
Prometheus&Grafana监控&睿象云入门教程2
Prometheus&Grafana监控入门教程2
Prometheus和Flink集成
Flink 提供的 Metrics 可以在 Flink 内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的 Task 日志。比如作业很大或者有很多作业的情况下,该如何处理?此时 Metrics 可以很好的帮助开发人员了解作业的当前状况。
从Flink的源码结构我们可以看到,Flink官方支持Prometheus,并且提供了对接Prometheus的jar包,很方便就可以集成。

拷贝jar包
- 拷贝新的flink目录,flink-prometheus
- 将flink-metrics-prometheus-1.12.0.jar拷贝到 <flink_home>/lib目录下
[daydayup@hadoop202 flink-prometheus]$ cp /opt/module/flink-prometheus/plugins/metrics-prometheus/flink-metrics-prometheus-1.12.0.jar /opt/module/flink-prometheus/lib/
Flink 的 Classpath 位于lib目录下,所以插件的jar包需要放到该目录下
修改Flink配置
进入到Flink的conf目录,修改flink-conf.yaml
[daydayup@hadoop202 conf]$ vim flink-conf.yaml
添加如下配置:
##### 与Prometheus集成配置 #####
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
# PushGateway的主机名与端口号
metrics.reporter.promgateway.host: hadoop202
metrics.reporter.promgateway.port: 9091
# Flink metric在前端展示的标签(前缀)与随机后缀
metrics.reporter.promgateway.jobName: flink-metrics-ppg
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
metrics.reporter.promgateway.interval: 30 SECONDS
为了运行测试程序,启动netcat
[daydayup@hadoop202 sbin]$ nc -lk 9999
启动hdfs、yarn,提交flink任务到yarn上
[daydayup@hadoop202 flink-prometheus]$ bin/flink run -t yarn-per-job -c com.daydayup.flink.chapter02.Flink03_WordCount_UnboundStream ./flink-base-1.0-SNAPSHOT-jar-with-dependencies.jar
可以通过8088跳到flinkUI的job页面,查看指标统计
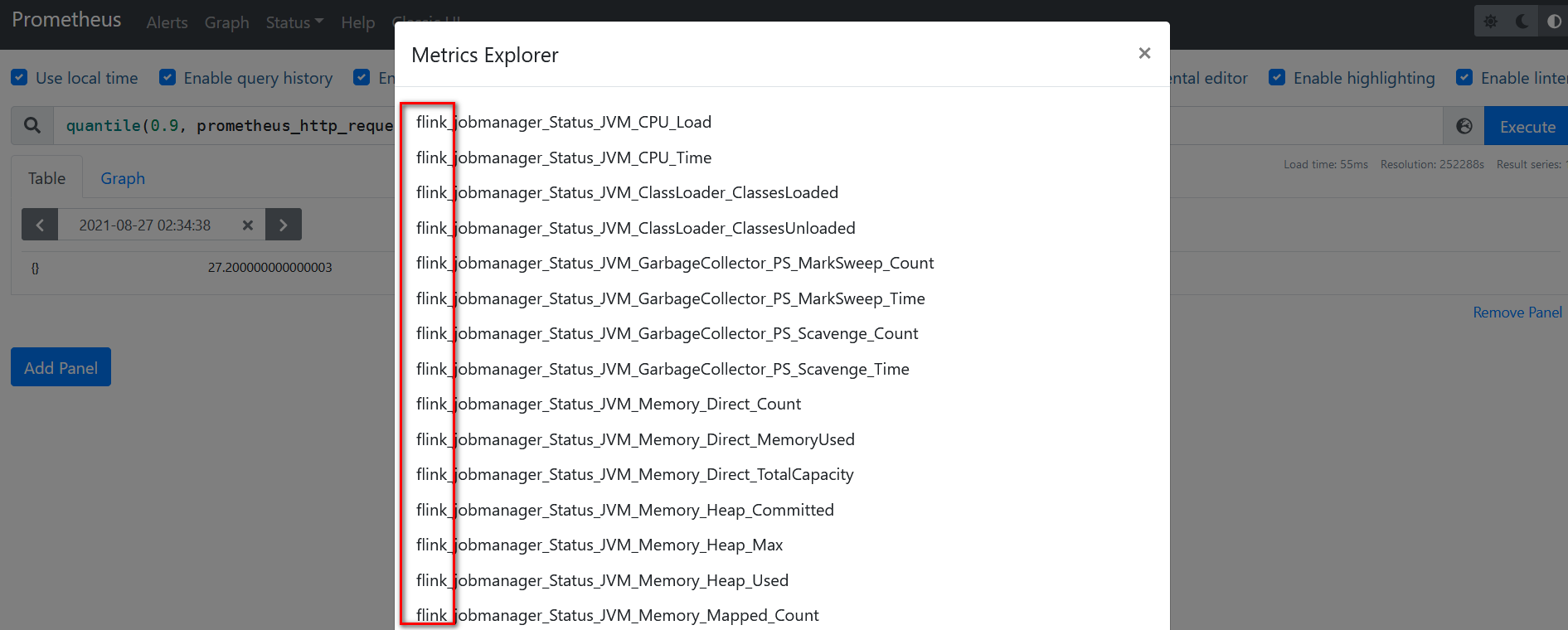
刷新Prometheus页面,如果有flink指标,集成成功
Prometheus和Grafana集成
grafana 是一款采用Go语言编写的开源应用,主要用于大规模指标数据的可视化展现,是网络架构和应用分析中最流行的时序数据展示工具,目前已经支持绝大部分常用的时序数据库。下载地址:https://grafana.com/grafana/download
上传并解压
- 将grafana-8.1.2.linux-amd64.tar.gz上传至/opt/software/目录下,解压:
[daydayup@hadoop202 software]$ tar -zxvf grafana-enterprise-8.1.2.linux-amd64.tar.gz -C /opt/module/
启动Grafana
[daydayup@hadoop202 grafana-8.1.2]$ nohup ./bin/grafana-server web > ./grafana.log 2>&1 &
- 打开web:http://hadoop202:3000,默认用户名和密码:admin
添加数据源Prometheus
点击配置,点击Data Sources:
点击添加按钮:
找到Prometheus,点击Select
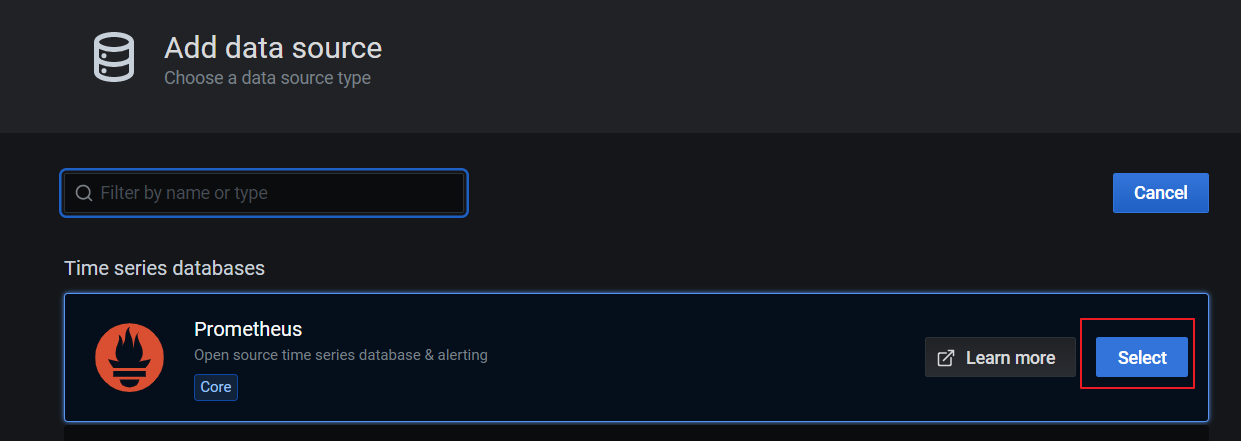
配置Prometheus Server地址:
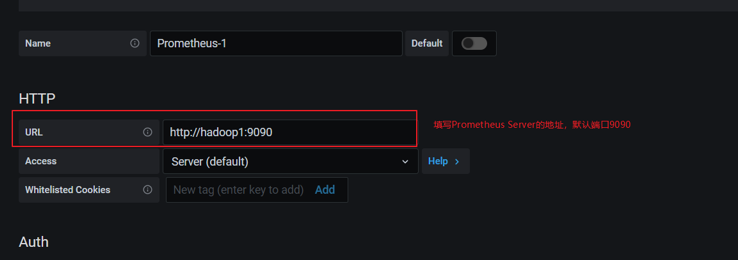
点击下方的Save&Test:
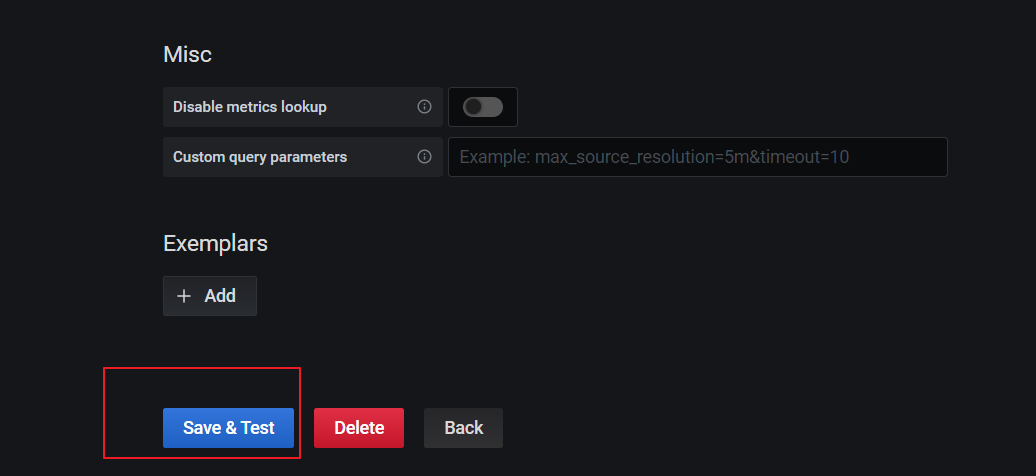
出现绿色的提示框,表示与Prometheus正常联通:

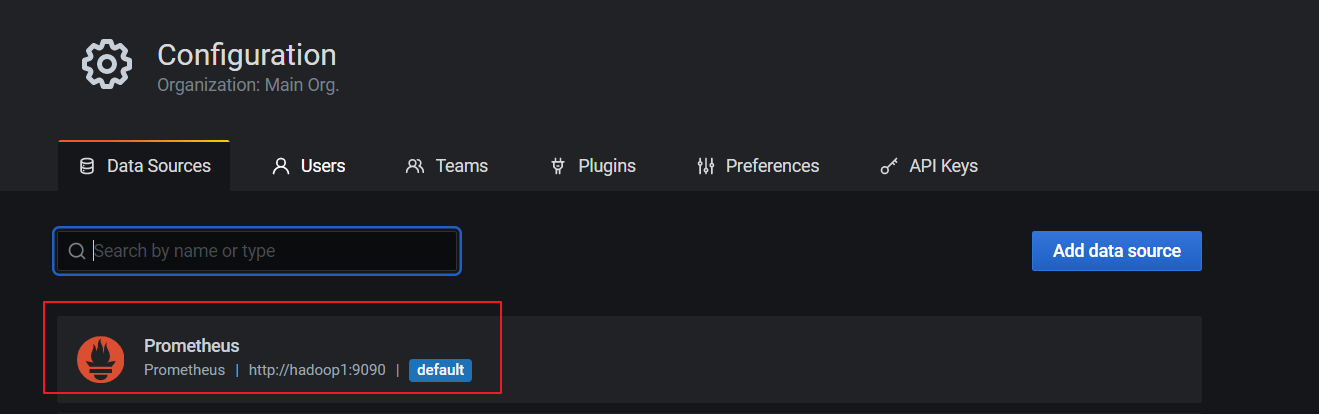
点击Back返回即可,可以看到Data Sources页面,出现了添加的Prometheus:
手动创建仪表盘Dashboard
点击左边栏的 “+”号,选择Dashboard:
添加新的仪表板,点击Add an empty panel:
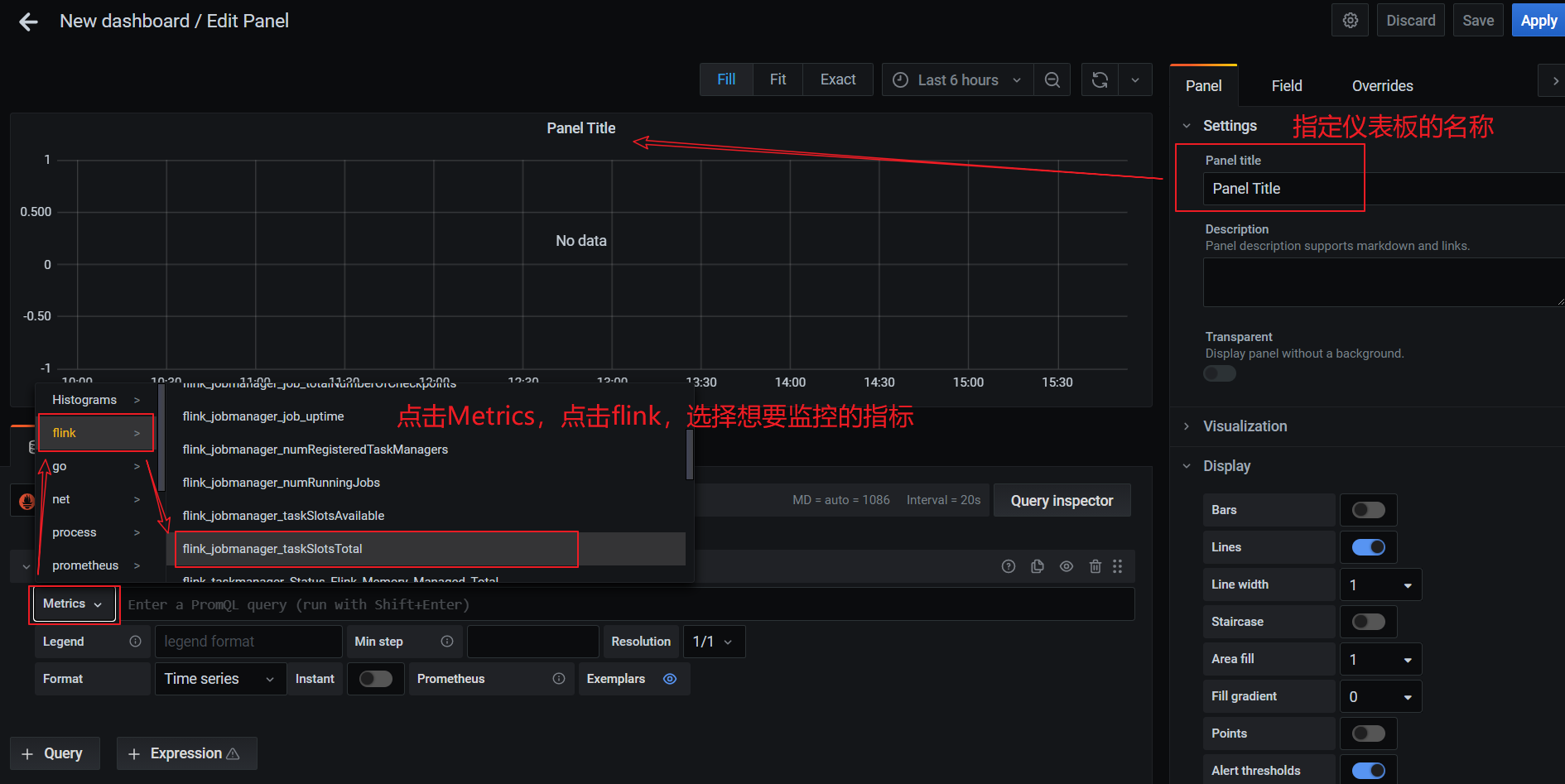
配置仪表板监控项:
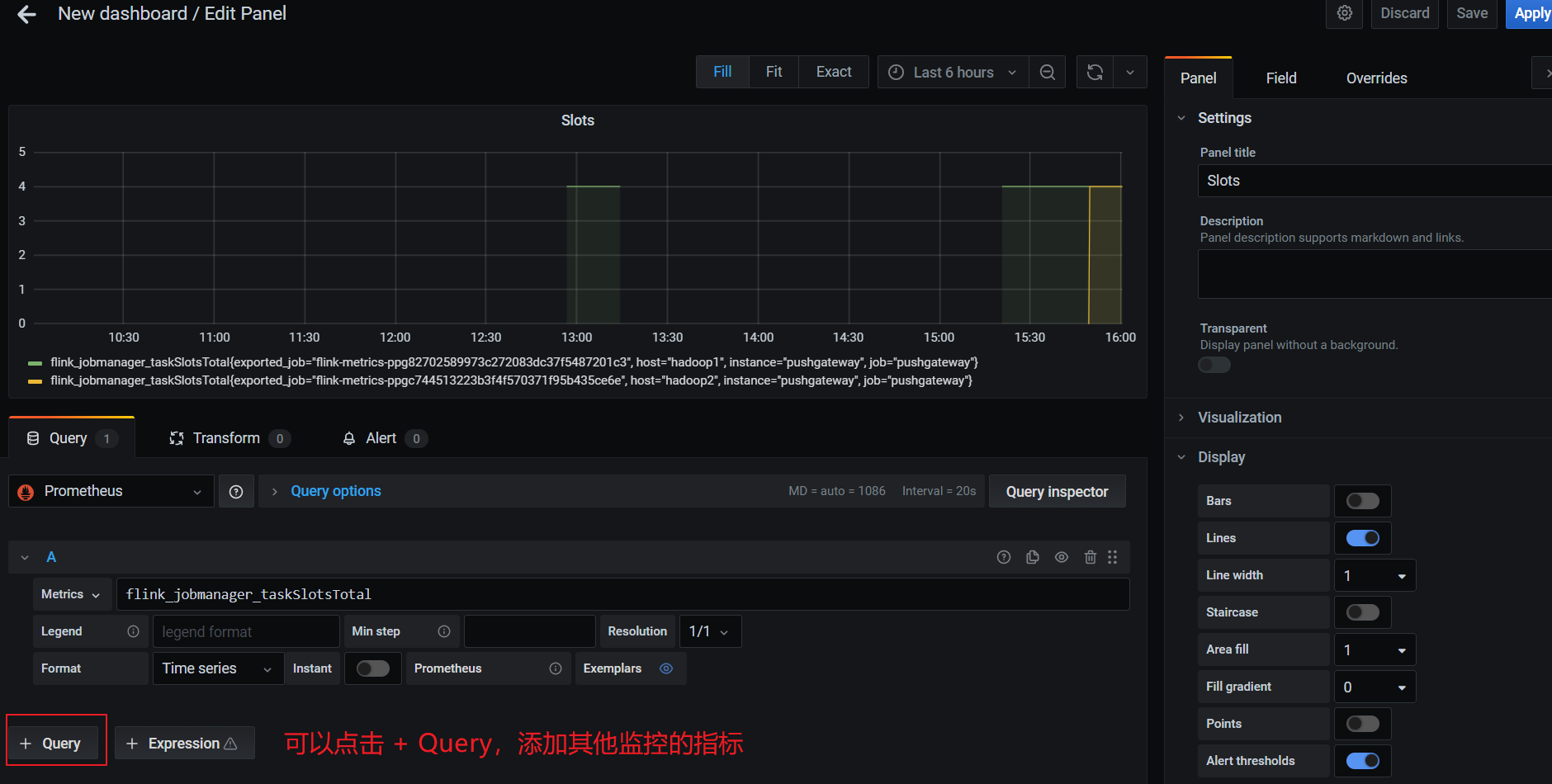
一个仪表板可以配置多个监控项,添加其他监控项:
配置新的监控项:
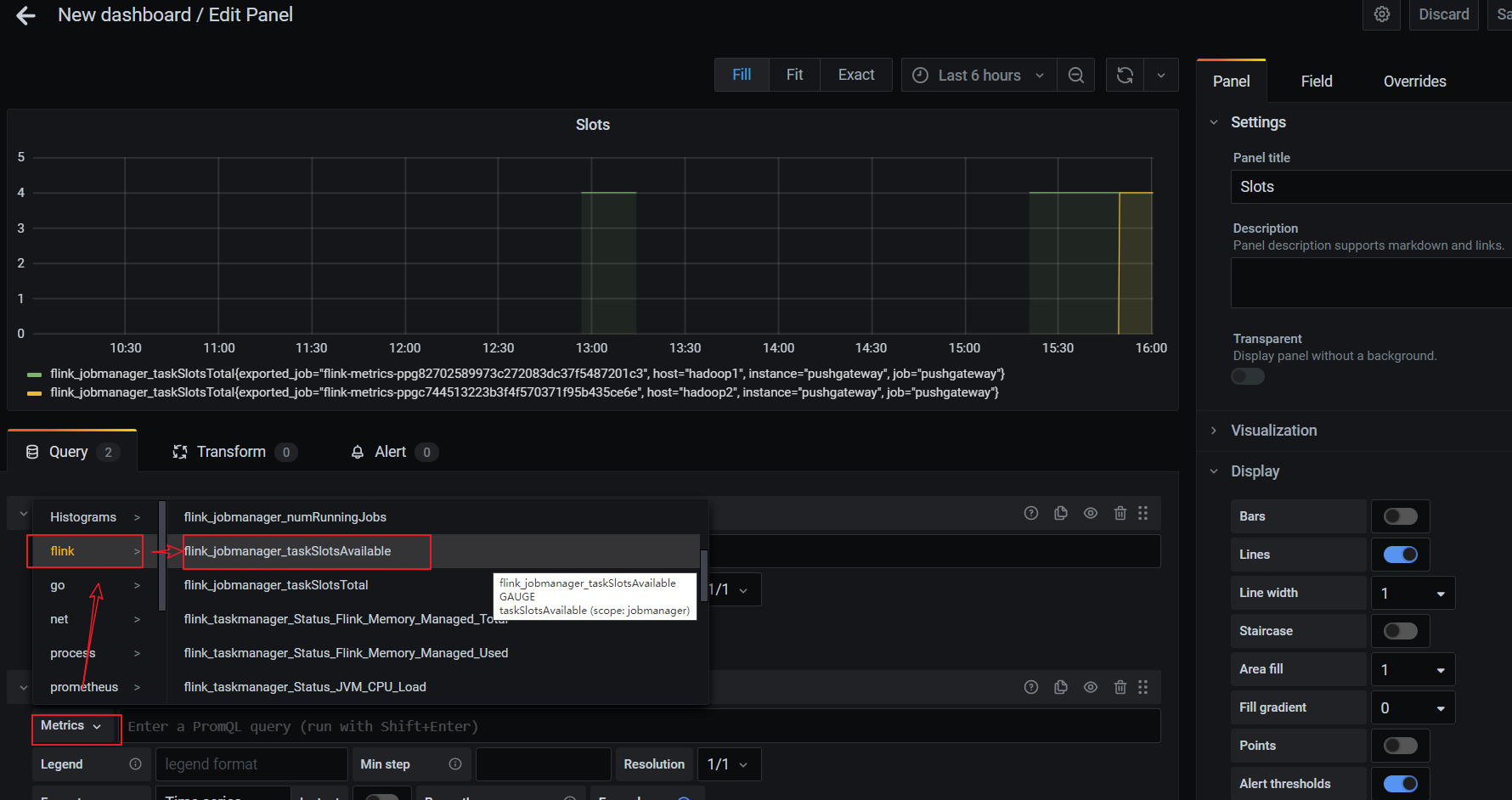
直接添加Flink模板
手动一个个添加Dashboard比较繁琐,Grafana社区鼓励用户分享Dashboard,通过https://grafana.com/dashboards网站,可以找到大量可直接使用的Dashboard模板。
Grafana中所有的Dashboard通过JSON进行共享,下载并且导入这些JSON文件,就可以直接使用这些已经定义好的Dashboard:
进入官网,搜索Flink模板:
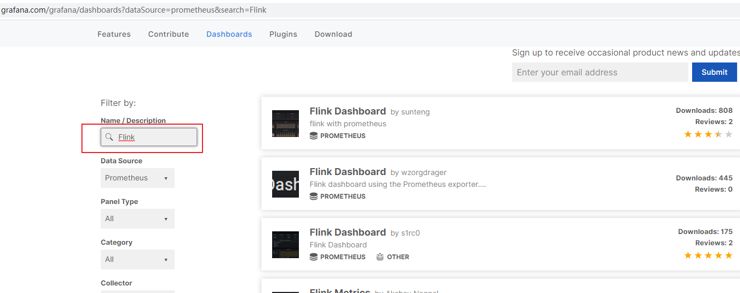
选择自己喜欢的模板(800+下载的这个模板相对指标较多)
选中跳转页面后,点击 Download JSON:
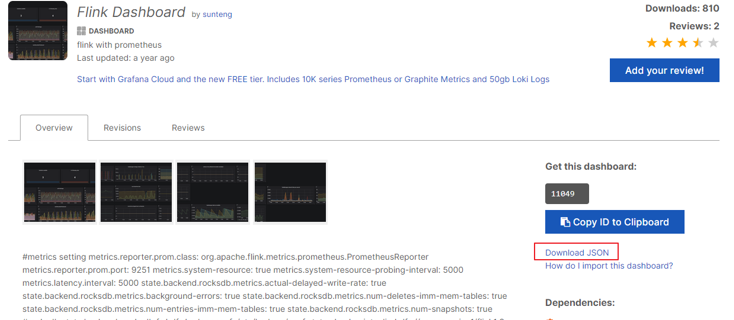
点击Grafana界面左侧 ”+”号,选择import:
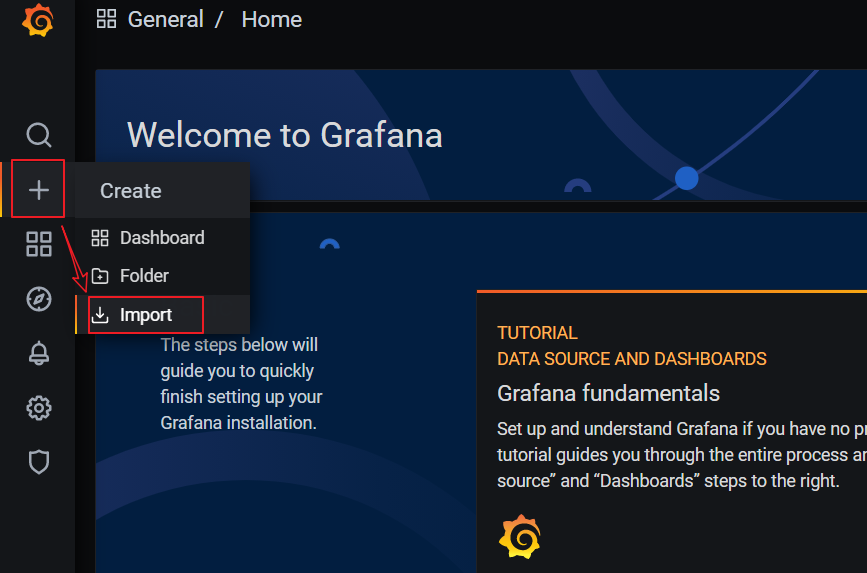
上传JSON文件:
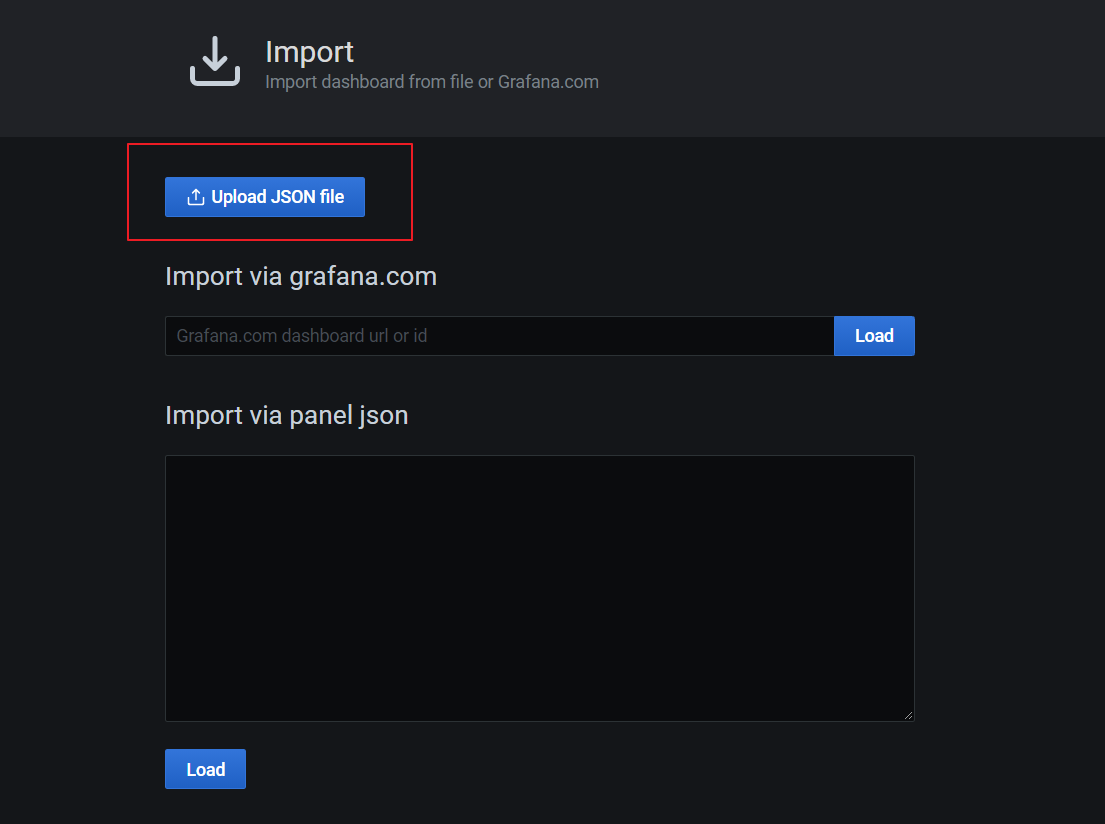
配置模板信息:
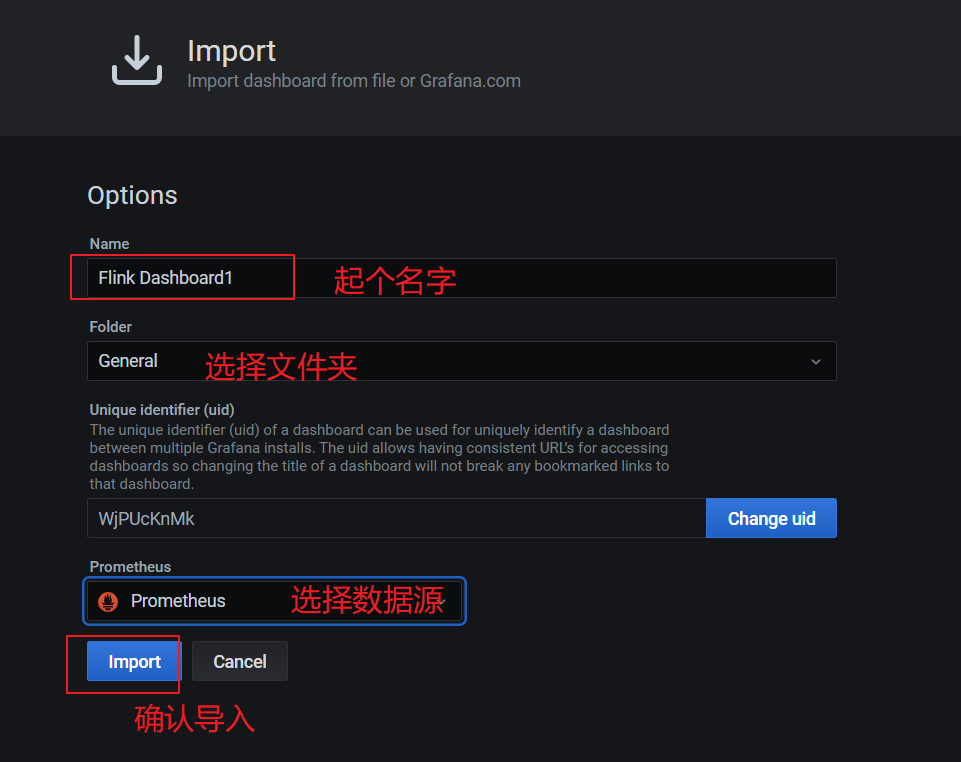
导入完,在首页即可看见添加的仪表盘,点击进去查看:
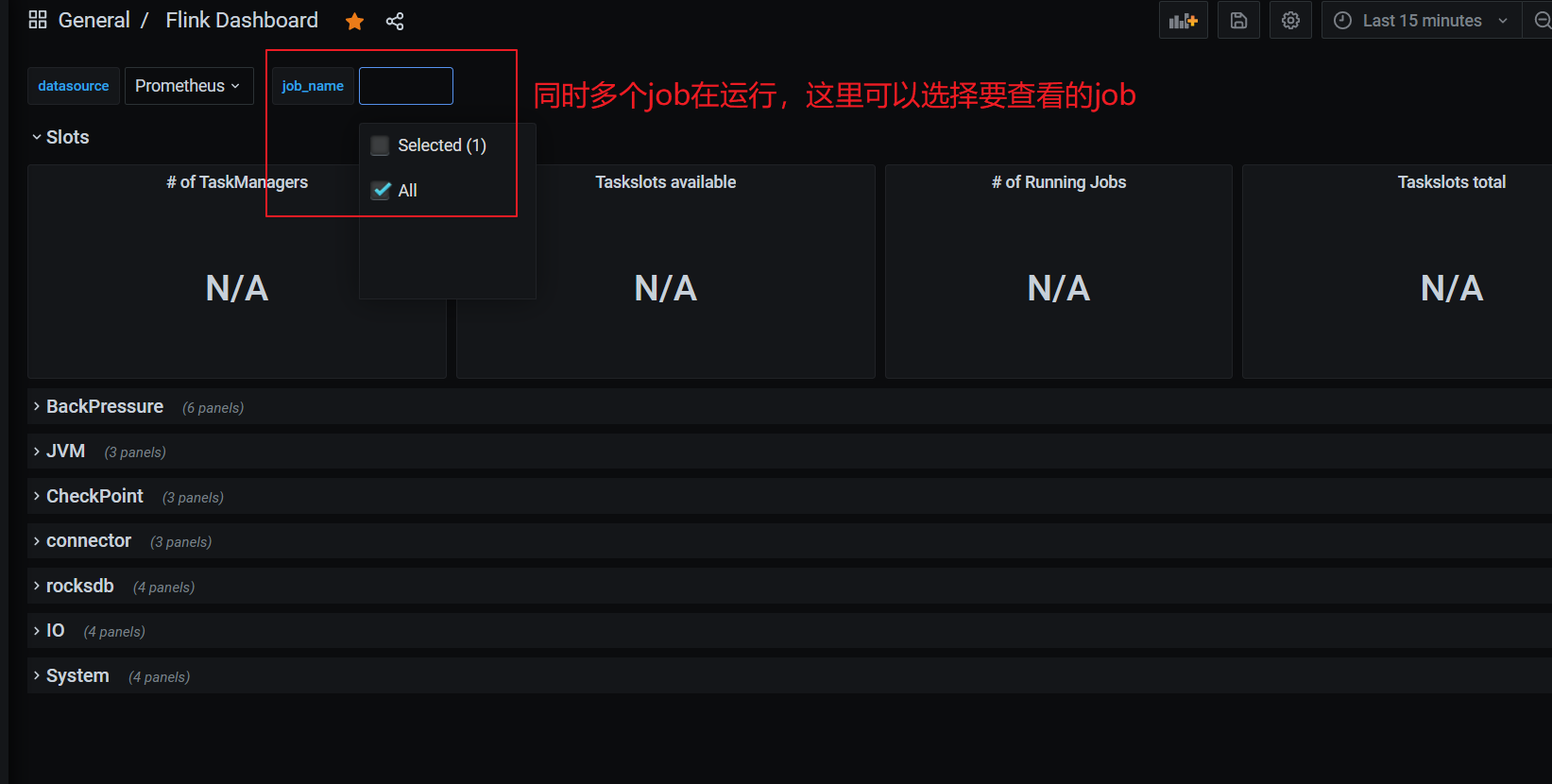
正常提交job,即可在grafana看到相关监控项的情况。
注意:代码里env.execute(“作业名”),最好指定不同的作业名用于区分,不指定会使用默认的作业名:Flink Streaming Job,在Grafana页面就无法区分不同job!!!
添加Node Exporter模板
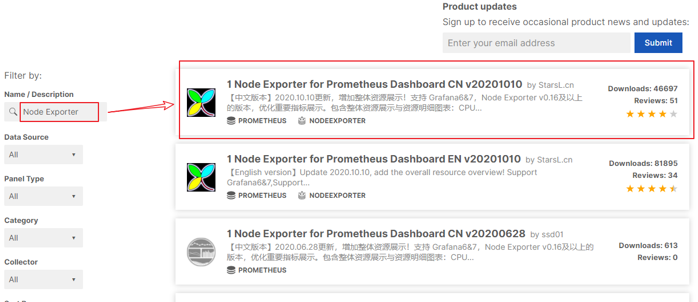
同5.5,进入https://grafana.com/dashboards 页面,
- 搜索Node Exporter,选择下载量最高的中文版本:
- 下载模板json文件
- 在Grafana中导入模板:
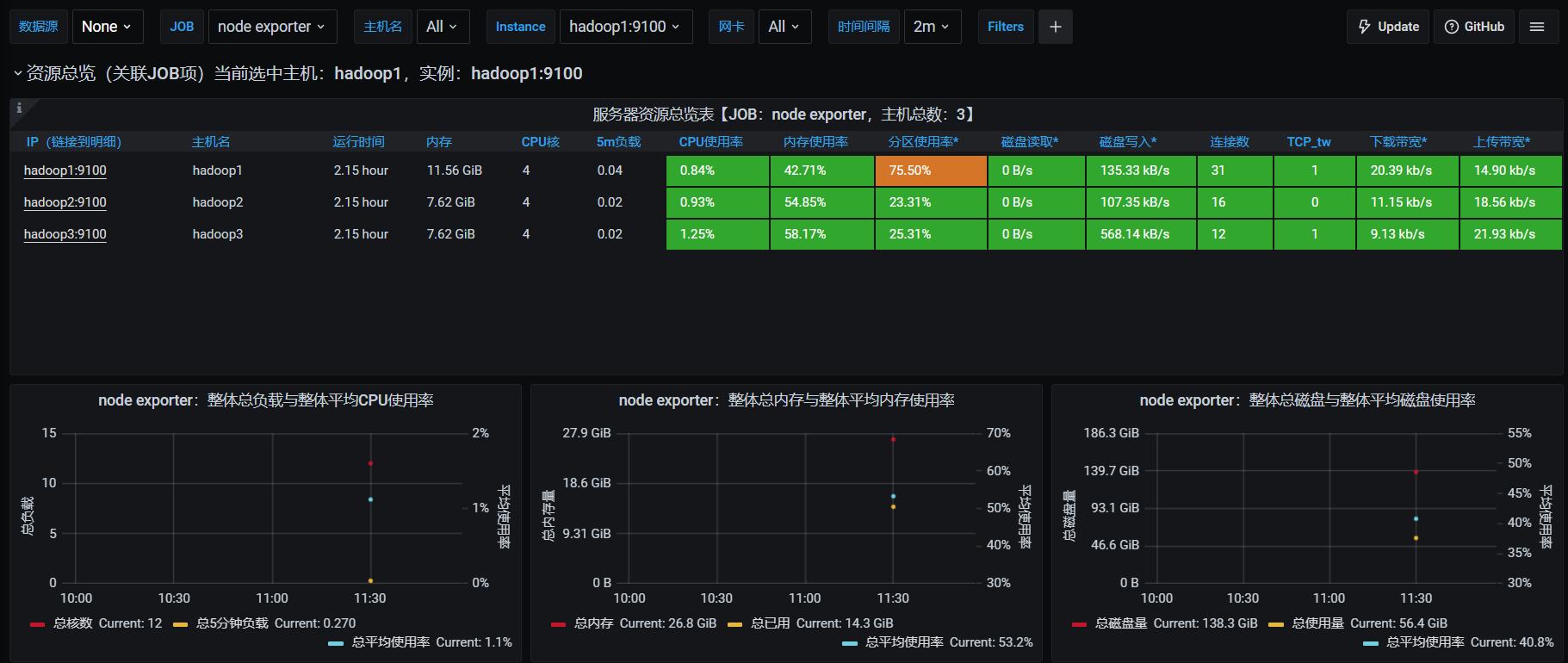
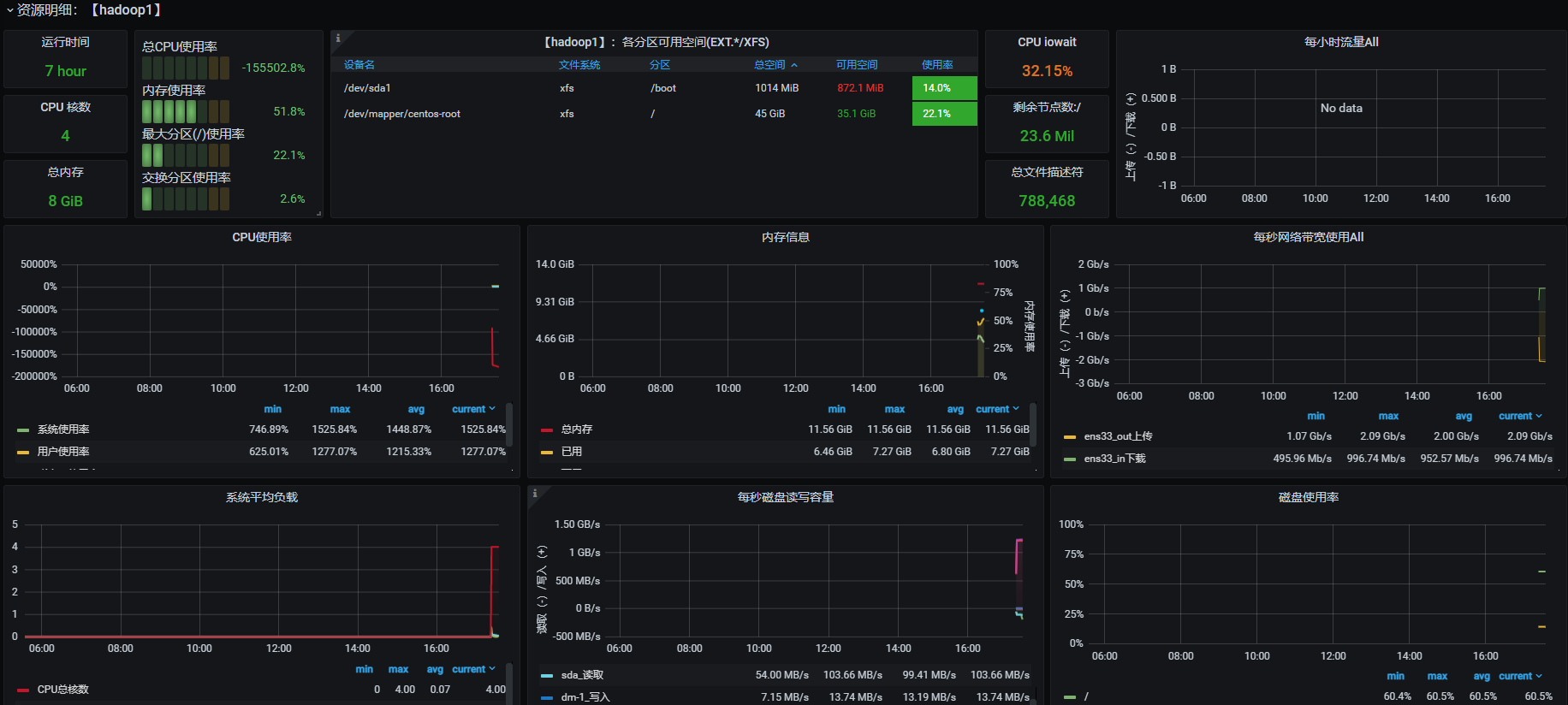
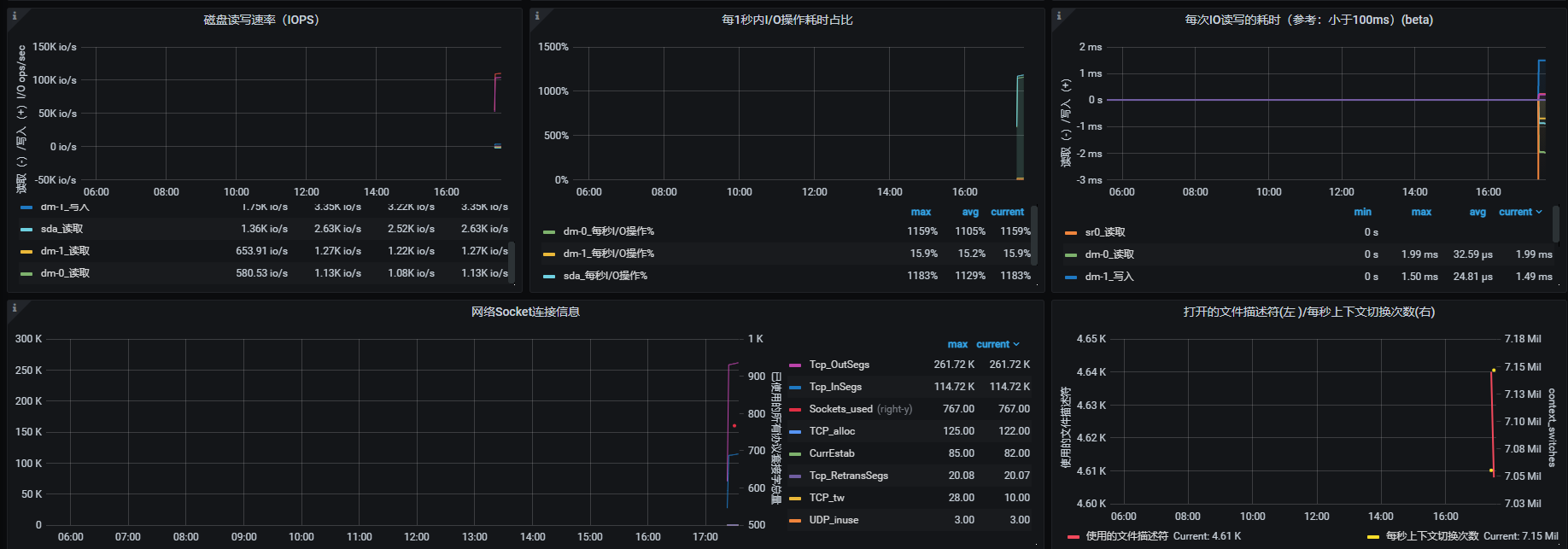
- 欣赏酷炫又详细的监控页:
组件启停脚本
- 进入到/home/daydayup/bin目录下,创建脚本flink-monitor.sh
#!/bin/bash
case $1 in
"start"){
echo '----- 启动 prometheus -----'
nohup /opt/module/prometheus-2.29.1/prometheus --web.enable-admin-api --config.file=/opt/module/prometheus-2.29.1/prometheus.yml > /opt/module/prometheus-2.29.1/prometheus.log 2>&1 &
echo '----- 启动 pushgateway -----'
nohup /opt/module/pushgateway-1.4.1/pushgateway --web.listen-address :9091 > /opt/module/pushgateway-1.4.1/pushgateway.log 2>&1 &
echo '----- 启动 grafana -----'
nohup /opt/module/grafana-8.1.2/bin/grafana-server --homepath /opt/module/grafana-8.1.2 web > /opt/module/grafana-8.1.2/grafana.log 2>&1 &
};;
"stop"){
echo '----- 停止 grafana -----'
pgrep -f grafana | xargs kill
echo '----- 停止 pushgateway -----'
pgrep -f pushgateway | xargs kill
echo '----- 停止 prometheus -----'
pgrep -f prometheus | xargs kill
};;
esac
- 脚本添加执行权限
[daydayup@hadoop202 bin]$ chmod +x flink-monitor.sh
配置案例
任务失败监控
这一个指标监控主要是基于flink_jobmanager_job_uptime 这个指标进行了监控。原理是在job任务存活时,会按照配置metrics.reporter.promgateway.interval上报频率递增。基于这个特点,当任务失败后这个数值就不会改变,就能监控到任务失败。
- 添加监控项:
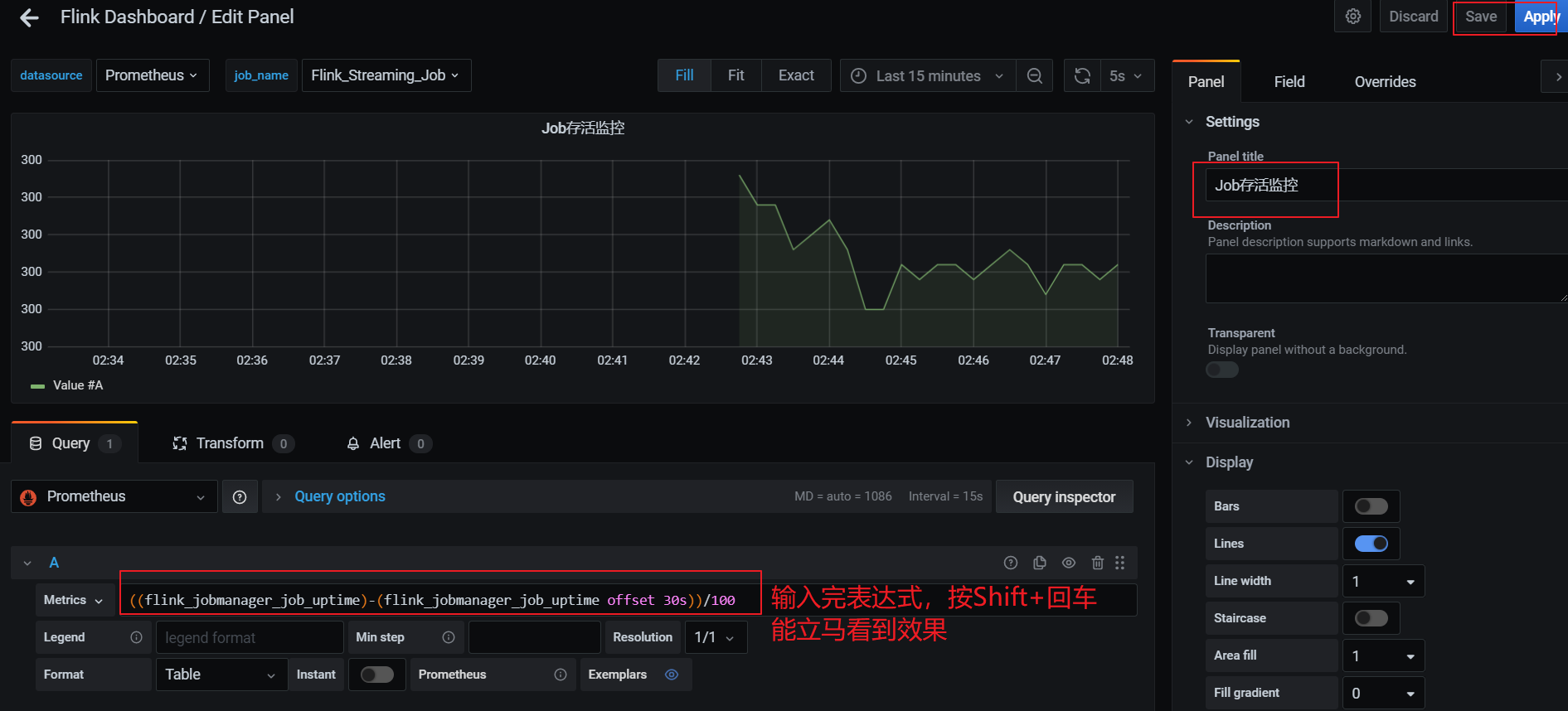
30秒为数据上报到 promgateway 频率,除以100为了数据好看,当job任务失败后数 flink上报的promgateway 的 flink_jobmanager_job_uptime指标值不会变化。((flink_jobmanager_job_uptime)-(flink_jobmanager_job_uptime offset 30s))/100 值就会是0,可以配置告警。
- 配置告警
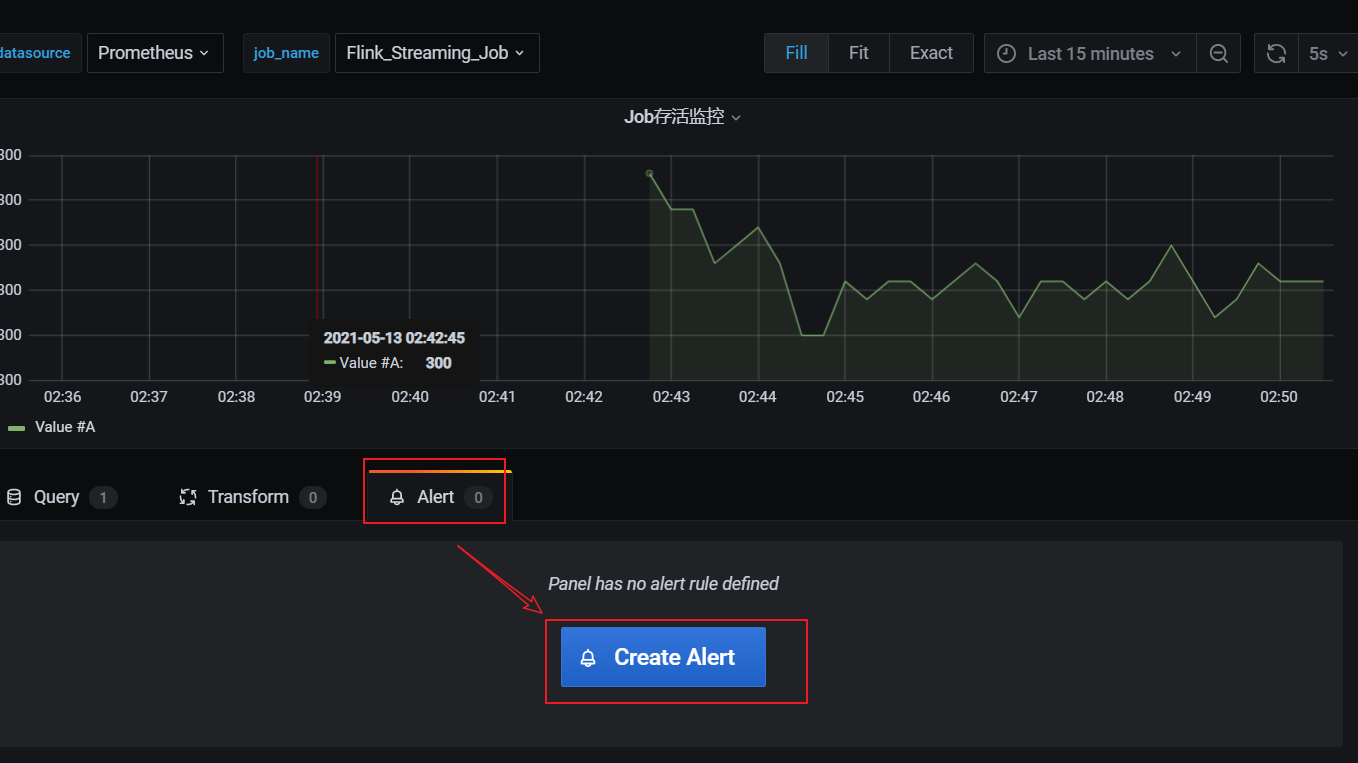
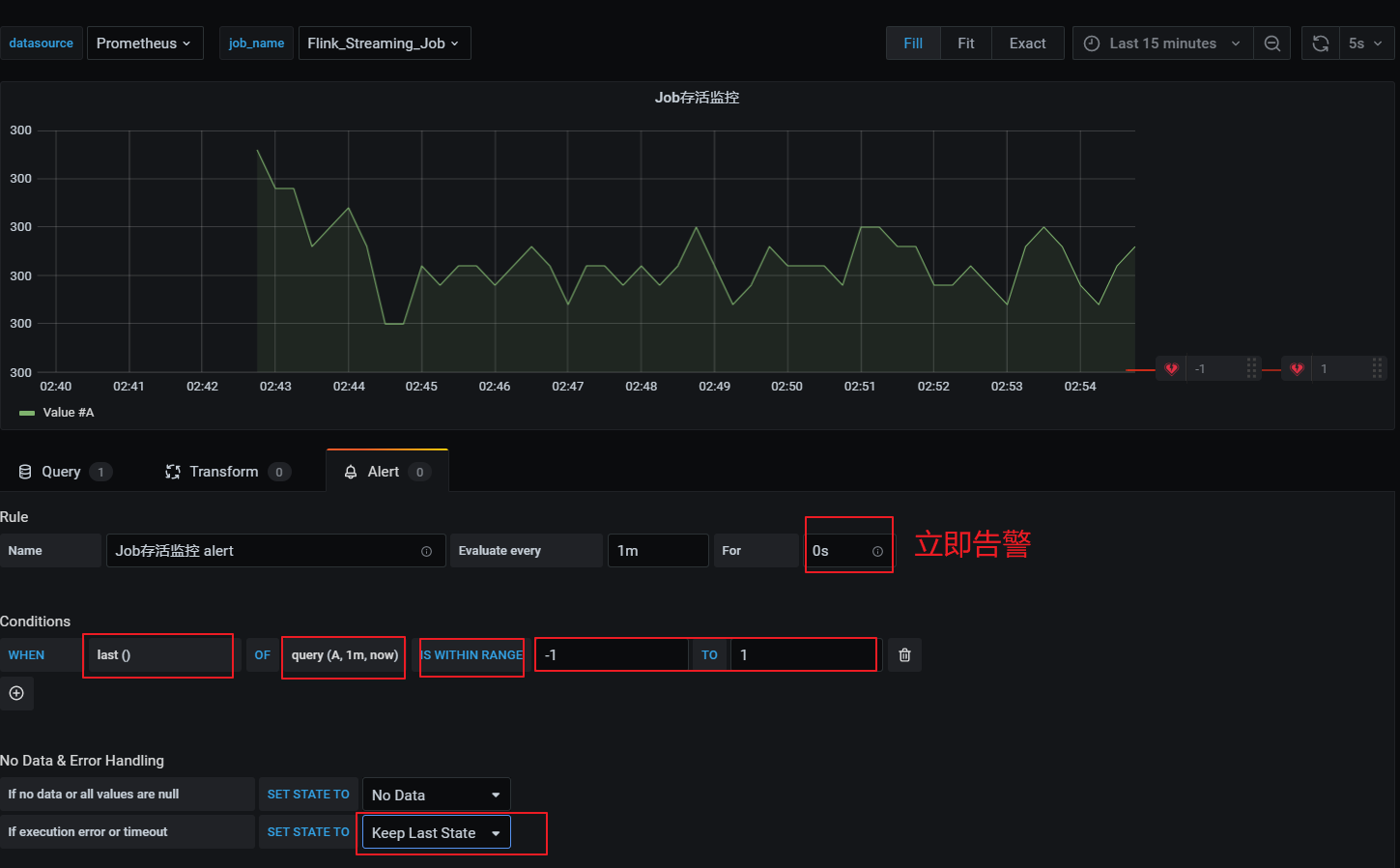
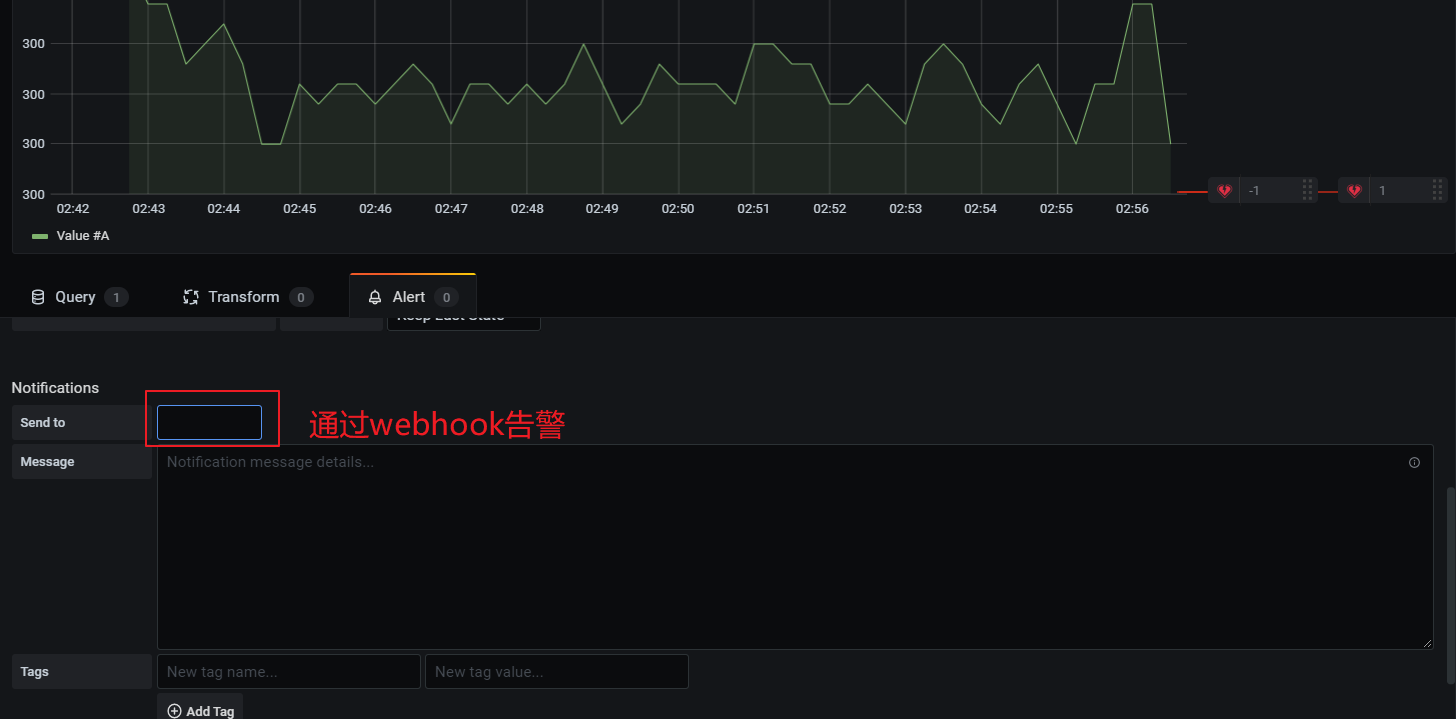
在告警通知中可以邮件和webhook,webhook可以调用相关接口,执行一些动作。webhook需要提前配置,在这里配置告警时就可以直接引入。
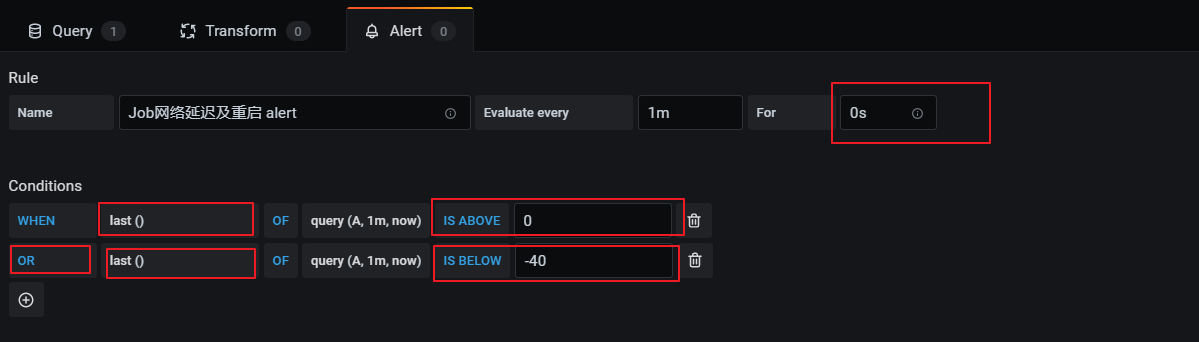
网络延时或任务重启监控
这个告警也是基于flink_jobmanager_job_uptime 指标,在出现网络延时或者重启后进行监控通知,监控指标如下:
((flink_jobmanager_job_uptime offset 30s)-(flink_jobmanager_job_uptime))/1000
1)延时会导致值突然小于-30(正常情况为-30)
2)重启会导致flink_jobmanager_job_uptime指标清零从新从0值上报,导致查询公式值突然大于0(正常情况为-30)
- 添加监控项
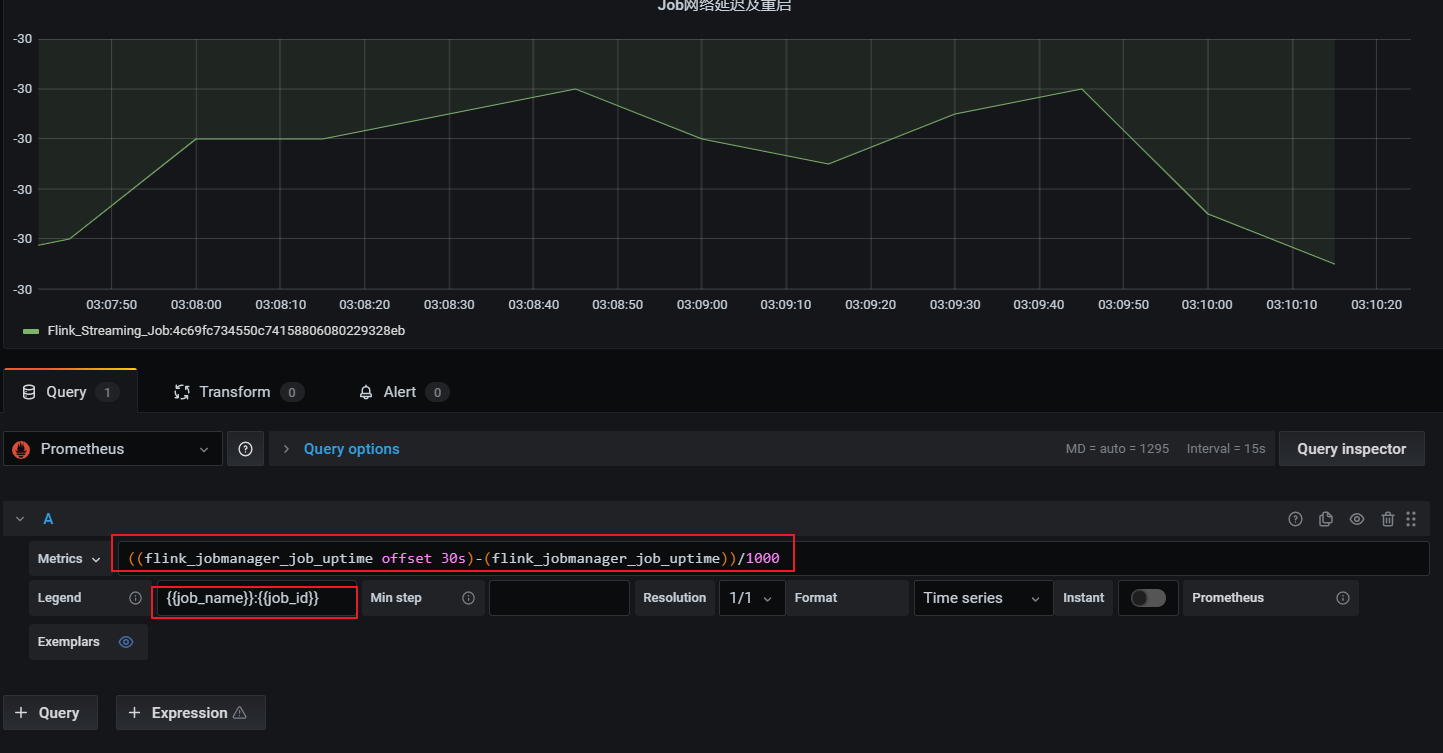
- 配置告警规则:
重启次数
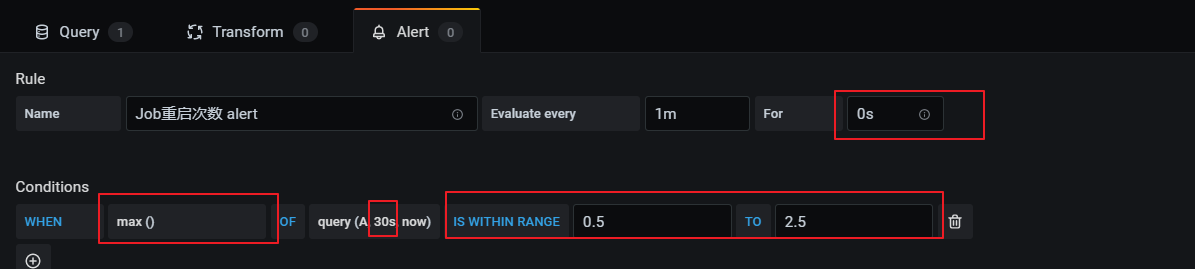
基于flink_jobmanager_job_numRestarts 指标,表示flink job的重启次数。一般设置重启策略后,在任务异常重启后这个数值会递增+1。可以单纯的监控重启次数,也可以每次重启都进行告警(差值)。
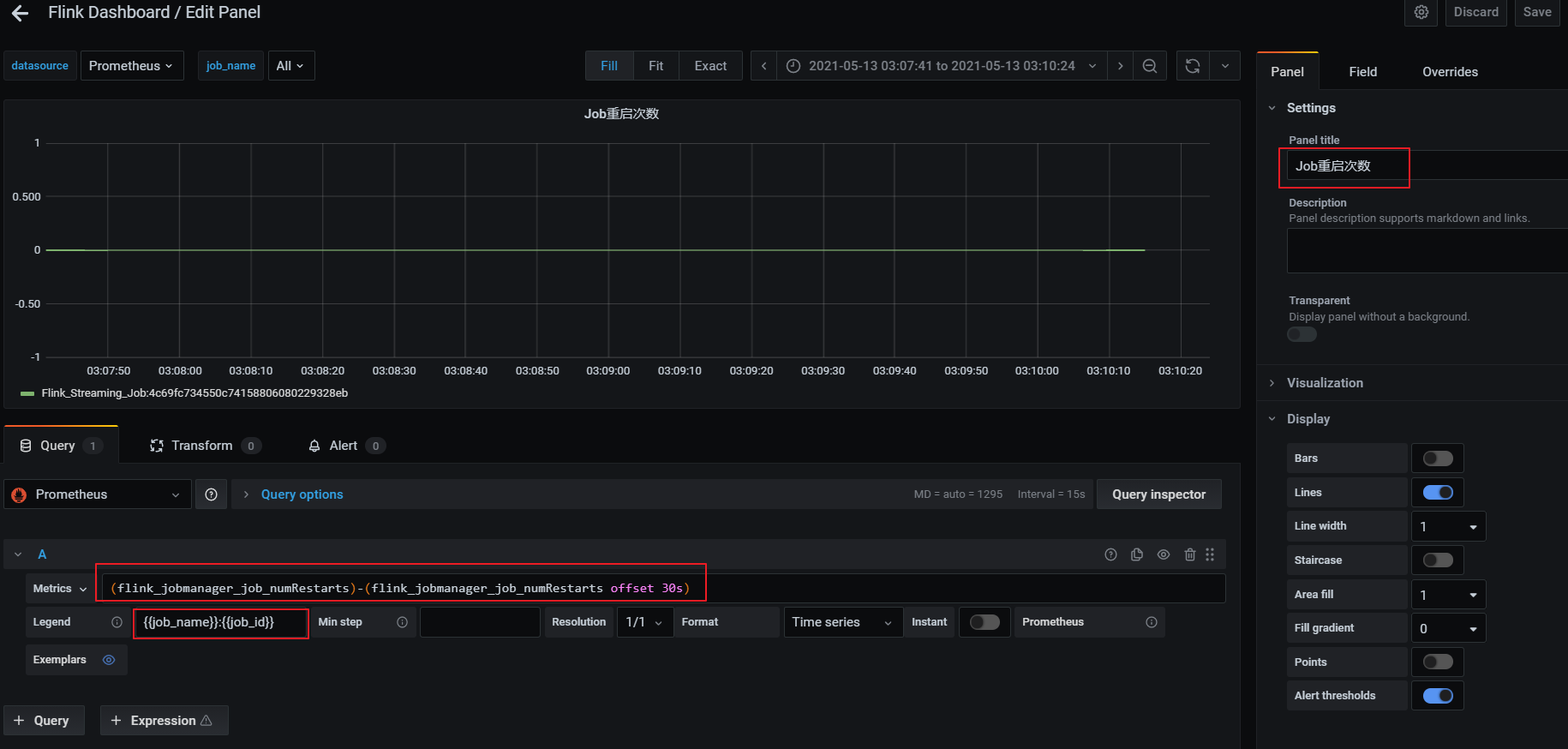
利用当前值减去30秒前的值,如果等于1证明重启了一次。
- 添加告警规则:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端