分布
X∼(0−1)分布,当x1=0,x2=1时,两点分布也叫做(0-1)分布
二项分布:
若随机变量X的分布律为P{X=k}=Cknpk(1−p)n−k,k=0,1,...,n
则称X服从参数为n,p的二项分布,记作X∼b(n,p)
二项分布可以作为描述n重伯努利试验中事件A出现次数的数学模型
(0-1)分布是二项分布在n=1时的特殊情形,故也可写成P{X=k}=pkq1−k,k=0,1;q=1−p
定理:
设ξ∼B(n,p),则当k=ent((n+1)p)时(ent是下取整),b(k;n,p)的值最大,若(n+1)p为整数,则b(k;n,p)=b(k−1;n,p)同为最大值
(可以用二项分布的后一项比前一项,分析比值来证明)
泊松定理:
设npn=λ(λ>0是一常数,n是任意正整数),则对任意一固定的非负整数k,有
limn→∞Cknpkn(1−Pn)n−k=λke−λk!
此定理表明当n很大p很小时,有以下近似公式Cknpk(1−P)n−k≈λke−λk!,其中λ=np
二项分布的泊松公式常用于研究稀有事件
泊松分布:
若随机变量X的分布律为
P{X=k}=λke−λk!,k=0,1,2,...
其中λ>0是常数,则称X服从参数为λ的泊松分布,记为X∼P(λ)
泊松分布可以作为描述大量试验中稀有事件出现的次数的概率分布情况的一个数学模型
F(x)=P{X≤x}=∑xk≤xP{X=xk}=∑xk≤xpk
2.3连续型随机变量及其分布
讨论连续型随机变量在某点的概率是毫无意义的(总是0)
因此计算连续型随机变量的区间概率时不必考虑区间端点的情况
事件{X=a}是“零概率事件”但不是“不可能事件”
连续型随机变量及其概率密度函数(概率密度/密度函数):
若对随机变量X的分布函数F(x),存在非负函数f(x),使对于任意实数x,有
F(x)=∫x−∞f(t)dt
则称X为连续型随机变量,f(x)称为X的概率密度函数
概率密度函数的性质:
- f(x)≥0
- ∫∞−∞f(x)dx=1
- P{x1<X≤x2}=F(x2)−F(x1)=∫x2x1f(x)dx
- 若f(x)在x点连续,则有F′(x)=f(x)
反过来,任一满足以上1、2两个性质的函数f(x),一定可以作为某个连续型随机变量的密度函数
3种常见的连续型随机变量:均匀分布、指数分布、正态分布
-
均匀分布
若连续型随机变量X具有概率密度
f(x)={1b−a,a<x<b0,其它
则称X在区间(a,b)上服从均匀分布,记作X∼U(a,b)
其分布函数为
F(x)=⎧⎪
⎪⎨⎪
⎪⎩0,x<ax−ab−a,a≤x<b1,x≥b
-
指数分布
若随机变量X的密度函数为
f(x)={λe−λx,X>00,x≤0
其中λ>0为常数,则称X服从参数为λ的指数分布,记作X∼E(λ).
对应的分布函数为
F(x)={1−e−λx,x>0,0,x≤0.
指数分布常见于寿命分布,因为其具有无记忆性
对任意s,t>0有
P{X>s+t|X>s}=P{X>t}.
-
正态分布
若连续型随机变量X的密度函数为
f(x)=1√2πσe−(x−e)22σ2,−∞<x<+∞
其中μ,σ(σ>0)为常数,则称X服从参数为μ,σ的正太分布,记为X∼N(μ,σ2)
关于∫+∞−∞f(x)dx=1证略
(令I=∫+∞−∞e−t22dt,极坐标积分变换算出I2=2π,∫+∞−∞f(x)dx=1√2πI=1)
实际问题中大量的随机变量服从或近似服从正态分布
正太分布的性质:
- 曲线关于x=μ对称
- 曲线在x=μ处取最大值,离μ越远f(x)值越小
- 曲线在μ±σ出有拐点
- 曲线以x轴为渐进线
- σ为精度参数,μ为位置参数。固定μ,σ越小图形越尖陡;固定σ,μ变化则沿x轴平移。
当μ=0,σ=1时,称X服从标准正太分布N(0,1),其密度函数表示为φ(x),分布函数表示为Φ(x)
(Φ(−x)=1−Φ(x))
若X∼N(μ,σ2),则有X−μσ∼N(0,1)(证略)
所以有P{x1<X≤x2}=Φ(x2−μσ)−Φ(x1−μσ)
3σ原则:正太分布落在(μ−3σ,μ+3σ)内是几乎肯定的事,可以认为有|X−μ|<3σ
2.4随机变量函数的分布
任务:通过已知的随机变量分布求出与其有函数关系的另一个随机变量的分布
对于要求的随机变量函数的密度函数,一般先求出相应的分布函数再对分布函数求导得出密度函数
若连续型随机变量X具有概率密度fX(x),−∞<x<+∞,又知Y=g(x)=X2
则Y的概率密度为fY(y)={12√y[fX(√y)+fX(−√y)],y>00,y≤0
若X∼N(0,1)
则Y的概率密度为fY(y)={1√2πy−12e−y2,y>00,y≤0,此时称Y服从自由度为1的χ2分布
定理:
设随机变量X具有概率密度fX(x),−∞<x<+∞,又设函数g′(x)处处可导且g′(x)>0(或g′(x)<0),则Y=g(X)是连续型随机变量,其概率密度为
fY(y)={fX(h(y))|h′(y)|,α<y<β0,其它
其中α=min{g(−∞),g(+∞)},β=max{g(−∞),g(+∞)},h(y)是g(x)的反函数
(证略)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律