第六次作业
作业1:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
代码如下:
from bs4 import BeautifulSoup
import threading
import re
import requests
import urllib.request
import pymysql
def get_html(url):
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
html = res.text
prase(html)
def prase(html):
urls = []
soup = BeautifulSoup(html, "html.parser")
movies = soup.find('ol')
movies = movies.find_all('li')
for i in movies:
try:
# 将mNo转换成string类型
mNo = i.em.string
# 电影名
mName = i.find('span').text
'''# 利用正则匹配出图片网址
img = str(i.find('img'))
# 此时返回的img_url为列表类型
img_url = re.findall(r'src="(.*?)"', img)
img_url = img_url[0]
# 将图片下载保存,此时下载为单线程
download(mName, img_url)'''
# 导演、主演、上映年份、国家、类型等信息存在于同一子节点中
info = i.find('p').text
# 导演
director = re.findall(r'导演: (.*?) ', info)
# 主演
actor = re.findall(r'主演: (.*?) ', info)
# 将第二行的信息分割后存入数组
array = re.findall(r'\d+.+', info)[0].split('/')
# strip()的作用是去除空格
# 上映年份
time = array[0].strip()
# 国家
country = array[1].strip()
# 类型
type = array[2].strip()
# 评分
score = i.find('span', attrs={"class": "rating_num"}).text
# 通过next_sibling查找”评分“的兄弟节点获取“评价人数”
num = i.find('span', attrs={"class": "rating_num"}).next_sibling.next_sibling.next_sibling.next_sibling.text
# 引用
quote = i.find('span', attrs={"class": "inq"}).text
# 文件路径
mFile = str(mName) + ".jpg"
cursor.execute("insert into movie(mNo,mName,director,actor,time,country,type,score,num,quote,mFile) "
"values( % s, % s, % s, % s, % s, % s, % s, % s, % s, % s, % s)",
(mNo, mName, director, actor, time, country, type, score, num, quote, mFile))
except Exception:
pass
# 查找页面内所有图片信息
images = soup.select("img")
for image in images:
try:
# 找出图片对应网址
url = image['src']
# 找出对应电影名
mName = image['alt']
if url not in urls:
T = threading.Thread(target=download, args=(mName, url))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
def download(pic_name, img):
req = urllib.request.Request(img)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:/data/file2/" + str(pic_name) + ".jpg", "wb")
fobj.write(data)
fobj.close()
url = 'https://movie.douban.com/top250'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'}
# 连接数据库
con = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='mydb', charset='utf8')
cursor = con.cursor(pymysql.cursors.DictCursor)
sql = 'create table movie(mNo int,mName varchar(32), director varchar(32),actor varchar(32),time varchar(32),' \
'country varchar(16),type varchar(32),score varchar(32),num varchar(32),quote varchar(32),mFile varchar(32));'
cursor.execute(sql)
cursor.execute("delete from movie")
threads = []
for page in range(0, 11):
get_html("https://movie.douban.com/top250?start="+str(page*25)+"&filter=")
for t in threads:
t.join()
# 关闭连接
con.commit()
con.close()
运行结果
- 数据库存储
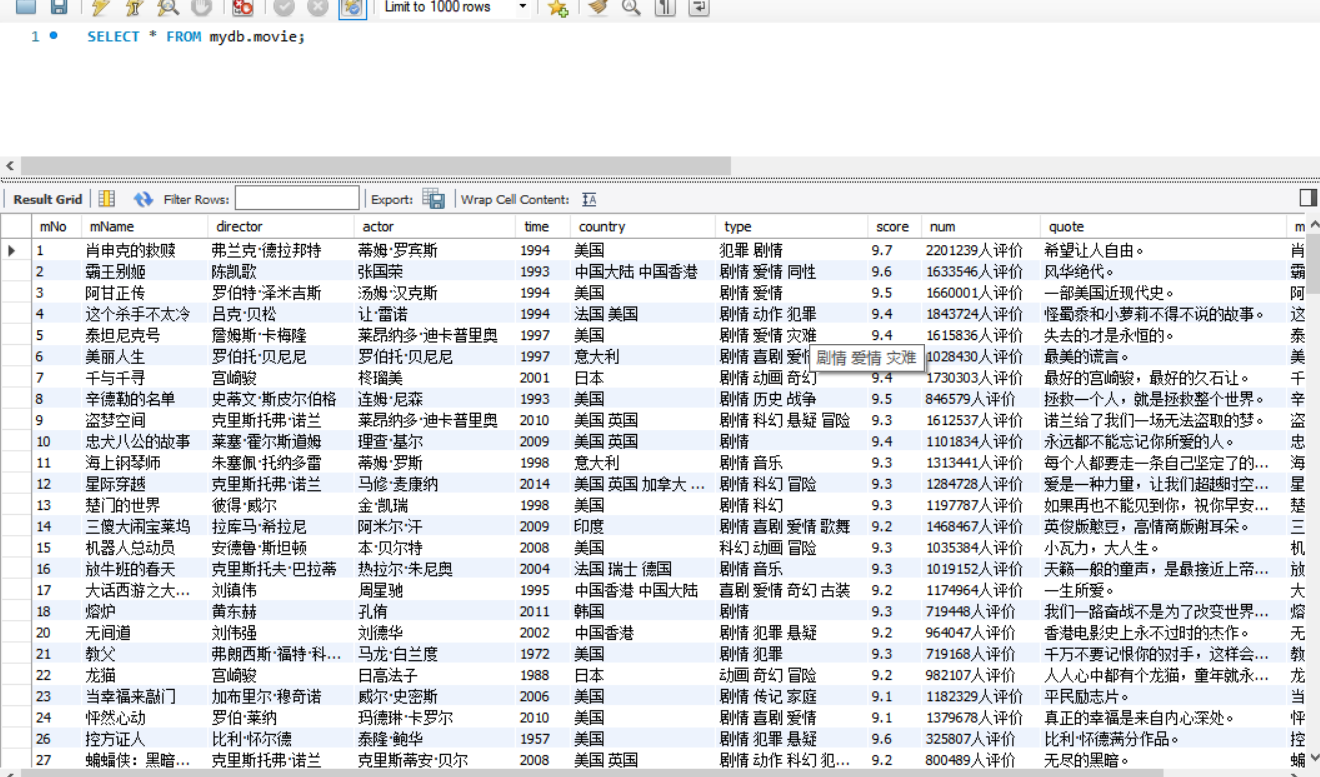
- 文件夹图片
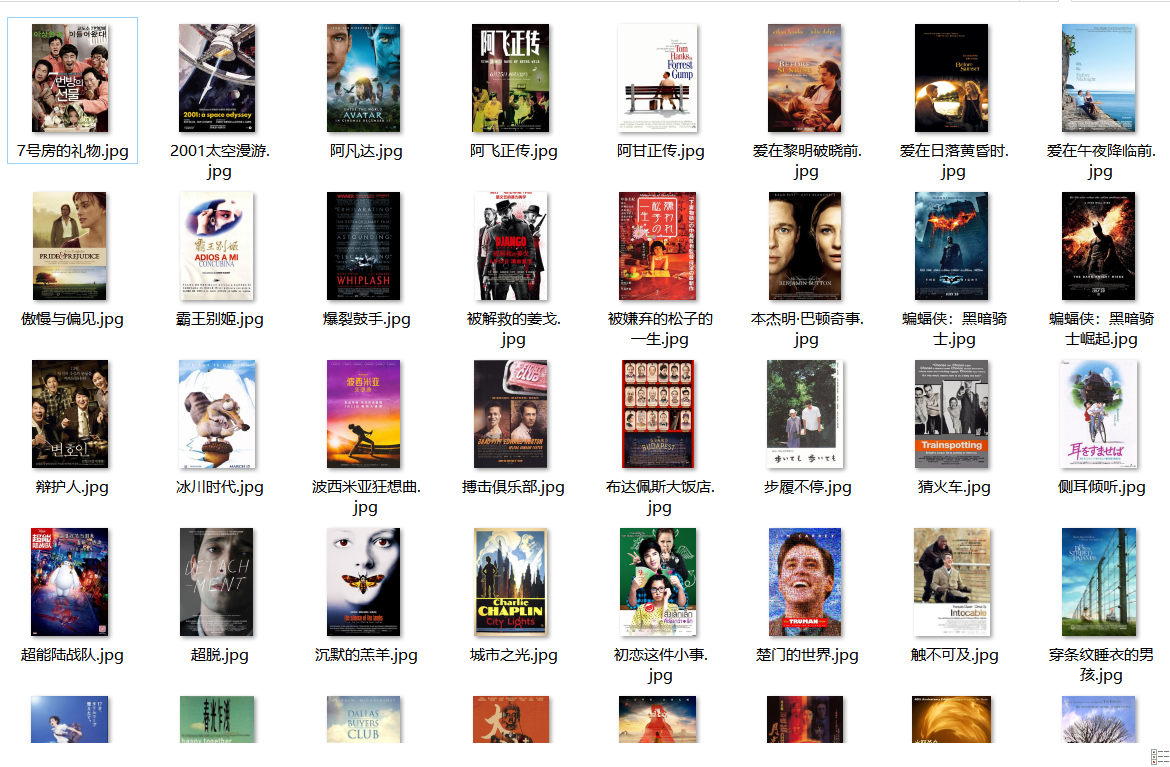
心得体会
1.温故知新,重新学习了re和beautiful soup的使用方法(不重新学都忘光了hhh),之前遇到的一些疑惑也能理解了。对beautiful soup的查找兄弟方法有了初步的理解,但不明白为啥查找相邻的节点需要两次的next_sibling。
2.爬取图片时是查找所有的img src,可能会出现下载与电影无关图片的问题。原本的想法是创建一个空列表存储所有图片url后在进行爬取,但是这样不好命名,希望下次能找到更好的方法。
3.对多线程的运行机制理解还不够透彻,知其然不知其所以然,还要再多看看。关于本次数据的存储本来不想用mysql,但是用prettytable的时候出现了超过迭代次数的报错,进程终止。还是屈服了
作业2:
Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
代码如下:
- college_bank
import scrapy
from bs4 import UnicodeDammit
import requests
import urllib
from ..items import CollegeInfoItem
from ..pipelines import CollegeInfoPipeline
class CollegeBankSpider(scrapy.Spider):
name = 'college_bank'
# allowed_domains = ['www.baidu.com.io_']
def start_requests(self):
url = 'https://www.shanghairanking.cn/rankings/bcur/2020'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
# 解析网页
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath('//table[@class="rk-table"]//tbody[@data-v-2a8fd7e4]//tr')
for li in lis:
# sNo,sName,city三个信息可以在当前网页上查看到
sNo = li.xpath('.//td[position()=1]/text()').extract_first().replace('\n', '').replace(' ', '')
sName = li.xpath('.//td[position()=2]/a/text()').extract_first()
city = li.xpath('.//td[position()=3]/text()').extract_first().replace('\n', '').replace(' ', '')
# 此网页所能爬取到的url不是学校官网网址
# officalUrl,info,logo要进入另一个网页
url = li.xpath('.//td[@class="align-left"]/a/@href').extract_first()
url = 'http://www.shanghairanking.cn' + url
res = requests.get(url)
res.encoding = res.apparent_encoding
html = res.text
selector = scrapy.Selector(text=html)
# 注意官网和src是属性值
officalUrl = selector.xpath('//div[@class="univ-website"]/a/@href').extract_first()
info = selector.xpath('//div[@class="univ-introduce"]/p/text()').extract_first()
# 获取到学校logo地址,进行下载
logo = selector.xpath('//td[@class="univ-logo"]/img/@src').extract_first()
req = urllib.request.Request(logo)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:/data/file1/" + str(sNo) + ".png", "wb")
fobj.write(data)
fobj.close()
print('#######################################')
print(sNo)
print(sName)
print(city)
print(officalUrl)
print(info)
print(str(sNo)+".png")
print('**************************************')
item = CollegeInfoItem()
item['sNo'] = sNo
item['sName'] = sName
item['city'] = city
item['officalUrl'] = officalUrl
item['info'] = info
item['mFile'] = str(sNo)+".png"
yield item
pass
- items
import scrapy
class CollegeInfoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
sNo = scrapy.Field()
sName = scrapy.Field()
city = scrapy.Field()
officalUrl = scrapy.Field()
info = scrapy.Field()
mFile = scrapy.Field()
pass
- pipelines
import pymysql
class CollegeInfoPipeline:
def open_spider(self, spider):
try:
self.con = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456',
db='mydb', charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.sql = 'create table college(sNo int,sName varchar(32),city varchar(16),officalUrl varchar(64),' \
'info text,mFile varchar(16));'
# self.cursor.execute(self.sql)
self.cursor.execute('delete from college')
self.opened = True
except Exception as err:
print(err)
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
def process_item(self, item, spider):
if self.opened:
self.cursor.execute("insert into college (sNo,sName,city,officalUrl,info,mfile) values(%s,%s,%s,%s,%s,%s)",
(item['sNo'], item['sName'], item['city'], item['officalUrl'], item['info'], item['mFile']))
return item
运行结果
-
控制台输出
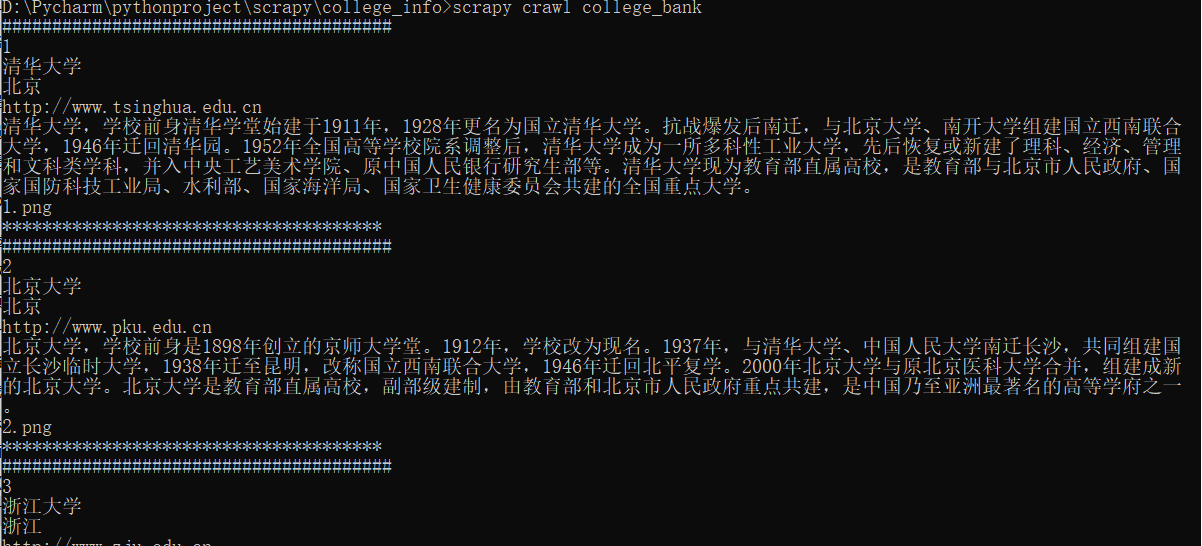
-
数据库存储
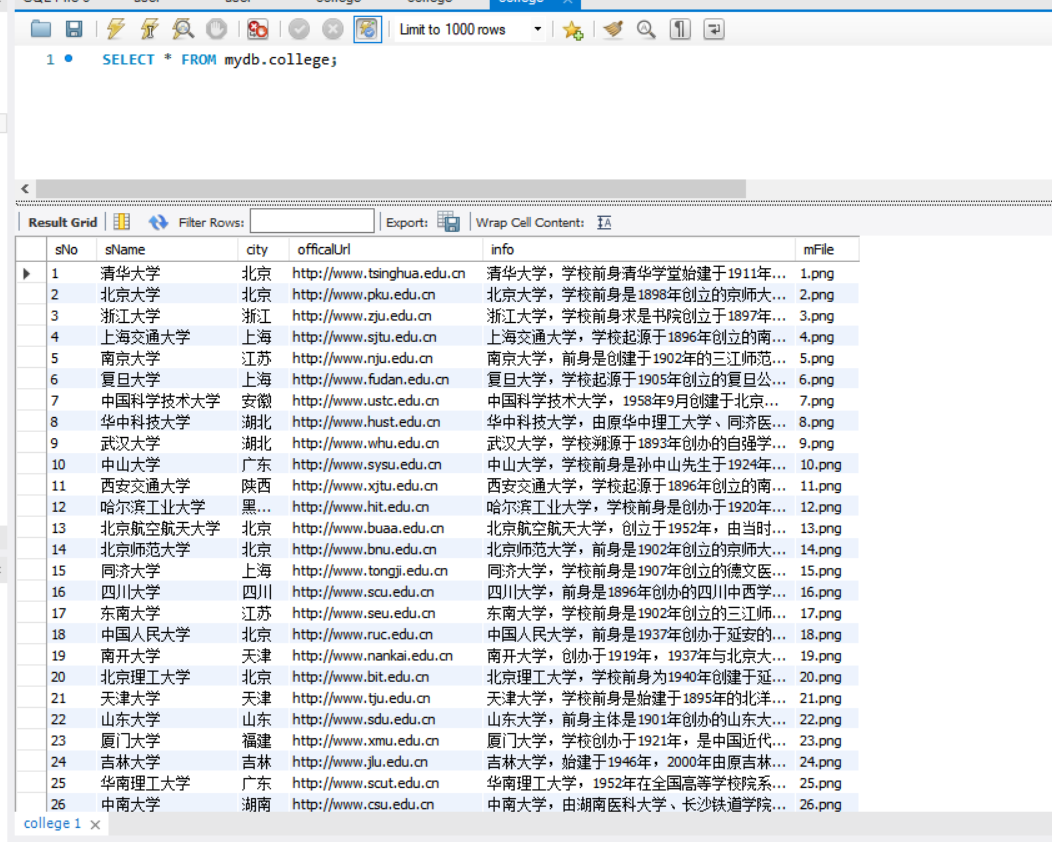
-
文件夹图片

心得体会
重新温习了一下scrapy框架的使用方法,加深了对selector的理解,本次作业要爬取的内容全都可以在一个页面中找到,不需要翻页,结合之前的知识不会感觉难度太大。时隔n天再次使用scrapy,对比发现selenium虽然说速度上不够快,但是真的方便啊(虽然可能更大一部分原因是scrapy太久没用了,忘光了)。
作业3:
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import pymysql
def Load_in():
time.sleep(1)
# 点击登录
user = driver.find_element_by_xpath('//*[@id="j-topnav"]/div')
user.click()
time.sleep(1)
# 选择其他方式登录
way = driver.find_element_by_xpath('//div[@class="ux-login-set-scan-code_ft"]/span')
way.click()
time.sleep(1)
# 选择电话号码登录
telephone = driver.find_element_by_xpath('//ul[@class="ux-tabs-underline_hd"]/li[2]')
telephone.click()
time.sleep(1)
frame = driver.find_element_by_xpath("/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div/iframe")
# 将操作切换至页面弹窗
driver.switch_to.frame(frame)
driver.find_element_by_xpath('//input[@type="tel"]').send_keys('15260637027')
time.sleep(1)
driver.find_element_by_xpath('//input[@class="j-inputtext dlemail"]').send_keys('******')
time.sleep(1)
load_in = driver.find_element_by_xpath('//*[@id="submitBtn"]')
load_in.click()
def MyClass():
time.sleep(2)
# 进入个人中心
myclass = driver.find_element_by_xpath('//*[@id="j-indexNav-bar"]/div/div/div/div/div[7]/div[3]/div')
myclass.click()
all_spider()
def all_spider():
time.sleep(1)
spider()
time.sleep(1)
# 进行翻页的尝试
try:
driver.find_element_by_xpath('//ul[@class="ux-pager"]/li[@class="ux-pager_btn ux-pager_btn__next"]/a[@class="th-bk-disable-gh"]')
except Exception:
driver.find_element_by_xpath('//ul[@class="ux-pager"]/li[@class="ux-pager_btn ux-pager_btn__next"]/a[@class="th-bk-main-gh"]').click()
all_spider()
def spider():
global id
time.sleep(1)
lis = driver.find_elements_by_xpath('//div[@class="course-card-wrapper"]')
print(lis)
for li in lis:
time.sleep(1)
li.click()
# 获取页面句柄,原网页为0,新网页为1
window = driver.window_handles
# 切换到新页面
driver.switch_to.window(window[1])
time.sleep(1)
driver.find_element_by_xpath('//*[@id="g-body"]/div[3]/div/div[1]/div/a').click()
# 重新获取句柄
window = driver.window_handles
# 切换到下一页面
driver.switch_to.window(window[2])
time.sleep(1)
id += 1
course = driver.find_element_by_xpath('//*[@id="g-body"]/div[1]/div/div[3]/div/div[1]/div[1]/span[1]').text
teacher = driver.find_element_by_xpath('//*[@id="j-teacher"]//h3[@class="f-fc3"]').text
collage = driver.find_element_by_xpath('//*[@id="j-teacher"]/div/a/img').get_attribute('alt')
process = driver.find_element_by_xpath('//*[@id="course-enroll-info"]/div/div[1]/div[2]/div[1]').text
count = driver.find_element_by_xpath('//*[@id="course-enroll-info"]/div/div[2]/div[1]/span').text
brief = driver.find_element_by_xpath('//*[@id="j-rectxt2"]').text
print(id)
print(course)
print(teacher)
print(collage)
print(process)
print(count)
print(brief)
cursor.execute("insert into mooc(id, course, teacher, collage, process, count, brief) "
"values( % s, % s, % s, % s, % s, % s, % s)",
(id, course, teacher, collage, process, count, brief))
time.sleep(1)
# 关闭此窗口
driver.close()
# 切换回上一网页
driver.switch_to.window(window[1])
time.sleep(1)
# 进入两次新网页,所以要进行两次close()操作
driver.close()
driver.switch_to.window(window[0])
print('***********************************')
url = 'https://www.icourse163.org/'
chrome_options = Options()
'''chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')'''
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get(url)
# 最大化浏览器窗口
driver.maximize_window()
# 连接数据库
con = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='mydb', charset='utf8')
cursor = con.cursor(pymysql.cursors.DictCursor)
sql = 'create table mooc(id int,course varchar(32),teacher varchar(16),collage varchar(32),process varchar(64),' \
'count varchar(64),brief text);'
'''cursor.execute(sql)'''
cursor.execute("delete from mooc")
# 登录
Load_in()
id = 0
# 爬取课程信息
MyClass()
# 关闭连接
con.commit()
con.close()
登录gif
运行结果
- 终端运行结果
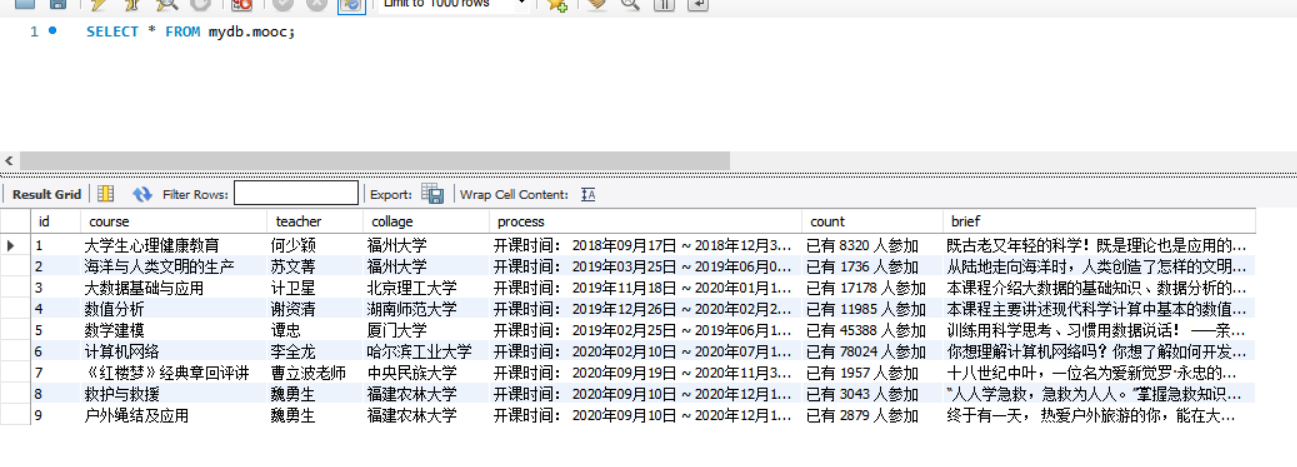
- 数据库存储
心得体会
1.模拟登陆时,点击注册/登陆会弹出一个小弹窗,这个弹窗并不是新页面,需要通过driver.switch_to.frame进行切换。
2.这一次的作业需要在点开一个新界面的基础上再点开第二个网页,此时需要重新获取页面句柄,同时关闭也要关闭两次
ps:这次作业和上一次差不多,就是模拟点击课程时,突然弹出让我评价的窗口,害的程序直接报错,只要手动评价后就不会再弹出了,不评价会一直弹。。。
