第四次作业
作业1:
Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
代码如下:
import scrapy
from ..items import BookinfoItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class BookSpider(scrapy.Spider):
name = 'book'
key = '阿来尘埃落定北岳文艺出版社'
# allowed_domains = ['www.baidu.com.io']
start_urls = 'http://search.dangdang.com/'
def start_requests(self):
url = BookSpider.start_urls + "?key=" + BookSpider.key
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath(
"./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# detail有时没有,结果None
item = BookinfoItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
# 最后一页时link为None
link = selector.xpath(
"//div[@class='paging']/ul[@name='Fy']/li[@class='next'] / a / @ href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
import pymysql
class BookinfoPipeline:
def open_spider(self, spider):
print('opened')
try:
self.con = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456',
db='mydb', charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute('delete from books')
self.opened = True
self.count = 1
except Exception as err:
print(err)
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print('closed')
print('总共爬取', self.count-1, '本书籍')
def process_item(self, item, spider):
try:
'''print(item['title'])
print(item['author'])
print(item['publisher'])
print(item['date'])
print(item['price'])
print(item['detail'])
print()'''
if self.opened:
self.cursor.execute("insert into books (bId, bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) "
"values(% s, % s, % s, % s, % s, % s, % s)",
(self.count, item["title"], item["author"], item["publisher"], item["date"],
item["price"], item["detail"]))
self.count += 1
except Exception as err:
print(err)
return item
import scrapy
class BookinfoItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
pass
运行结果
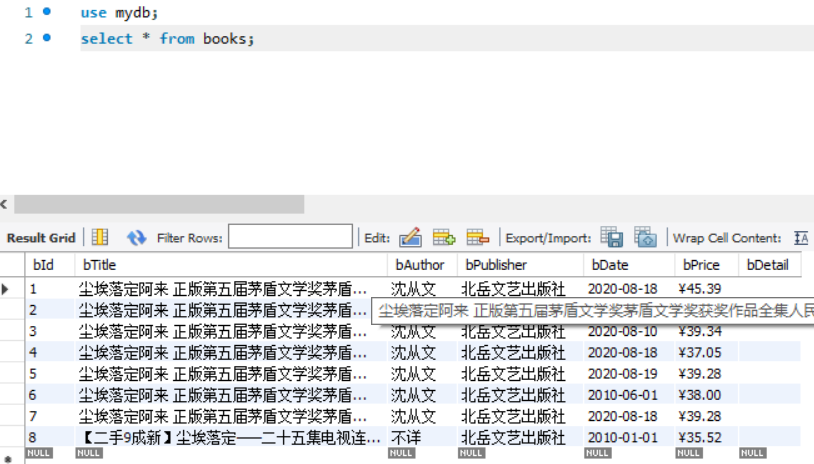
心得体会
这次作业新增的内容就是建立py与MySQL的连接,将数据存入SQL中,尤其要注意程序中插入数据的格式,表头的内容要与数据库中一一对应,否则就会存储失败。
作业2:
Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
代码如下:
import scrapy
from selenium import webdriver
from ..items import Stockinfo2Item
from ..pipelines import Stockinfo2Pipeline
class StockSpider(scrapy.Spider):
name = 'stock'
# allowed_domains = ['www.baidu.com.io']
def start_requests(self):
url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
driver = webdriver.Chrome()
try:
driver.get("http://quote.eastmoney.com/center/gridlist.html#hs_a_board")
lis = driver.find_elements_by_xpath("//table[@id='table_wrapper-table']/tbody/tr")
for li in lis:
array = li.text.split(" ")
item = Stockinfo2Item()
item["id"] = array[1]
item["name"] = array[2]
item["new_price"] = array[6]
item["extent"] = array[7]
item["change_price"] = array[8]
item["number"] = array[9]
item["money"] = array[10]
item["promote"] = array[11]
item["highest"] = array[12]
item["lowest"] = array[13]
item["today_begin"] = array[14]
item["yesterday_over"] = array[15]
yield item
except Exception as err:
print(err)
print(Stockinfo2Pipeline.tb)
import pymysql
import prettytable as pt
class StockinfoPipeline:
num = 0
tb = pt.PrettyTable(["序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"])
def open_spider(self, spider):
print('opened')
try:
self.con = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456',
db='mydb', charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute('delete from stock')
self.opened = True
self.count = 1
except Exception as err:
print(err)
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
def process_item(self, item, spider):
StockinfoPipeline.num += 1
StockinfoPipeline.tb.add_row(
[StockinfoPipeline.num, item["id"], item["name"], item["new_price"], item["extent"], item["change_price"],
item["number"], item["money"], item["promote"], item["highest"], item["lowest"], item["today_begin"],
item["yesterday_over"]])
if self.opened:
self.cursor.execute("insert into stock (count,id,sName,new_price,extent,change_price,sNumber,money,"
"promote,highest,lowest,today_begin,yesterday_over) "
"values( %s, % s, % s, % s, % s, % s, % s, % s, % s, % s, % s, % s, % s)",
(self.count, item["id"], item["name"], item["new_price"], item["extent"],
item["change_price"], item["number"], item["money"], item["promote"], item["highest"],
item["lowest"], item["today_begin"], item["yesterday_over"]))
self.count += 1
return item
import scrapy
class StockinfoItem(scrapy.Item):
id = scrapy.Field()
name = scrapy.Field()
new_price = scrapy.Field()
extent = scrapy.Field()
change_price = scrapy.Field()
number = scrapy.Field()
money = scrapy.Field()
promote = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
today_begin = scrapy.Field()
yesterday_over = scrapy.Field()
pass
运行结果
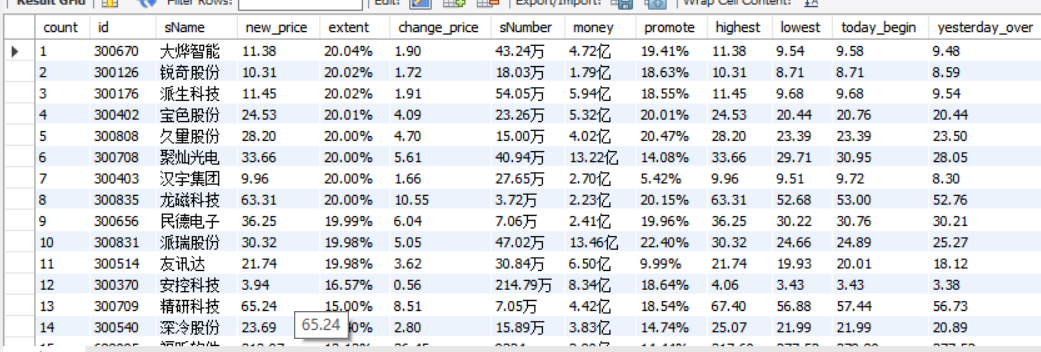
心得体会
股票数据是通过JavaScript进行控制的,单纯的通过xpath爬取内容为空,所以需要安装selenium框架,初步了解了一下selenium框架的用法,不会复杂,piplines和items文件也不需要怎么改动,很快就出结果了。
作业3:
使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据
代码如下:
import scrapy
from ..items import ExchangeRateItem
from bs4 import UnicodeDammit
class BankSpider(scrapy.Spider):
name = 'bank'
# allowed_domains = ['www.baidu.com.io']
def start_requests(self):
url = 'http://fx.cmbchina.com/hq/'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//div[@id='realRateInfo']/table/tr")
for li in lis[1:]:
Currency = li.xpath("./td[@class='fontbold']/text()").extract_first()
TSP = li.xpath("./td[@class='numberright'][position()=1]/text()").extract_first()
CSP = li.xpath("./td[@class='numberright'][position()=2]/text()").extract_first()
TBP = li.xpath("./td[@class='numberright'][position()=3]/text()").extract_first()
CBP = li.xpath("./td[@class='numberright'][position()=4]/text()").extract_first()
bTime = li.xpath("./td[@align='center'][position()=3]/text()").extract_first()
item = ExchangeRateItem()
item["Currency"] = Currency.strip() if Currency else ""
item["TSP"] = TSP.strip() if TSP else ""
item["CSP"] = CSP.strip() if CSP else ""
item["TBP"] = TBP.strip() if TBP else ""
item["CBP"] = CBP.strip() if CBP else ""
item["bTime"] = bTime.strip() if bTime else ""
yield item
except Exception as err:
print(err)
import pymysql
class ExchangeRatePipeline:
def open_spider(self, spider):
try:
self.con = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456',
db='mydb', charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute('delete from bank')
self.opened = True
self.count = 1
except Exception as err:
print(err)
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
def process_item(self, item, spider):
try:
'''print(item["Currency"])
print(item["TSP"])
print(item["CSP"])
print(item["TBP"])
print(item["CBP"])
print(item["bTime"])'''
if self.opened:
self.cursor.execute("insert into bank (count,Currency,TSP,CSP,TBP,CBP,bTime) "
"values(% s, % s, % s, % s, % s, % s, % s)",
(self.count, item["Currency"], item["TSP"], item["CSP"], item["TBP"],
item["CBP"], item["bTime"]))
self.count += 1
except Exception as err:
print(err)
return item
import scrapy
class ExchangeRateItem(scrapy.Item):
# define the fields for your item here like:
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
bTime = scrapy.Field()
pass
运行结果
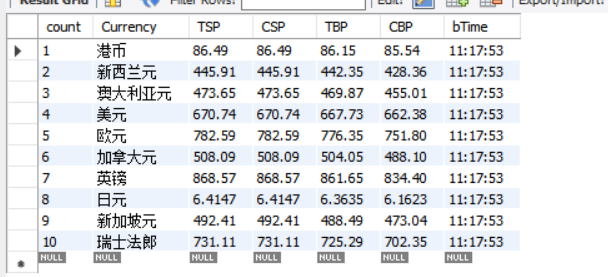
心得体会
在MySQL建表时要注意数据的类型。刚开始不小心把count定义成varchar,搞半天不明白为啥我的数据没有按照升序排列。。。还有就是这次爬取的数据表格第一行是空的,要去除。
