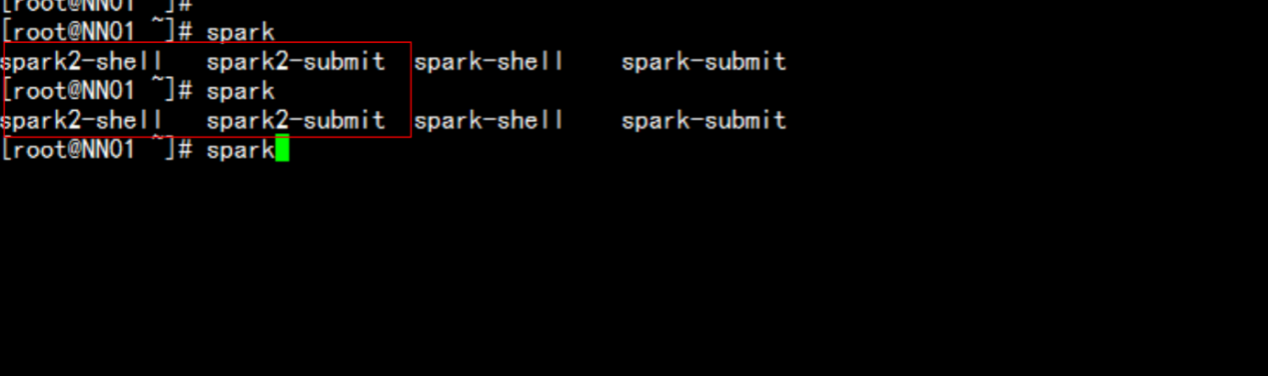
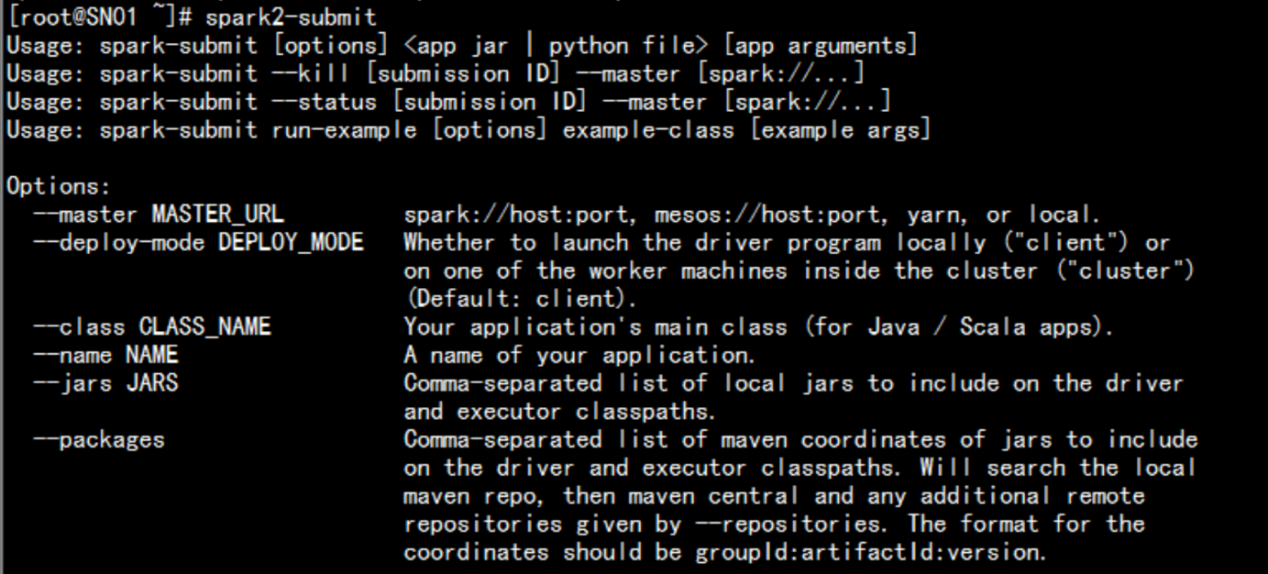
CDH入门教程2
CDH入门教程2
第3章 数据仓库模块安装
3.1 Hive安装
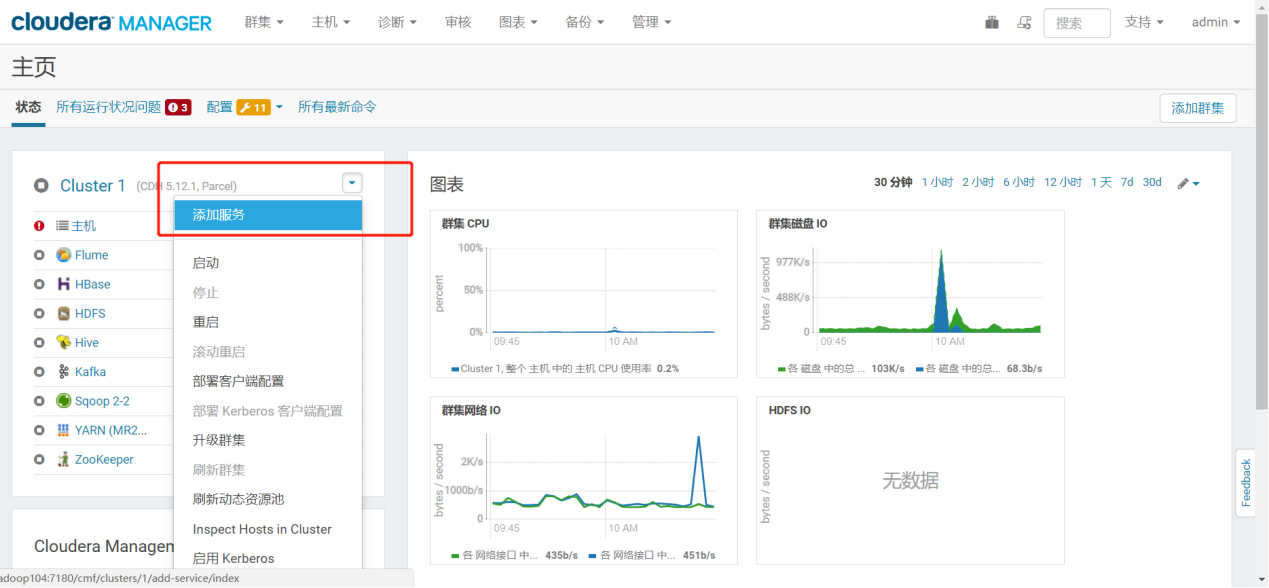
3.1.1 添加服务
3.1.2 添加Hive服务
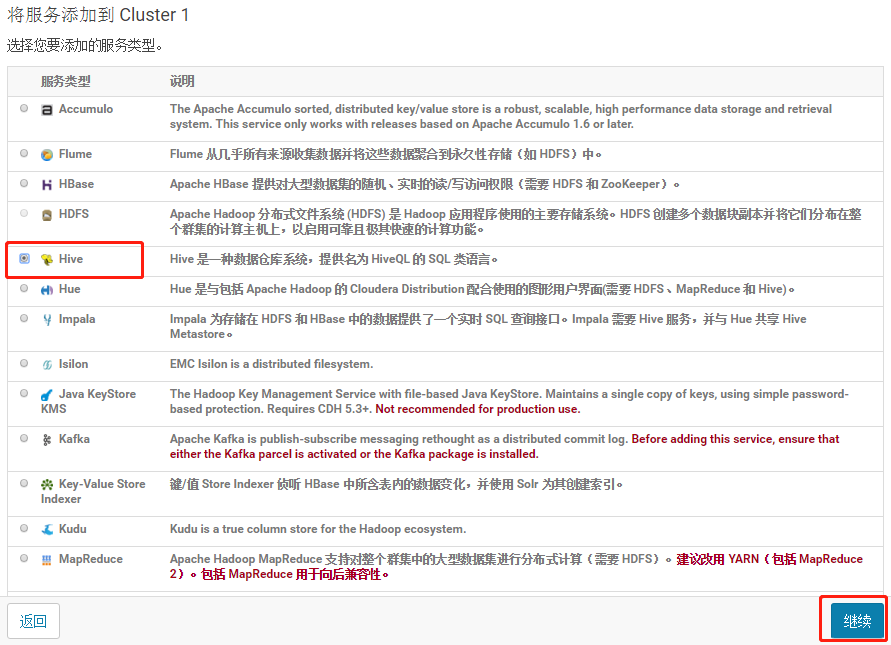
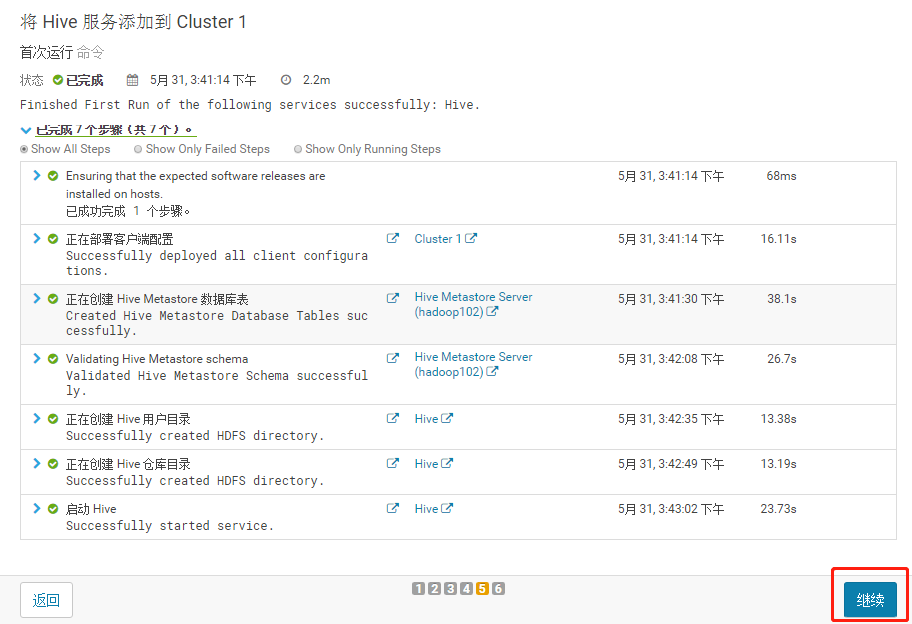
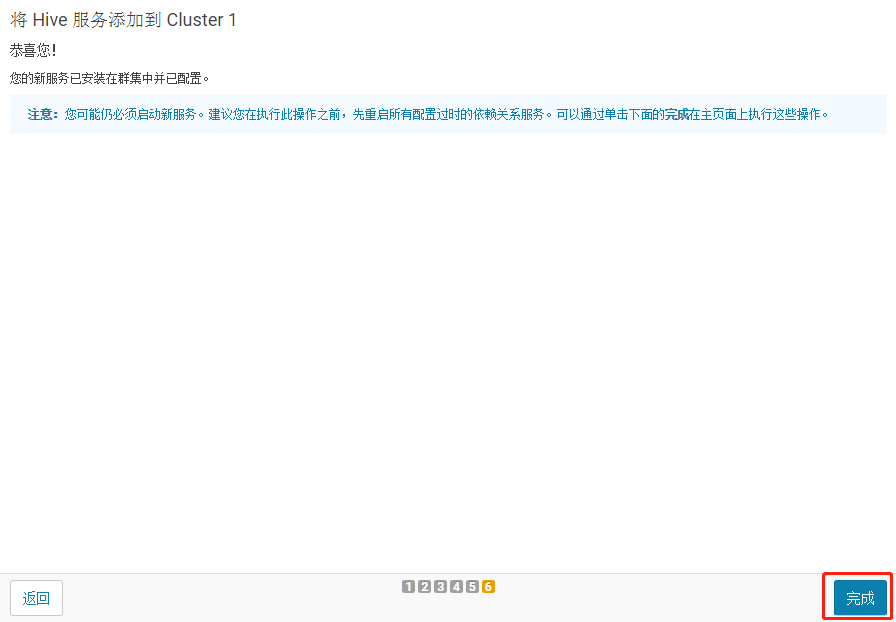
3.1.3 将 Hive 服务添加到 Cluster 1
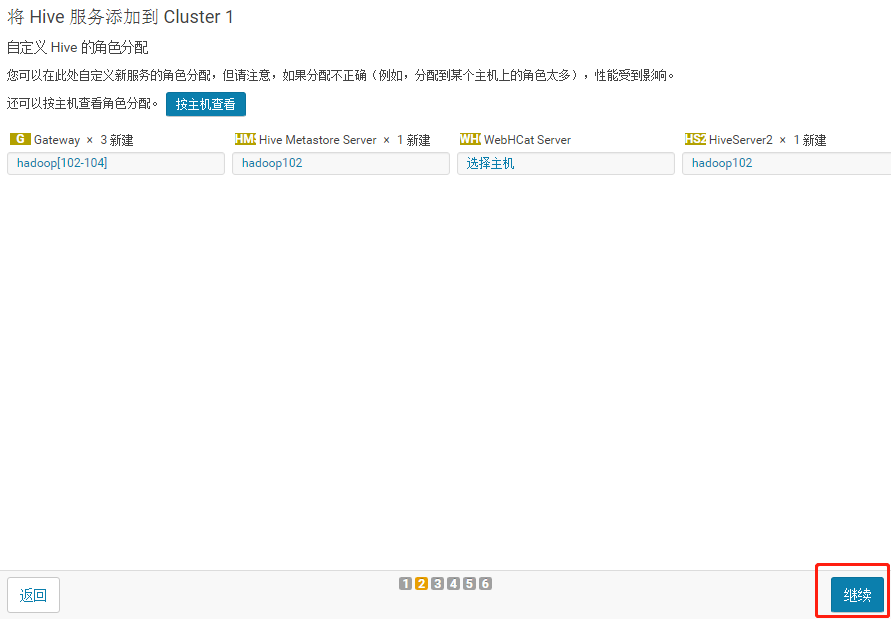
3.1.4 配置hive元数据
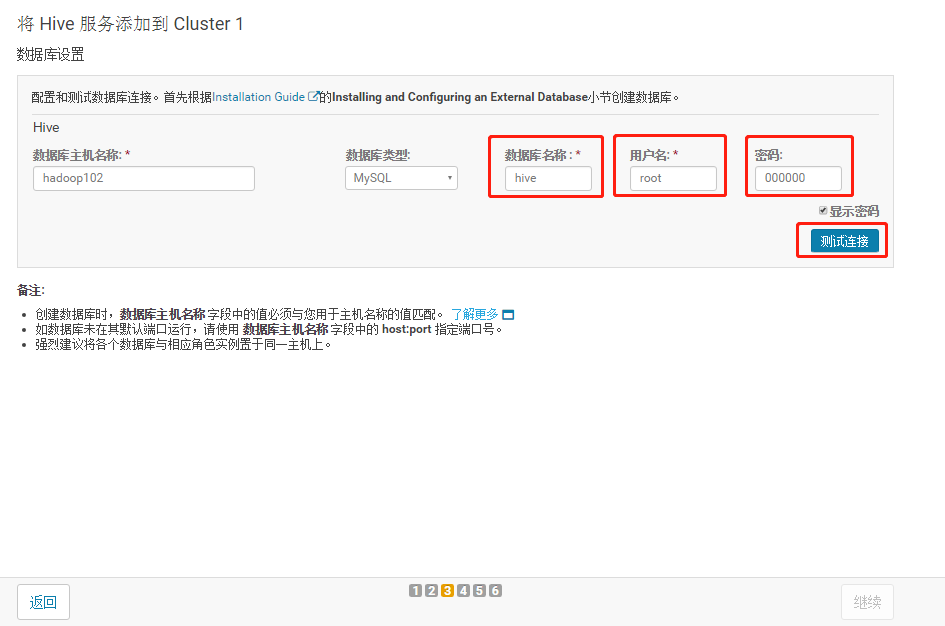
3.1.5 测试通过后继续
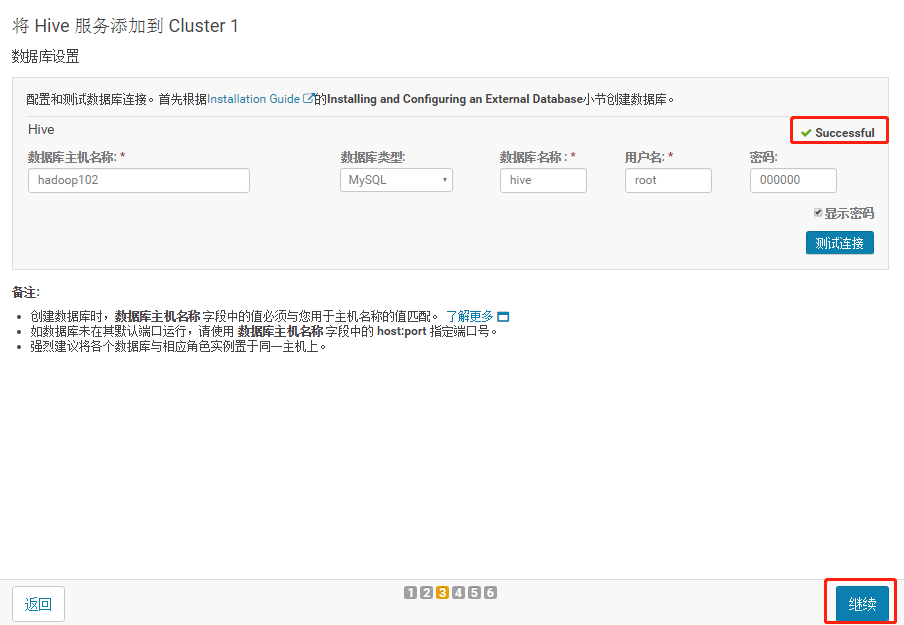
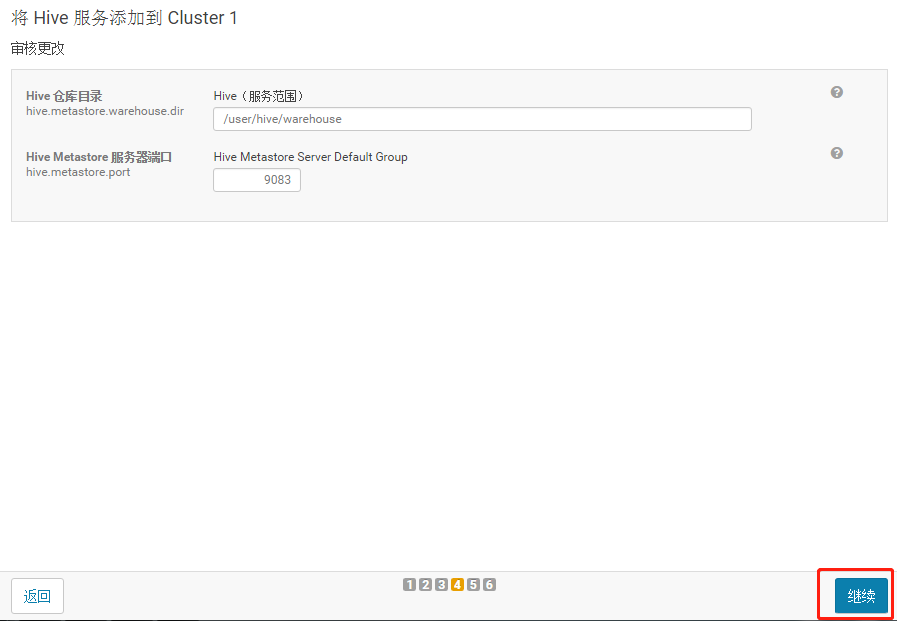
3.1.6 自动启动Hive进程
3.2 Oozie安装
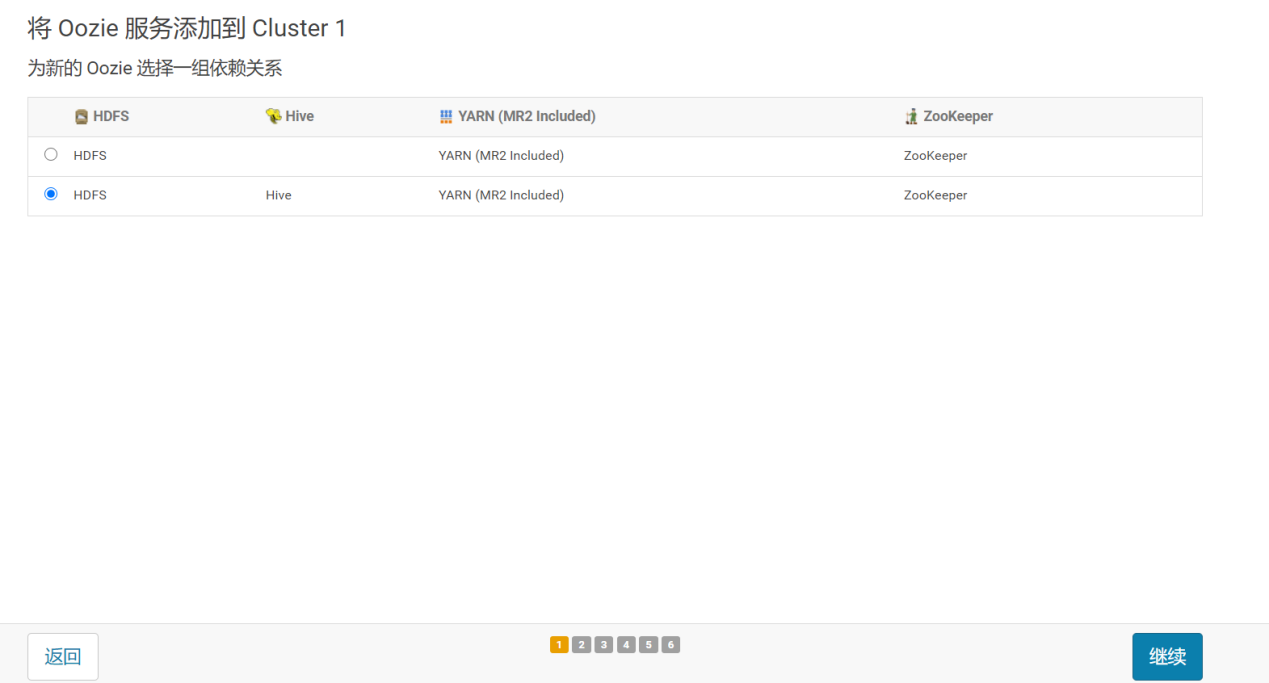
3.2.1 添加Oozie服务
3.2.2 选择集群节点
3.2.3 选择有MySQL的节点安装
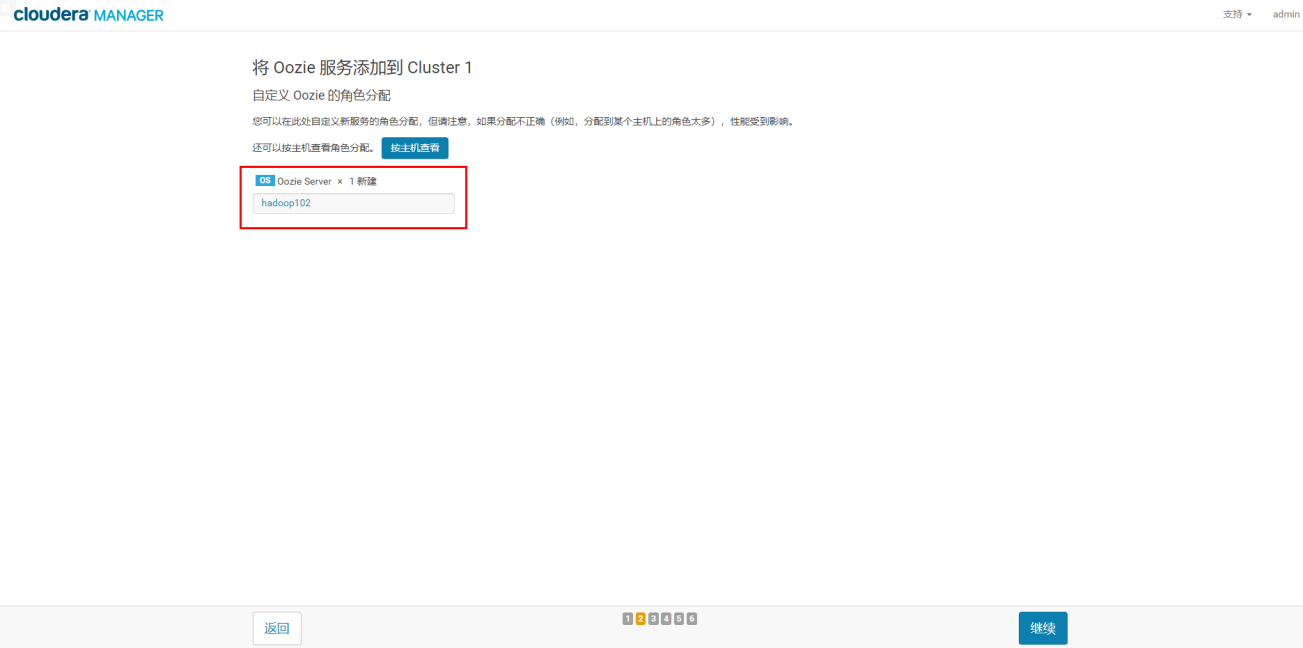
3.2.4 链接数据库
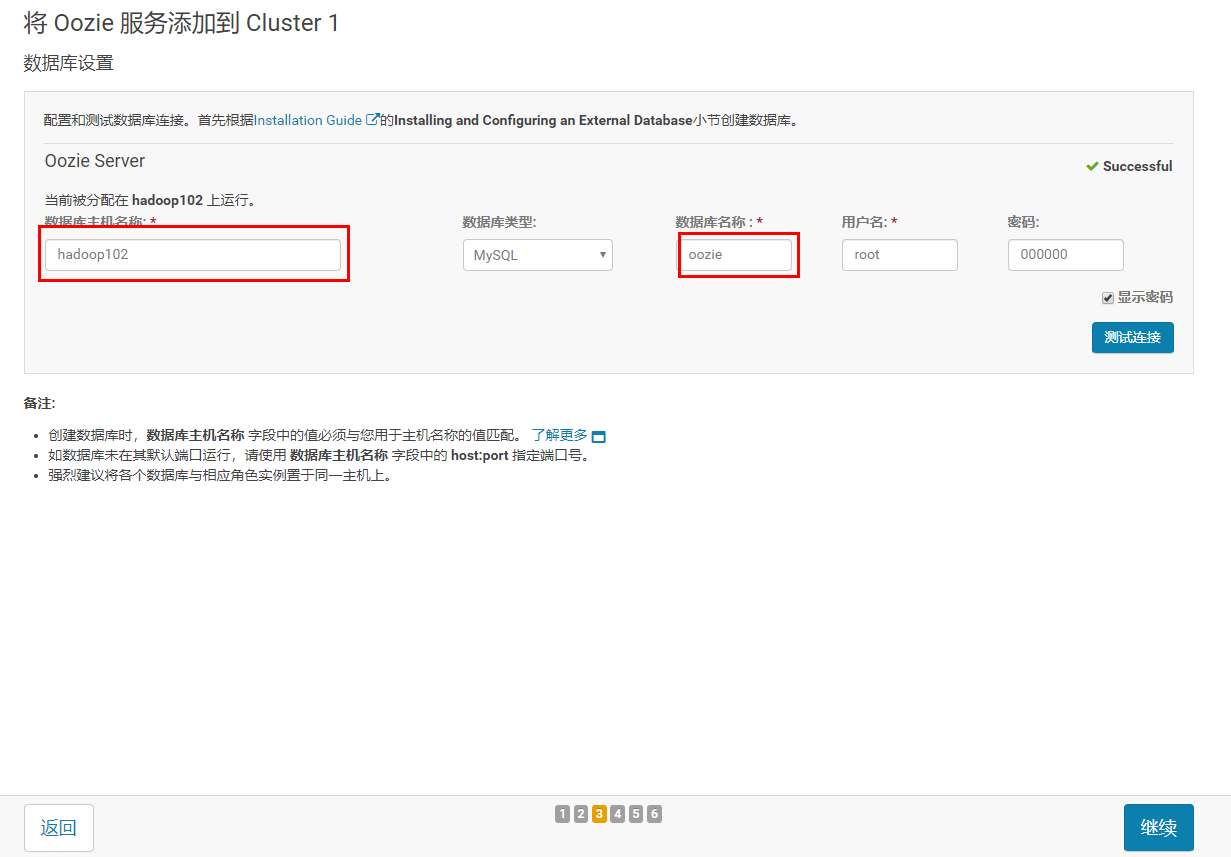
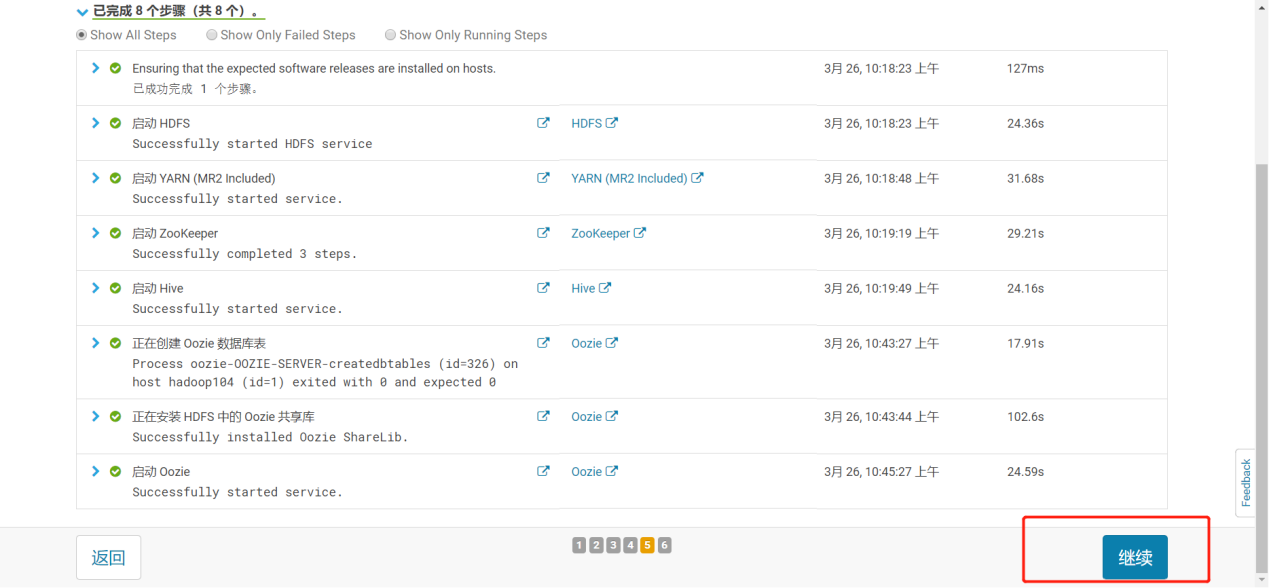
3.2.5 一路继续到完成
3.3 Hue安装
3.3.1 Hue概述
1)Hue来源
HUE=Hadoop User Experience(Hadoop用户体验),直白来说就一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web框架Django实现的。通过使用HUE我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据。
2)Hue官网及使用者
官网网站:http://gethue.com/
3.3.2 安装前的准备
1)在LoadBalancer节点安装mod_ssl
[root@hadoop102 ~]# yum -y install mod_ssl
2)查看/usr/lib64/mysql下有没有libmysqlclient_r.so.18,如果没有,上传hadoop103主机上的libmysqlclient_r.so.18到/usr/lib64/mysql,并软链接到/usr/lib64/,然后运行ldconfig 命令,让其生效。
[root@hadoop102 ~]# ls /usr/lib64/mysql
[root@hadoop103 mysql]#
scp /usr/lib64/mysql/libmysqlclient.so.18 root@hadoop102:/usr/lib64/mysql/
[root@hadoop102 ~]ln -s /usr/lib64/mysql/libmysqlclient.so.18 /usr/lib64/libmysqlclient_r.so.18
[root@hadoop102 ~]ldconfig
3.3.3 HUE安装步骤
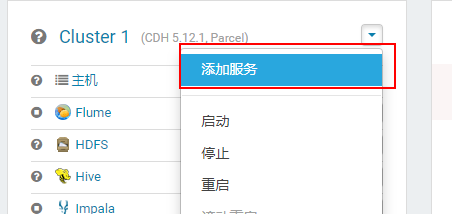
1)添加HUE服务
2)选择集群节点
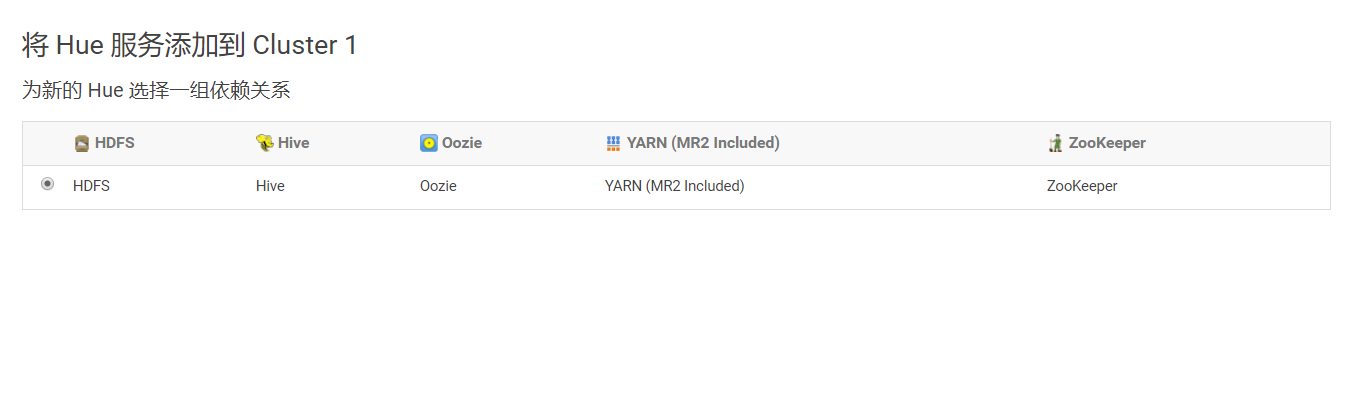
3)分配角色
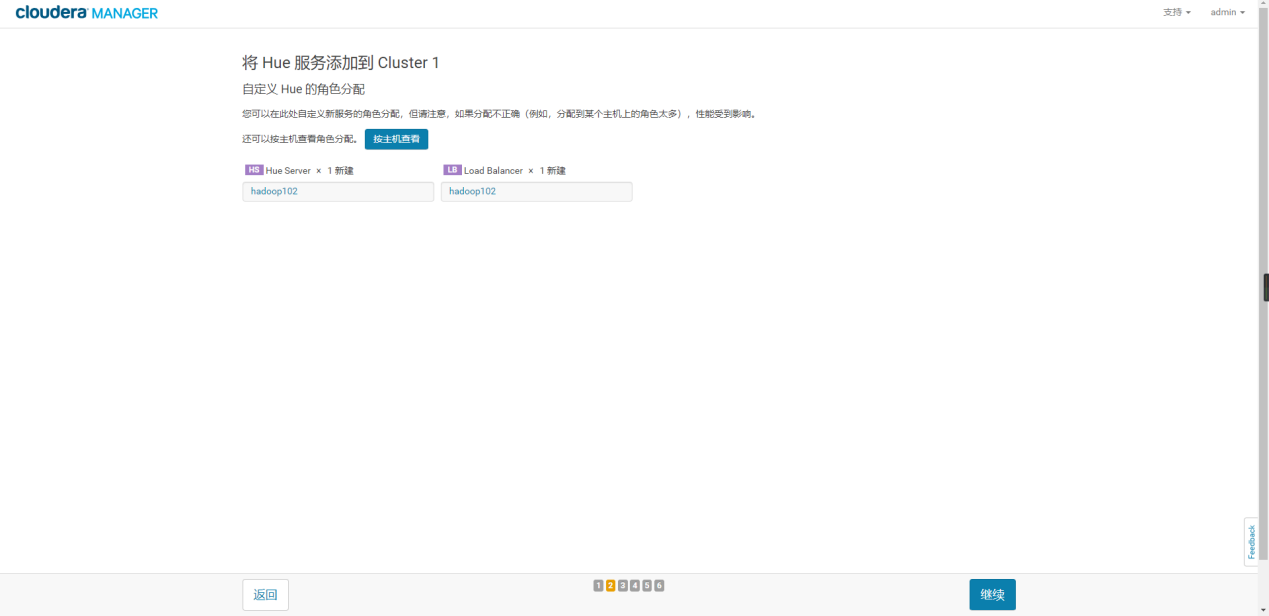
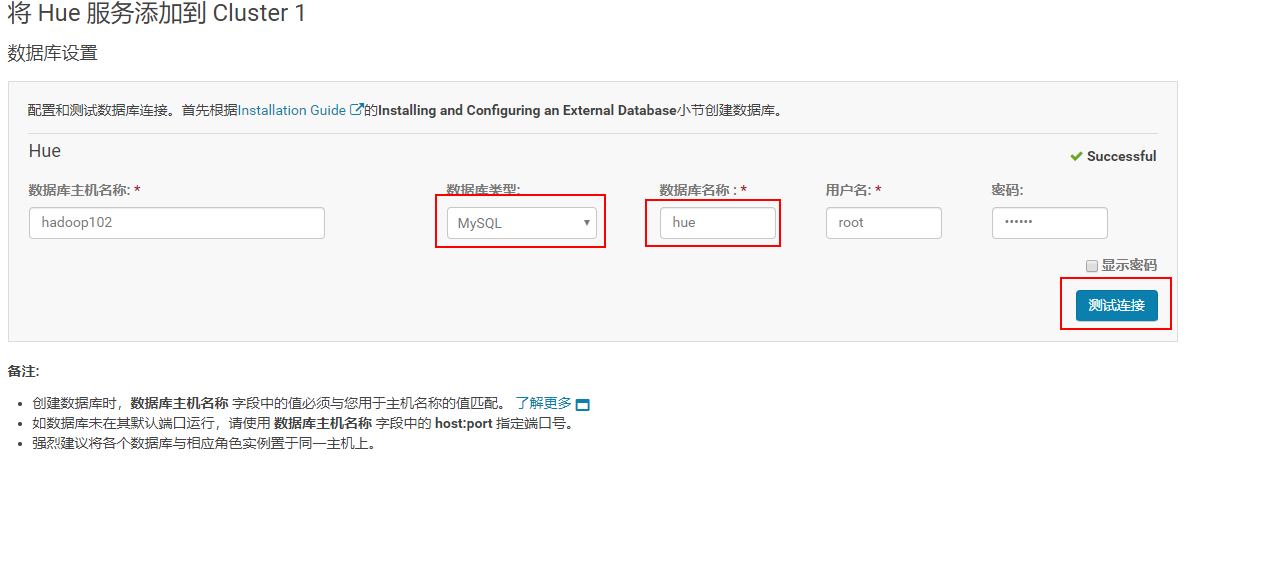
4)配置数据库
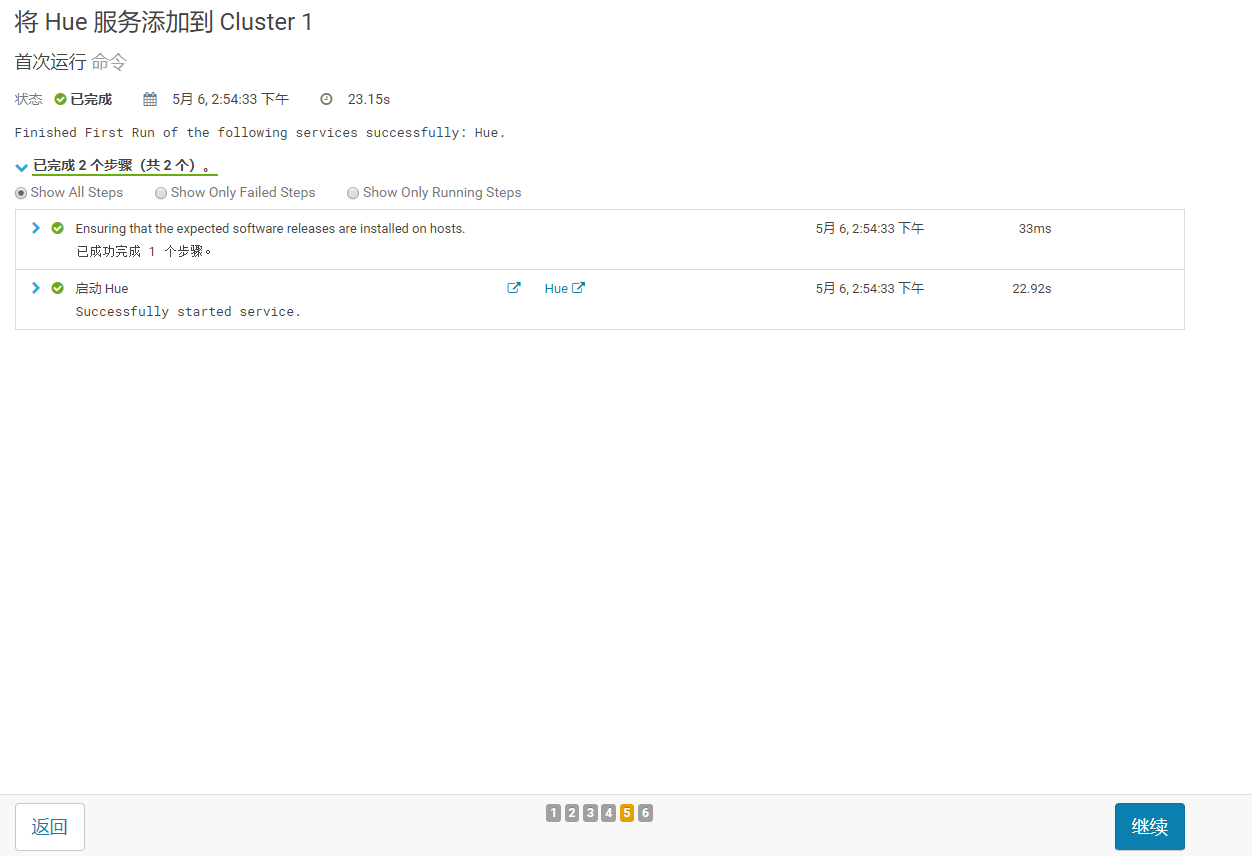
5)安装完成
6)HUE页面
http://hadoop102:8888(未优化)或http://hadoop102:8889(优化)
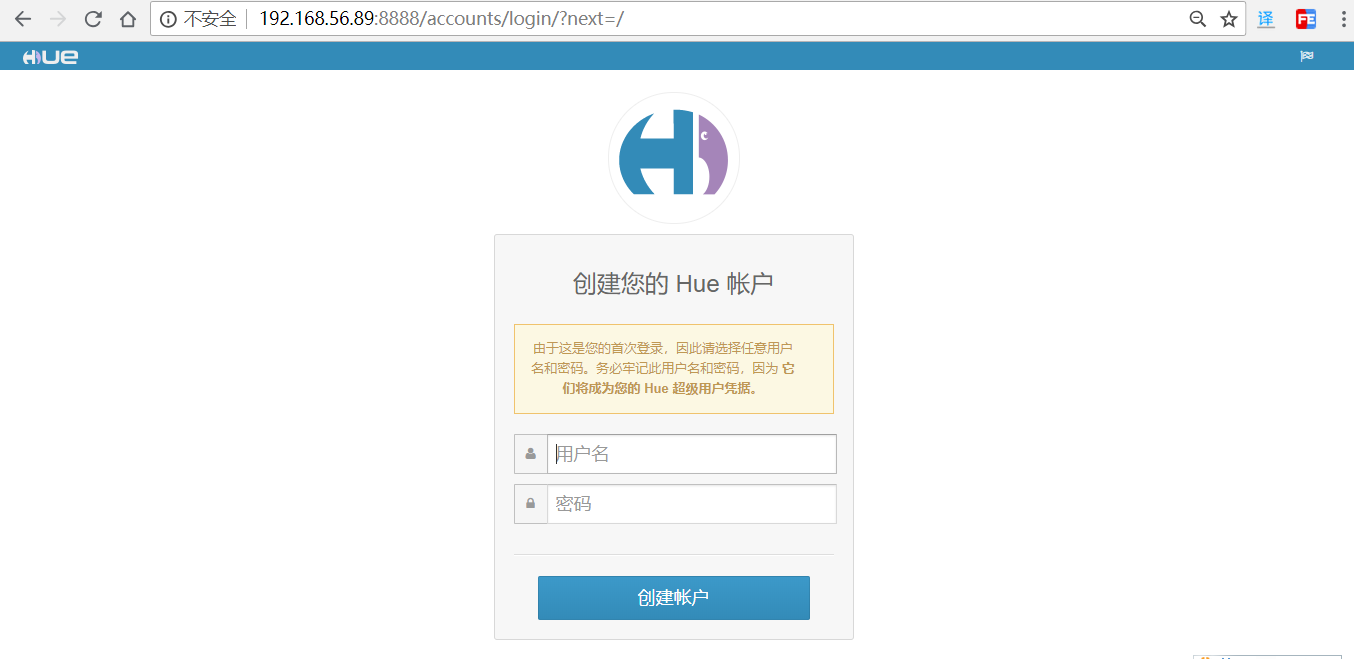
第一次开启HUE会出现以下页面,此时输入的用户名和密码可以随意,之后登录页面以第一次输入的账号密码为依据。例如,用户名:admin 密码:admin
3.4 Impala安装
3.4.1 添加服务

3.4.2 选择Impala服务
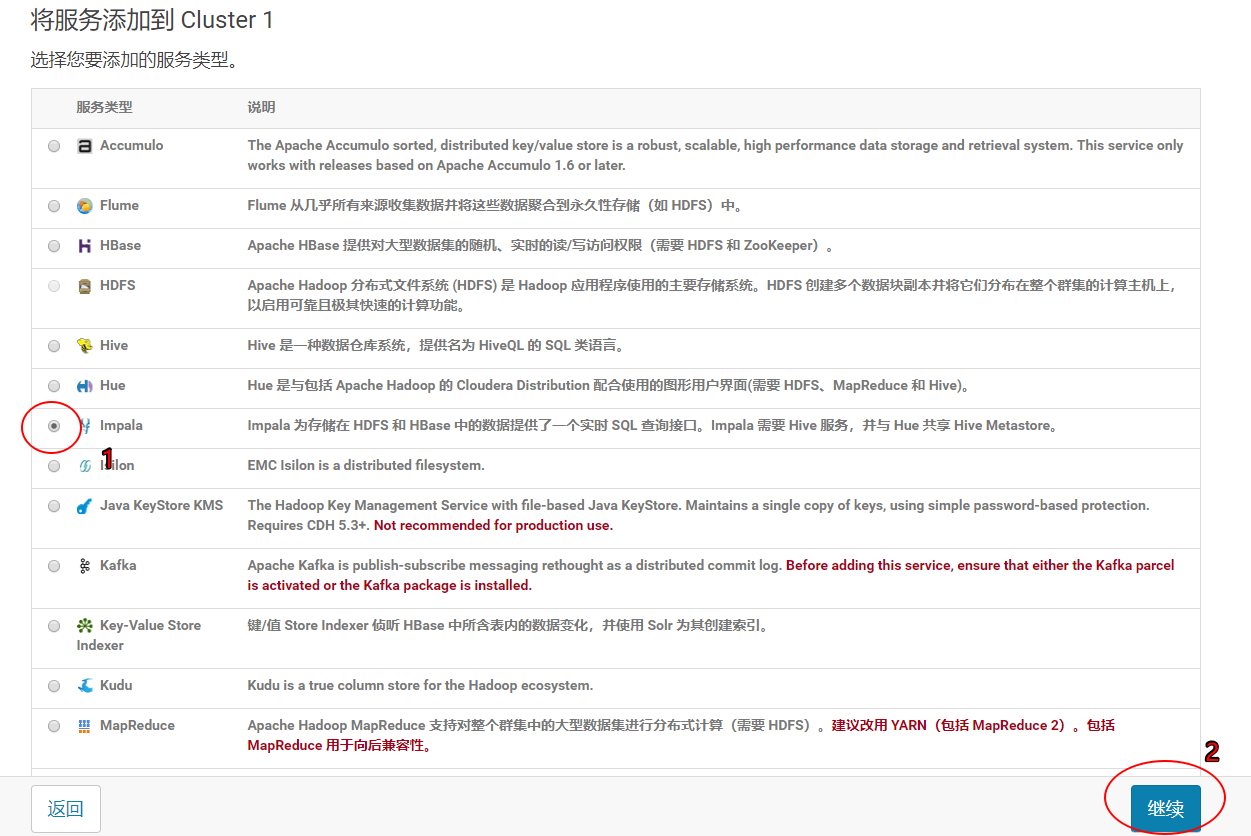
3.4.3 角色分配
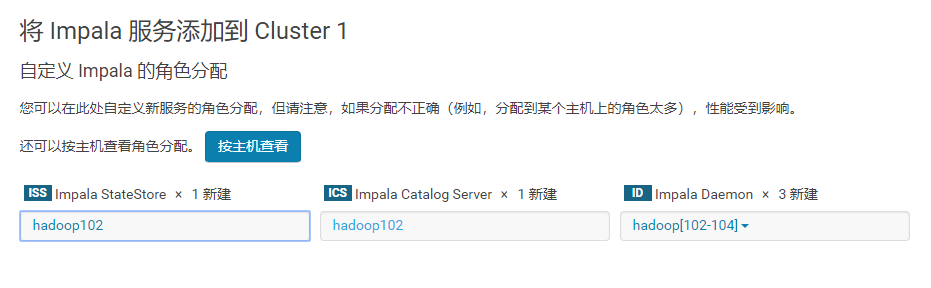
注意:最好将StateStore和CataLog Sever单独部署在同一节点上。
3.4.4 配置Impala

3.4.5 启动Impala
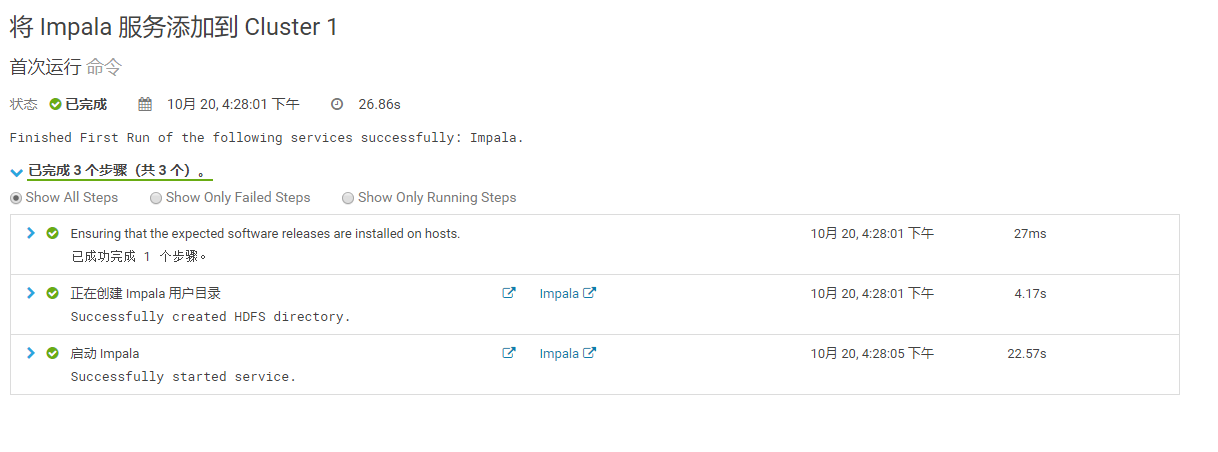
3.4.6 安装成功

3.4.7 配置Hue支持Impala
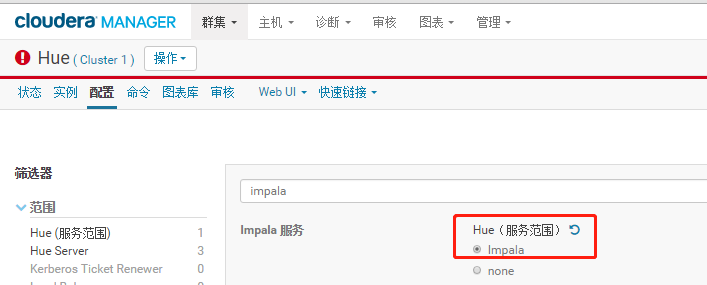
3.5 Impala基于Hue查询
3.5.1 打开Hue
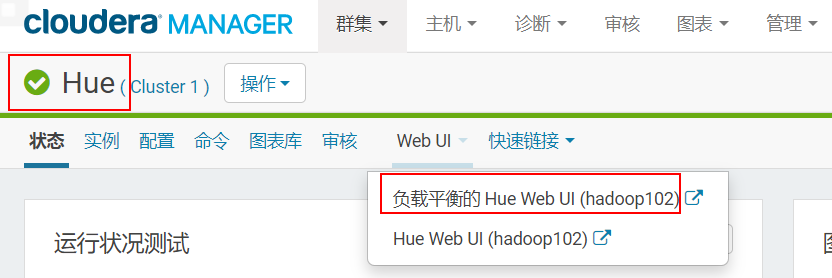
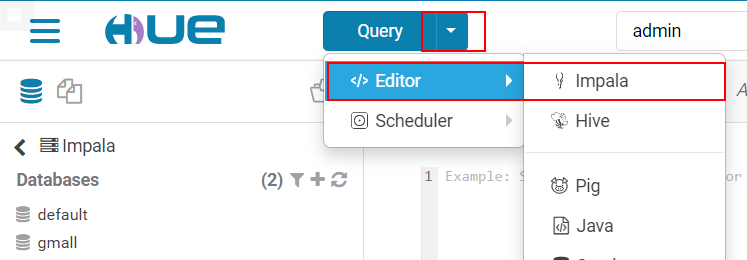
3.5.2 进入impala查询
第4章 实时模块安装之Spark升级
在CDH5.16.2集群中,默认安装的Spark是1.6版本,这里需要将其升级为Spark2.4版本。经查阅官方文档,发现Spark1.6和2.x是可以并行安装的,也就是说可以不用删除默认的1.6版本,可以直接安装2.x版本,它们各自用的端口也是不一样的。
Cloudera发布Apache Spark 2概述(可以在这里面找到安装方法和parcel包的仓库)
cloudera的官网可以下载相关的parcel 的离线安装包:
https://www.cloudera.com/documentation/spark2/latest/topics/spark2_installing.html
Cloudera Manager版本的介绍:
https://www.cloudera.com/documentation/enterprise/latest/topics/cm_ig_parcels.html#cmug_topic_7_11_5__section
4.1 Spark升级过程
4.1.1 离线包下载
1)所需软件:http://archive.cloudera.com/spark2/csd/
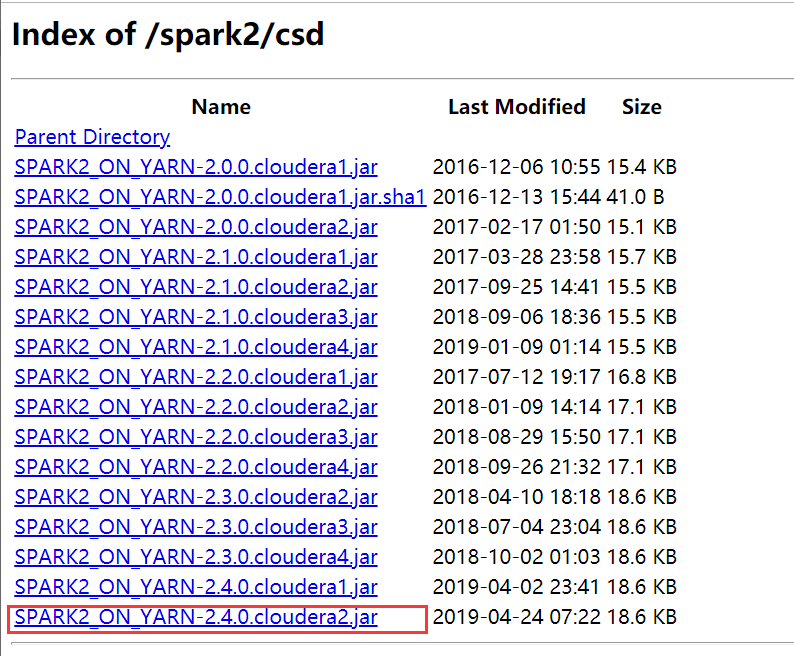
2)Parcels 包的下载地址:http://archive.cloudera.com/spark2/parcels/2.4.0.cloudera2/
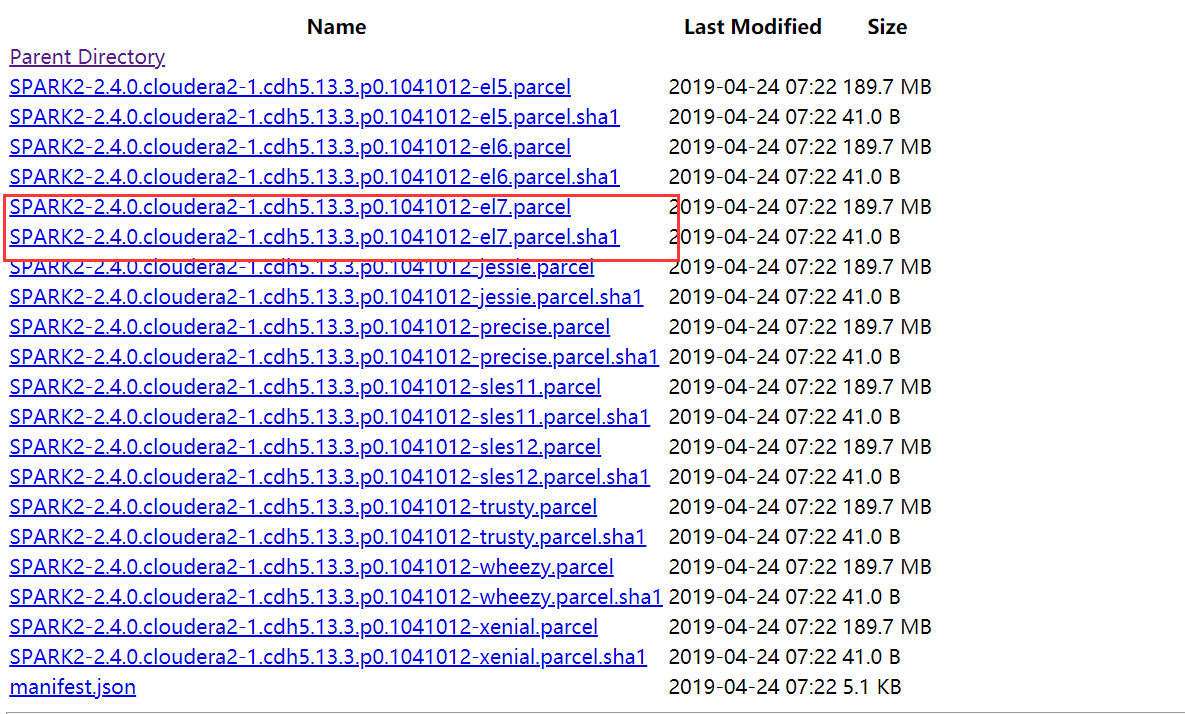
4.1.2 离线包上传
1)上传文件SPARK2_ON_YARN-2.4.0.cloudera2.jar到/opt/cloudera/csd/下面
2)上传文件SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel和SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel.sha1 到/opt/cloudera/parcel-repo/
3)将SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel.sha1重命名为SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel.sha
[root@hadoop102 parcel-repo]# mv SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel.sha1 SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel.sha
4.2 页面操作
4.2.1 更新Parcel
在cm首页点击Parcel,再点击检查新Parcel
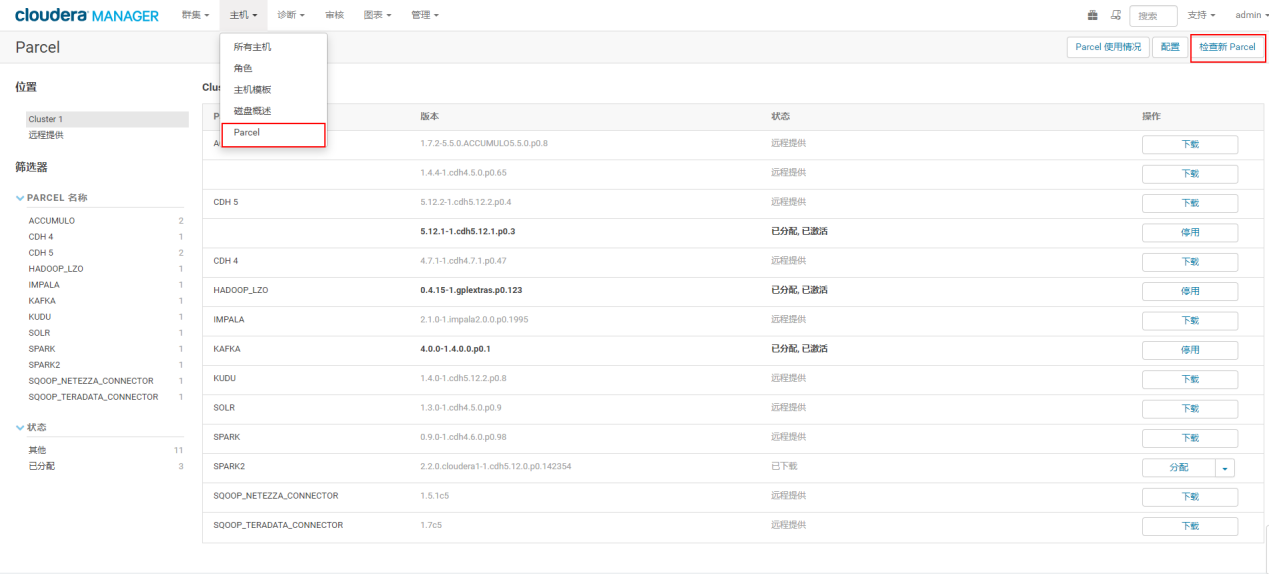
4.2.2 点击分配
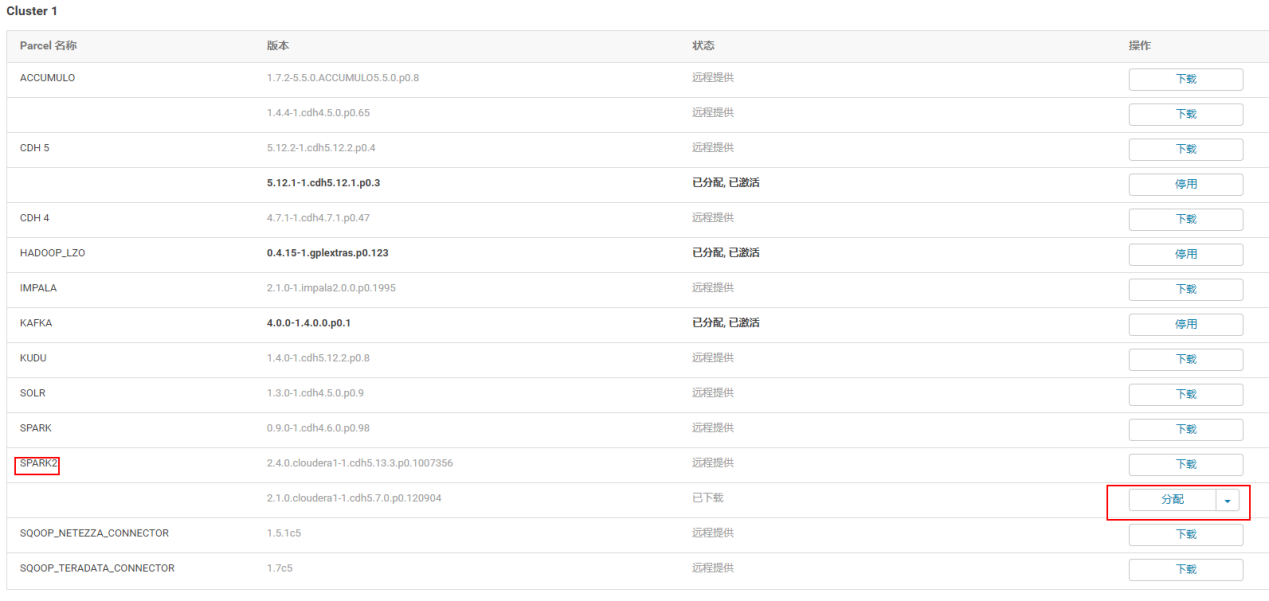
4.2.3 点击激活
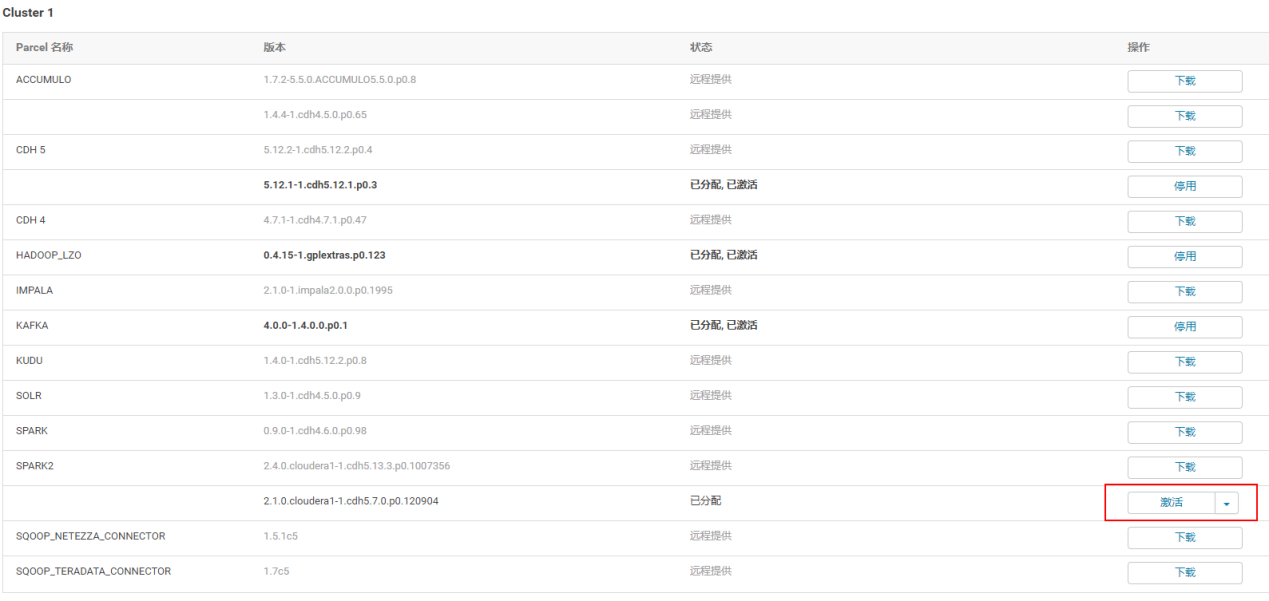
4.2.4 回到首页点击添加服务
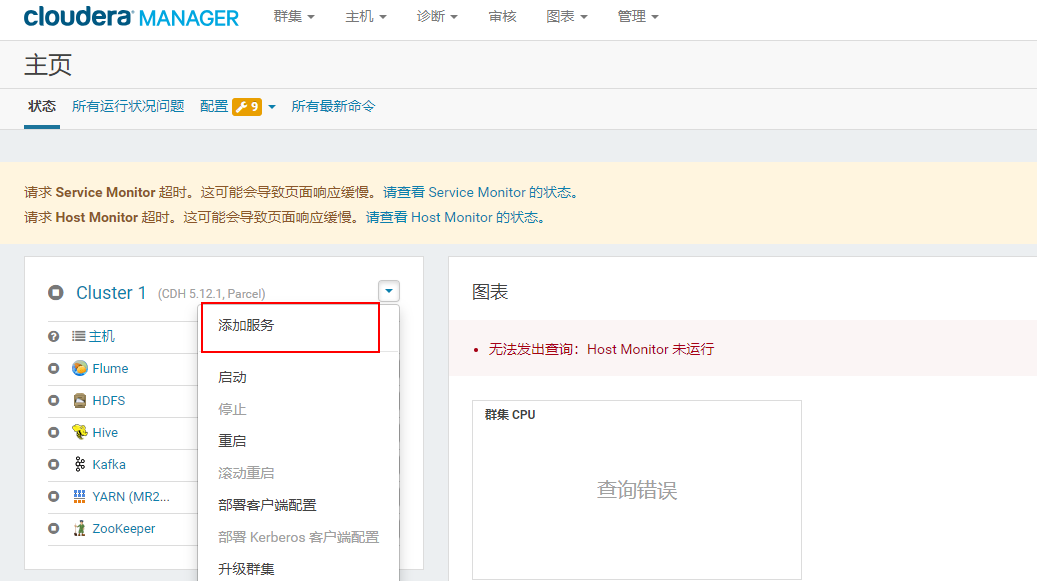
4.2.5 点击Spark2继续
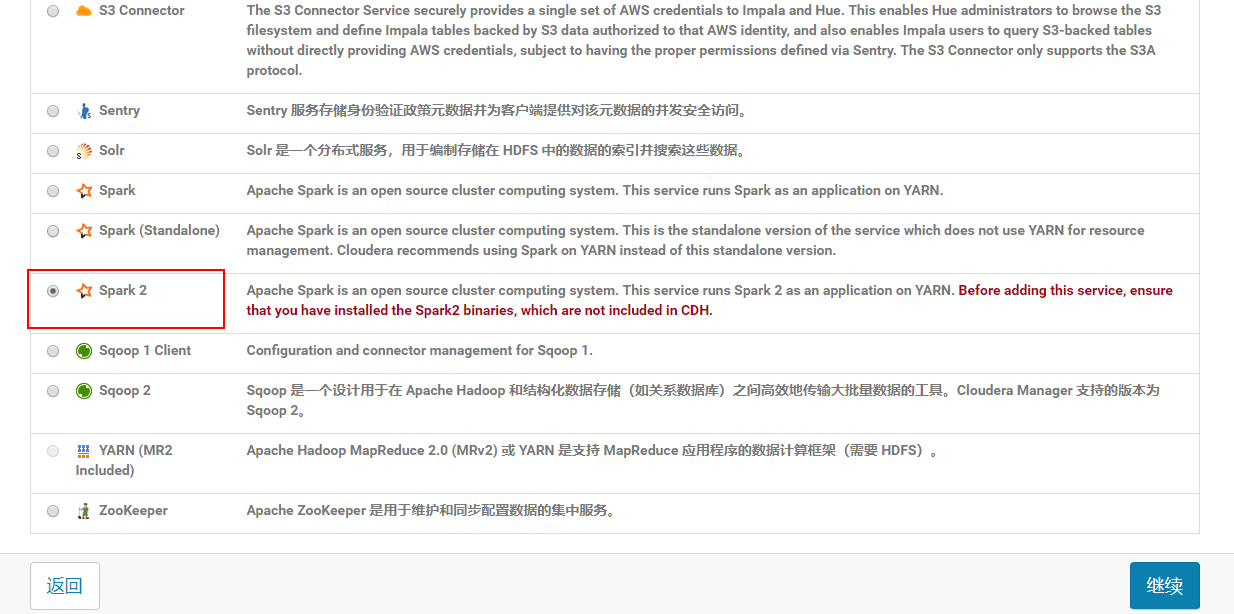
如果没有Spark2,则重启server:
[root@hadoop102 ~]#
/opt/module/cm/cm-5.16.2/etc/init.d/cloudera-scm-server restart
4.2.6 选择一组依赖关系
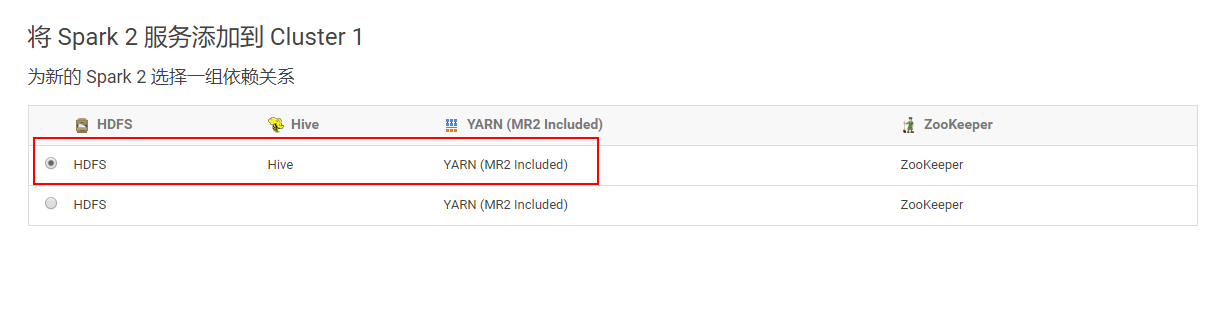
4.2.7 角色分配
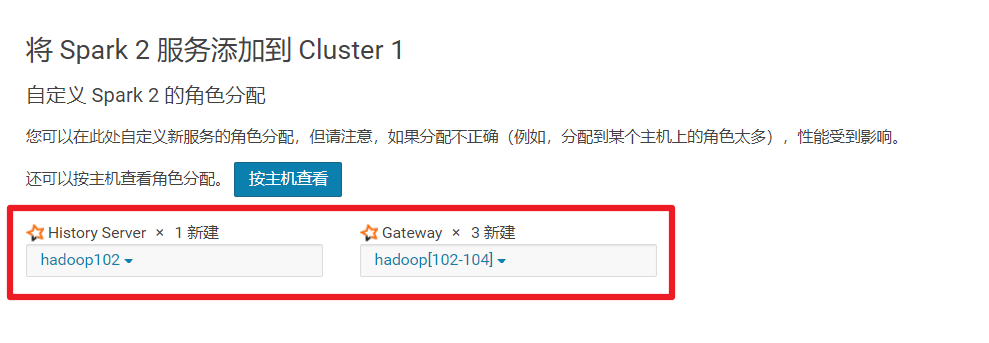
需要选择Gateway(客户端) 可以都选
4.2.8 部署并启动
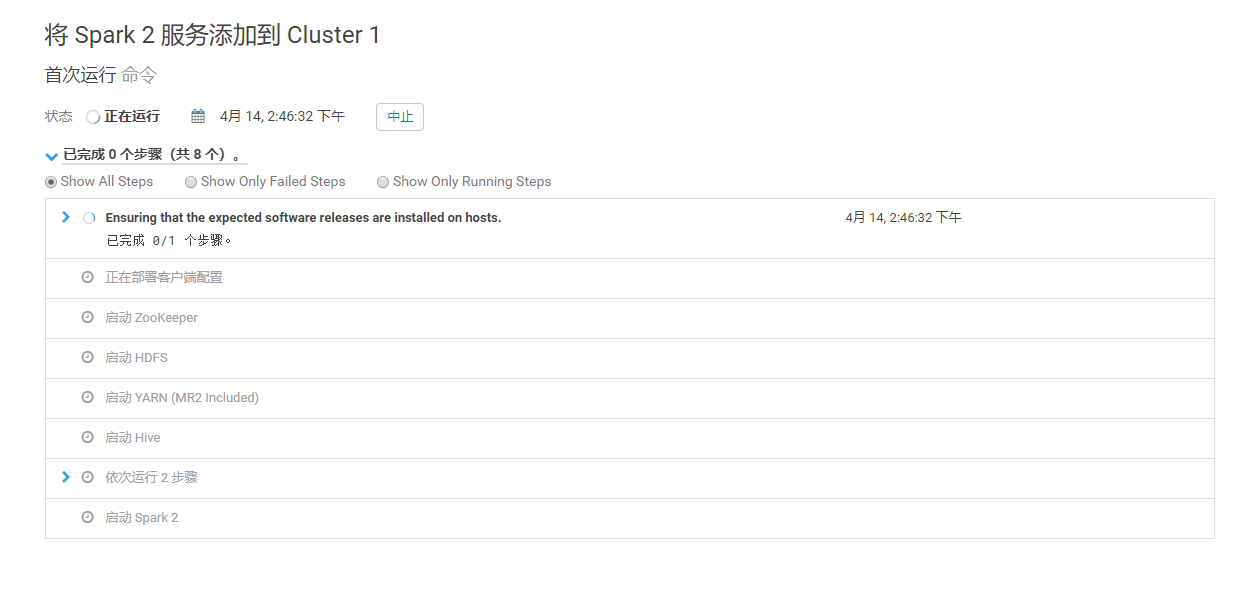
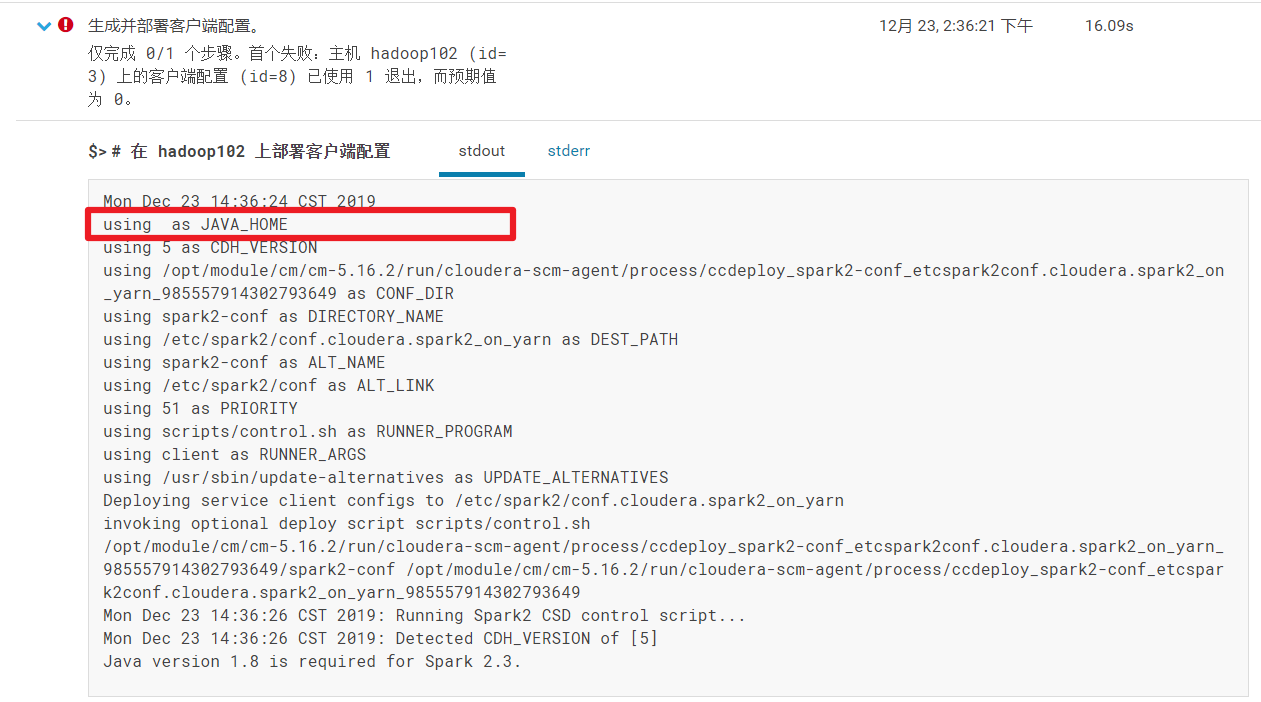
注意:这里我报了一个错:主机 hadoop102 (id=3) 上的客户端配置 (id=8) 已使用 1 退出,而预期值为 0。
- 问题原因:最后找到原因是因为CM安装Spark不会去环境变量去找Java,需要将Java路径添加到CM配置文件
- 解决办法1(需要重启cdh):
找到hadoop102、hadoop103、hadoop104三台机器的配置,配置java主目录

3)解决方法2(无需重启cdh):
查看/opt/module/cm/cm-5.16.2/lib64/cmf/service/common/cloudera-config.sh
找到java8的home目录,会发现cdh不会使用系统默认的JAVA_HOME环境变量,而是依照bigtop进行管理,因此我们需要在指定的/usr/java/default目录下安装jdk。当然我们已经在/opt/module/jdk1.8.0_144下安装了jdk,因此创建一个连接过去即可
[root@hadoop102 ~]# mkdir /usr/java
[root@hadoop102 ~]# ln -s /opt/module/jdk1.8.0_144/ /usr/java/default
[root@hadoop103 ~]# mkdir /usr/java
[root@hadoop103 ~]# ln -s /opt/module/jdk1.8.0_144/ /usr/java/default
[root@hadoop104 ~]# mkdir /usr/java
[root@hadoop104 ~]# ln -s /opt/module/jdk1.8.0_144/ /usr/java/default
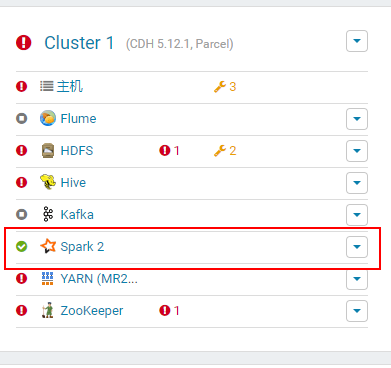
4.2.9 命令行查看命令