
[Pytorch]Pytorch 细节记录(转)
文章来源 https://www.cnblogs.com/king-lps/p/8570021.html
1. PyTorch进行训练和测试时指定实例化的model模式为:train/eval
eg:
 View Code
View Code eval即evaluation模式,train即训练模式。仅仅当模型中有Dropout和BatchNorm是才会有影响。因为训练时dropout和BN都开启,而一般而言测试时dropout被关闭,BN中的参数也是利用训练时保留的参数,所以测试时应进入评估模式。
(在训练时,𝜇和𝜎2是在整个mini-batch 上计算出来的包含了像是64 或28 或其它一定数量的样本,但在测试时,你可能需要逐一处理样本,方法是根据你的训练集估算𝜇和𝜎2,估算的方式有很多种,理论上你可以在最终的网络中运行整个训练集来得到𝜇和𝜎2,但在实际操作中,我们通常运用指数加权平均来追踪在训练过程中你看到的𝜇和𝜎2的值。还可以用指数加权平均,有时也叫做流动平均来粗略估算𝜇和𝜎2,然后在测试中使用𝜇和𝜎2的值来进行你所需要的隐藏单元𝑧值的调整。在实践中,不管你用什么方式估算𝜇和𝜎2,这套过程都是比较稳健的,因此我不太会担心你具体的操作方式,而且如果你使用的是某种深度学习框架,通常会有默认的估算𝜇和𝜎2的方式,应该一样会起到比较好的效果) -- Deeplearning.ai
2. PyTorch权重初始化的几种方法
class discriminator(nn.Module):</span><span style="color: #0000ff">def</span> <span style="color: #800080">__init__</span>(self, dataset = <span style="color: #800000">'</span><span style="color: #800000">mnist</span><span style="color: #800000">'</span><span style="color: #000000">): super(discriminator, self).</span><span style="color: #800080">__init__</span><span style="color: #000000">() 。... self.conv </span>=<span style="color: #000000"> nn.Sequential( nn.Conv2d(self.input_dim, </span>64, 4, 2, 1<span style="color: #000000">), nn.ReLU(), ) ... self.fc </span>=<span style="color: #000000"> nn.Sequential( nn.Linear(</span>32, 64 * (self.input_height // 2) * (self.input_width // 2<span style="color: #000000">)), nn.BatchNorm1d(</span>64 * (self.input_height // 2) * (self.input_width // 2<span style="color: #000000">)), nn.ReLU(), ) self.deconv </span>=<span style="color: #000000"> nn.Sequential( nn.ConvTranspose2d(</span>64, self.output_dim, 4, 2, 1<span style="color: #000000">), </span><span style="color: #008000">#</span><span style="color: #008000">nn.Sigmoid(), # EBGAN does not work well when using Sigmoid().</span>)
utils.initialize_weights(self)</span><span style="color: #0000ff">def</span><span style="color: #000000"> forward(self, input): ...def initialize_weights(net):
for m in net.modules():
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.ConvTranspose2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()


def init_weights(m): print(m) if type(m) == nn.Linear: m.weight.data.fill_(1.0) print(m.weight)net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2))
net.apply(init_weights)
def weights_init(m): classname = m.__class__.__name__ if classname.find('Conv') != -1: m.weight.data.normal_(0.0, 0.02) elif classname.find('BatchNorm') != -1: m.weight.data.normal_(1.0, 0.02) m.bias.data.fill_(0)net.apply(weights_init)
class torch.nn.Module 是所有神经网络的基类。
modules()返回网络中所有模块的迭代器。
add_module(name, module) 将一个子模块添加到当前模块。 该模块可以使用给定的名称作为属性访问。
apply(fn) 适用fn递归到每个子模块(如返回.children(),以及自我。
3. PyTorch 中Variable的重要属性
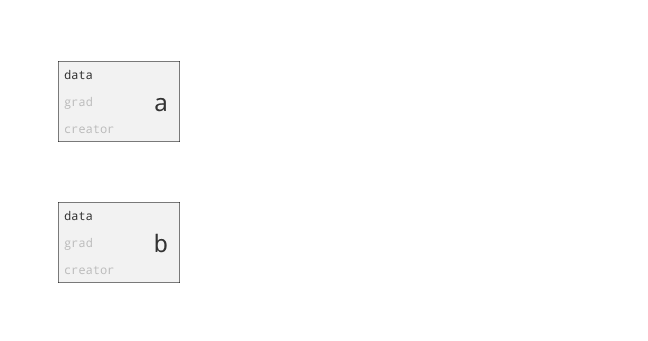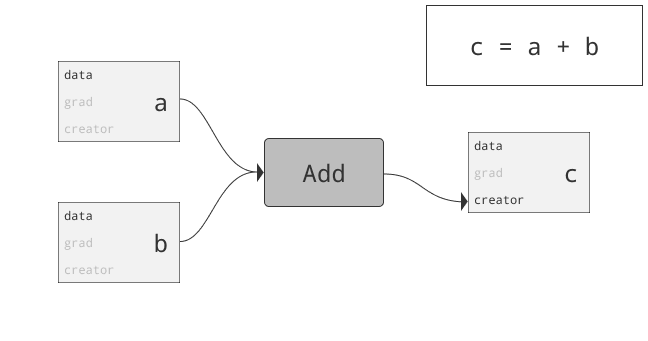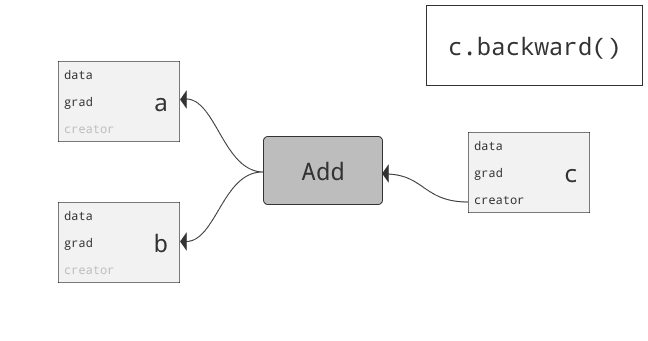
class torch.autograd.Variable
为什么要引入Variable?首先回答为什么引入Tensor。仅仅利用numpy也可以实现前向反向操作,但numpy不支持GPU运算。而Pytorch为Tensor提供多种操作运算,此外Tensor支持GPU。问题来了,两三层网络可以推公式写反向传播,当网络很复杂时需要自动化。autograd可以帮助我们,当利用autograd时,前向传播会定义一个计算图,图中的节点就是Tensor。图中的边就是函数。当我们将Tensor塞到Variable时,Variable就变为了节点。若x为一个Variable,那x.data即为Tensor,x.grad也为一个Variable。那x.grad.data就为梯度的值咯。总结:PyTorch Variables与PyTorch Tensors有着相同的API,Tensor上的所有操作几乎都可用在Variable上。两者不同之处在于利用Variable定义一个计算图,可以实现自动求导!
重要的属性如下:
requires_grad
指定要不要更新這個變數,對於不需要更新的變數可以把他設定成False,可以加快運算。
Variable默认是不需要求导的,即requires_grad属性默认为False,如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True。
在用户手动定义Variable时,参数requires_grad默认值是False。而在Module中的层在定义时,相关Variable的requires_grad参数默认是True。
在计算图中,如果有一个输入的requires_grad是True,那么输出的requires_grad也是True。只有在所有输入的requires_grad都为False时,输出的requires_grad才为False。
volatile
指定需不需要保留紀錄用的變數。指定變數為True代表運算不需要記錄,可以加快運算。如果一個變數的volatile是True,則它的requires_grad一定是False。
簡單來說,對於需要更新的Variable記得將requires_grad設成True,當只需要得到結果而不需要更新的Variable可以將volatile設成True加快運算速度。 参考:PyTorch 基礎篇
variable的volatile属性默认为False,如果某一个variable的volatile属性被设为True,那么所有依赖它的节点volatile属性都为True。volatile属性为True的节点不会求导,volatile的优先级比requires_grad高。
当有一个输入的volatile=True时,那么输出的volatile=True。volatile=True推荐在模型的推理过程(测试)中使用,这时只需要令输入的voliate=True,保证用最小的内存来执行推理,不会保存任何中间状态。在使用volatile=True的时候,变量是不存储 creator属性的,这样也减少了内存的使用。
参考:自动求导机制 、『PyTorch』第五弹_深入理解autograd_上:Variable属性方法
PyTorch学习系列(十)——如何在训练时固定一些层?、Pytorch笔记01-Variable和Function(自动梯度计算)
detach()
返回一个新变量,与当前图形分离。结果将永远不需要渐变。如果输入是易失的,输出也将变得不稳定。返回的 Variable 永远不会需要梯度。
根据GAN的代码来看:
方法1. 利用detach阶段梯度流:(代码片段:DCGAN)
# train with real netD.zero_grad() real_cpu, _ = data batch_size = real_cpu.size(0) if opt.cuda: real_cpu = real_cpu.cuda() input.resize_as_(real_cpu).copy_(real_cpu) label.resize_(batch_size).fill_(real_label) inputv = Variable(input) labelv = Variable(label)output </span>=<span style="color: #000000"> netD(inputv) errD_real </span>=<span style="color: #000000"> criterion(output, labelv) errD_real.backward() D_x </span>=<span style="color: #000000"> output.data.mean() </span><span style="color: #008000">#</span><span style="color: #008000"> train with fake</span> noise.resize_(batch_size, nz, 1, 1).normal_(0, 1<span style="color: #000000">) noisev </span>=<span style="color: #000000"> Variable(noise) fake </span>=<span style="color: #000000"> netG(noisev) labelv </span>=<span style="color: #000000"> Variable(label.fill_(fake_label)) output </span>=<span style="color: #000000"> netD(fake.detach()) errD_fake </span>=<span style="color: #000000"> criterion(output, labelv) errD_fake.backward() D_G_z1 </span>=<span style="color: #000000"> output.data.mean() errD </span>= errD_real +<span style="color: #000000"> errD_fake optimizerD.step() </span><span style="color: #008000">#</span><span style="color: #008000">###########################</span> <span style="color: #008000">#</span><span style="color: #008000"> (2) Update G network: maximize log(D(G(z)))</span> <span style="color: #008000">#</span><span style="color: #008000">##########################</span>netG.zero_grad()
labelv = Variable(label.fill_(real_label)) # fake labels are real for generator cost
output = netD(fake)
errG = criterion(output, labelv)
errG.backward()
D_G_z2 = output.data.mean()
optimizerG.step()
首先在用fake更新D的时候,给G的输出加了detach,是因为我们希望更新时只更新D的参数,而不需保留G的参数的梯度。其实这个detach也是可以不用加的,因为直到netG.zero_grad() 被调用G的梯度是不会被用到的,optimizerD.step()只更新D的参数。
然后在利用fake更新G的时候,却没有给G的输出加detach,因为你本身就是需要更新G的参数,所以不能截断它。
参考:stackoverflow 、github_issue(why is detach necessary)
方法2.利用 volatile = True 来冻结G的梯度:(代码片段:WGAN
# train with real real_cpu, _ = data netD.zero_grad() batch_size = real_cpu.size(0)</span><span style="color: #0000ff">if</span><span style="color: #000000"> opt.cuda: real_cpu </span>=<span style="color: #000000"> real_cpu.cuda() input.resize_as_(real_cpu).copy_(real_cpu) inputv </span>=<span style="color: #000000"> Variable(input) errD_real </span>=<span style="color: #000000"> netD(inputv) errD_real.backward(one) </span><span style="color: #008000">#</span><span style="color: #008000"> train with fake</span> noise.resize_(opt.batchSize, nz, 1, 1).normal_(0, 1<span style="color: #000000">) noisev </span>= Variable(noise, volatile = True) <span style="color: #008000">#</span><span style="color: #008000"> totally freeze netG</span> fake =<span style="color: #000000"> Variable(netG(noisev).data) inputv </span>=<span style="color: #000000"> fake errD_fake </span>=<span style="color: #000000"> netD(inputv) errD_fake.backward(mone) errD </span>= errD_real -<span style="color: #000000"> errD_fake optimizerD.step() </span><span style="color: #008000">#</span><span style="color: #008000">###########################</span> <span style="color: #008000">#</span><span style="color: #008000"> (2) Update G network</span> <span style="color: #008000">#</span><span style="color: #008000">##########################</span> <span style="color: #0000ff">for</span> p <span style="color: #0000ff">in</span><span style="color: #000000"> netD.parameters(): p.requires_grad </span>= False <span style="color: #008000">#</span><span style="color: #008000"> to avoid computation</span>netG.zero_grad()
# in case our last batch was the tail batch of the dataloader,
# make sure we feed a full batch of noise
noise.resize_(opt.batchSize, nz, 1, 1).normal_(0, 1)
noisev = Variable(noise)
fake = netG(noisev)
errG = netD(fake)
errG.backward(one)
optimizerG.step()
gen_iterations += 1
冻结G的梯度,即在更新D的时候,反向传播计算梯度时不会计算G的参数的梯度。作用与方法1相同。
eg:
如果我们有两个网络 A,B, 两个关系是这样的 y=A(x),z=B(y). 现在我们想用 z.backward()来为 B 网络的参数来求梯度,但是又不想求 A 网络参数的梯度。我们可以这样:
# y=A(x), z=B(y) 求B中参数的梯度,不求A中参数的梯度 # 第一种方法 y = A(x) z = B(y.detach()) z.backward()# 第二种方法
y = A(x)
y.detach_()
z = B(y)
z.backward()
参考: pytorch: Variable detach 与 detach_ 、Pytorch入门学习(九)---detach()的作用(从GAN代码分析)
另一个简单说明detach用法的github issue demo:
fc1 = nn.Linear(1, 2) fc2 = nn.Linear(2, 1) opt1 = optim.Adam(fc1.parameters(),lr=1e-1) opt2 = optim.Adam(fc2.parameters(),lr=1e-1)x = Variable(torch.FloatTensor([5]))
z = fc1(x)
x_p = fc2(z)
cost = (x_p - x) ** 2
'''
print (z)
print (x_p)
print (cost)
'''
opt1.zero_grad()
opt2.zero_grad()cost.backward()
for n, p in fc1.named_parameters():
print (n, p.grad.data)for n, p in fc2.named_parameters():
print (n, p.grad.data)opt1.zero_grad()
opt2.zero_grad()z = fc1(x)
x_p = fc2(z.detach())
cost = (x_p - x) ** 2cost.backward()
for n, p in fc1.named_parameters():
print (n, p.grad.data)for n, p in fc2.named_parameters():
print (n, p.grad.data)结果:
weight
12.0559
-8.3572
[torch.FloatTensor of size 2x1]bias
2.4112
-1.6714
[torch.FloatTensor of size 2]weight
-33.5588 -19.4411
[torch.FloatTensor of size 1x2]bias
-9.9940
[torch.FloatTensor of size 1]================================================
weight
0
0
[torch.FloatTensor of size 2x1]bias
0
0
[torch.FloatTensor of size 2]weight
-33.5588 -19.4411
[torch.FloatTensor of size 1x2]bias
-9.9940
[torch.FloatTensor of size 1]
grad_fn
梯度函数图跟踪。每一个变量在图中的位置可通过其grad_fn属性在图中的位置推测得到。
is_leaf
查看是否为叶子节点。即如果由用户创建。
x = V(t.ones(1)) b = V(t.rand(1), requires_grad = True) w = V(t.rand(1), requires_grad = True) y = w * x # 等价于y=w.mul(x) z = y + b # 等价于z=y.add(b) x.requires_grad, b.requires_grad, w.requires_grad (False, True, True)x.is_leaf, w.is_leaf, b.is_leaf
(True, True, True)z.grad_fn
<AddBackward1 object at 0x7f615e1d9cf8>z.grad_fn.next_functions
((<MulBackward1 object at 0x7f615e1d9780>, 0), (<AccumulateGrad object at 0x7f615e1d9390>, 0))
#next_functions保存grad_fn的输入,是一个tuple,tuple的元素也是Function第一个是y,它是乘法(mul)的输出,所以对应的反向传播函数y.grad_fn是MulBackward
第二个是b,它是叶子节点,由用户创建,grad_fn为None
autograd.grad、register_hook
在反向传播过程中非叶子节点的导数计算完之后即被清空。若想查看这些变量的梯度,有两种方法:
- 使用autograd.grad函数
- 使用register_hook
x = V(t.ones(3), requires_grad=True) w = V(t.rand(3), requires_grad=True) y = x * w # y依赖于w,而w.requires_grad = True z = y.sum() x.requires_grad, w.requires_grad, y.requires_grad (True, True, True)
# 非叶子节点grad计算完之后自动清空,y.grad是None z.backward() (x.grad, w.grad, y.grad)(Variable containing:
0.1636
0.3563
0.6623
[torch.FloatTensor of size 3], Variable containing:
1
1
1
[torch.FloatTensor of size 3], None)
此时y.grad为None,因为backward()只求图中叶子的梯度(即无父节点),如果需要对y求梯度,则可以使用autograd_grad或`register_hook`使用autograd.grad:
# 第一种方法:使用grad获取中间变量的梯度 x = V(t.ones(3), requires_grad=True) w = V(t.rand(3), requires_grad=True) y = x * w z = y.sum() # z对y的梯度,隐式调用backward() t.autograd.grad(z, y)(Variable containing:
1
1
1
[torch.FloatTensor of size 3],)
使用hook:
# 第二种方法:使用hook # hook是一个函数,输入是梯度,不应该有返回值 def variable_hook(grad): print('y的梯度: \r\n',grad)x = V(t.ones(3), requires_grad=True)
w = V(t.rand(3), requires_grad=True)
y = x * w
# 注册hook
hook_handle = y.register_hook(variable_hook)
z = y.sum()
z.backward()# 除非你每次都要用hook,否则用完之后记得移除hook
hook_handle.remove()y的梯度:
Variable containing:
1
1
1
[torch.FloatTensor of size 3]
参考:pytorch-book/chapter3-Tensor和autograd/
关于梯度固定与优化设置:
model = nn.Sequential(*list(model.children())) for p in model[0].parameters(): p.requires_grad=False
for i in m.parameters(): i.requires_grad=False
optimizer.SGD(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-3)
可以在中间插入冻结操作,这样只冻结之前的层,后续的操作不会被冻结:
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5)</span><span style="color: #0000ff">for</span> p <span style="color: #0000ff">in</span><span style="color: #000000"> self.parameters(): p.requires_grad</span>=<span style="color: #000000">False self.fc1 </span>= nn.Linear(16 * 5 * 5, 120<span style="color: #000000">) self.fc2 </span>= nn.Linear(120, 84<span style="color: #000000">) self.fc3 </span>= nn.Linear(84, 10)</pre>
count = 0 para_optim = [] for k in model.children(): # model.modules(): count += 1 # 6 should be changed properly if count > 6: for param in k.parameters(): para_optim.append(param) else: for param in k.parameters(): param.requires_grad = False optimizer = optim.RMSprop(para_optim, lr)################
another way
<span style="color: #0000ff">for</span> idx,m <span style="color: #0000ff">in</span><span style="color: #000000"> enumerate(model.modules()): </span><span style="color: #0000ff">if</span> idx >50<span style="color: #000000">: </span><span style="color: #0000ff">for</span> param <span style="color: #0000ff">in</span><span style="color: #000000"> m.parameters(): param.requires_grad </span>=<span style="color: #000000"> True </span><span style="color: #0000ff">else</span><span style="color: #000000">: </span><span style="color: #0000ff">for</span> param <span style="color: #0000ff">in</span><span style="color: #000000"> m.parameters(): param.requires_grad </span>= False</pre>
对特定层的权重进行限制:
def clamp_weights(self): for module in self.net.modules(): if(hasattr(module, 'weight') and module.kernel_size==(1,1)): module.weight.data = torch.clamp(module.weight.data,min=0)
参考:github
载入权重后发现错误率或正确率不正常,可能是学习率已改变,而保存和载入时没有考虑优化器:所以保存优化器:
save_checkpoint({ 'epoch': epoch + 1, 'arch': args.arch, 'state_dict': model.state_dict(), 'optimizer': optimizer.state_dict(), 'prec1': prec1, }, save_name) # saveif args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
checkpoint = torch.load(args.resume)
args.start_epoch = checkpoint['epoch']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
print("=> loaded checkpoint '{}' (epoch {})"
.format(args.resume, checkpoint['epoch']))
else:
print("=> no checkpoint found at '{}'".format(args.resume)) # load
对特定的层学习率设置:
params = [] for name, value in model.named_parameters(): if 'bias' in name: if 'fc2' in name: params += [{'params':value, 'lr': 20 * args.lr, 'weight_decay': 0}] else: params += [{'params':value, 'lr': 2 * args.lr, 'weight_decay': 0}] else: if 'fc2' in name: params += [{'params':value, 'lr': 10 * args.lr}] else: params += [{'params':value, 'lr': 1 * args.lr}]optimizer </span>=<span style="color: #000000"> torch.optim.SGD(params, args.lr, momentum</span>=<span style="color: #000000">args.momentum, weight_decay</span>=args.weight_decay)</pre>
或者:
class net(nn.Module): def __init__(self): super(net, self).__init__() self.conv1 = nn.Conv2d(3, 64, 1) self.conv2 = nn.Conv2d(64, 64, 1) self.conv3 = nn.Conv2d(64, 64, 1) self.conv4 = nn.Conv2d(64, 64, 1) self.conv5 = nn.Conv2d(64, 64, 1) def forward(self, x): out = conv5(conv4(conv3(conv2(conv1(x))))) return out我们希望conv5学习率是其他层的100倍,我们可以:
net = net()
lr = 0.001conv5_params = list(map(id, net.conv5.parameters()))
base_params = filter(lambda p: id(p) not in conv5_params,
net.parameters())
optimizer = torch.optim.SGD([
{'params': base_params},
{'params': net.conv5.parameters(), 'lr': lr * 100},
, lr=lr, momentum=0.9)如果多层,则:
conv5_params = list(map(id, net.conv5.parameters()))
conv4_params = list(map(id, net.conv4.parameters()))
base_params = filter(lambda p: id(p) not in conv5_params + conv4_params,
net.parameters())
optimizer = torch.optim.SGD([
{'params': base_params},
{'params': net.conv5.parameters(), 'lr': lr * 100},
{'params': net.conv4.parameters(), 'lr': lr * 100},
, lr=lr, momentum=0.9)


</div>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号