

WordCountPro
基本任务:代码编写+单元测试
GitHub项目地址
https://github.com/Hoyifei/SQ-T-Homework-WordCount-Advanced
PSP表格
| PSP | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| ·Estimate | 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | 180 | 300 |
| ·Analysis | 需求分析 (包括学习新技术) | 30 | 30 |
| ·Design Spec | 生成设计文档 | 20 | 20 |
| ·Design Review | 设计复审 (和同事审核设计文档) | 20 | 10 |
| ·Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| ·Design | 具体设计 | 30 | 30 |
| ·Coding | 具体编码 | 120 | 180 |
| ·Code Review | 代码复审 | 20 | 30 |
| ·Test | 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | 30 | 50 |
| ·Test Report | 测试报告 | 30 | 30 |
| ·Size Measurement | 计算工作量 | 10 | 10 |
| ·Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 640 | 880 |
接口设计与实现
主要负责分词模块
主要实现思路如下:
1)记录当前是否位于单词里
2)字母一定属于单词
3)当‘-’的前后都是字母时,它属于单词,否则是分隔符
4)其它字符都是分隔符
5)读取到分隔符时,如果位于单词里则结束当前单词,调用endOfWordCallback
6)文件读取完毕后,如果位于单词中,结束当前单词
7)在本模块里不进行大小写的处理
分词模块会读取一个文本文件并著字符扫描,在扫描过程中调用这样一个回调函数的接口
public interface WordSplitterCallback {
/**
* When the WordSplitter decided that a char belongs to current word, it will call this to append the char to current word.
*
* @param ch The char to be append.
*/
void appendCharCallback(char ch);
/**
* When thed WordSplitter find the end of current word, it will call this to inform that the current word is over.
*/
void endOfWordCallback();
}
当分词模块认为当前字符属于单词时,将会调用appendCharCallback函数
当它认为当前字符不属于单词,当前单词应该结束时,调用endOfWordCallback函数。当连续地出现多个不属于单词的字符时,只调用一次endOfWordCallback
分词模块本身的接口如下
public class WordSplitter {
public WordSplitter(WordSplitterCallback cb, String filename) throws IOException {
}
public void split() {
}
}
构造函数接受文件名和回调函数作为参数,split函数执行整个分词过程。
测试用例设计
测试的形式是读入一个文本文件,输出分词结果。
测试用例包含部分设计构造的文件和随机生成的已知结果的较大文件,设计的测试文件如下:
case1:测试基本的分词和对非法字符的处理(视为分隔符并忽略)
case2:测试对单词内部的连字符的处理
case3:测试对单词末尾出现的连字符的处理
case4:测试对连续多个连字符的处理(认为它们是分隔符)
case5:测试含数字的单词
| Test Case ID 测试用例编号 | Test Item 测试项(即功能模块或函数) | Test Case Title 测试用例标题 | Test Criticality重要级别实际耗时(分钟) | Pre-condition预置条件 | Input 输入 | Procedure 操作步骤 | Output 预期结果 | Result实际结果 | Status是否通过计划 | Remark 备注(在此描述使用的测试方法) |
|---|---|---|---|---|---|---|---|---|---|---|
| Sp_1 | 分词模块 | 基本的分词和对非法字符的处理 | H | 无 | Splitter_testcase1.txt | 无 | T | T | 是 | 白盒测试 |
| Sp_2 | 分词模块 | 测试对单词内部的连字符的处理 | H | 无 | Splitter_testcase2.txt | 无 | T | T | 是 | 白盒测试 |
| Sp_3 | 分词模块 | 对单词末尾出现的连字符的处理 | H | 无 | Splitter_testcase3.txt | 无 | T | T | 是 | 白盒测试 |
| Sp_4 | 分词模块 | 对连续多个连字符的处理 | H | 无 | Splitter_testcase4.txt | 无 | T | T | 是 | 白盒测试 |
| Sp_5 | 分词模块 | 含数字的单词 | H | 无 | Splitter_testcase5.txt | 无 | T | T | 是 | 白盒测试 |
| Sp_6 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase6.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_7 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase7.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_8 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase8.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_9 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase9.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_10 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase10.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_11 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase11.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_12 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase12.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_13 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase13.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_14 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase14.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_15 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase15.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_16 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase16.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_17 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase17.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_18 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase18.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_19 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase19.txt | 无 | T | T | 是 | 黑盒测试 |
| Sp_20 | 分词模块 | 大数据实例 | M | 无 | Splitter_testcase20.txt | 无 | T | T | 是 | 黑盒测试 |
测试评价
单元测试运行截图:
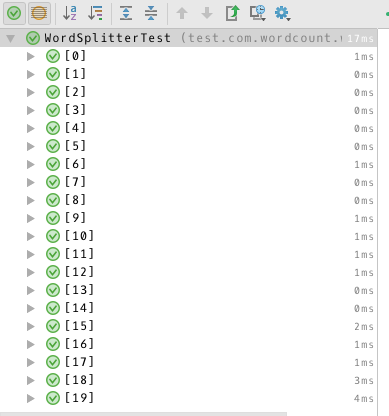
测试用例均通过了测试,运行时间短,效率符合要求。测试用例覆盖了可能出现的输入情况,并生成了实例进行测试,结果符合预期。
扩展任务:静态测试
开发规范
选用了《阿里巴巴Java开发手册》规范中编程规约的命名格式及代码格式部分。如大括号的使用约定。如果是大括号内为空,则简洁地写成{}即可,不需要换行;如果 是非空代码块则: 1) 左大括号前不换行。 2) 左大括号后换行。 3) 右大括号前换行。 4) 右大括号后还有 else 等代码则不换行;表示终止的右大大括号的使用约定。如果是大括号内为空,则简洁地写成{}即可,不需要换行;如果 是非空代码块则: 1) 左大括号前不换行。 2) 左大括号后换行。 3) 右大括号前换行。 4) 右大括号后还有 else 等代码则不换行;表示终止的右大括号后必须换行。说明:按照代码格式编写出的代码易于检查,同时方便他人的阅读和修改。
代码分析
使用该规范分析了学号后5位为17073的同学提交的代码。代码格式基本符合要求,问题:缩进并未用4个空格而是tab,有些变量及函数的命名不清晰,缩写不规范。
静态代码工具:
扫描工具:intelliJ IDEA插件
下载地址:https://www.jetbrains.com/idea/
扫描结果:安装插件后,扫描与程序编写同时进行,即时改正了编写的错误和警告,故无统计结果。
结果分析:最终代码符合规范,过程中出现了代码缩进未用4个空格,变量命名不规范,引用类时使用其对象的错误及警告等。
组内评价
小组最终代码注释均偏少,部分命名不规范,难理解。改进:商议命名规范,同时遵循开发规范中命名风格的要求,尽量是命名清晰易懂。
高级任务:性能测试和优化
设计思路
采用整体测试的数据生成步骤,但不对答案进行判断,使用数据量大的英文小说和随机生成的文本内容跟复杂的文件作为系统的输入文件。
性能指标
程序运行的时间,即分词,计数和排序模块和输出的用时。
同行评审
组内成员共同进行同行评审,组长主持,经讨论,认为影响程序性能的因素主要在分词模块对输入文件的读入以及单词的排序算法上。
测试结果
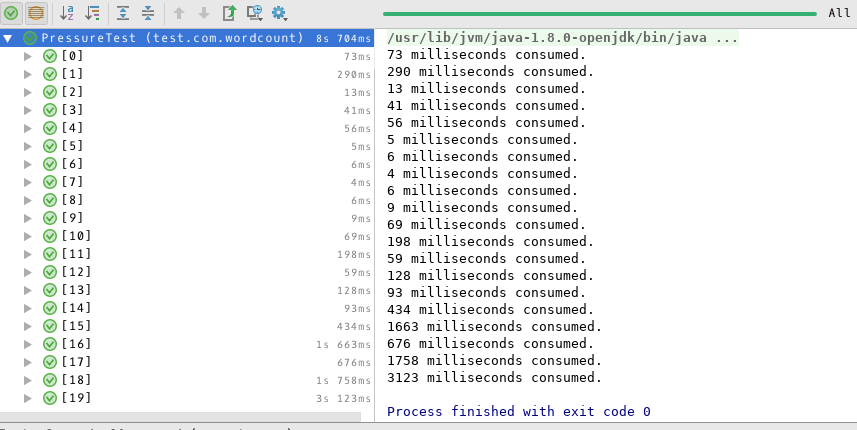
所有的压力测试用时较短,系统的质量水平较高,但文件偏大时,耗时明显增多,故影响程序性能的主要因素为文件的读入和单词的计数,而排序算法对性能的影响并不大,结果与评审有出入。
性能优化
对于文件读入,可以通过硬件优化实现性能的提高,单词计数可以通过优化计数算法,改进时间复杂度提升性能。优化后程序性能指标为程序运行的时间和内存占用。
小结
软件开发是主题,为软件测试提供对象,没有软件开发,就没有测试。软件测试对于软件开发来说是多方位的,对程序准确性(动态,静态),程序性能等,没有测试,软件开发是不完整的。同时,软件测试的结果便是软件质量的表达,所以软件测试是软件质量的保证。所以,软件开发是软件测试的基础,但同时又需要软件测试提高软件质量。开发和测试相辅相成,都以软件的高质量为目标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号