2019秋招面试题-机器学习部分
一、TF-IDF
有很多不同的数学公式可以用来计算TF-IDF。这边的例子以上述的数学公式来计算。词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。一个计算文件频率 (IDF) 的方法是文件集里包含的文件总数除以测定有多少份文件出现过“母牛”一词。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 lg(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03 * 4=0.12。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
二、分类和回归的损失函数
https://www.cnblogs.com/houjun/p/8956384.html
分类:
1、 0-1损失 (zero-one loss)
2、感知损失
3、cross entropy
4、Logistic loss
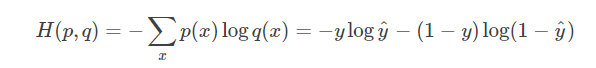
*********************************************************************
回归:
https://blog.csdn.net/reallocing1/article/details/56292877
MSE: Mean Squared Error
均方误差:是指参数估计值与参数真值之差平方的期望值;
RMSE
均方根误差:是均方误差的算术平方根
MAE :Mean Absolute Error
平均绝对误差是绝对误差的平均值
平均绝对误差能更好地反映预测值误差的实际情况.
SVM损失函数:hinge损失+w2正则
adaboost:指数损失
三、如何避免陷入鞍点(局部最小)
(一)以多组不同参数值初始化多个神经网络,去其中误差最小的作为结果
(二)使用“模拟退火”技术
模拟退火在每一步都以一定的概率接受比当前解更差的结果,从而有助于跳出局部最小值。在每次迭代过程中,接受’“次优解”的概率要随着时间的推移而逐渐降低,从而保证算法稳定。
(三)使用随机梯度下降
每次随机选取一个样本进行梯度下降,在梯度下降时加入了随机因素。即便陷入了局部最小点,它计算出的梯度可能仍不为零,这样就有机会跳出局部最小继续搜索。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号