

性能场景之业务模型在性能执行场景中的具体实现逻辑
系统架构

业务模型
| 业务接口 | 比例 |
|---|---|
| Ta | 20% |
| Tab | 30% |
| Tabc | 20% |
| Tabcd | 30% |
这里的比例可以通过access访问日志来统计,也可以参照《性能测试30讲》第十四章和《高楼的性能工程实战课》第六章
这里要说明下
-
每个接口在调用时,都会在经过的系统中产生一条请求,同时插入一条记录。
-
接口都是串行调用,比如Tabcd接口就是穿过系统ABCD。
下面完善表格
| 系统A | 系统B | 系统C | 系统D | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 业务接口 | 比例 | 访问路径 | 请求数 | DB记录数 | 请求数 | DB记录数 | 请求数 | DB记录数 | 请求数 | DB记录数 |
| Ta | 20% | A | 1 | 1 | ||||||
| Tab | 30% | A-B | 1 | 1 | 1 | 1 | ||||
| Tabc | 20% | A-B-C | 1 | 1 | 1 | 1 | 1 | 1 | ||
| Tabcd | 30% | A-B-C-D | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
上面的表格是每个业务接口调用一次在各系统中产生的请求数和DB记录数
脚本设计
针对这个业务比例,有两种策略来设计脚本
策略一:所有业务接口之间都是独立的,没有任何业务逻辑
显然,我们把每个接口单独控制比例就行了,jmeter设置如下
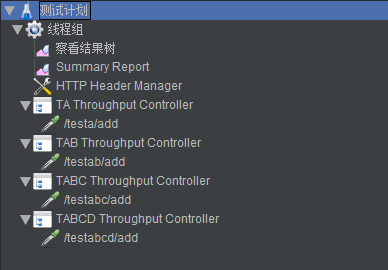
针对每个业务接口都放到一个Throughput Controller中,比例设置和上面的表格中一致,如下图所示:
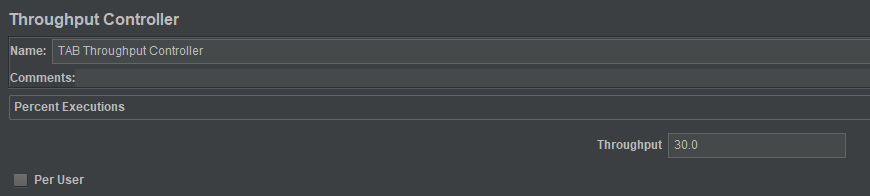
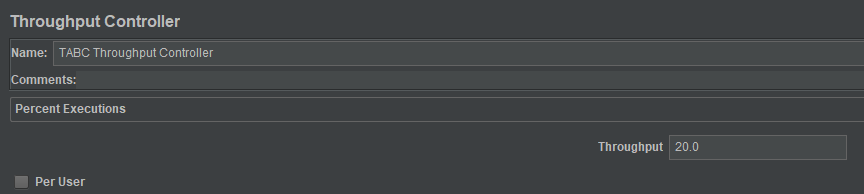
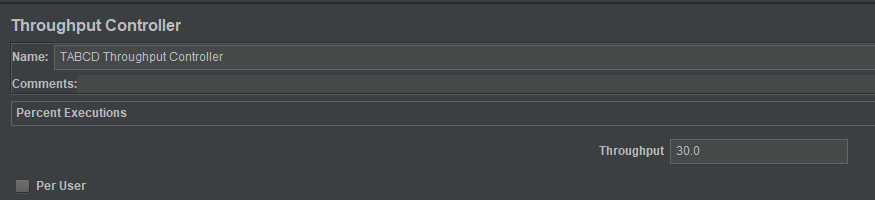
这里,我们运行100次迭代,每个接口会严格按照设置的比例来运行,线程组配置如下:
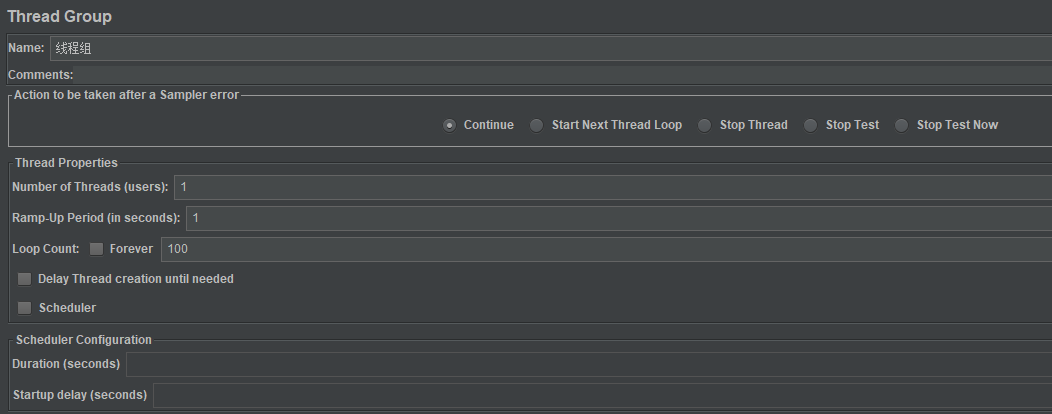
我用一个线程迭代100次,看执行结果:

显然,各个接口是按照我们设计的比例来执行的。
线程组通过设置运行时间来执行,效果也是一样的:
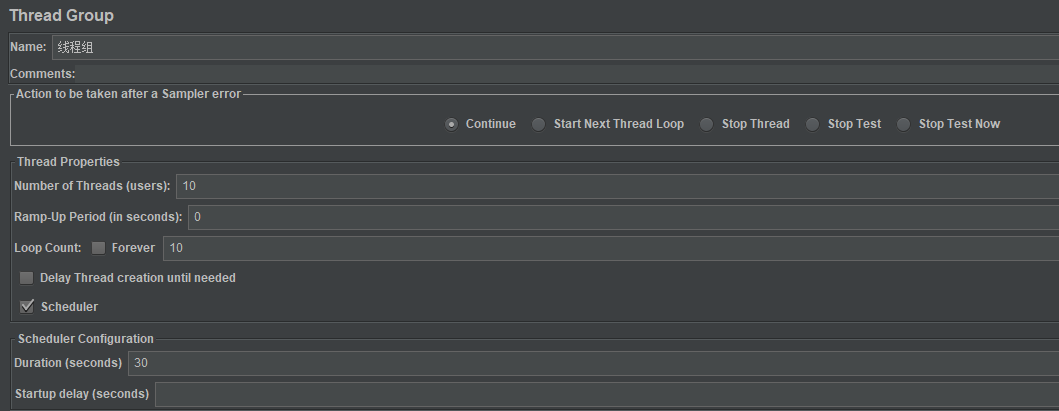
10个线程,每个线程跑10遍,结果如下:
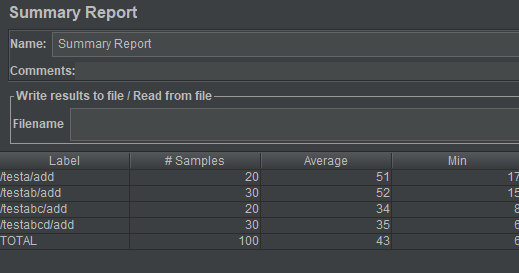
最终落到上面的表格就是这样
| 系统A | 系统B | 系统C | 系统D | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 业务接口 | 比例 | 访问路径 | 请求数 | DB记录数 | 请求数 | DB记录数 | 请求数 | DB记录数 | 请求数 | DB记录数 |
| Ta | 20% | A | 20 | 20 | ||||||
| Tab | 30% | A-B | 30 | 30 | 30 | 30 | ||||
| Tabc | 20% | A-B-C | 20 | 20 | 20 | 20 | 20 | 20 | ||
| Tabcd | 30% | A-B-C-D | 30 | 30 | 30 | 30 | 30 | 30 | 30 | 30 |
或者不限定迭代次数,设置duration,再看下
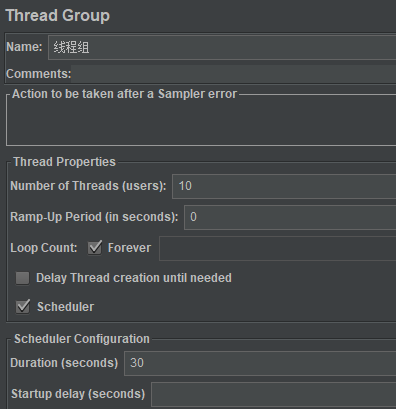
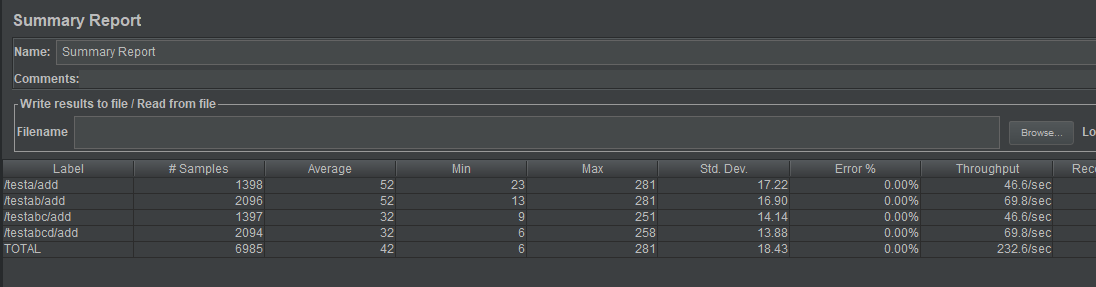
算一下看看
testa:1398/6985=20.014316%
testab:2096/6985=30.007158%
testabc:1397/6985=20%
testabcd:2094/6985=29.978525%
所以,根据这个策略来设计场景,比例偏差必然小于1%。
策略二:业务接口有上下逻辑关系
比如下单,必须登录才能下单,如果你不想登录,就要构造session,这样的业务场景如果还按策略一来设计脚本场景就会有两个问题:
- 需要造数据
- 业务接口的调用逻辑和生产不符
在这个业务背景下,我先假设接口是ta-tab-tabc-tabcd,顺序执行,针对上面的比例关系,我们有两种设计方法。
策略二之方法一:
| 业务接口 | 比例 | 业务脚本1 | 业务脚本2 |
|---|---|---|---|
| Ta | 20% | 20% | |
| Tab | 30% | 20% | 10% |
| Tabc | 20% | 20% | |
| Tabcd | 30% | 20% | 10% |
- 业务脚本1包括Ta/Tab/Tabc/Tabcd四个接口,并且是串行执行的。
- 业务脚本2只包含Tab/Tabcd两个接口,并且也是串行执行。(注:这里我假设的逻辑,Tab - Tabcd是可以组成完整业务的,不需要依赖Ta,Tabc这两个接口,在方法二中我再说当他们不能单独组成完整业务要怎么做。)
这时的场景配置怎么做?首先脚本结构是这样的。
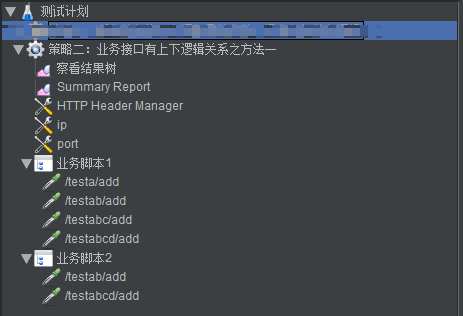
这里的两个业务脚本,对应Throughput Controller。现在问题来了,业务脚本1的执行比例应该是多少呢?
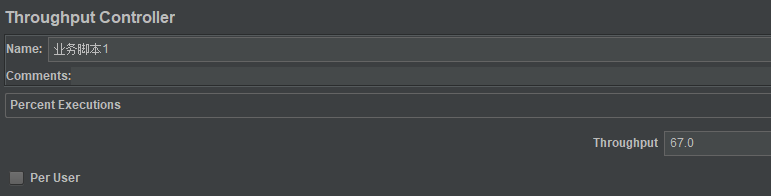
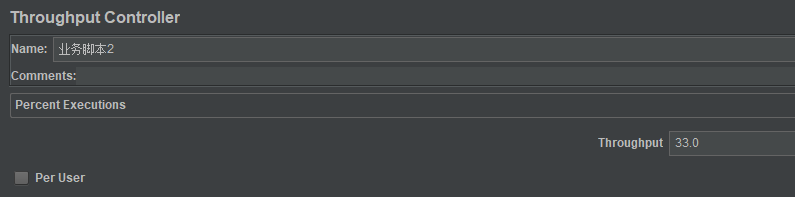
因为业务脚本1的20%是从30%中来的,所以业务脚本1的执行比例是20%/30%,为66.666666...%,而业务脚本2的比例是10%/30%,为33.33333...%,取整结果如下:
| 业务脚本1 | 业务脚本2 | |
|---|---|---|
| 执行比例 | 67% | 33% |
所以,Throughput Controller我们这样设置:
Thread Group这样配置:
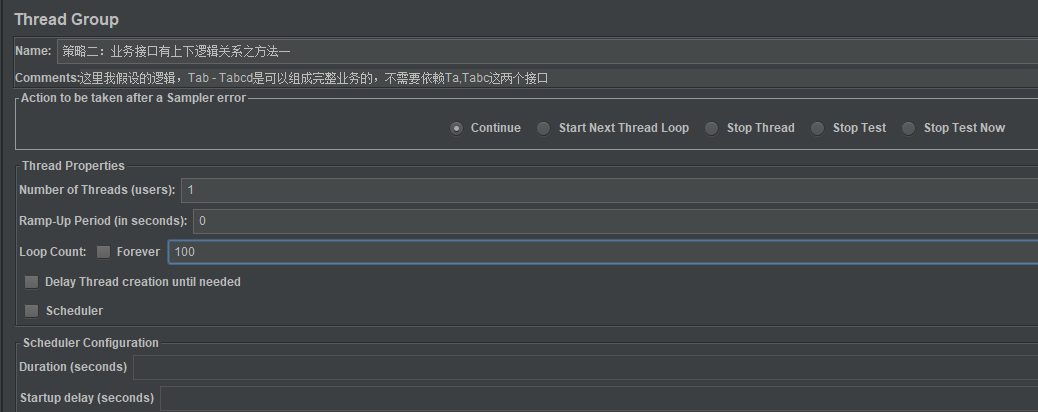
我还是用一个线程迭代100次,这个场景的执行结果,如果不出所料,是这样的:
因为我总共执行100次,业务脚本1会执行67次,所以每个接口都会执行67次;业务脚本2会执行33次,所以Tab、Tabcd会各执行33次,所以执行次数如下:
| 业务接口 | 比例 | 业务脚本1 | 业务脚本2 | 业务接口执行次数 |
|---|---|---|---|---|
| Ta | 20% | 67 | 67 | |
| Tab | 30% | 67 | 33 | 100 |
| Tabc | 20% | 67 | 67 | |
| Tabcd | 30% | 67 | 33 | 100 |
执行下看看实际结果:

嗯,果然不出我所料~~
策略二之方法二:
现在有一个需求是这样的,我的接口必须按顺序执行,单独Tab,Tabcd不能闭环怎么办?
这种情况只能有一个业务脚本啊。这时候的脚本可以这样配置:
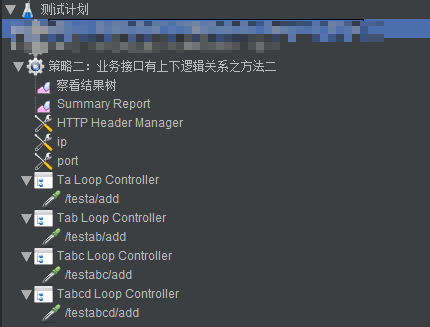
这里我在每个接口上面加了一个Loop Controller,设置Loop Count成这样:
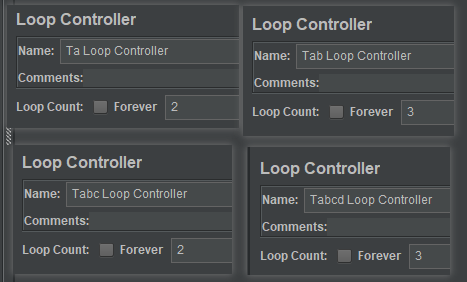
注:这里的设置循环次数数值取决于百分比,但是由于这里只支持整数,所以当比例值不是整数时,要扩大倍数使之成为整数之后再设置在这里。
线程组设置如下:
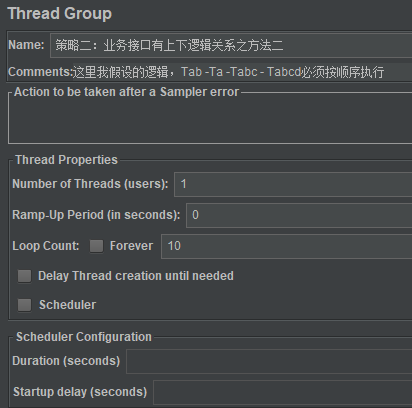
这里我们暂且设置为1个线程迭代10次,来更清晰的呈现比例关系。结果如下:
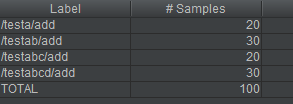
结果证明满足比例关系!
总结
业务模型对性能场景是灰常重要的。从生产上或者从业务手上拿到业务比例后,如果不能严格地在场景中遵循业务比例来执行场景,那这个性能场景就不符合业务模型,从而导致性能项目做起来毫无意义。
在这里,我描述了两种策略来实现业务模型。策略一对应的是无逻辑关系的混合业务场景;策略二对应的是有逻辑关系的混合业务场景。
接口代码(fastapi+pydantic)
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
# 使用pydantic模型做请求体
class Test(BaseModel):
code: str
data: str
tax: float
amount: float
@app.get("/test")
def home():
result = {"code":0, "msg": "这是一个用于性能压测的演示项目"}
return result
@app.post("/testa/add")
def a():
results = {"code":0,"msg":"success"}
return results
@app.post("/testab/add")
def b():
results = {"code":0,"msg":"success"}
return results
@app.post("/testabc/add")
def c():
results = {"code":0,"msg":"success"}
return results
@app.post("/testabcd/add")
def d(test:Test):
return test
 浙公网安备 33010602011771号
浙公网安备 33010602011771号