第一次个人编程作业
1-1Github链接:点击这里
1-2计算模块接口的设计与实现过程。
刚开始查阅资料的时候先找到的是simhash函数,在用自己的文本(很短)进行初步测试时发现得出的测试结果真·不忍直视,就放弃了(后来才看到simhash适用于长文本,早知道直接用给的文档进行测试了)。。然后又看到了评价很好的TF-IDF模型,可是自己查重效果也不太好,原因是语料库不够多,没有足够的训练样本,不适用于这种一对一文档对比。还有看到其他几种方法,总会出现一些能力之外的错,最后终于找到简单易懂的余弦算法(害,我是原罪)
1.第一步肯定是简单地读取文档呀(虽然我在中文解码耗了很久)
2.接下来就是处理文本,这里我选择了最简单也适合我的jieba分词,不禁感叹python的方便
3.分词完就是可以用各种方法进行计算了
4.最后在指定路径输出结果
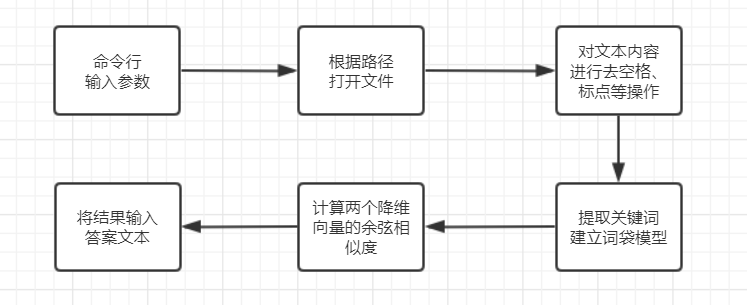
(1)找出两篇文章的关键词
(2)每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合中的词的词频
(3)生成两篇文章各自的词频向量
(4)计算两个向量的余弦相似度,值越大就表示越相似。
具体通过余弦算法计算文本相似度的原理可以参考阮一峰老师的这篇文章
这里我主要定义了三个函数:
1.去标点符号
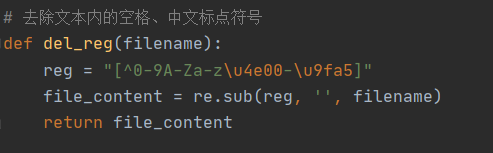
2.建立词袋模型
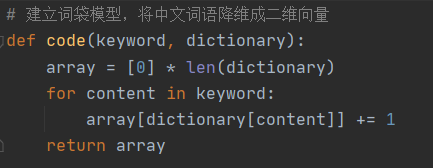
3.余弦相似度的计算

1-3计算模块接口部分的性能改进。
1.标点符号的去除,效果还是有的
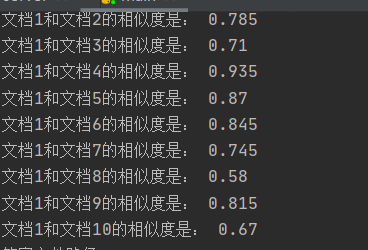
2.cos方法在计算短文本重复率有较好的性能,而在计算长文本容易结果偏高(如下图)
(ps:因为为了更好地观察文本相似度,这一步骤没有取小数点后两位)
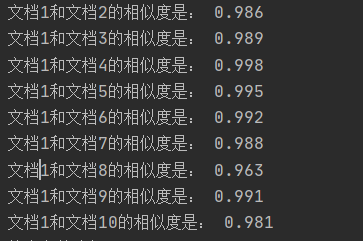
改进:不再直接用jieba分词处理后的文本建立词典,而是通过提取关键词来建立词典(这次的结果就比较符合预期了)
3.关键词数的选择对结果影响很大,但是对于一篇文档重要的词数不容易确定(有些精炼,有些啰嗦)
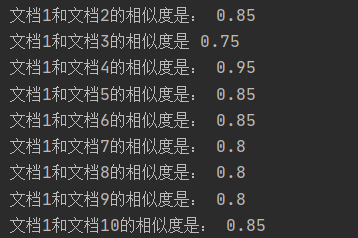
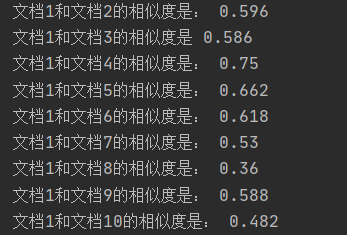
(因为想展示关键词的影响,所以在词数选择时选择了比较极端的情况(极大和极小))
想法:我是比较想用去除自定义停用表的方法,但是因为不能读写其他的文件,就只能pass了。
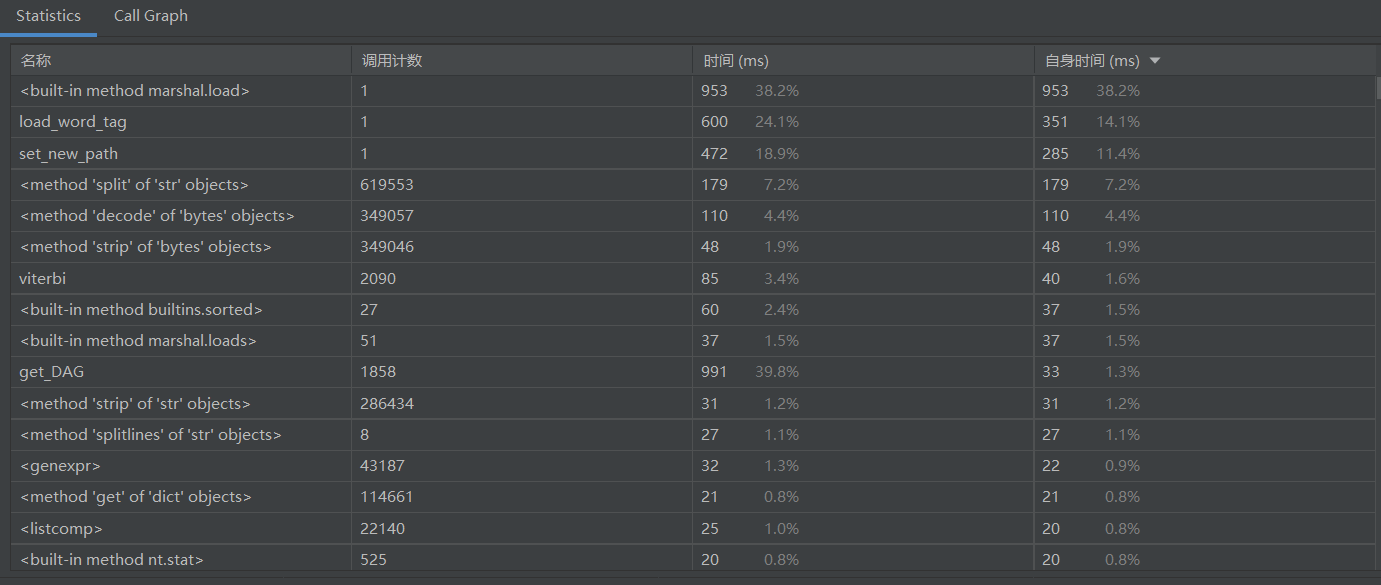
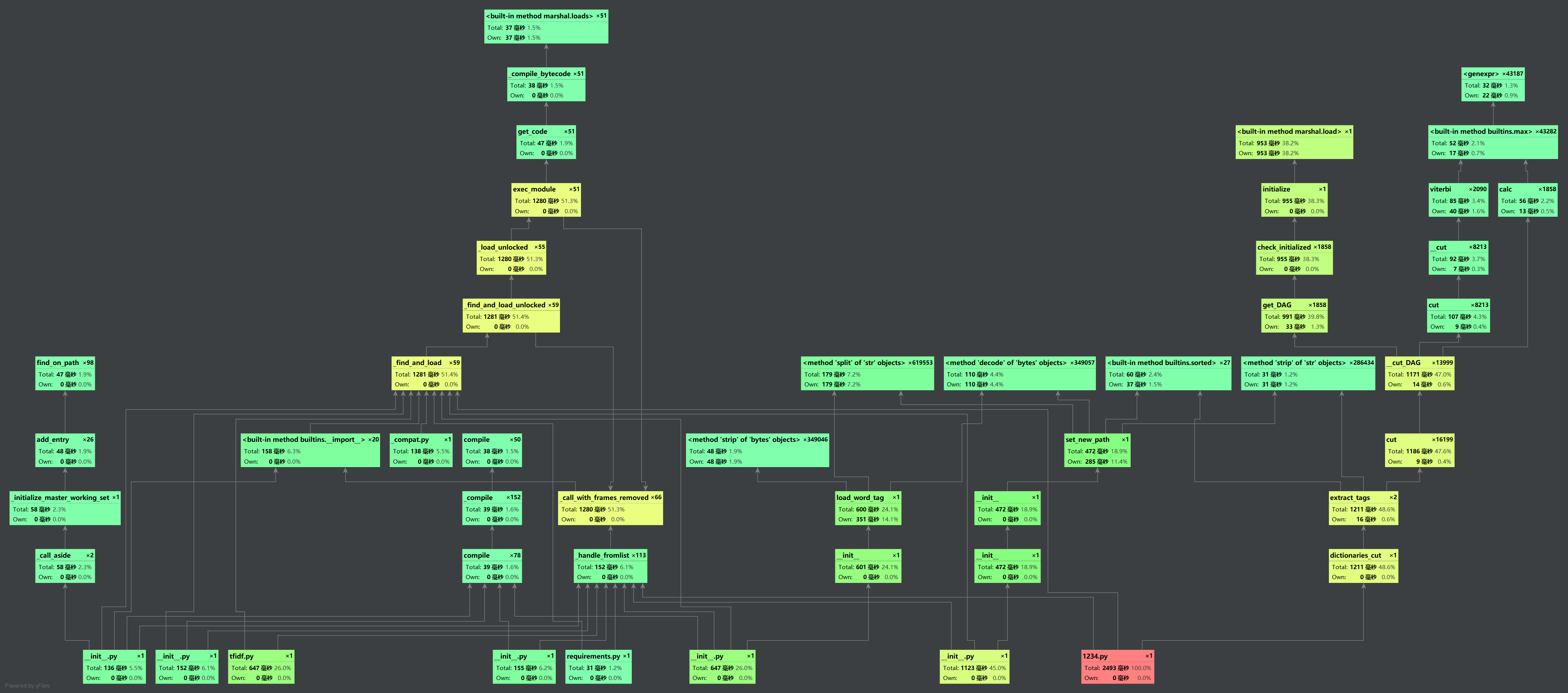
从总时间来看,2.5s,要求以内(毕竟余弦虽然准确率没有其他方法高,但是好歹跑的快)

1-4计算模块部分单元测试展示。
虽说python中有unittest让我们调用,但是对我来说,能用一个循环达成相同的效果就不要再去用别的吧,毕竟少做少错qaq,但是私底下还是会学一学unittest的
import codecs
import re
import jieba.analyse
import math
#去除文本内的空格、中文标点符号
def del_reg(filename):
reg = "[^0-9A-Za-z\u4e00-\u9fa5]"
file_content = re.sub(reg, '', filename)
return file_content
#建立词袋模型,将中文词语降维成二维向量
def code(keyword, dictionary):
array = [0] * len(dictionary)
for content in keyword:
array[dictionary[content]] += 1
return array
#通过计算两个向量的余弦距离来求文本相似度
def cos(vector1, vector2):
vector_sum = 0
fq1 = 0
fq2 = 0
for content in range(len(vector1)):
vector_sum += vector1[content] * vector2[content]
fq1 += pow(vector1[content], 2)
fq2 += pow(vector2[content], 2)
try:
answer = round(float(vector_sum) / (math.sqrt(fq1) * math.sqrt(fq2)), 3)
except ZeroDivisionError:
answer = 0.0
return answer
#encoding='utf-8'
#file_path1 = input("文件1路径:")
#file_path2 = input("文件2路径:")
file_path1='sim_0.8/orig.txt'
fileList=['sim_0.8/orig.txt', 'sim_0.8/orig_0.8_add.txt', 'sim_0.8/orig_0.8_del.txt','sim_0.8/orig_0.8_dis_1.txt', 'sim_0.8/orig_0.8_dis_3.txt','sim_0.8/orig_0.8_dis_7.txt','sim_0.8/orig_0.8_dis_10.txt',
'sim_0.8/orig_0.8_dis_15.txt','sim_0.8/orig_0.8_mix.txt','sim_0.8/orig_0.8_rep.txt']
for r in range(0,10):
file1 = codecs.open(file_path1, mode='r', encoding='utf-8').read()
file2 = codecs.open(fileList[r], mode='r', encoding='utf-8').read()
file1 = del_reg(file1)
file2 = del_reg(file2)
#提取文本里的关键词
keyword1 = jieba.analyse.extract_tags(file1, topK=200, withWeight=False)
keyword2 = jieba.analyse.extract_tags(file2, topK=200, withWeight=False)
#将文档1和文档2提取到的关键词合并成一个集合
word_set = set(keyword1).union(set(keyword2))
#建立一个词典
word_dict = dict()
i = 0
#将两篇文章出现的关键词存入到字典里
for word in word_set:
word_dict[word] = i
i += 1
file1_code = code(keyword1, word_dict)
file2_code = code(keyword2, word_dict)
result = cos(file1_code, file2_code)
print("文档1和文档%d的相似度是:%.2f" % (r+1, result))
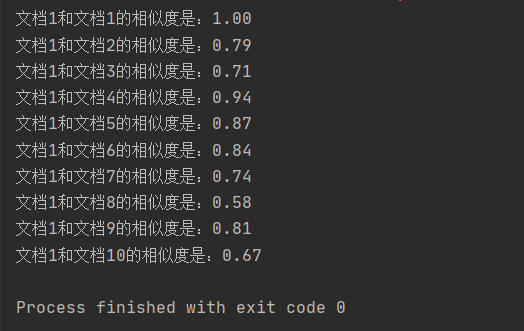
输出结果还是可以接受的吧,至少不是毫无区分度,嗯,是这样

1-5计算模块部分异常处理说明。
1.当给出路径不存在可以读取的文件时:

2.当进行余弦计算时出现0:

1-6psp表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 80 |
| Estimate | 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | 40 | 60 |
| Analysis | 需求分析 (包括学习新技术) | 300 | 360 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 10 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 60 |
| Design | 具体设计 | 40 | 40 |
| Coding | 具体编码 | 240 | 300 |
| Code Review | 代码复审 | 60 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 40 | 100 |
| Reporting | 报告 | 60 | 60 |
| Test Repor | 测试报告 | 40 | 50 |
| Size Measurement | 计算工作量 | 60 | 40 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 40 |
| 合计 | 1010 | 1390 |
一些总结:
刚开始看到这个题目,完全懵逼状态,这是我能做出来的??在查阅了n多资料后,慢慢地,磨出了一行又一行代码,虽然还是很粗糙,用的也是最简单的方法,但起码是自己敲出来的不是?最大的收获当然是这个过程中学到许多python库的调用及模型的建立,虽然都没用上(下次一定)然后还没来得及开心一下,?github?性能提升?一堆闻所未闻的东西再一次把我击沉,然后很多东西还是英文,只能畏畏缩缩地打开翻译软件。。。一大堆操作下来,才对工程这个概念有更深刻的体会,code!=project 看下来对这些操作应该是熟悉了一点点。。下次的作业应该会比较容易上手。吧?
