linux云计算Openstack创建虚拟机步骤2(nova组件 控制节点和计算节点)
Nova服务 组件介绍
1.Nova服务部署 工作流程
nova 计算服务(经典)一 套控制器openstack 框架
nova- api: 接收处理外界实例相关请求(创建实例) (os cpu网络等 配置 )
把实例元数据写到nova数据库
请求放到消息队列(消息队列实现异步通信 )
nova-scheduler: 调度-- 选择最合适的计算节点来创建实例
nova- compute: 创建实例(具体干活) -- hypervisor来管理一 driver
nova-conductor: 对接nova数据库 computer通过消息队列连接到数据库
openstack 分布式
nova 分层各司其职
公司

2.工作流程 6步
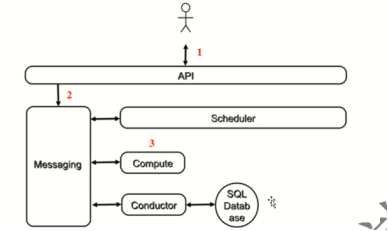
简单来说
1.用户发起请求
2.Apl请求发送消息队列 进行调度scheduler(Apl接受请求,写到数据库中)
3.调度结果放到队列中 分配到主机上的任务 分配到哪台机器哪台机器取这个调度结果消息
4.消息队列通过conductor从数据库中取消息
5.取完之后将信息通过消息队列发送到computer主机上
1.客户(可以是OpenStack最终用户,也可以是其他程序)向API(nova-api)发送请求:“帮我创建一个虚机”;
2.API对请求做一些必要处理后,向Messaging(RabbitMQ)发送了一条消息:“让Scheduler创建一个虚机”;
3.Scheduler(nova-scheduler)从Messaging获取到API发给它的消息,然后执行调度算法,从若干计算节点中选出节点 A ;
4.Scheduler向Messaging发送了一条消息:“在计算节点 A 上创建这个虚机”
5.计算节点 A 的Compute(nova-compute)从Messaging中获取到Scheduler发给它的消息,然后在本节点的Hypervisor上启动虚机;
6.在虚机创建的过程中,Compute如果需要查询或更新数据库信息,会通过Messaging向Conductor(nova-conductor)发送消息,Conductor负责数据库访问。
2.Openstack 通用设计思路 Nova组件介绍
1.设计思路
Openstack设计思路
API前端服务
Scheduler调度服务
Worker工作服务
Driver框架
2.组件介绍
Nova由很多子服务组成,同时OpenStack是一个分布式系统,对于Nova这些服务会部署在两类节点上,计算节点和控制节点,
计算节点上安装了Hypervisor,上面运行虚拟机,只有nova-compute需要放在计算节点上,其他子服务则是放在控制节点上的。
lnova-api
lnova-api-metadata
lnova-compute
lnova-placement-api
lnova-scheduler
lnova-conductor
lnova-consoleauth
lnova-novncproxy
lThe queue
lSQL database
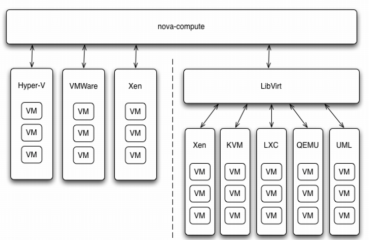
3.Nova支持 的hypervisor
nova-compute运行在计算节点上,通过插件形式对Hypervisor进行管理,当前的版本(Ocata),对各种主流的虚拟化平台都提供了支持,
典型地通过XenAPI/vCenter API/Libvirt等所提供的插件接口执行虚拟机的创建、终止、迁移等生命周期管理。
4.Nova操作指令
常规操作
常规操作中,Launch、Start、Reboot、Shut Off 和 Terminate 都很好理解。
Resize
通过应用不同的 flavor 分配给 instance 的资源。
Lock/Unlock
可以防止对 instance 的误操作。
Pause/Suspend/Resume
暂停当前 instance,并在以后恢复。 Pause 和 Suspend 的区别在于 Pause 将 instance 的运行状态保存在计算节点的内存中,而 Suspend 保存在磁盘上。
Pause 的优点是 Resume 速度比 Suspend 快;
缺点是如果计算节点因某种原因重启,内存数据丢失,就无法 Resume 了,而 Suspend 则没有这个问题。
Snapshot
备份 instance 到 Glance。 Snapshot 生成的 image 可用于故障恢复,或者以此为模板部署新的 instance。
3.Nova控制节点 服务案例 做一个主键之前 先建立数据库
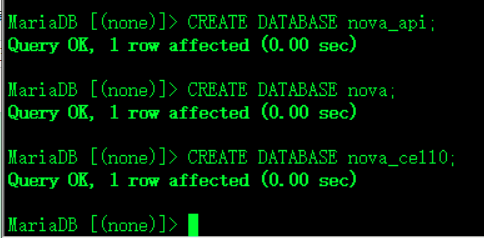
1.Nova创建三个数据库 授权
mysql -u root -p123登录数据库
CREATE DATABASE nova_api;创建三个库
CREATE DATABASE nova;
CREATE DATABASE nova_cell0;Cell单元格的意思
sql数据库和消息队列压力最大
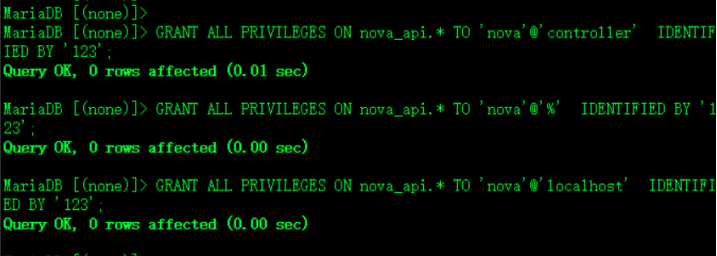
授权每个库三个权
GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'controller' IDENTIFIED BY '123';
GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'%' IDENTIFIED BY '123';
GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'localhost' IDENTIFIED BY '123';
GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'controller' IDENTIFIED BY '123';
GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'%' IDENTIFIED BY '123';
GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'localhost' IDENTIFIED BY '123';
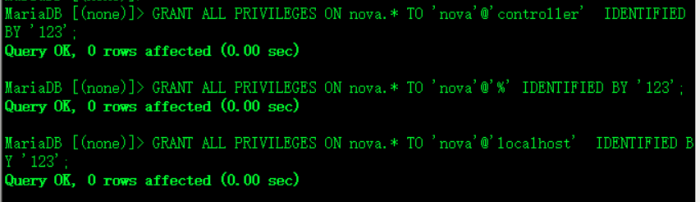
GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'controllert' IDENTIFIED BY '123';
GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'%' IDENTIFIED BY '123';
GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'localhost' IDENTIFIED BY '123';
2.注册keystone消息创建nova用户绑定角色 暴露url 端口为8774
创建用户
. admin.sh
openstack user create --domain default --password-prompt nova
openstack role add --project service --user nova admin绑定admin角色
注册service服务 暴露出url 端口为 8774
注意 --符号问题
openstack service create --name nova --description "OpenStack Compute" compute注册服务service
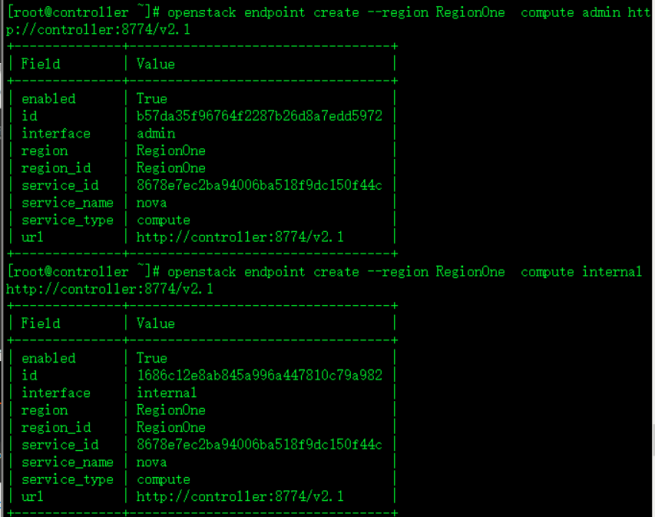
openstack endpoint create --region RegionOne compute public http://controller:8774/v2.1
openstack endpoint create --region RegionOne compute admin http://controller:8774/v2.1
openstack endpoint create --region RegionOne compute internal http://controller:8774/v2.1
3.再创建placement用户 添加角色 注册服务 暴露endpoint 的url 端口为8778
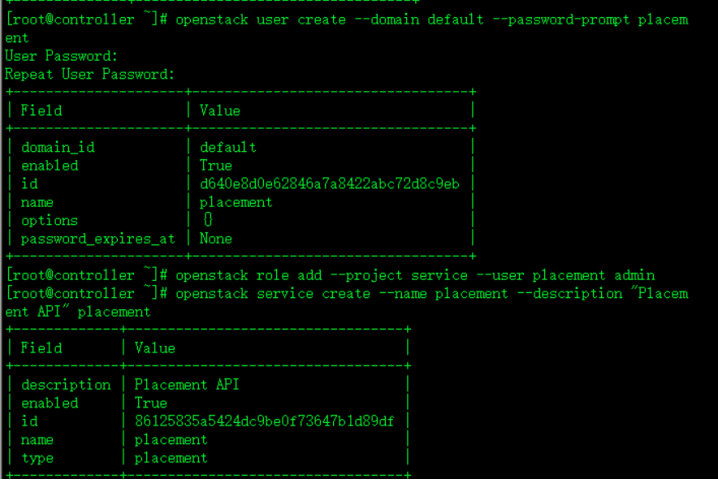
openstack user create --domain default --password-prompt placement
openstack role add --project service --user placement admin为placement创建角色 为admin
openstack service create --name placement --description "Placement API" placement 注册服务
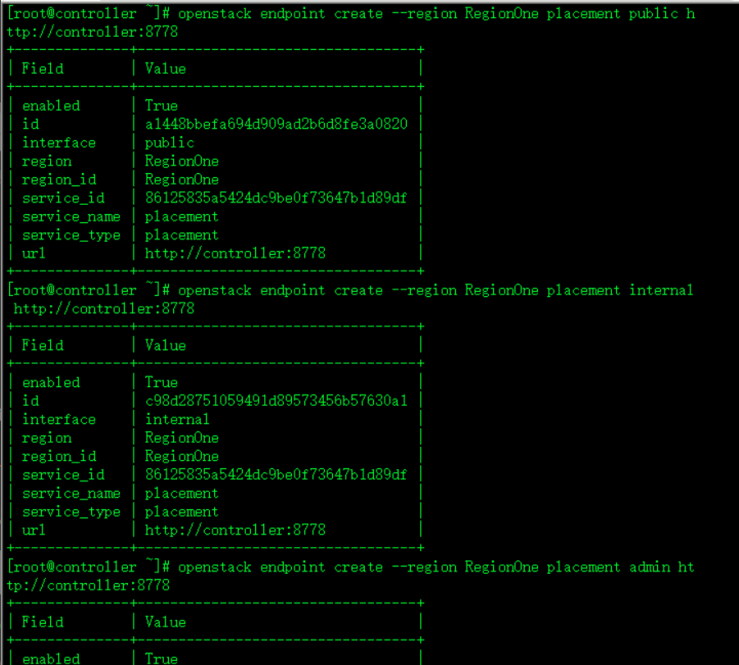
openstack endpoint create --region RegionOne placement public http://controller:8778
openstack endpoint create --region RegionOne placement internal http://controller:8778
openstack endpoint create --region RegionOne placement admin http://controller:8778
注意 :controlle可暴露出去写公网IP也可以
4.安装软件包 修改配置文件/etc/nova/nova.conf (修改9处)
yum install openstack-nova-api openstack-nova-conductor openstack-nova-console openstack-nova-novncproxy openstack-nova-scheduler openstack-nova-placement-api-y安装五个软件包
vim /etc/nova/nova.conf
1.
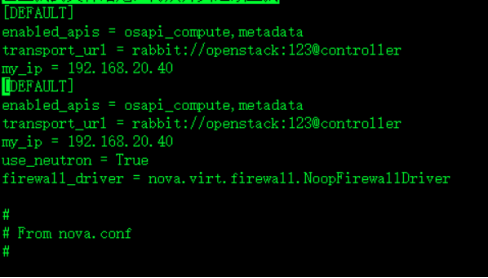
[DEFAULT]
enabled_apis = osapi_compute,metadata
transport_url = rabbit://openstack:123@controller
my_ip = 192.168.20.40控制节点IP
use_neutron = True启用neutron
firewall_driver = nova.virt.firewall.NoopFirewallDriver
2.
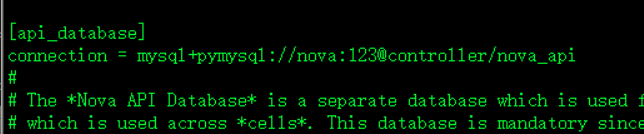
[api_database]api库
connection = mysql+pymysql://nova:123@controller/nova_api
3.
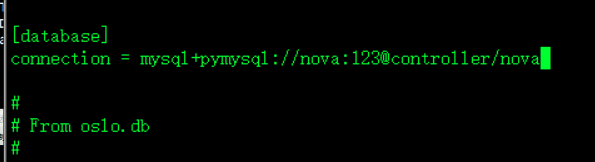
[database] 主库
connection = mysql+pymysql://nova:123@controller/nova
4.
[api]指定认证方式
auth_strategy = keystone

5.
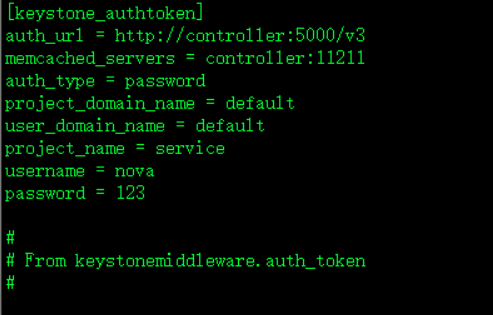
[keystone_authtoken]认证
auth_url = http://controller:5000/v3
memcached_servers = controller:11211
auth_type = password
project_domain_name = default
user_domain_name = default
project_name = service
username = nova
password = 123
6.
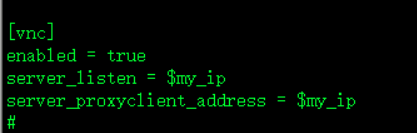
[vnc]
enabled = true开启vnc
server_listen = $my_ip监听控制节点我的IP
server_proxyclient_address = $my_ip
7.
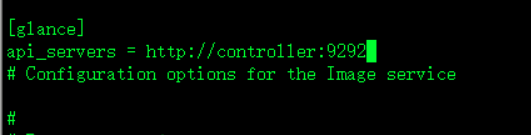
[glance]镜像地址
api_servers = http://controller:9292
8.
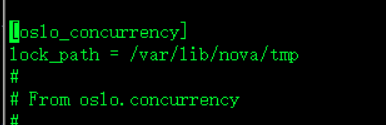
[oslo_concurrency]锁路径这是关于文件锁的机制
lock_path = /var/lib/nova/tmp
9.
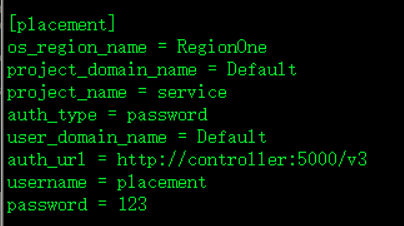
[placement]调度服务user对应的信息
os_region_name = RegionOne
project_domain_name = Default
project_name = service
auth_type = password
user_domain_name = Default
auth_url = http://controller:5000/v3
username = placement
password = 123
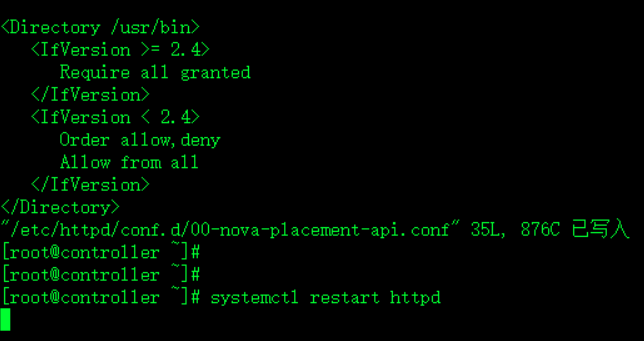
5.因为安装包packaging有bug 修复bug 修改httpd的配置文件(增加一个标签对)
vim /etc/httpd/conf.d/00-nova-placement-api.conf
<Directory /usr/bin>
<IfVersion >= 2.4>
Require all granted
</IfVersion>
<IfVersion < 2.4>
Order allow,deny
Allow from all
</IfVersion>
</Directory>
systemctl restart httpd
6.填充数据库 注册cell0 和创建cell1
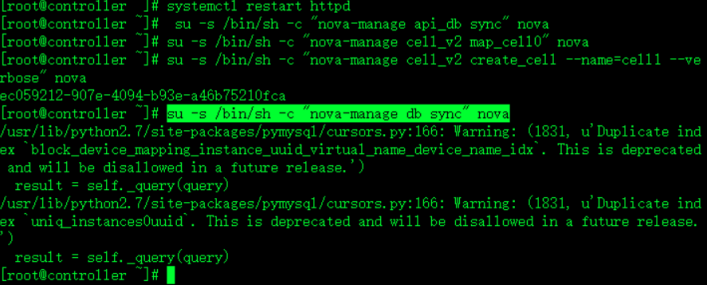
su -s /bin/sh -c "nova-manage api_db sync" nova填充api数据库
su -s /bin/sh -c "nova-manage cell_v2 map_cell0" nova注册cello0
su -s /bin/sh -c "nova-manage cell_v2 create_cell --name=cell1 --verbose" nova创建cell1
su -s /bin/sh -c "nova-manage db sync" nova填充nova数据库
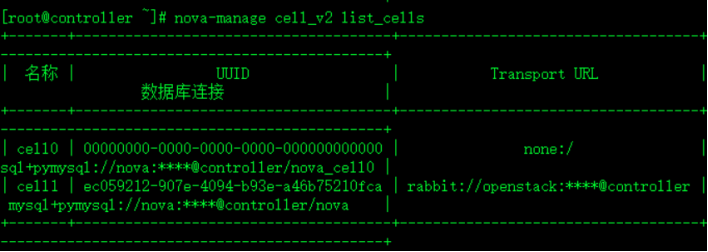
nova-manage cell_v2 list_cells验证查看列表
7.启动这五个服务 查看状态 (服务出错解决方法)
启动服务 开机自启 rabbitmqctl服务启动失败解决方法
systemctl enable openstack-nova-api.service \
openstack-nova-consoleauth.service openstack-nova-scheduler.service \
openstack-nova-conductor.service openstack-nova-novncproxy.service
systemctl start openstack-nova-api.service \
openstack-nova-consoleauth.service openstack-nova-scheduler.service \
openstack-nova-conductor.service openstack-nova-novncproxy.service
查看状态
systemctl status openstack-nova-api.service openstack-nova-consoleauth.service openstack-nova-scheduler.service openstack-nova-conductor.service openstack-nova-novncproxy.service
systemctl status openstack-nova-api.service openstack-nova-consoleauth.service openstack-nova-scheduler.service openstack-nova-conductor.service openstack-nova-novncproxy.service | grep "running" | wc -l统计正在运行的服务
8.openstack-nova-scheduler服务出错 因为缺少openstack的rabbitmqctl 用户 解决方法
假如说控制节点报错启动五个服务 其中openstack-nova-consoleauth 和 openstack-nova-scheduler 服务起不来
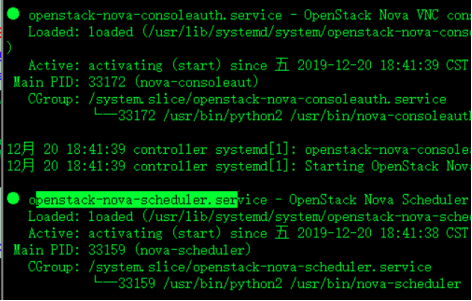
方法 查看日志
cd /var/log/nova/
tail -f nova-scheduler.log 意思是缺少用户

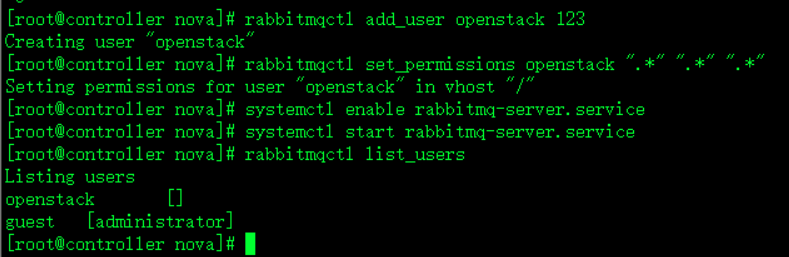
rabbitmqctl list_users此时在控制节点查看rabbitmq用户
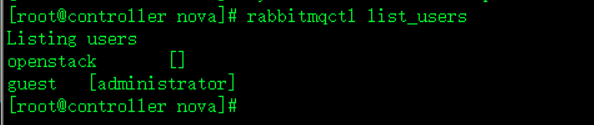
发现之前创建的openstack用户不见了
rabbitmqctl add_user openstack 123重新添加openstack用户
rabbitmqctl set_permissions openstack “." ".” “.*”赋予权限
systemctl start rabbitmq-server.service启动服务
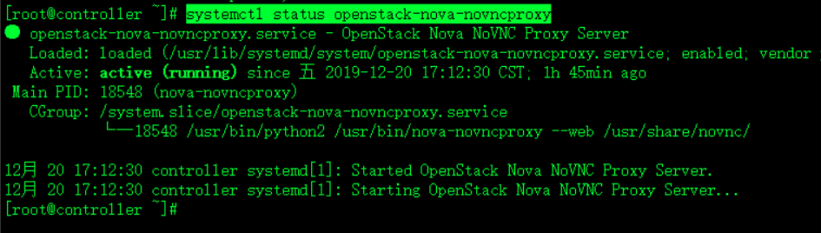
再次查看状态
systemctl status openstack-nova-novncproxy
4.计算节点上的nova部署 安装nova软件包,修改配置启动服务,控制节点验证注意关闭防火墙selinux
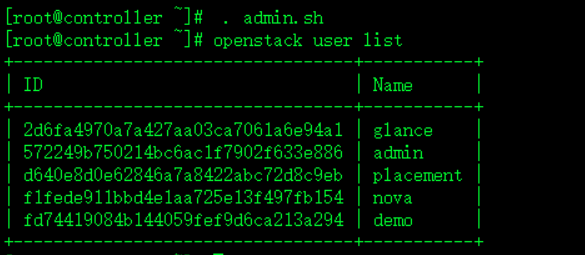
1.检测 控制节点的user endpoint 镜像和service列表(四个列表)
. admin.sh
openstack user list
openstack endpoint list

查看镜像 和service
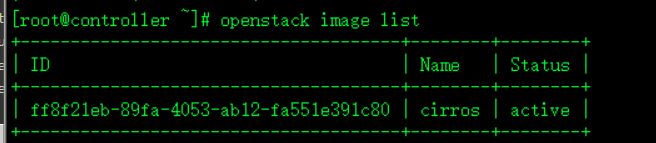
openstack image list
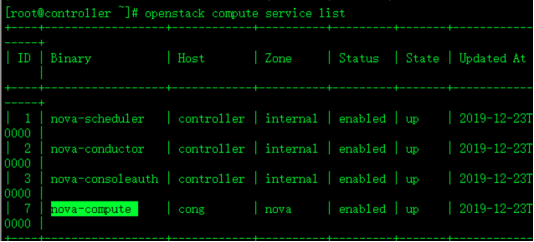
openstack compute service list未做实验的computer 的service
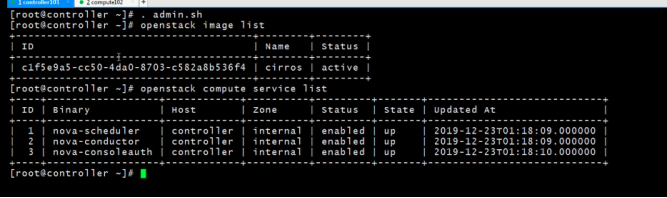
这个是做完计算节点后验证出来的新的computer
2.计算节点下载安装nova包 修改yum源,下载
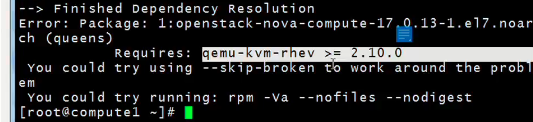
yum install openstack-nova-compute -y下载安装包会发现少这个安装包
vim /etc/yum.repos.d/CentOS-Base.repo再原有的yum配置里面增加virt镜像包
yum makecache :q建立
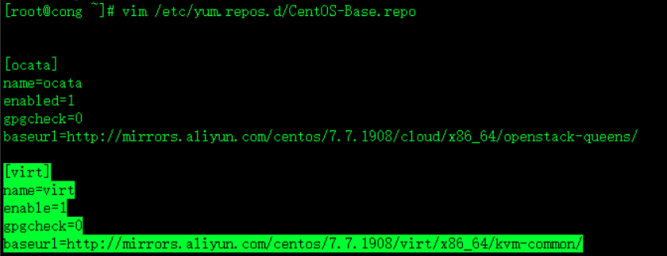
[virt]
name=virt
enable=1
gpgcheck=0
baseurl=http://mirrors.aliyun.com/centos/7.7.1908/virt/x86_64/kvm-common/
3.修改计算节点 nova主配置文件(6处)
vim /etc/nova/nova.conf
1.
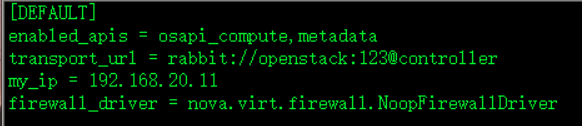
[DEFAULT]
enabled_apis = osapi_compute,metadata
transport_url = rabbit://openstack:123@controller
my_ip = 192.168.20.11
firewall_driver = nova.virt.firewall.NoopFirewallDriver
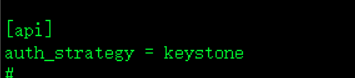
2.
[api]
auth_strategy = keystone
3.
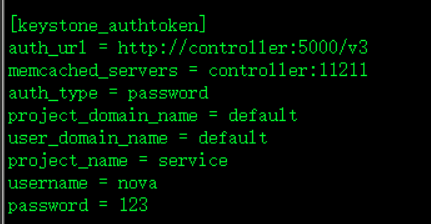
[keystone_authtoken]
auth_url = http://controller:5000/v3
memcached_servers = controller:11211
auth_type = password
project_domain_name = default
user_domain_name = default
project_name = service
username = nova
password = 123
4.
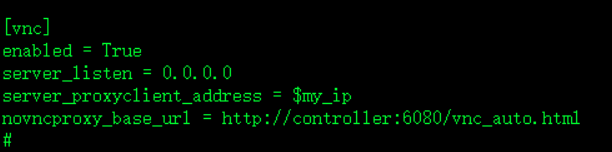
[vnc]
enabled = True
server_listen = 0.0.0.0
server_proxyclient_address = $my_ip
novncproxy_base_url = http://controller:6080/vnc_auto.html
5.
[oslo_concurrency]
lock_path = /var/lib/nova/tmp

6.
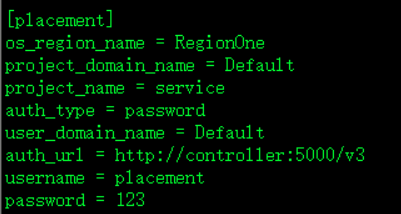
[placement]
os_region_name = RegionOne
project_domain_name = Default
project_name = service
auth_type = password
user_domain_name = Default
auth_url = http://controller:5000/v3
username = placement
password = 123
4.确定计算节点是否支持虚拟机硬件加速 若为0,修改配置文件 启动服务
egrep -c '(vmx|svm)' /proc/cpuinfo确定计算节点是否支持虚拟机的硬件加速
如果此命令返回一个或更大的值,则compute节点支持硬件加速,这通常不需要额外的配置。
如果此命令返回的值为0,则计算节点不支持硬件加速,必须配置libvirt来使用QEMU而不是KVM。
2.编辑/etc/nova/nova.conf文件中的[libvirt]部分
vim /etc/nova/nova.conf
[libvirt]
virt_type = qemu
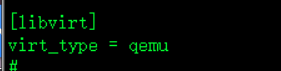
启动服务看selinux状态,主机名
systemctl enable libvirtd.service openstack-nova-compute.service
systemctl start libvirtd.service openstack-nova-compute.service
check /var/log/nova/nova-compute.log如果报错查看
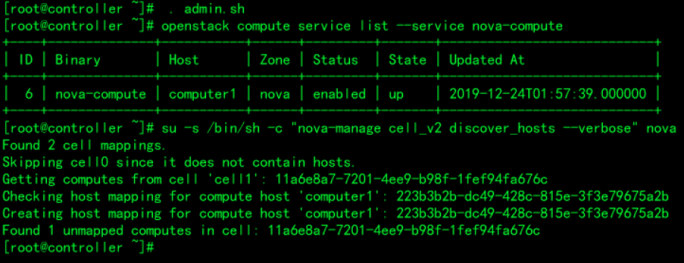
5.控制节点上 填充数据库 将计算节点添加到cell数据库操作中
将计算节点添加到cell数据库操作中
. admin.sh
openstack compute service list --service nova-compute
su -s /bin/sh -c "nova-manage cell_v2 discover_hosts --verbose" nova填充库
来源的管理凭据,以启用只管理的CLI命令,然后确认在数据库中有计算主机:
假如 添加新的计算节点时,必须在控制器节点上运行nova-manage cell_v2 discover_hosts来注册这些新的计
算节点。或者,可以在/etc/nova/nova.conf中设置一个适当的间隔

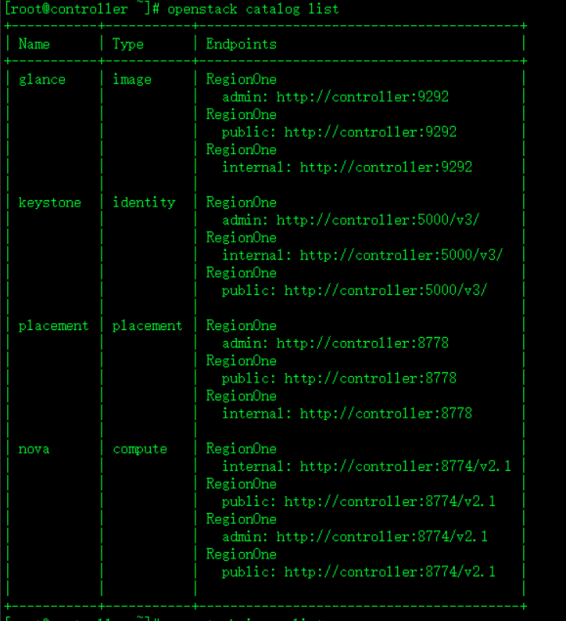
6.验证 控制节点上 查看computer service和catalog和image列表 查看更新
. admin.sh
openstack compute service list

openstack catalog list
openstack image list
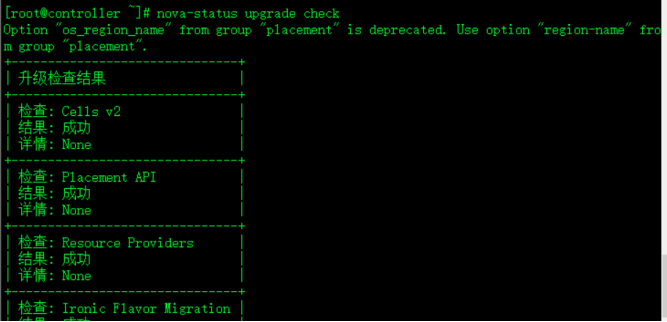
nova-status upgrade check查看更新
4.计算服务nova各子组件工作详解
nova-api
nova-api 是整个 Nova 组件的门户,所有对 Nova 的请求都首先由 nova-api 处理。nova-api 向外界暴露若干 HTTP REST API 接口, 在 keystone 中可以查询 nova-api 的 endponits。
客户端就可以将请求发送到 endponits 指定的地址,向 nova-api 请求操作。 当然,作为最终用户的我们不会直接发送 Rest AP I请求。 OpenStack CLI,Dashboard 和其他需要跟 Nova 交换的组件会使用这些 API。
nova-conductor
nova-compute 需要获取和更新数据库中 instance 的信息。但 nova-compute 并不会直接访问数据库,而是通过 nova-conductor 实现数据的访问。
这样做有两个显著好处:
1.更高的系统安全性
2.更好的系统伸缩性
nova-scheduler
nova-scheduler 如何选择计算节点
nova-scheduler 的调度机制和实现方法:即解决如何选择在哪个计算节点上启动 instance 的问题。
创建 Instance 时,用户会提出资源需求,例如 CPU、内存、磁盘各需要多少。OpenStack 将这些需求定义在 flavor 中,用户只需要指定用哪个 flavor 就可以了。
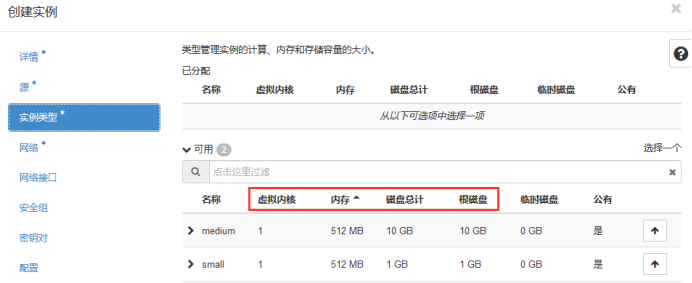
可用的 flavor 在 System->Flavors 中管理。
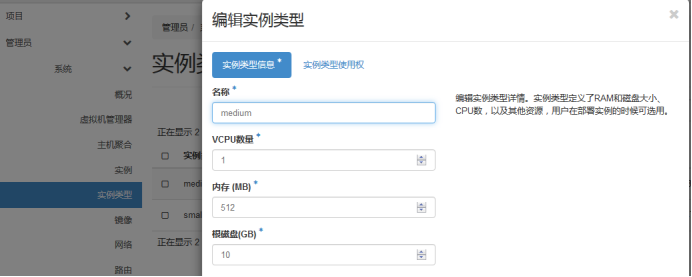
Flavor 主要定义了 VCPU,RAM,DISK 和 Metadata 这四类。 nova-scheduler 会按照 flavor 去选择合适的计算节点。
Filter scheduler
Filter scheduler 是 nova-scheduler 默认的调度器,调度过程分为两步:
1.通过过滤器(filter)选择满足条件的计算节点(运行 nova-compute)
2.通过权重计算(weighting)选择在最优(权重值最大)的计算节点上创建 Instance。
RetryFilter
RetryFilter 的作用是刷掉之前已经调度过的节点。
AvailabilityZoneFilter
为提高容灾性和提供隔离服务,可以将计算节点划分到不同的Availability Zone中。例如把一个机架上的机器划分在一个 Availability Zone 中。 OpenStack 默认有一个命名为 “Nova” 的 Availability Zone,所有的计算节点初始都是放在 “Nova” 中。 用户可根据需要创建自己的 Availability Zone。
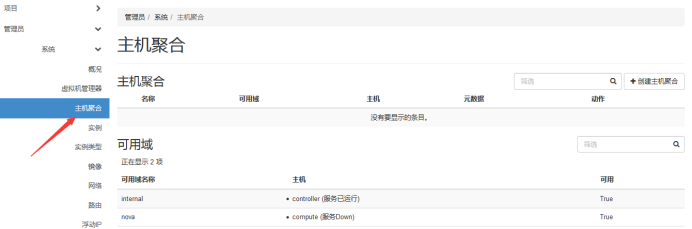
RamFilter
RamFilter 将不能满足 flavor 内存需求的计算节点过滤掉。
DiskFilter
DiskFilter 将不能满足 flavor 磁盘需求的计算节点过滤掉。
CoreFilter
CoreFilter 将不能满足 flavor vCPU 需求的计算节点过滤掉。
nova-compute
nova-compute 的功能可以分为两类:
1.定时向 OpenStack 报告计算节点的状态
2.实现 instance 生命周期的管理
定期向 OpenStack 报告计算节点的状态
nova-scheduler 的很多 Filter 是根据计算节点的资源使用情况进行过滤的。比如 RamFilter 要检查计算节点当前可以的内存量;CoreFilter 检查可用的 vCPU 数量;DiskFilter 则会检查可用的磁盘空间。
那么:OpenStack 是如何得知每个计算节点的这些信息呢?
nova-compute 会定期向 OpenStack 报告。从 nova-compute 的日志 /var/log/nova/nova-compute.log 可以发现: 每隔一段时间,nova-compute 就会报告当前计算节点的资源使用情况和 nova-compute 服务状态。

那nova-compute 是如何获得当前计算节点的资源使用信息的?
要得到计算节点的资源使用详细情况,需要知道当前节点上所有 instance 的资源占用信息。 这些信息谁最清楚? 当然是 Hypervisor。
nova-compute 可以通过 Hypervisor 的 driver 拿到这些信息。举例来说,在我们的实验环境下 Hypervisor 是 KVM,用的 Driver 是 LibvirtDriver。 LibvirtDriver 可以调用相关的 API 获得资源信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号