第一次作业——结合三次小作业
作业1:
UniversitiesRanking代码及截图
import requests
from bs4 import BeautifulSoup
import bs4
def get_text(url):
try:
r = requests.get(url)
r.raise_for_status() # 判断状态码是否为200
r.encoding = r.apparent_encoding # 使返回的编码准确
return r.text
except:
print("异常") # 如果状态码不是200就会产生异常
return " "
def university_list(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children: # 查找的子节点
if isinstance(tr, bs4.element.Tag): # 剔除不需要的信息
tds = tr('td')
# 要用strip()去除文本中的空格,不然内容为none时会报错
# 把td信息存入ulist中
ulist.append([tds[0].text.strip(), tds[1].text.strip(), tds[2].text.strip(), tds[3].text.strip(), tds[4].text.strip()])
def university_rank(ulist, num):
# {5}:中间的部分用第五个元素填充,即chr(12288)所表示的空格
template = "{0:^10}\t{1:{5}^10}\t{2:{5}^10}\t{3:{5}^10}\t{4:^10}"
print(template.format("排名", "学校名称", "省市", "类型", "总分", chr(12288))) # chr(12288)中文空格
for i in range(num):
u = ulist[i]
print(template.format(u[0], u[1], u[2], u[3], u[4], chr(12288)))
def main():
university_info = []
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
html = get_text(url)
university_list(university_info, html)
university_rank(university_info, 76)
if __name__ == '__main__':
main()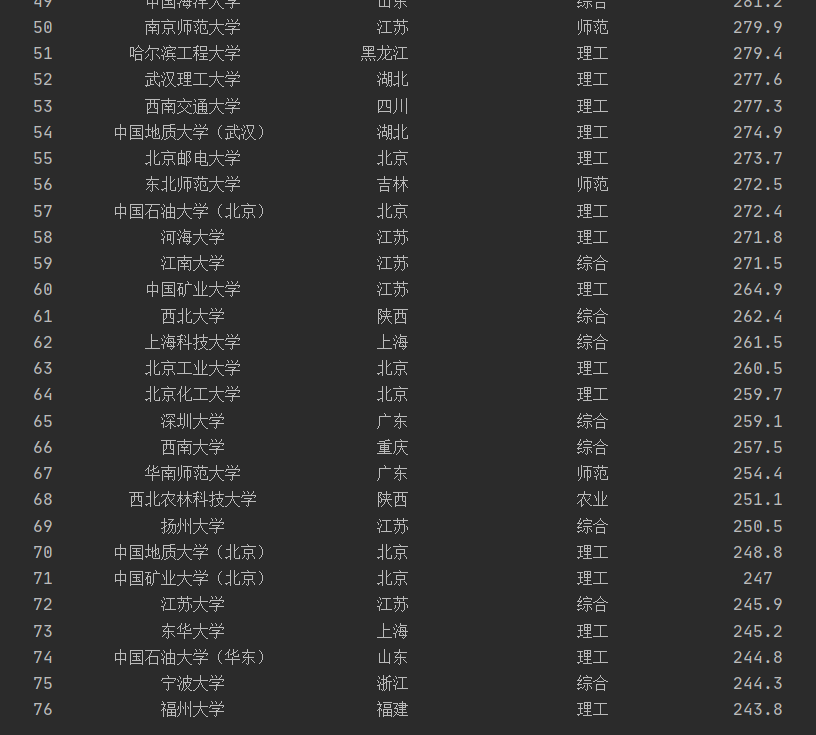
心得体会:
通过这次作业,主要了解了beautifulsoup对HTML文档节点查找的应用,其中的过程并不复杂,主要是要注意爬取内容的格式处理,因为我们输出这个排名是给定了一个输出样板的,输出样板的格式必须要能与输出的数据对应才能正确输出结果,刚开始运行时就因为没有去除空格而导致unsupported format string passed to NoneType.__format__的报错。
作业2:
GoodsPrice代码及截图
import requests
import re
def get_text(url):
# cookie:一个 Web 站点为每一个访问者产生一个唯一的ID,以 cookie 文件的形式保存在每个用户的机器上
# cookie的作用:“绕开”淘宝登录界面,正确的爬取相关信息(个人理解就是骗淘宝是人在浏览,不会被反爬?)
# cookie的获取:登录淘宝后进入开发者模式点击network>doc>headers获取,具体可以看百度
kv = {'cookie': '__wpkreporterwid_=eececfef-906a-4fb6-ace3-fb6bad074a9d; miid=1634809439250278456; thw=cn; tracknick=%5Cu770B%5Cu5979%5Cu559C%5Cu6B22%5Cu4ED6; tg=0;enc=OSHVBUIZSYB1ri%2FjC7mpbEQDGz0DOTuJaZvDM2iDLGQ79sUaG3y9rAtbU2fU6yhpJtZWEGM4IQhT8pfpntOeNA%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156;lego2_cna=YMMU8XCPH2042TPC8EUK08DX;cna=saRUFWbiQEQCAdpqkQ0o20Aj; _m_h5_tk=4add6874f1fc3c3b7b55f78927640045_1600590235159; _m_h5_tk_enc=f183ab0d5e6b272b21693ab54d512fe9; t=8acd43ec8988b9ef215b3ff947fa5200; v=0; _tb_token_=37b8e8646dee9; xlly_s=2; ctoken=UhFwpaWspyb8bf41I_k2WDx0; cookie2=2cbb8f5872526eeb35cba8adc260eed9; _samesite_flag_=true; sgcookie=E100vfY7LmQb53nk6VdYVS2LmPcYGkGVYzxfvbk%2B3S56z%2FNsOBBNm3OR5X2XXiYG4GuxTElnpcUDCuk0yFXhVCvL5g%3D%3D; unb=3211086177; uc3=id2=UNJQ7JrPk7IY6g%3D%3D&lg2=WqG3DMC9VAQiUQ%3D%3D&nk2=3AB9G%2FGOgMDnBw%3D%3D&vt3=F8dCufeJPXTTc0mYK8U%3D; csg=9daf4408; lgc=%5Cu770B%5Cu5979%5Cu559C%5Cu6B22%5Cu4ED6; cookie17=UNJQ7JrPk7IY6g%3D%3D; dnk=%5Cu770B%5Cu5979%5Cu559C%5Cu6B22%5Cu4ED6; skt=131499d55be3d474; existShop=MTYwMDU4NDY5OA%3D%3D; uc4=nk4=0%403nRK0e5viV4c3C%2F7EL1mRldzY%2BOi&id4=0%40UgXXlRJMKjytBrob6W7duBqamP3j; _cc_=WqG3DMC9EA%3D%3D; _l_g_=Ug%3D%3D; sg=%E4%BB%9679; _nk_=%5Cu770B%5Cu5979%5Cu559C%5Cu6B22%5Cu4ED6; cookie1=BxIeZkDcEn8dNujLMh37ANXlG1tMRI%2FOG52QzOAmceE%3D; mt=ci=3_1; uc1=pas=0&existShop=false&cookie16=W5iHLLyFPlMGbLDwA%2BdvAGZqLg%3D%3D&cookie21=Vq8l%2BKCLjhS4UhJVbhgU&cookie14=Uoe0bU1Mx2N2Mg%3D%3D&cookie15=VT5L2FSpMGV7TQ%3D%3D; isg=BMnJJ2TY8h5rqo8byIYWElQt1vUjFr1I_M_8lms_obCgsuvEuWQpGOcr8BYE8VWA; tfstk=c4eAB_cbGab0q-o8YSCof6eL6L2AaZ_tPngMBMLU4-OF6M9vhs3wK6pY_X7aN2f..; l=eB_LTDzVQN5Va2d1BO5Cnurza77t1Id3zkPzaNbMiInca6sPTBakONQ44OWB7dtjgtfbnUxP4o0UAdHMWazKAxDDBecuBKWOAYp6-', 'user-agent': 'Mozilla/5,0'}
try:
r = requests.get(url, headers=kv, timeout=30)
# 使响应的内容的编码方式准确
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parse_info(info_list, html):
try:
price_list = re.findall(r'"view_price":"[\d.]*"', html)
title_list = re.findall(r'"raw_title":".*?"', html)
for i in range(len(price_list)):
# 此时的price_list存储的信息格式为"view_price":"**"
# 用split除去冒号后,第二个数据即为所求价格
price = eval(price_list[i].split(':')[1])
title = eval(title_list[i].split(':')[1])
info_list.append([price, title])
except:
print("")
def goods_price(info_list):
# 给format输出形式定义一种样板
template = "\t{:^4}{:^8}\t{:^16}"
# 方便统计输出的商品信息数
count = 0
print(template.format("序号", '价格', '商品名'))
for i in info_list:
count = count + 1
print(template.format(count, i[0], i[1]))
def main():
# 创建一个空列表用来存储商品的价格信息
info_list = []
key = '辣条'
url = 'https://s.taobao.com/search?q=' + key
html = get_text(url)
parse_info(info_list, html)
goods_price(info_list)
if __name__ == '__main__':
main()
心得体会:
这次作业的第一个难点就是爬取电商网站会被反爬从而出现爬取失败的结果,在网上看了几种解决方法,在代码内加入了自己的cookie码同时爬取尽量少的内容,最后可以输出结果。然后不同的电商网站存储数据的格式是不一样的,爬取前要先查看源码来定义爬取格式,就能正确输出结果了。
作业3:
JpgFileDownload代码及其截图
import urllib.request
import re
from bs4 import BeautifulSoup
def get_html(url):
res = urllib.request.urlopen(url)
html = res.read()
return html
def parse_html(htmlfile):
mysoup = BeautifulSoup(htmlfile, 'html.parser')
# 通过查看学校官网源代码,发现学校图片开头均为![]() picture_src = mysoup.findAll('img')
img_re = re.compile(r'src="(.*?)"')
for i in range(len(picture_src)):
s = str(picture_src[i])
img_url = re.findall(img_re, s)
if img_url:
# 此时的url可能含有weight等参数,所以取第一个字符串(刚好是图片网址)
img_url = img_url[0]
# 单纯的靠网页爬取出的图片地址下载不来,在前面加入url可以解决
img_url = url + img_url
print("%d"%(i+1)+":"+img_url)
with open("D:/data/file1/%s.jpg" % (i+1), 'wb') as f:
try:
pic_url = get_html(img_url)
f.write(pic_url)
except :
print("URLError")
if __name__ == '__main__':
url = 'https://www.fzu.edu.cn/'
html = get_html(url)
parse_html(html)
picture_src = mysoup.findAll('img')
img_re = re.compile(r'src="(.*?)"')
for i in range(len(picture_src)):
s = str(picture_src[i])
img_url = re.findall(img_re, s)
if img_url:
# 此时的url可能含有weight等参数,所以取第一个字符串(刚好是图片网址)
img_url = img_url[0]
# 单纯的靠网页爬取出的图片地址下载不来,在前面加入url可以解决
img_url = url + img_url
print("%d"%(i+1)+":"+img_url)
with open("D:/data/file1/%s.jpg" % (i+1), 'wb') as f:
try:
pic_url = get_html(img_url)
f.write(pic_url)
except :
print("URLError")
if __name__ == '__main__':
url = 'https://www.fzu.edu.cn/'
html = get_html(url)
parse_html(html)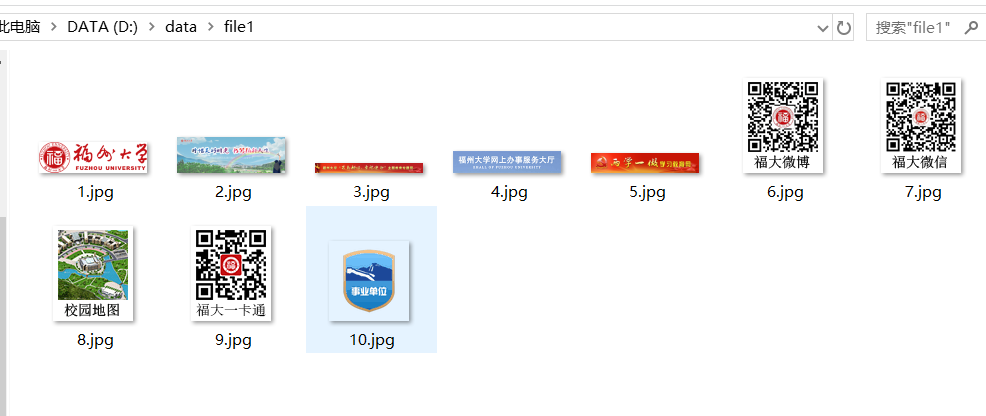
心得体会:
爬取内容与前两次作业进行的操作差不多,但是如果在get_html(url)步骤时如果返回的是text(),就会出现图片无法加载的情况,上网查找原因,大概是因为text()只返回所选元素的文本内容,html()可以返回所选元素的内容(包括 HTML 标记),可能要下载图片就是要包含HTML标记?(不太确定),最后获取完URL可以直接通过文本读写的方式将图片下载下来。
