

Hive3源码总结1
大数据技术之Hive源码
第1章 HQL是如何转换为MR任务的
1.1 Hive的核心组成介绍
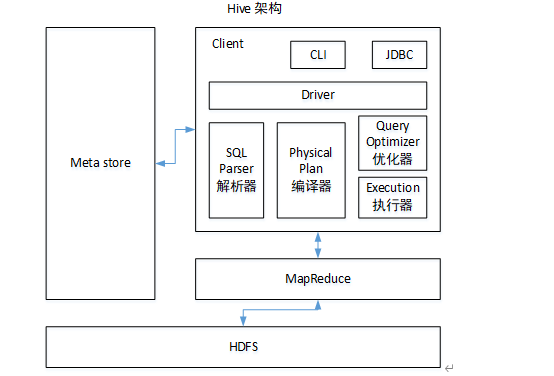
1)用户接口:Client
CLI(command-line interface如开启bin/hive)、JDBC/ODBC(hiveserver2方式,jdbc访问hive,如beeline)、WEBUI(浏览器访问hive)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库(只支持单客户端访问)中,推荐使用MySQL存储Metastore。
3)Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4)驱动器:Driver 连接客户端与服务端之间的桥梁。
5)解析器(SQL Parser)
将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
6)编译器(Physical Plan)
将AST编译生成逻辑执行计划,即逻辑(操作)树。
7)优化器(Query Optimizer)
对逻辑执行计划进行优化,各个参数(如 map join)都有对应的优化器,可以选择开启/关闭,HQL转为MR任务时会遍历所有的优化器。
8)执行器(Execution)
把逻辑执行计划转换成可以运行的物理计划。任务最终被翻译成Task Tree去执行,执行器会把对于Task Tree封装到MR任务中去提交。对Hive来说,就是MR/Spark。
1.2 HQL转换为MR任务流程说明
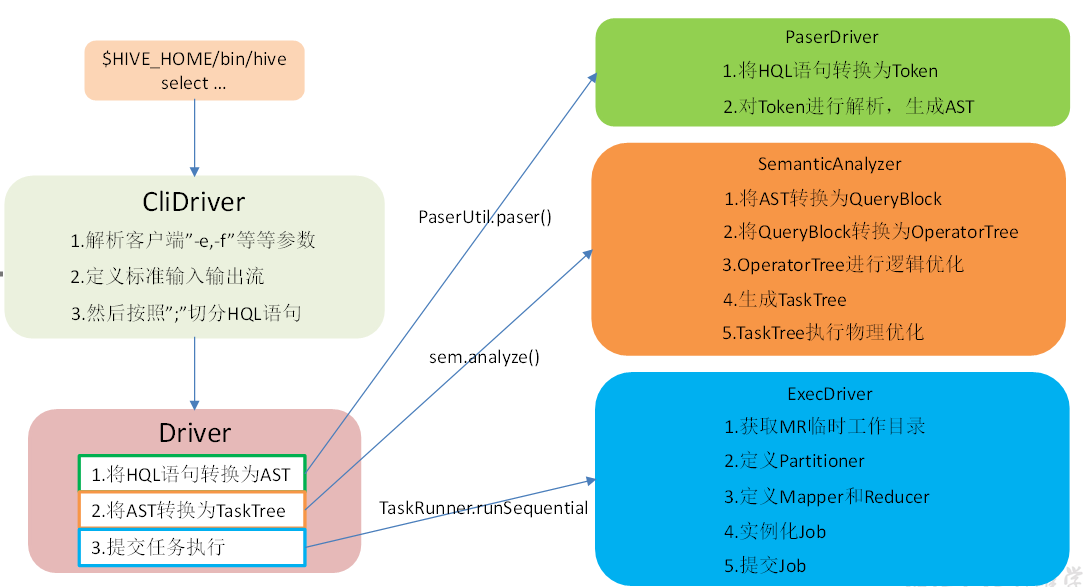
1.进入程序,利用Antlr框架定义HQL的语法规则,对HQL完成词法语法解析,将HQL转换为为AST(抽象语法树);
2.遍历AST,抽象出查询的基本组成单元QueryBlock(查询块),可以理解为最小的查询执行单元(如 select、from);
3.遍历QueryBlock,将其转换为OperatorTree(操作树,也就是逻辑执行计划),可以理解为不可拆分的一个逻辑执行单元;
4.使用逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少Shuffle数据量;
5.遍历OperatorTree,转换为TaskTree。也就是翻译为MR任务的流程,将逻辑执行计划转换为物理执行计划;
6.使用物理优化器对TaskTree进行物理优化(如:谓词下推);
7.生成最终的执行计划,提交任务到Hadoop集群运行。
第2章 HQL转换为MR源码详细解读
2.1 HQL转换为MR源码整体流程介绍
2.2 程序入口 — CliDriver
众所周知,我们执行一个HQL语句通常有以下几种方式:
1)$HIVE_HOME/bin/hive进入客户端,然后执行HQL;
2)$HIVE_HOME/bin/hive -e “hql”;
3)$HIVE_HOME/bin/hive -f hive.sql;
4)先开启hivesever2服务端,然后通过JDBC方式(如beeline,beeline比bin/hive会增加字段分隔竖线更加便于阅读)连接远程提交HQL。
可以知道我们执行HQL主要依赖于$HIVE_HOME/bin/hive和$HIVE_HOME/bin/ hivesever2两种脚本来实现提交HQL,而在这两个脚本中,最终启动的JAVA程序的主类为“org.apache.hadoop.hive.cli.CliDriver”,所以其实Hive程序的入口就是“CliDriver”这个类。
2.3 HQL的读取与参数解析
2.3.1 找到“CliDriver”这个类的“main”方法
public static void main(String[] args) throws Exception {
int ret = new CliDriver().run(args);
System.exit(ret);
}
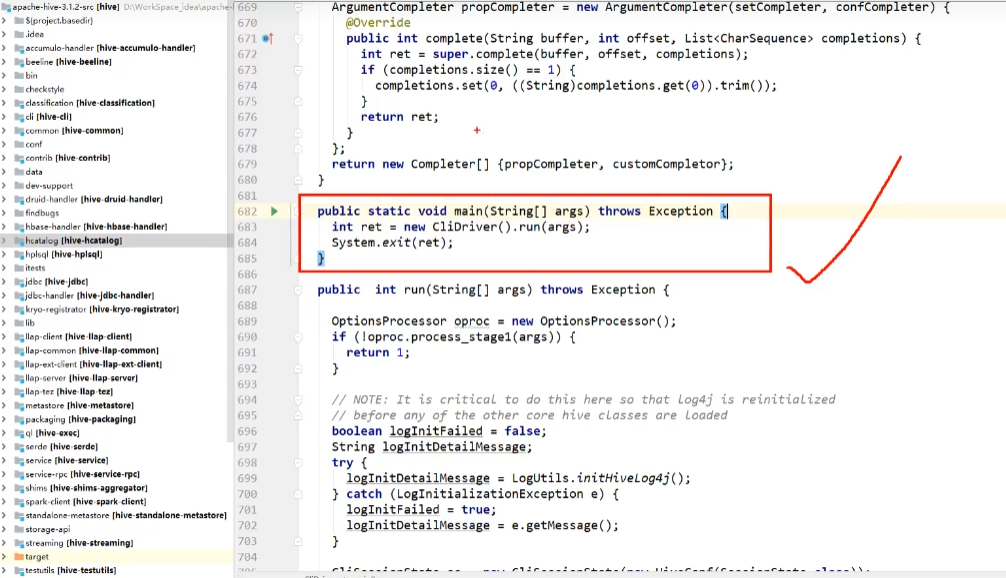
2.3.2 主类的run方法
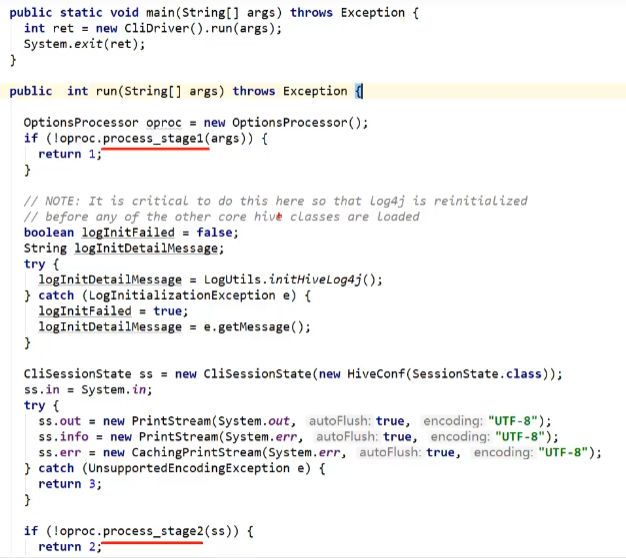
解析:
public int run(String[] args) throws Exception {
OptionsProcessor oproc = new OptionsProcessor();
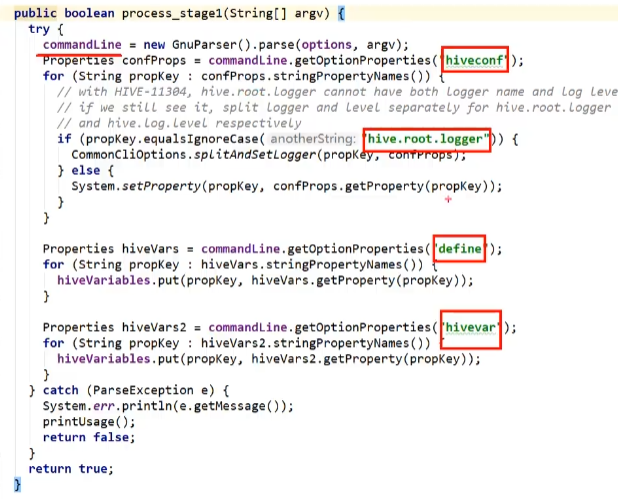
//解析系统参数 点击process_stage1跳转,图中框选的为检验的系统参数文件
if (!oproc.process_stage1(args)) {
return 1;//不正确则返回1,不往后执行
}
... ...
CliSessionState ss = new CliSessionState(new HiveConf(SessionState.class));
//标准输入in输出out以及错误err输出流的定义,后续需要输入HQL以及打印控制台信息info
ss.in = System.in;
try {
ss.out = new PrintStream(System.out, true, "UTF-8");
ss.info = new PrintStream(System.err, true, "UTF-8");
ss.err = new CachingPrintStream(System.err, true, "UTF-8");
} catch (UnsupportedEncodingException e) {
return 3; // 异常则返回3
}
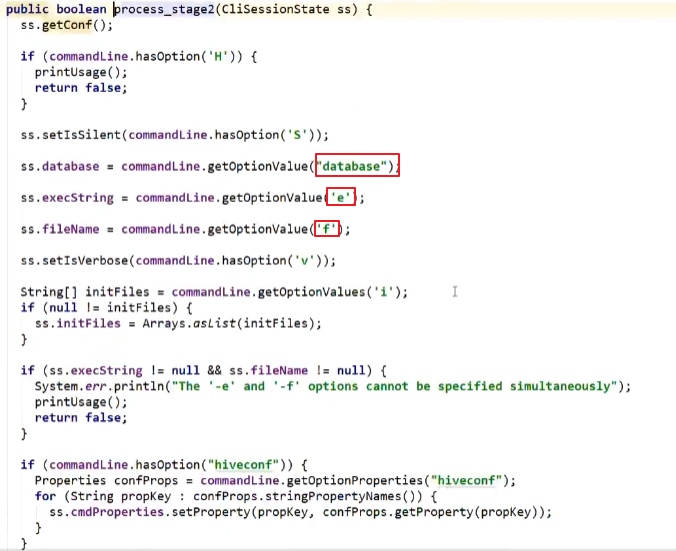
//解析用户参数,包含"-e -f -v -database"等等.点击process_stage2跳转,图中框选的为解析输入的用户参数,数据库,-e -f等等。
if (!oproc.process_stage2(ss)) {
return 2;// 异常则返回2
}
... ...
// execute cli driver work
try {
return executeDriver(ss, conf, oproc);// 2.3.3 executeDriver方法
} finally {
ss.resetThreadName();
ss.close();
}
}
2.3.3 executeDriver方法
private int executeDriver(CliSessionState ss, HiveConf conf, OptionsProcessor oproc)
throws Exception {
CliDriver cli = new CliDriver();
cli.setHiveVariables(oproc.getHiveVariables());
// use the specified database if specified
cli.processSelectDatabase(ss);
// Execute -i init files (always in silent mode)
cli.processInitFiles(ss);
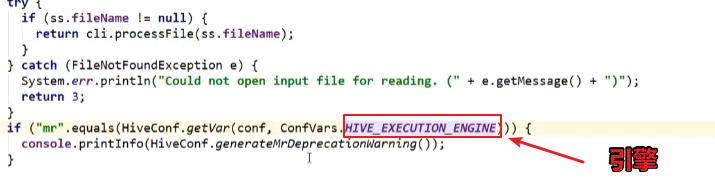
if (ss.execString != null) {
int cmdProcessStatus = cli.processLine(ss.execString);
return cmdProcessStatus;
}
 ... ...
... ...
setupConsoleReader();//初始化控制台阅读器
String line;
int ret = 0;//ret为0则返回值正常,否则1,2,3…
String prefix = "";
String curDB = getFormattedDb(conf, ss);
String curPrompt = prompt + curDB;
String dbSpaces = spacesForString(curDB);
//读取客户端的输入HQL
while ((line = reader.readLine(curPrompt + "> ")) != null) {
if (!prefix.equals("")) {//前缀为空串,则换行
prefix += '\n';
}
if (line.trim().startsWith("--")) {//”--”为注释前缀,不加载进hql解析
continue;//继续读下一行行句
}
//以按照“;”分割的方式解析
if (line.trim().endsWith(";") && !line.trim().endsWith("\\;")) {
line = prefix + line;
ret = cli.processLine(line, true); //2.3.4 processLine方法
prefix = "";
curDB = getFormattedDb(conf, ss);
curPrompt = prompt + curDB;
dbSpaces = dbSpaces.length() == curDB.length() ? dbSpaces : spacesForString(curDB);
} else {
prefix = prefix + line;//将不是以”;”分隔的当前行数据往之前的语句后继续追加
curPrompt = prompt2 + dbSpaces;
continue; //继续读下一行行句(直到以”;”分隔)
}
}
return ret;
}
2.3.4 processLine方法
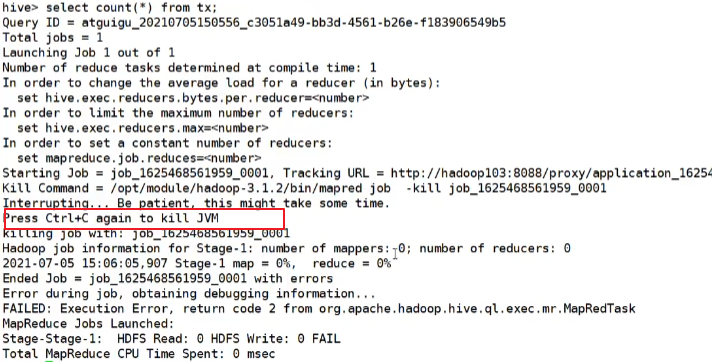
public int processLine(String line, boolean allowInterrupting) {
SignalHandler oldSignal = null;
Signal interruptSignal = null;
... ...

客户端按crtl+c退出
... ...
try {
int lastRet = 0, ret = 0;
// we can not use "split" function directly as ";" may be quoted
List<String> commands = splitSemiColon(line);
String command = "";
for (String oneCmd : commands) {
if (StringUtils.endsWith(oneCmd, "\\")) {
command += StringUtils.chop(oneCmd) + ";";
continue;
} else {
command += oneCmd;
}
if (StringUtils.isBlank(command)) {//空行则继续
continue;
}
//解析单行HQL
ret = processCmd(command); //2.3.5 processCmd方法
command = "";
lastRet = ret;
boolean ignoreErrors = HiveConf.getBoolVar(conf, HiveConf.ConfVars.CLIIGNOREERRORS);
if (ret != 0 && !ignoreErrors) {
return ret;
}
}
return lastRet;
} finally {
// Once we are done processing the line, restore the old handler
if (oldSignal != null && interruptSignal != null) {
Signal.handle(interruptSignal, oldSignal);
}
}
}
2.3.5 processCmd方法
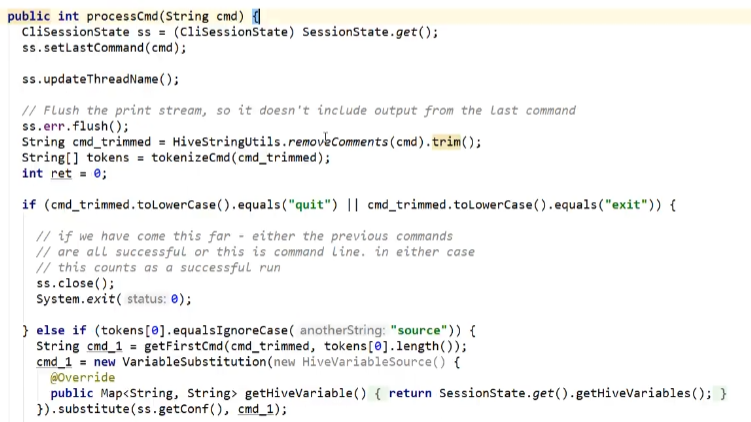
解析:
public int processCmd(String cmd) {
CliSessionState ss = (CliSessionState) SessionState.get();
... ...
//1.如果命令为"quit"或者"exit"(转小写),则退出
if (cmd_trimmed.toLowerCase().equals("quit") || cmd_trimmed.toLowerCase().equals("exit")) {
// if we have come this far - either the previous commands
// are all successful or this is command line. in either case
// this counts as a successful run
ss.close();
System.exit(0);
//2.如果命令为"source"开头,则表示执行HQL文件,继续读取文件并解析
} else if (tokens[0].equalsIgnoreCase("source")) {
String cmd_1 = getFirstCmd(cmd_trimmed, tokens[0].length());
cmd_1 = new VariableSubstitution(new HiveVariableSource() {
@Override
public Map<String, String> getHiveVariable() {
return SessionState.get().getHiveVariables();
}
}).substitute(ss.getConf(), cmd_1);
File sourceFile = new File(cmd_1);
if (! sourceFile.isFile()){
console.printError("File: "+ cmd_1 + " is not a file.");
ret = 1;
} else {
try {
ret = processFile(cmd_1);
} catch (IOException e) {
console.printError("Failed processing file "+ cmd_1 +" "+ e.getLocalizedMessage(),
stringifyException(e));
ret = 1;
}
}
//3.如果命令以"!"开头,则表示用户需要执行Linux命令
} else if (cmd_trimmed.startsWith("!")) {
// for shell commands, use unstripped command
String shell_cmd = cmd.trim().substring(1);
shell_cmd = new VariableSubstitution(new HiveVariableSource() {
@Override
public Map<String, String> getHiveVariable() {
return SessionState.get().getHiveVariables();
}
}).substitute(ss.getConf(), shell_cmd);
// shell_cmd = "/bin/bash -c \'" + shell_cmd + "\'";
try {
ShellCmdExecutor executor = new ShellCmdExecutor(shell_cmd, ss.out, ss.err);
ret = executor.execute();
if (ret != 0) {
console.printError("Command failed with exit code = " + ret);
}
} catch (Exception e) {
console.printError("Exception raised from Shell command " + e.getLocalizedMessage(),
stringifyException(e));
ret = 1;
}
//4.以上三者都不是,则认为用户输入的为"select ..."正常的增删改查、建表等等的HQL语句,则进行HQL解析
} else {
try {
try (CommandProcessor proc = CommandProcessorFactory.get(tokens, (HiveConf) conf)) {
if (proc instanceof IDriver) {
// Let Driver strip comments using sql parser
ret = processLocalCmd(cmd, proc, ss);// 2.3.6 processLocalCmd方法
} else {
ret = processLocalCmd(cmd_trimmed, proc, ss);
}
}
} catch (SQLException e) {
console.printError("Failed processing command " + tokens[0] + " " + e.getLocalizedMessage(),
org.apache.hadoop.util.StringUtils.stringifyException(e));
ret = 1;
}
catch (Exception e) {
throw new RuntimeException(e);
}
}
ss.resetThreadName();
return ret;
}
2.3.6 processLocalCmd方法
这里主要介绍输出后的打印条数、时长和结束语句等。
int processLocalCmd(String cmd, CommandProcessor proc, CliSessionState ss) {
boolean escapeCRLF = HiveConf.getBoolVar(conf, HiveConf.ConfVars.HIVE_CLI_PRINT_ESCAPE_CRLF);
int ret = 0;
if (proc != null) {
if (proc instanceof IDriver) {
IDriver qp = (IDriver) proc;
PrintStream out = ss.out;
//获取系统时间作为开始时间,以便后续计算HQL执行时长
long start = System.currentTimeMillis();
if (ss.getIsVerbose()) {
out.println(cmd);
}
//HQL执行的核心方法
ret = qp.run(cmd).getResponseCode();//2.3.7 qp.run(cmd)方法
if (ret != 0) {
qp.close();
return ret;
}
// query has run capture the time
//获取系统时间作为结束时间,以便后续计算HQL执行时长
long end = System.currentTimeMillis();
double timeTaken = (end - start) / 1000.0;
ArrayList<String> res = new ArrayList<String>();
//打印头信息
printHeader(qp, out);
// print the results,包含结果集并获取抓取到数据的条数
int counter = 0;
try {
if (out instanceof FetchConverter) {
((FetchConverter) out).fetchStarted();
}
while (qp.getResults(res)) {
for (String r : res) {
if (escapeCRLF) {
r = EscapeCRLFHelper.escapeCRLF(r);
}
out.println(r);
}
counter += res.size();
res.clear();
if (out.checkError()) {
break;
}
}
} catch (IOException e) {
console.printError("Failed with exception " + e.getClass().getName() + ":" + e.getMessage(),
"\n" + org.apache.hadoop.util.StringUtils.stringifyException(e));
ret = 1;
}
qp.close();
if (out instanceof FetchConverter) {
((FetchConverter) out).fetchFinished();
}
//打印HQL执行时间以及抓取数据的条数(经常使用Hive的同学是否觉得这句很熟悉呢,其实就是执行完一个HQL最后打印的那句话)
console.printInfo(
"Time taken: " + timeTaken + " seconds" + (counter == 0 ? "" : ", Fetched: " + counter + " row(s)"));//没有结果返回条数为0,打印空串,否则是正常数据输出对应的打印语句
} else {
String firstToken = tokenizeCmd(cmd.trim())[0];
String cmd_1 = getFirstCmd(cmd.trim(), firstToken.length());
if (ss.getIsVerbose()) {
ss.out.println(firstToken + " " + cmd_1);
}
CommandProcessorResponse res = proc.run(cmd_1);
if (res.getResponseCode() != 0) {
ss.out
.println("Query returned non-zero code: " + res.getResponseCode() + ", cause: " + res.getErrorMessage());
}
if (res.getConsoleMessages() != null) {
for (String consoleMsg : res.getConsoleMessages()) {
console.printInfo(consoleMsg);
}
}
ret = res.getResponseCode();
}
}
return ret;
}
2.3.7 qp.run(cmd)方法
点击进入“run”方法,该方法为IDriver接口的抽象方法,此处实际调用的是“org.apache.hadoop.hive.ql.Driver”类中的“run”方法,找到“Driver”类中的“run”方法。
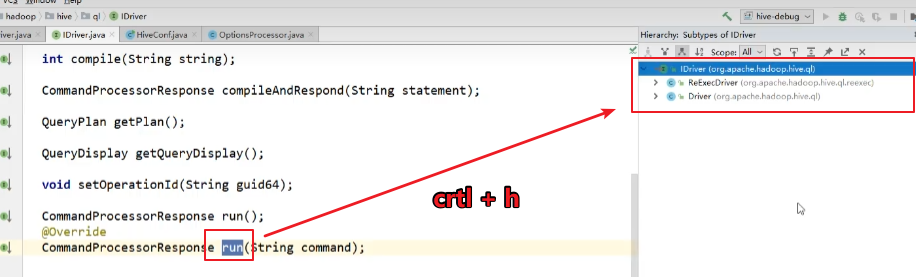
找到“Driver”类中的“run”方法。
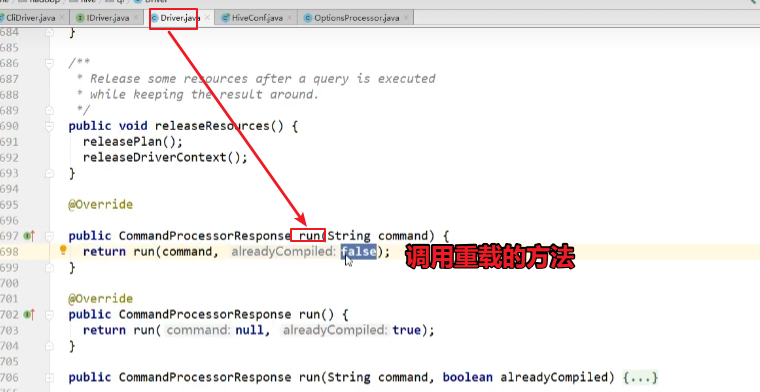
public CommandProcessorResponse run(String command) {
return run(command, false);//提交的job进行编译(false代表不是早已编译的)
}
public CommandProcessorResponse run(String command, boolean alreadyCompiled) {
try {
runInternal(command, alreadyCompiled);// 2.3.8 runInternal方法
return createProcessorResponse(0);
} catch (CommandProcessorResponse cpr) {
... ...
}
}
2.3.8 runInternal方法(编译和执行都是driver类当中的runInternal方法中,编译和执行是平级的)
private void runInternal(String command, boolean alreadyCompiled) throws CommandProcessorResponse {
errorMessage = null;
SQLState = null;
downstreamError = null;
LockedDriverState.setLockedDriverState(lDrvState);
lDrvState.stateLock.lock();
... ...
PerfLogger perfLogger = null;
if (!alreadyCompiled) {
// compile internal will automatically reset the perf logger
//1.编译HQL语句
compileInternal(command, true);// 2.4.1 compileInternal方法
// then we continue to use this perf logger
perfLogger = SessionState.getPerfLogger();
}
... ...
try {
编译和执行都是driver类当中的runInternal方法中,编译和执行是平级的
//2.执行
execute();//2.5.6 execute方法
} catch (CommandProcessorResponse cpr) {
rollback(cpr);
throw cpr;
}
isFinishedWithError = false;
}
}
2.4 HQL生成AST(抽象语法树)
2.4.1 compileInternal方法
private void compileInternal(String command, boolean deferClose) throws CommandProcessorResponse {
Metrics metrics = MetricsFactory.getInstance();
if (metrics != null) {
metrics.incrementCounter(MetricsConstant.WAITING_COMPILE_OPS, 1);
}
… …
if (compileLock == null) {
throw createProcessorResponse(ErrorMsg.COMPILE_LOCK_TIMED_OUT.getErrorCode());
}
try {
compile(command, true, deferClose);// 2.4.2 compile方法
} catch (CommandProcessorResponse cpr) {
try {
releaseLocksAndCommitOrRollback(false);
} catch (LockException e) {
LOG.warn("Exception in releasing locks. " + org.apache.hadoop.util.StringUtils.stringifyException(e));
}
throw cpr;
}
}
2.4.2 compile方法
private void compile(String command, boolean resetTaskIds, boolean deferClose) throws CommandProcessorResponse {
PerfLogger perfLogger = SessionState.getPerfLogger(true);
perfLogger.PerfLogBegin(CLASS_NAME, PerfLogger.DRIVER_RUN);
perfLogger.PerfLogBegin(CLASS_NAME, PerfLogger.COMPILE);
lDrvState.stateLock.lock();
... ...
//HQL生成AST
ASTNode tree;
try {
tree = ParseUtils.parse(command, ctx);// 2.4.3 parse方法
} catch (ParseException e) {
parseError = true;
throw e;
} finally {
hookRunner.runAfterParseHook(command, parseError);
}
}
2.4.3 parse方法
/** Parses the Hive query. */
public static ASTNode parse(String command, Context ctx) throws ParseException {
return parse(command, ctx, null);
}
public static ASTNode parse(
String command, Context ctx, String viewFullyQualifiedName) throws ParseException {
ParseDriver pd = new ParseDriver();
ASTNode tree = pd.parse(command, ctx, viewFullyQualifiedName);
tree = findRootNonNullToken(tree);
handleSetColRefs(tree);
return tree;
}
public ASTNode parse(String command, Context ctx, String viewFullyQualifiedName)
throws ParseException {
if (LOG.isDebugEnabled()) {
LOG.debug("Parsing command: " + command);
}
//1.构建词法解析器
HiveLexerX lexer = new HiveLexerX(new ANTLRNoCaseStringStream(command));
//2.将HQL中的关键词替换为Token
TokenRewriteStream tokens = new TokenRewriteStream(lexer);
if (ctx != null) {
if (viewFullyQualifiedName == null) {
// Top level query
ctx.setTokenRewriteStream(tokens);
} else {
// It is a view
ctx.addViewTokenRewriteStream(viewFullyQualifiedName, tokens);
}
lexer.setHiveConf(ctx.getConf());
}
说明:Antlr框架。Hive使用Antlr实现SQL的词法和语法解析。Antlr是一种语言识别的工具,可以用来构造领域语言。 这里不详细介绍Antlr,只需要了解使用Antlr构造特定的语言只需要编写一个语法文件,定义词法和语法替换规则即可,Antlr完成了词法分析、语法分析、语义分析、中间代码生成的过程。
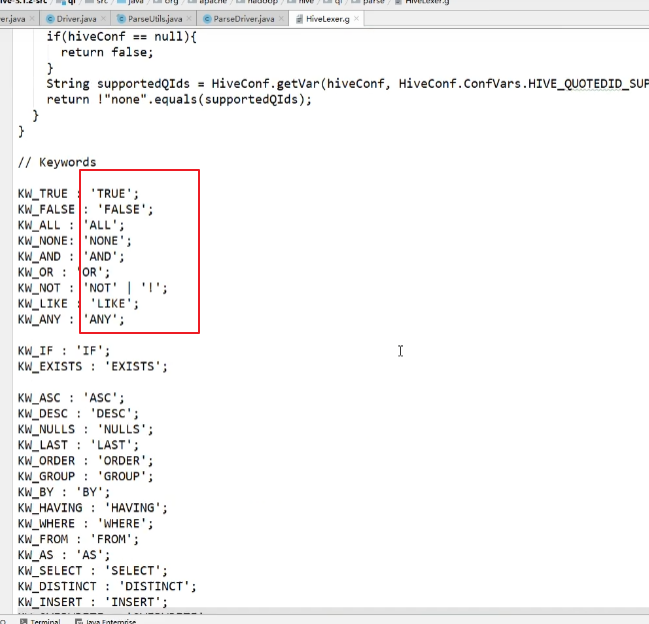
Hive中语法规则的定义文件在0.10版本以前是Hive.g一个文件,随着语法规则越来越复杂,由语法规则生成的Java解析类可能超过Java类文件的最大上限,0.11版本将Hive.g拆成了5个文件,词法规则HiveLexer.g和语法规则的4个文件SelectClauseParser.g,FromClauseParser.g,IdentifiersParser.g,HiveParser.g。
比如:
词法的具体解析:
HiveParser parser = new HiveParser(tokens);
if (ctx != null) {
parser.setHiveConf(ctx.getConf());
}
parser.setTreeAdaptor(adaptor);
HiveParser.statement_return r = null;
try {
//3.进行语法解析,生成最终的AST
r = parser.statement();
} catch (RecognitionException e) {
e.printStackTrace();
throw new ParseException(parser.errors);
}
if (lexer.getErrors().size() == 0 && parser.errors.size() == 0) {
LOG.debug("Parse Completed");
} else if (lexer.getErrors().size() != 0) {
throw new ParseException(lexer.getErrors());
} else {
throw new ParseException(parser.errors);
}
ASTNode tree = (ASTNode) r.getTree();
tree.setUnknownTokenBoundaries();
return tree;
}
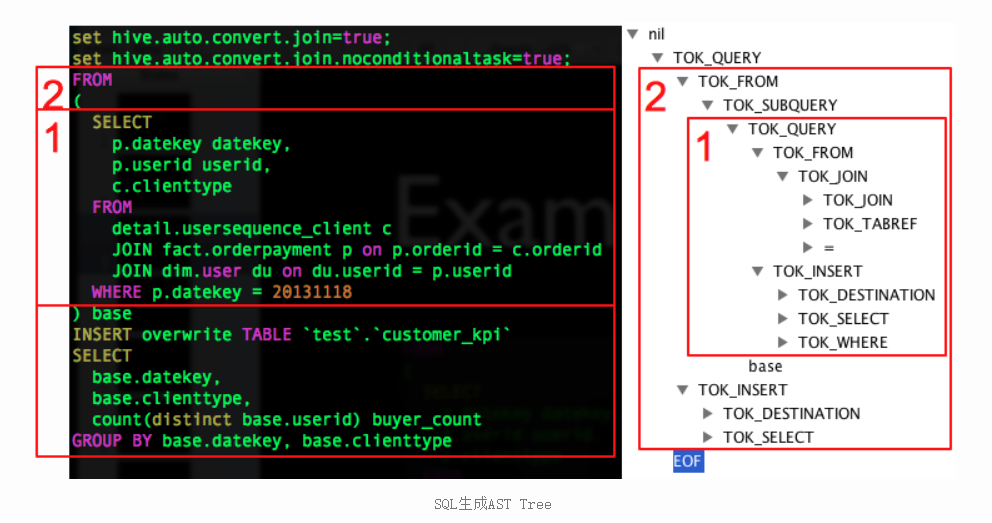
说明:例如HQL语句为:
FROM
(
SELECT
p.datekey datekey,
p.userid userid,
c.clienttype
FROM
detail.usersequence_client c
JOIN fact.orderpayment p ON p.orderid = c.orderid
JOIN default.user du ON du.userid = p.userid
WHERE p.datekey = 20131118
) base
INSERT OVERWRITE TABLE `test`.`customer_kpi`
SELECT
base.datekey,
base.clienttype,
count(distinct base.userid) buyer_count
GROUP BY base.datekey, base.clienttype
生成对应的AST(抽象语法树)为:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!