
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
2 <= nums.length <= 104
-109 <= nums[i] <= 109
-109 <= target <= 109
只会存在一个有效答案
解题思路:
已知target,遍历数组元素时,通过(target - 数组元素)即可得到第二个相加的参数,判断此参数是否存在于数组当中,且要保证该参数和当前遍历元素不是同一个元素。
/** * @param {number[]} nums * @param {number} target * @return {number[]} */ var twoSum = function(nums, target) { let ret = []; for (let i = 0; i < nums.length; i++) { let numOne = nums[i]; let numTwo = target - numOne; let index = nums.indexOf(numTwo); if (index !== -1 && index !== i) { ret = [].concat(i, index); return ret; } } return ret; };
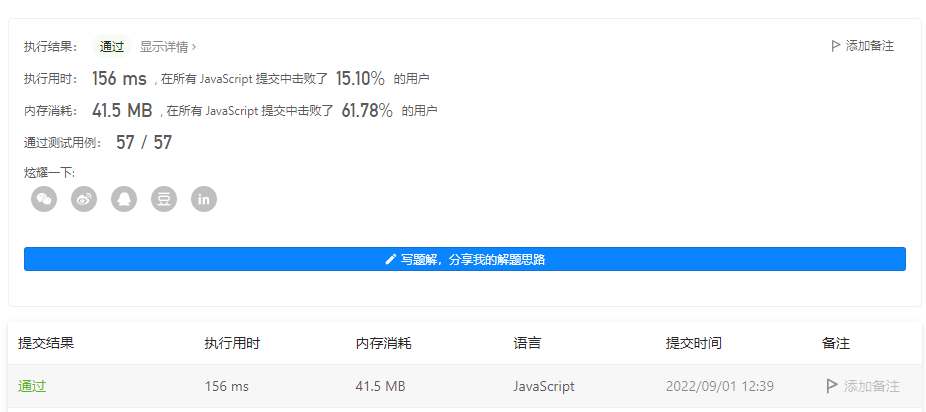
代码的执行用时和内存消耗如下:
这里有一个思路,就是建立一个 {值: 索引值}的键值对(哈希表),比如数组[1,1, 2, 2, 3, 3],建立键值对后为{ 1: 1, 2: 3, 3: 5 }。
意思是指:一个值只保存一个索引即可,相同的值只需要查找这个索引即可。
按照这个思路重新修改代码如下:
/** * @param {number[]} nums * @param {number} target * @return {number[]} */ var twoSum = function(nums, target) { let ret = []; let numIndex = new Map(); for (let i = 0; i < nums.length; i++) { numIndex.set(nums[i], i); } for (let i = 0; i < nums.length; i++) { let numOne = nums[i]; let numTwo = target - numOne; let index = numIndex.get(numTwo); if (index !== undefined && index !== i) { ret = [].concat(i, index); return ret; } } return ret; };
代码的执行用时和内存消耗如下:
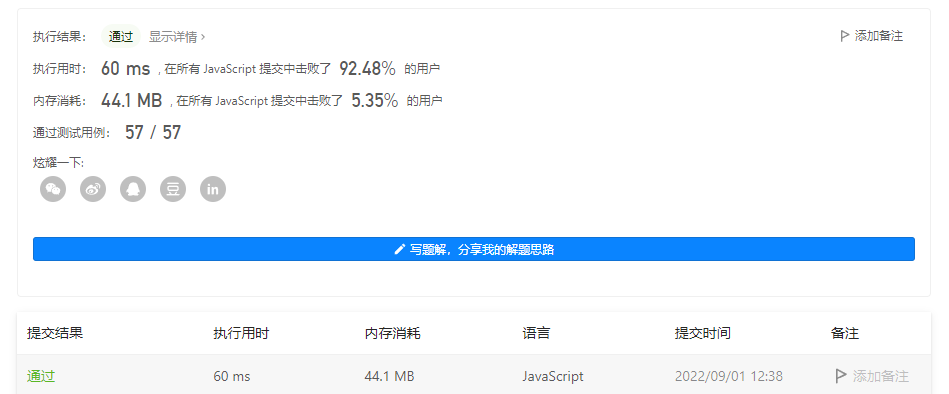
发现后者的用时更少,内存可以忽略不计。
两者的区别主要在于,举例说明:
当数组为[3, 1, 1, 2, 3],给的target为6时,前者在遍历数组时,当索引 i = 0时, numOne=3,numTwo=3,通过数组的indexOf方法拿到的index为0,此时index === i 则进入下一次遍历 i = 1,直到 i = 4时,此时numOne = 3, numTwo = 3,index为0,此时index !== i,则为最终的return。
但是按照后者的方法,会维护一个map对象{ 3: 4, 1: 2, 2: 3 },当target为6时,遍历数组,当索引 i = 0 时,numOne = 3 = numTwo, 此时通过map.get得到的index 为4,index !== i ,则直接输出。后者的代码就是跳过了前者中无用的一次循环,因此效率增加。
2.给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例1:
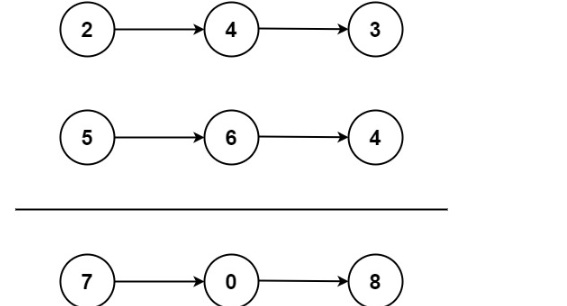
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
示例 2:
输入:l1 = [0], l2 = [0]
输出:[0]
示例 3:
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]
提示:
每个链表中的节点数在范围 [1, 100] 内
0 <= Node.val <= 9
题目数据保证列表表示的数字不含前导零
注意:本身这个题目的逻辑不是很难,但是要注意数据结构ListNode,要根据它所给出的数据结果做返回,如果按照形式上的数组作为返回就会报错,函数的输入也是ListNode,如果按照数组来考虑也会各种报错。
代码如下:
/** * Definition for singly-linked list. * function ListNode(val, next) { * this.val = (val===undefined ? 0 : val) * this.next = (next===undefined ? null : next) * } */ /** * @param {ListNode} l1 * @param {ListNode} l2 * @return {ListNode} */ var listNodeToArray = function(listNode) { let arr = []; arr.push(listNode.val); let next = listNode.next; while (next !== null) { arr.push(next.val); next = next.next; } return arr; } var arrayToListNode = function(array) { let listNode; let val = array[0]; let otherArr = array.slice(1); let next = otherArr.length ? arrayToListNode(otherArr) : undefined; listNode = new ListNode(val, next); return listNode; } var addTwoNumbers = function(l1, l2) { let arr1 = listNodeToArray(l1); let arr2 = listNodeToArray(l2); let len1 = arr1.length; let len2 = arr2.length; let ret = []; let update = false; let add; if (len1 > len2) { add = new Array(len1 - len2).fill(0); arr2.splice(len2, 0, ...add); } else if (len1 < len2) { add = new Array(len2 - len1).fill(0); arr1.splice(len1, 0, ... add); } let len = arr1.length; for (let i = 0; i < len; i++) { let sum = arr1[i] + arr2[i]; sum = update ? sum + 1 : sum; if (sum >= 10) { update = true; ret.push(sum % 10); } else { update = false; ret.push(sum); } if (i === len - 1 && update) { ret.push(1); } } return arrayToListNode(ret); };
3.无重复的最长字符串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
思路:
我们先用一个例子考虑如何在较优的时间复杂度内通过本题。
我们不妨以示例一中的字符串 abcabcbb 为例,找出从每一个字符开始的,不包含重复字符的最长子串,那么其中最长的那个字符串即为答案。对于示例一中的字符串,我们列举出这些结果,其中括号中表示选中的字符以及最长的字符串:
以 (a)bcabcbb 开始的最长字符串为 (abc)abcbb;
以 a(b)cabcbb 开始的最长字符串为 a(bca)bcbb;
以 ab(c)abcbb 开始的最长字符串为 ab(cab)cbb;
以 abc(a)bcbb 开始的最长字符串为 abc(abc)bb;
以 abca(b)cbb 开始的最长字符串为 abca(bc)bb;
以 abcab(c)bb 开始的最长字符串为 abcab(cb)b;
以 abcabc(b)b 开始的最长字符串为 abcabc(b)b;
以 abcabcb(b) 开始的最长字符串为 abcabcb(b)。
发现了什么?如果我们依次递增地枚举子串的起始位置,那么子串的结束位置也是递增的!这里的原因在于,假设我们选择字符串中的第k个字符作为起始位置,并且得到了不包含重复字符的最长子串的结束位置为 rk。那么当我们选择第k+1个字符作为起始位置时,首先从k+1到rk之间的字符显然是不重要的(这之间的字符必然是不重复的,因为k到rk之间是不重复的),并且由于少了原本的第k个字符,我们可以尝试继续增大rk,直到右侧出现了重复字符为止。

/** * @param {string} s * @return {number} */ var lengthOfLongestSubstring = function(s) { let occ = new Set(); let len = s.length; let rk = -1; let ans = 0; for (let i = 0; i < len; i++) { if (i !== 0) { occ.delete(s.charAt(i - 1)); } while (rk + 1 < len && !occ.has(s.charAt(rk + 1))) { occ.add(s.charAt(rk + 1)); rk++; } ans = Math.max(ans, rk - i + 1) } return ans; };
上述问题是一个滑动窗口的典型问题,接下来主要讲一下滑动窗口:
滑动窗口是双指针的一种特例,可以称为左右指针,在任意时刻,只有一个指针运动,而另一个保持静止。滑动窗口一般用于解决特定的序列中符合条件的连续的子序列的问题。
滑动窗口的时间复杂度是线性的,一般是O(n),滑动窗口的左右边界都不会向左滑动,向左滑动等于走回头路,是一种回溯的算法,很可能陷入死循环。
滑动窗口是一种全遍历问题,一定会遍历到末尾的。
其本质思路在于:
1、初始化将滑动窗口压满,取得第一个滑动窗口的目标值;
2、继续滑动窗口,每往前滑动一次,需要删除一个和添加一个元素,求最优的目标值。
一般来说,滑动窗口解决最多的就是子序列和子数组的问题。
使用滑动窗口的难点在于:什么时候应该移动右指针来扩大窗口,什么时候移动左指针来减少窗口。
4.给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
每个右括号都有一个对应的相同类型的左括号。
示例 1:
输入:s = "()"
输出:true
示例 2:
输入:s = "()[]{}"
输出:true
示例 3:
输入:s = "(]"
输出:false
提示:
1 <= s.length <= 104
s 仅由括号 '()[]{}' 组成
思路分析:
判断括号的有效性可以使用栈(先进后出)来解决这个问题:
当遍历给定的字段s时,当遇到一个左括号时,我们会期望在后续遍历中,有一个相同类型的有括号使其闭合。由于后遇到的左括号要先闭合,因此我们可以将这个左括号放入栈顶。
当我们遇到一个右括号时,我们需要将一个相同类型的左括号闭合。此时,我们取出栈顶的左括号并判断它们是否是相同类型的括号。如果不是相同的类型,或者栈中并没有左括号,那么字符串s无效,返回false。
为了可以快速判断括号的类型,我们可以使用哈希表存储每一种括号,哈希表的key为右括号,值为相同类型的左括号。
在遍历结束后,如果栈中没有左括号,说明我们将字符串s中的所有左括号闭合,返回true,否则返回false。
注意有效字符串的长度一定是偶数,因此如果字符串的长度为奇数,我们可以直接返回false,省去后续的遍历判断过程。
