数据库select语句子查询和非关联子查询,关联子查询, 行列转换 行间比较 删除重复记录
select语句查询 行列转换 行间比较 删除重复记录
1.子查询 出现的位置 分类
子查询出现的位置
SELECT 列1,列2 ... from TABLE_NAME WHERE 列 = 值 GROUP BY 分组列 HAVING 分组列 = 值 ORDER BY 列
上面粗体蓝字的位置可以嵌套额外的SELECT语句(子查询),与外部主SELECT语句(主查询)结合起来使用,用一个查询语句实现更为复杂的任务。那些嵌套的SELECT语句往往被称为子查询;
子查询需要用括号( )括起来
分类
非关联子查询:子查询可以单独于主查询执行,仅执行1次,效率较高
关联子查询:子查询不能单独于主查询执行,如果主查询有N行,子查询将执行N次,效率相对较低,但灵活度高
2.非关联子查询6个案例
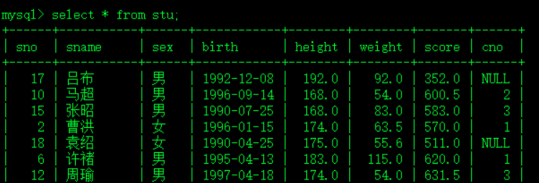
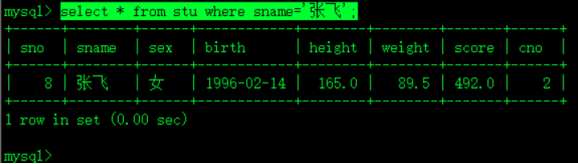
1.)查询学生中哪些人比张飞的体重重?
select * from stu;
select * from stu where sname='张飞'; 非关联子查询
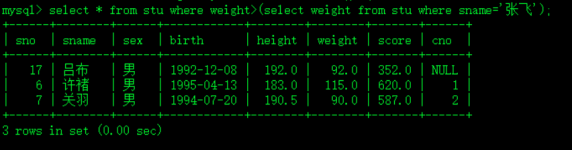
select * from stu where weight>(select weight from stu where sname='张飞');
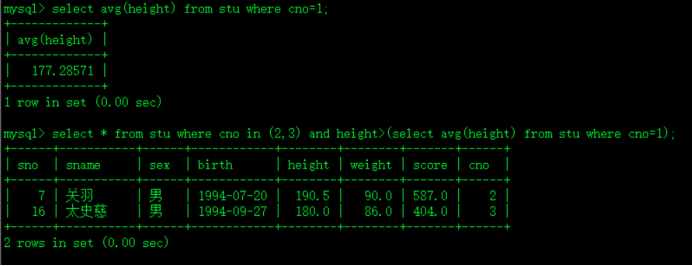
2.) 2班3班中哪些同学的身高比1班的平均身高高?
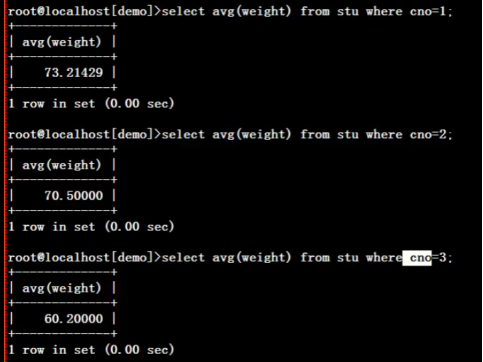
select avg(height) from stu where cno=1;查一班的平均身高
2班3班中哪些同学的身高比1班的平均身高高?
select * from stu where cno in (2,3) and height>(select avg(height) from stu where cno=1);
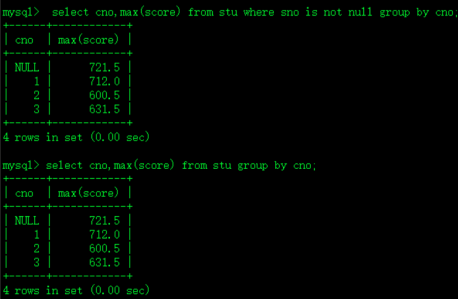
3.)每个班考分最高的同学都是谁?
select cno,max(score) from stu group by cno;每个班最高分
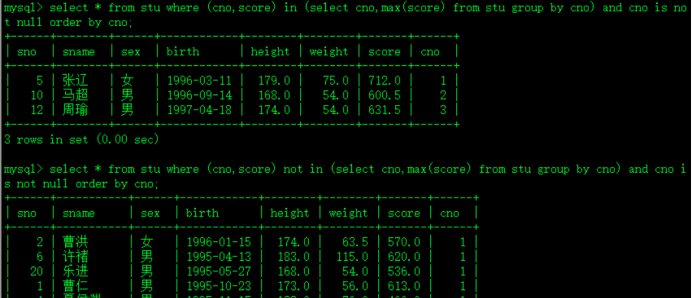
select * from stu where (cno,score) in (select cno,max(score) from stu group by cno) and cno is not null order by cno; not in
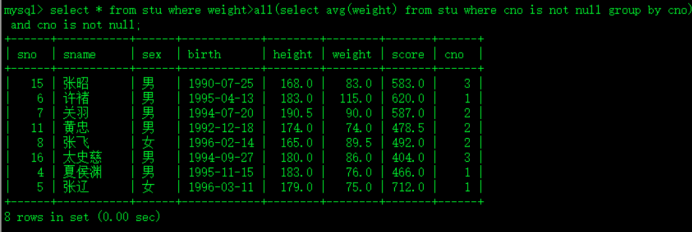
4.)哪些同学的体重比所有班的平均体重都重?
>ALL运算符:比所有的值都大 <ALL运算符:比所有的值都小 多行单列运算符
>ANY运算符:比最小的那个大就行 <ANY运算符:比最大的那个小就行
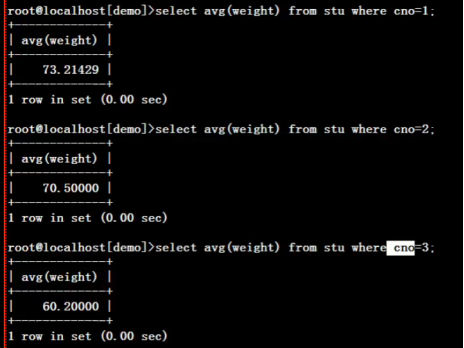
select avg(weight) from stu where cno is not null group by cno;每个班的平均体重
select avg(weight) from stu group by cno;
select * from stu where weight>all(select avg(weight) from stu where cno is not null group by cno) and cno is not null;
5.)哪些同学的身高高于本班的平均身高?
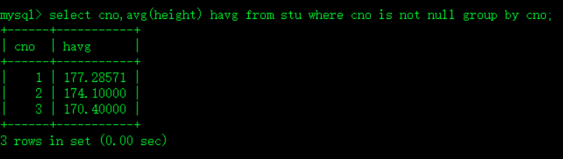
select * from stu s join (select cno,avg(height) havg from stu where cno is not null group by cno) t on s.cno=t.cno where height>havg order by s.cno;
From后面的子查询也叫内联视图, MySQL中这个内联视图子查询必须起个表别名,否则报错
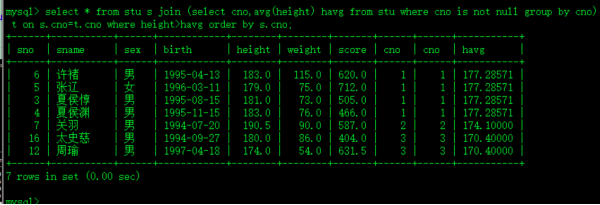
select cno,avg(height) havg from stu where cno is not null group by cno; 每个班平均身高 也叫内联视图
修改别名再查询内联视图
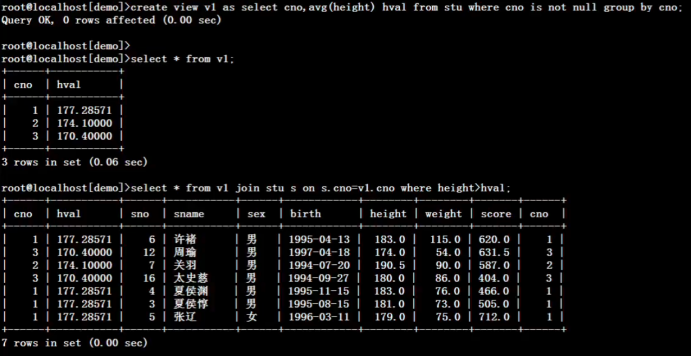
6.)不用多表连接方式,列出3班学生姓名和3班的班主任
select sname 学生姓名,(select teacher from class where cno=3) 班主任 from stu o where cno=3;老师和学生
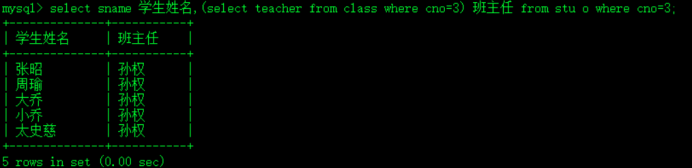
select teacher from class where cno=3;
select * from stu where cno=3;
3.关联子查询
1.)不用多表连接方式,列出每个学生的班号,姓名和其所在班的班主任
select o.cno 班号,o.sname 姓名,(select teacher from class where cno=o.cno) 班主任 from stu o where o.cno is not null order by o.cno,o.sname;
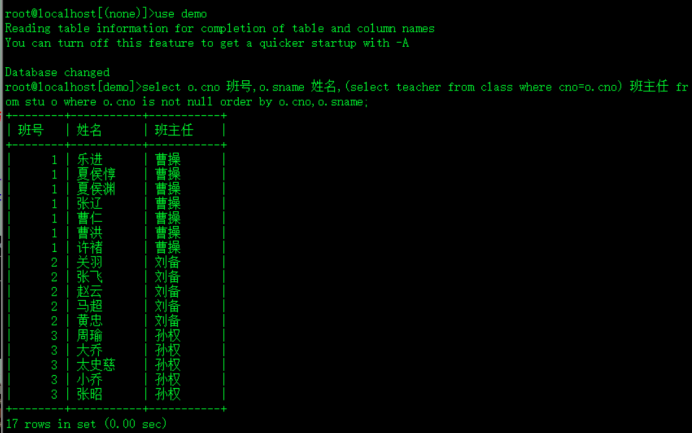
select sname,cno,(select teacher from class where cno=3) 班主任 from stu ;
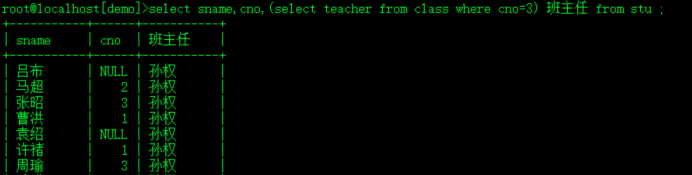
select sname,cno,(select teacher from class where cno=o.cno) 班主任 from stu o;
过程说明
特点:子查询不能单独执行,主查询必须起个别名
单独执行:select teacher from class where cno=o.cno; 报错,因为不知道o.cno中的o代表什么,o是外部主查询的别名,脱离了外部查询,子查询执行不了

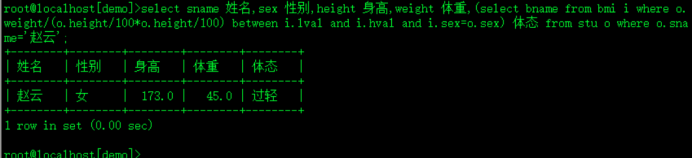
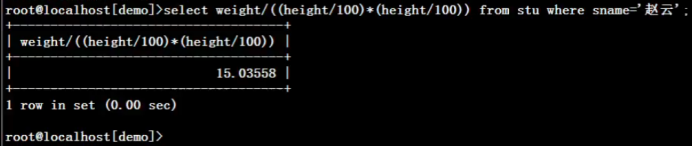
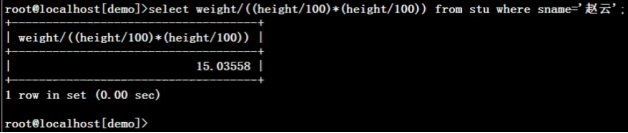
2.)不用多表连接方式,根据学生赵云的性别、身高和体重求出bmi体态(bname)
select sname 姓名,sex 性别,height 身高,weight 体重,(select bname from bmi i where o.weight/(o.height/100*o.height/100) between i.lval and i.hval and i.sex=o.sex) 体态 from stu o where o.sname='赵云';

三个班的平均体重
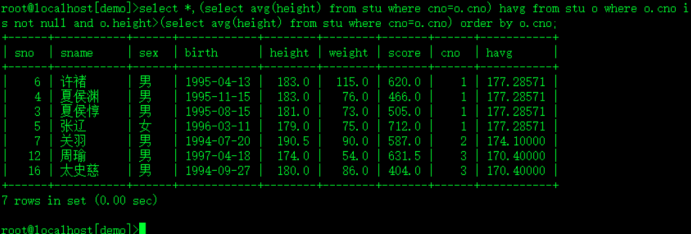
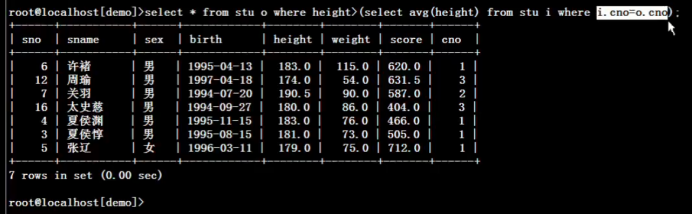
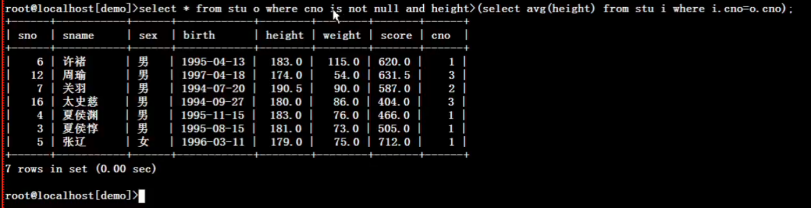
3.)使用关联子查询, 在已分班学生中 列出身高 高于本班平均身高 的学生
select *,(select avg(height) from stu where cno=o.cno) havg from stu o where o.cno is not null and o.height>(select avg(height) from stu where cno=o.cno) order by o.cno;

三个班的平均体重
去掉没分班求身高
4.SELECT - 查询综合练习:
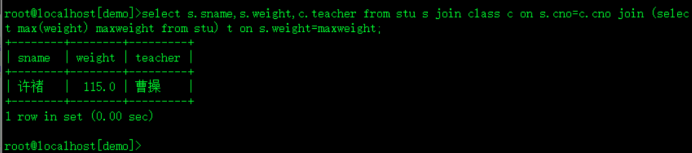
1.体重最重的同学的班主任是谁?
方法一:(多表连接 + 非关联子查询)
select sname,weight,teacher from stu s,class c where s.cno=c.cno and weight=(select max(weight) from stu);

方法二:(多表连接 + >=all + 非关联子查询)
select sname,weight,teacher from stu s,class c where s.cno=c.cno and weight>=all(select weight from stu);

方法三:(关联子查询 + 非关联子查询)
select sname,weight,(select teacher from class where cno=o.cno) teacher from stu o where weight=(select max(weight) from stu);

方法四:(多表连接 + 非关联子查询)
select s.sname,s.weight,c.teacher from stu s join class c on s.cno=c.cno join (select max(weight) maxweight from stu) t on s.weight=maxweight;
2.统计出所有班级的人数和学生列表,显示班号、班名、老师、人数、学生列表
方法一:(多表连接 + 分组)
select c.cno 班号,cname 班名,teacher 老师,count(s.cno) 人数,ifnull(group_concat(sname),'') 学生列表 from class c left join stu s on s.cno=c.cno group by c.cno,cname,teacher order by 1;

方法二:(关联子查询)
select cno 班号,cname 班名,teacher 老师,(select count(*) from stu where cno=c.cno) 人数,(select ifnull(group_concat(sname),'') 学生列表 from stu where cno=c.cno) 学生列表 from class c order by 1;

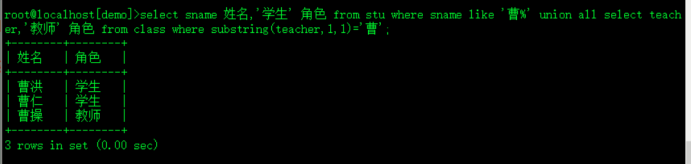
3.从学生表和班级表中找出姓曹的人,并标明其角色,学生或者教师
select sname 姓名,'学生' 角色 from stu where sname like '曹%' union all select teacher,'教师' 角色 from class where substring(teacher,1,1)='曹';
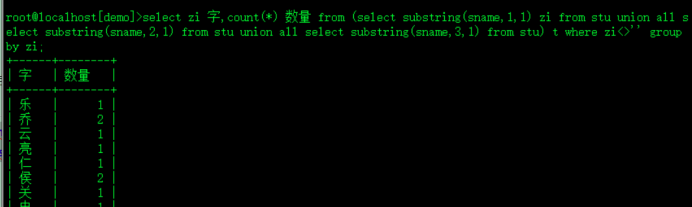
4.统计学生表中 所有学生的 姓名所用到的汉字,以及每个汉字用到的次数。即统计有多少个‘张’,多少个‘曹’,多少个‘刘’,多少个‘羽’等
算出名字最多几个字
select max(char_length(sname)) 最多字数 from stu;
用substr函数切割名字,用union all运算符叠加字,
形成的结果集作为内联视图,再按照不同字分组统计每个字的个数
select zi 字,count(*) 数量 from (select substring(sname,1,1) zi from stu union all select substring(sname,2,1) from stu union all select substring(sname,3,1) from stu) t where zi<>'' group by zi;
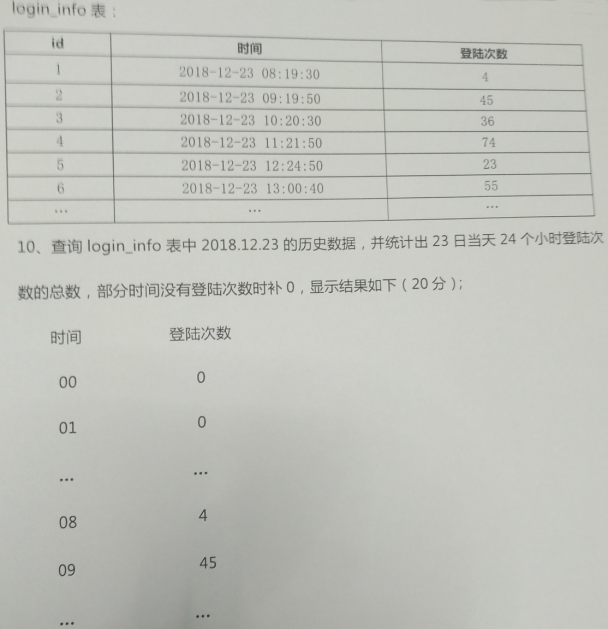
5.面试题
数据准备:建表
create table login_info (
id int,
login_time datetime,
login_count int
);
insert into `login_info` values (1, '2018-12-23 08:19:30', 4);
insert into `login_info` values (2, '2018-12-23 09:19:50', 45);
insert into `login_info` values (3, '2018-12-23 10:20:30', 36);
insert into `login_info` values (4, '2018-12-23 11:21:50', 74);
insert into `login_info` values (5, '2018-12-23 12:24:50', 23);
insert into `login_info` values (6, '2018-12-23 13:00:40', 55);
期望结果:

select hours 小时,ifnull(sum(login_count),0) 登录次数 from (
select '00' hours union all
select '01' union all
select '02' union all
select '03' union all
select '04' union all
select '05' union all
select '06' union all
select '07' union all
select '08' union all
select '09' union all
select '10' union all
select '11' union all
select '12' union all
select '13' union all
select '14' union all
select '15' union all
select '16' union all
select '17' union all
select '18' union all
select '19' union all
select '20' union all
select '21' union all
select '22' union all
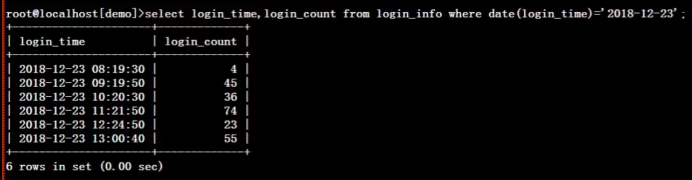
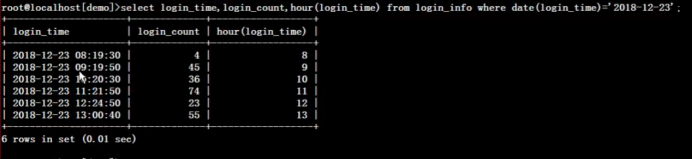
select '23') t left join (select * from login_info where date(login_time)='2018-12-23') l on t.hours=hour(l.login_time) group by hours order by hours;
6.查询方法补充示例 名词 分数 排名
给每个同学的身高排名,显示每个人由高到低的名次
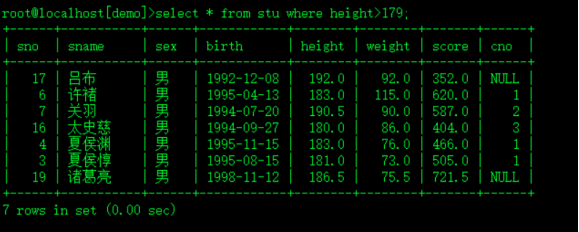
select *,(select count(*)+1 from stu i where i.height>o.height) height_ranking from stu o order by height_ranking;

select * from stu where height>179;
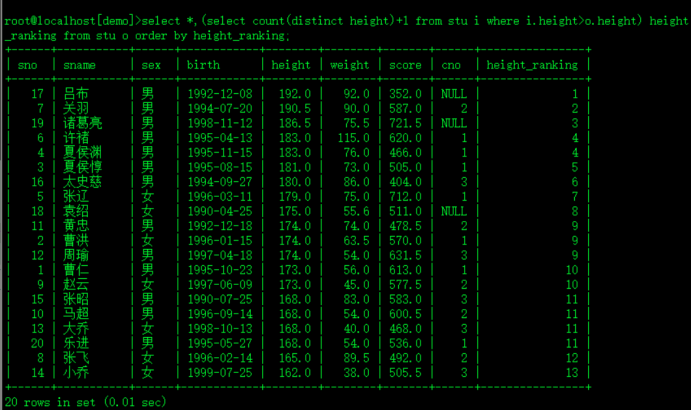
#dense ranking 稠密排名
select *,(select count(distinct height)+1 from stu i where i.height>o.height) height_ranking from stu o order by height_ranking;
给每个同学的考分排名,显示班内名次
select *,(select count(*)+1 from stu i where i.score>o.score and i.cno=o.cno) score_ranking from stu o where cno is not null order by cno,score_ranking;
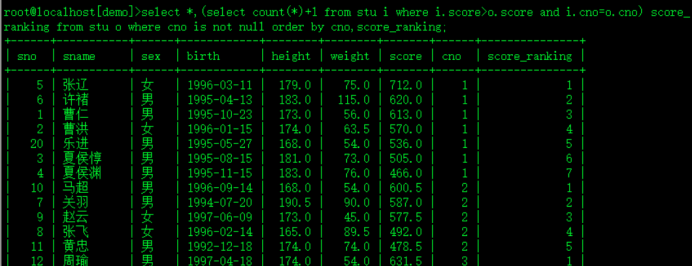
未分班
select *,(select count(*)+1 from stu i where i.score>o.score and i.cno=o.cno) mm from stu o order by cno, mm;
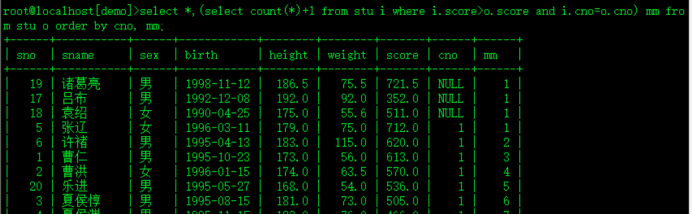
5.行转列
1.常用于生成报表,将数据表中的数据转换成可读性更好的形式
报表,按照班级号(cno)和性别(sex)统计人数,最高分,最低分
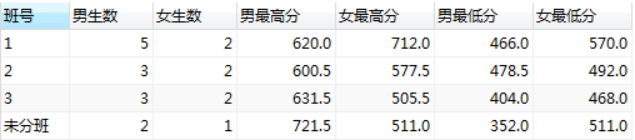
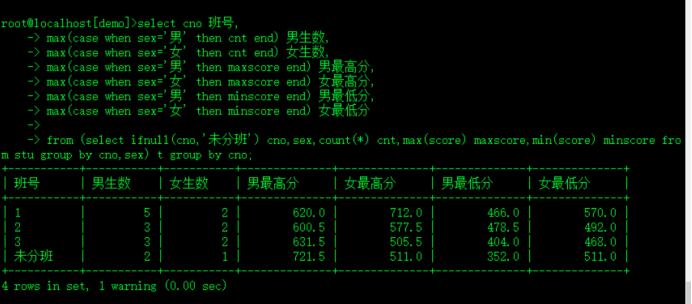
select cno 班号,
max(case when sex='男' then cnt end) 男生数,
max(case when sex='女' then cnt end) 女生数,
max(case when sex='男' then maxscore end) 男最高分,
max(case when sex='女' then maxscore end) 女最高分,
max(case when sex='男' then minscore end) 男最低分,
max(case when sex='女' then minscore end) 女最低分
from (select ifnull(cno,'未分班') cno,sex,count(*) cnt,max(score) maxscore,min(score) minscore from stu group by cno,sex) t group by cno;
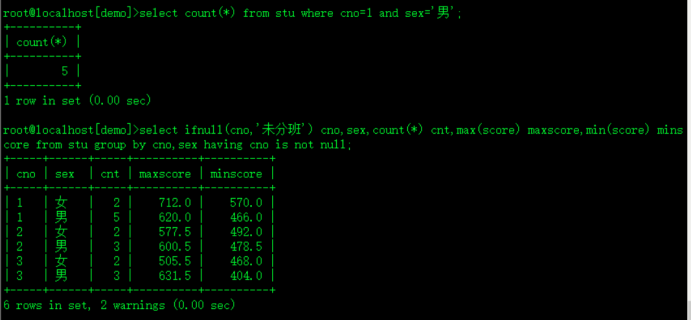
select count(*) from stu where cno=1 and sex='男';
select ifnull(cno,'未分班') cno,sex,count(*) cnt,max(score) maxscore,min(score) minscore from stu group by cno,sex having cno is not null;
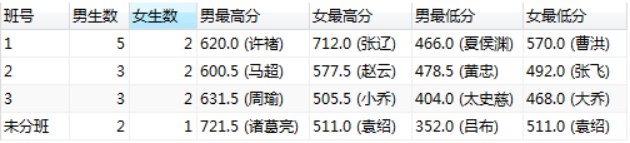
# 报表,按照班级号(cno)和性别(sex)统计人数,最高分(姓名),最低分(姓名)
1.数据源
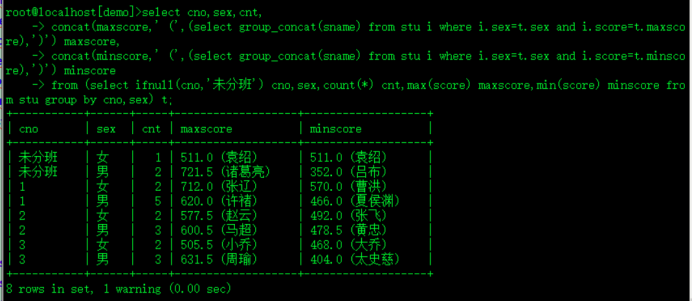
select cno,sex,cnt,
concat(maxscore,' (',(select group_concat(sname) from stu i where i.sex=t.sex and i.score=t.maxscore),')') maxscore,
concat(minscore,' (',(select group_concat(sname) from stu i where i.sex=t.sex and i.score=t.minscore),')') minscore
from (select ifnull(cno,'未分班') cno,sex,count(*) cnt,max(score) maxscore,min(score) minscore from stu group by cno,sex) t;
2.生成报表
select
cno 班号,
max(case when sex='男' then cnt end) 男生数,
max(case when sex='女' then cnt end) 女生数,
max(case when sex='男' then maxscore end) 男最高分,
max(case when sex='女' then maxscore end) 女最高分,
max(case when sex='男' then minscore end) 男最低分,
max(case when sex='女' then minscore end) 女最低分
from (数据源) t group by cno;
6.列转行
有时候数据库表的设计不合理,设计人员按照用户提供的报表设计数据表,数据统计不方便,需要列转行
#数据表按照报表的格式设计
#求每种产品年度销量,季度平均销量,有困难
#可以通过列转行来解决
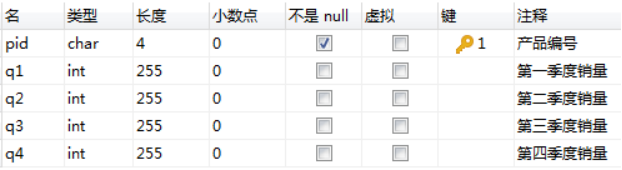
DROP TABLE IF EXISTS `sales`;
CREATE TABLE `sales` (
`pid` char(4) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '产品编号',
`q1` int(255) NULL DEFAULT NULL COMMENT '第一季度销量',
`q2` int(255) NULL DEFAULT NULL COMMENT '第二季度销量',
`q3` int(255) NULL DEFAULT NULL COMMENT '第三季度销量',
`q4` int(255) NULL DEFAULT NULL COMMENT '第四季度销量',
PRIMARY KEY (`pid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of sales
-- ----------------------------
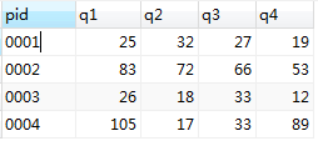
INSERT INTO `sales` VALUES ('0001', 25, 32, 27, 19);
INSERT INTO `sales` VALUES ('0002', 83, 72, 66, 53);
INSERT INTO `sales` VALUES ('0003', 26, 18, 33, 12);
INSERT INTO `sales` VALUES ('0004', 105, 17, 33, 89);
#数据源
select pid,q1 qty,'一季度' period from sales
union all
select pid,q2,'二季度' from sales
union all
select pid,q3,'三季度' from sales
union all
select pid,q4,'四季度' from sales order by pid
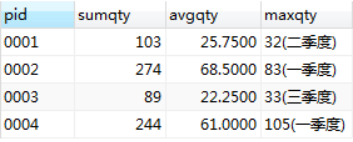
#年度总销量,季度平均销量,季度最大销量
select pid,sum(qty),avg(qty),max(qty) from
(
select pid,q1 qty,'一季度' period from sales
union all
select pid,q2,'二季度' from sales
union all
select pid,q3,'三季度' from sales
union all
select pid,q4,'四季度' from sales order by pid
) t group by pid
7.行间比较
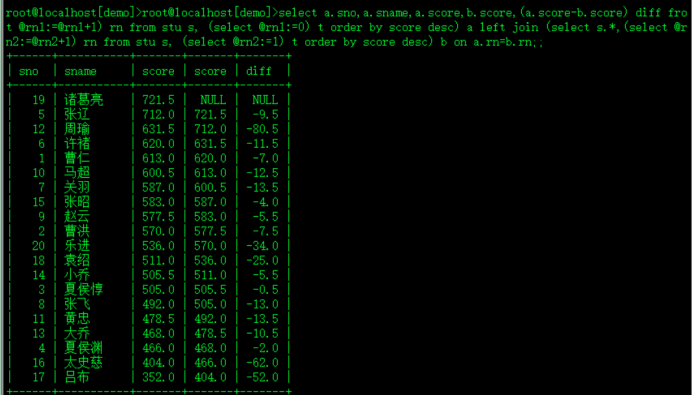
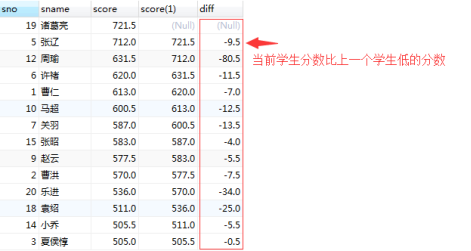
#按照score排序,显示间隔分数差值 系统变量
select a.sno,a.sname,a.score,b.score,(a.score-b.score) diff from
(select s.*,(select @rn1:=@rn1+1) rn from stu s, (select @rn1:=0) t order by score desc) a
left join
(select s.*,(select @rn2:=@rn2+1) rn from stu s, (select @rn2:=1) t order by score desc) b
on a.rn=b.rn
#按照cno排序,再按照score排序,显示间隔分数差值
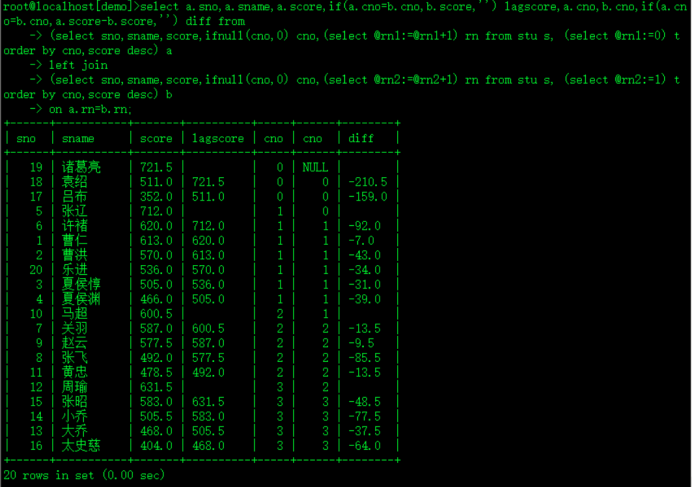
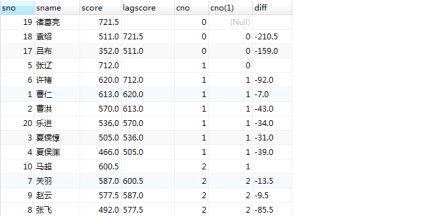
select a.sno,a.sname,a.score,if(a.cno=b.cno,b.score,'') lagscore,a.cno,b.cno,if(a.cno=b.cno,a.score-b.score,'') diff from
(select sno,sname,score,ifnull(cno,0) cno,(select @rn1:=@rn1+1) rn from stu s, (select @rn1:=0) t order by cno,score desc) a
left join
(select sno,sname,score,ifnull(cno,0) cno,(select @rn2:=@rn2+1) rn from stu s, (select @rn2:=1) t order by cno,score desc) b
on a.rn=b.rn;
8.删除重复记录
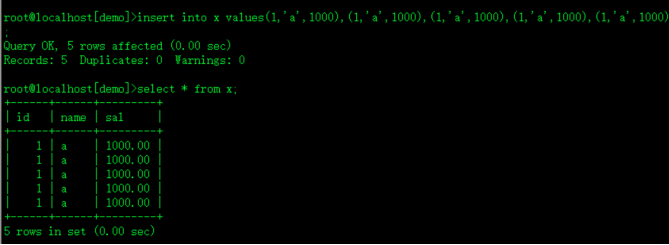
1.无主键
create table x (id int,name varchar(10),sal decimal(8,2));
insert into x values(1,'a',1000),(1,'a',1000),(1,'a',1000),(1,'a',1000),(1,'a',1000);
select * from x;
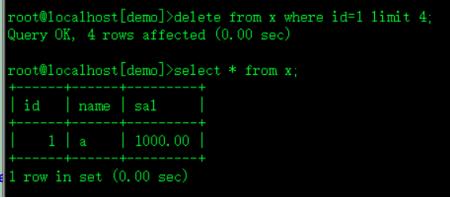
delete from w where id=1 limit 4;
select * from w;
2.有主键
create table w (id int auto_increment primary key,name varchar(10),sal decimal(8,2));
insert into w (name,sal) values('a',1000),('a',1000),('a',1000),('b',1500),('b',1500),('c',2000);
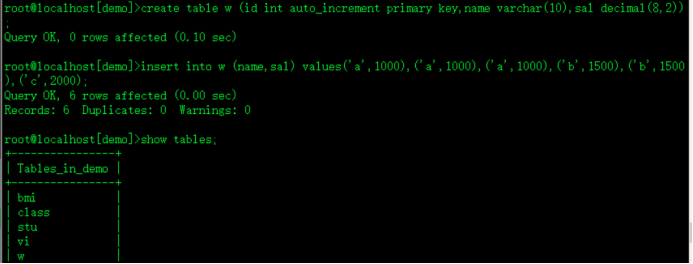
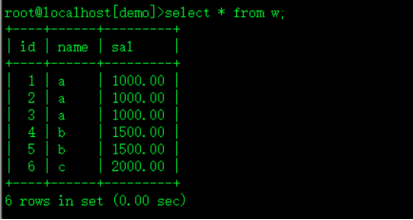
select * from w;
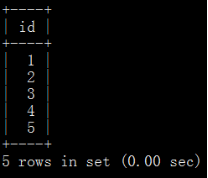
#找出哪些name,sal有重复记录,找出id
create table all_id as select id from where (name,sal) in (select name,sal from w group by name,sal having count(*)>1);
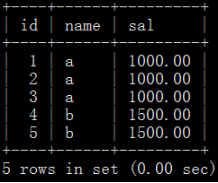
#找出有重复行id相关的所有记录
select * from w where id in (select id from w where (name,sal) in (select lect name,sal from w group by name,sal having count(*)>1)) ;
#重复记录中找出最大或最小的id进行保留
create table keep_id as select min(id) from (select * from w where id in (select id from w where (name,sal) in (select name,sal from w group by name,sal having count(*)>1))) w group by name,sal;
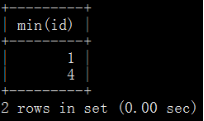
#删除有重复的id,但是要排除保留的id
begin;
delete from w where id in (select * from all_id) and id not in (select * from keep_id);
select * from w;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号