[PyTorch]PyTorch/python常用语法/常见坑点
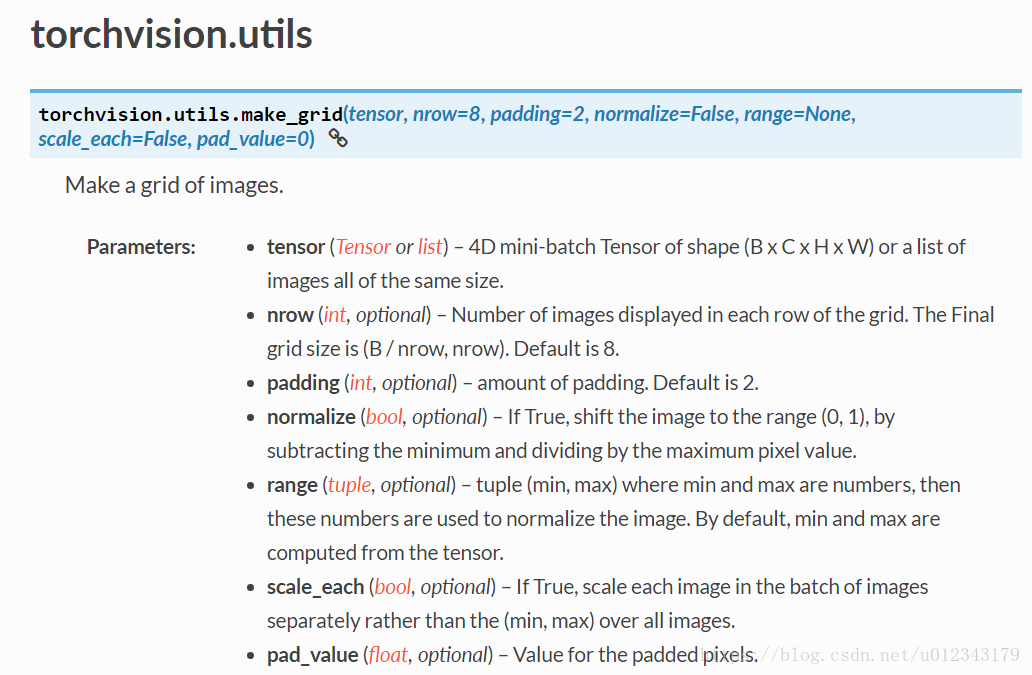
1. make_grid()
2. join与os.path.join()
1.join()函数
语法:‘sep’.join(seq)
参数说明:
sep:分隔符。可以为空
seq:要连接的元素序列、字符串、元组、字典等
上面的语法即:以sep作为分隔符,将seq所有的元素合并成一个新的字符串
返回值:返回一个以分隔符sep连接各个元素后生成的字符串
2、os.path.join()函数
语法: os.path.join(path1[,path2[,......]])
返回值:将多个路径组合后返回
注:第一个绝对路径之前的参数将被忽略
3. 读文件写文件
https://www.cnblogs.com/ymjyqsx/p/6554817.html
4. json操作
详细内容1
详细内容2)
json.dumps 将 Python 对象编码成 JSON 字符串
json.loads 将已编码的 JSON 字符串解码为 Python 对象
引入json
import json
常用有2个方法,也是最基本的使用方法:
1、dumps:把字典转成json字符串
2、loads:把json字符串转成字典
#coding:utf-8
import json
test_dict = {'a':1, 'b':2}
#把字典转成json字符串
json_text = json.dumps(test_dict)
print(json_text)
#把json字符串转成字典
json_dict = json.loads(json_text)
print(json_dict)
当然,我写的例子所使用的字典也比较简单。大家可以尝试拟一个复杂的,包含数组的字典。
若你尝试使用dir方法看json模块有什么方法时,会发现还有load、dump方法。这两个方法和上面两个方法少了一个字母s。
这两个方法是为了读写json文件提供的便捷方法。举个栗子,json字符串可以保存到文本文件。若只是使用loads和dumps,代码如下所示。
注意:以下代码涉及到utf-8文件读写,可以参考我前面的文章:Python读写utf-8的文本文件
1、把字典转成json字符串,并保存到文件中
#coding:utf-8
import json
import codecs
test_dict = {'a':1, 'b':2}
#把字典转成json字符串
json_text = json.dumps(test_dict)
#把json字符串保存到文件
#因为可能json有unicode编码,最好用codecs保存utf-8文件
with codecs.open('1.json', 'w', 'utf-8') as f:
f.write(json_text)
2、从json文件中读取到字典中
#coding:utf-8
import json
import codecs
#从文件中读取内容
with codecs.open('1.json', 'r', 'utf-8') as f:
json_text = f.read()
#把字符串转成字典
json_dict = json.loads(json_text)
上面代码,我们可以用load和dump修改。
1、dump把字典转成json字符串并写入到文件
#coding:utf-8
import json
import codecs
test_dict = {'a':1, 'b':2}
#把字典转成json字符串并写入到文件
with codecs.open('1.json', 'w', 'utf-8') as f:
json.dump(test_dict, f)
2、load从json文件读取json字符串到字典
#coding:utf-8
import json
import codecs
#从json文件读取json字符串到字典
with codecs.open('1.json', 'r', 'utf-8') as f:
json_dict = json.load(f)
这样明显省事很多。
最后,再说一个知识点。如何把json转成有序的字典。
众所周知,字典是无序的。所以json的loads方法转换得来的字典本来就是无序的。
但出于某种需求,需要确保顺序正常,按照原本json字符串的顺序。
这个需要在解析的时候,把无序字典换成有序字典。如下代码:
#coding:utf-8
from collections import OrderedDict
import json
json_text = '{ "b": 3, "a": 2, "c": 1}'
json_dict = json.loads(json_text)
print(u"转成普通字典")
for key, value in json_dict.items():
print("key:%s, value:%s" % (key, value))
json_dict = json.loads(json_text, object_pairs_hook=OrderedDict)
print(u"\n转成有序字典")
for key, value in json_dict.items():
print("key:%s, value:%s" % (key, value))
5. tensorboard使用
在使用GPU进行训练的时候,要安装tensorflow与tensorflow-gpu, 有的可能需cuda和cudnn不匹配,所以注意选好版本,安装好可以开另一个terminal运行 tensorboard --logdir=日志地址相对路径, 然后在本地游览器输入:服务器ip:6006即可
6. python shutil.move 移动文件
#复制文件:
shutil.copyfile("oldfile","newfile") #oldfile和newfile都只能是文件
shutil.copy("oldfile","newfile") #oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
#复制文件夹:
shutil.copytree("olddir","newdir") #olddir和newdir都只能是目录,且newdir必须不存在
#重命名文件(目录)
os.rename("oldname","newname") #文件或目录都是使用这条命令
#移动文件(目录)
shutil.move("oldpos","newpos")
shutil.move("D:/知乎日报/latest/一张优惠券,换你的通讯录信息,你愿意吗?.pdf", "D:/知乎日报/past/")
7. numpy.squeeze()函数
1)a表示输入的数组;
2)axis用于指定需要删除的维度,但是指定的维度必须为单维度,否则将会报错;
3)axis的取值可为None 或 int 或 tuple of ints, 可选。若axis为空,则删除所有单维度的条目;
4)返回值:数组
5) 不会修改原数组;
8. numpy中transpose和swapaxes
详细
transpose()
这个函数如果括号内不带参数,就相当于转置,和.T效果一样,而今天主要来讲解其带参数。
我们看如下一个numpy的数组:
arr=np.arange(16).reshape((2,2,4))
arr=
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
那么有:
arr.transpose(2,1,0)
array([[[ 0, 8],
[ 4, 12]],
[[ 1, 9],
[ 5, 13]],
[[ 2, 10],
[ 6, 14]],
[[ 3, 11],
[ 7, 15]]])
为什么会是这样的结果呢,这是因为arr这个数组有三个维度,三个维度的编号对应为(0,1,2),比如这样,我们需要拿到7这个数字,怎么办,肯定需要些三个维度的值,7的第一个维度为0,第二个维度为1,第三个3,所以arr[0,1,3]则拿到了7
arr[0,1,3] #结果就是7
这下应该懂了些吧,好,再回到transpose()这个函数,它里面就是维度的排序,比如我们后面写的transpose(2,1,0),就是把之前第三个维度转为第一个维度,之前的第二个维度不变,之前的第一个维度变为第三个维度,好那么我们继续拿7这个值来说,之前的索引为[0,1,3],按照我们的转换方法,把之前的第三维度变为第一维度,之前的第一维度变为第三维度,那么现在7的索引就是(3,1,0)
同理所有的数组内的数字都是这样变得,这就是transpose()内参数的变化。
理解了上面,再来理解swapaxes()就很简单了,swapaxes接受一对轴编号,其实这里我们叫一对维度编号更好吧,比如:
arr.swapaxes(2,1) #就是将第三个维度和第二个维度交换
array([[[ 0, 4],
[ 1, 5],
[ 2, 6],
[ 3, 7]],
[[ 8, 12],
[ 9, 13],
[10, 14],
[11, 15]]])
还是那我们的数字7来说,之前的索引是(0,1,3),那么交换之后,就应该是(0,3,1) 多说一句,其实numpy高维数组的切片也是这样选取维度的。 这就是transpose和swapaxes函数的讲解了
9. inplace操作
in-place operation在pytorch中是指改变一个tensor的值的时候,不经过复制操作,而是直接在原来的内存上改变它的值。可以把它成为原地操作符。
在pytorch中经常加后缀“”来代表原地in-place operation,比如说.add() 或者.scatter()。python里面的+=,*=也是in-place operation。
ReLU函数有个inplace参数,如果设为True,它会把输出直接覆盖到输入中,这样可以节省内存/显存。之所以可以覆盖是因为在计算ReLU的反向传播时,只需根据输出就能够推算出反向传播的梯度。但是只有少数的autograd操作支持inplace操作(如variable.sigmoid_()),除非你明确地知道自己在做什么,否则一般不要使用inplace操作。
10. torch.nn.MaxUnpool2d()
class torch.nn.MaxUnpool2d(kernel_size, stride=None, padding=0)
Maxpool2d的逆过程,不过并不是完全的逆过程,因为在maxpool2d的过程中,一些最大值的已经丢失。 MaxUnpool2d的输入是MaxPool2d的输出,包括最大值的索引,并计算所有maxpool2d过程中非最大值被设置为零的部分的反向。
注意:
MaxPool2d可以将多个输入大小映射到相同的输出大小。因此,反演过程可能会变得模棱两可。 为了适应这一点,可以在调用中将输出大小(output_size)作为额外的参数传入。具体用法,请参阅下面示例
参数:
kernel_size(int or tuple) - max pooling的窗口大小
stride(int or tuple, optional) - max pooling的窗口移动的步长。默认值是kernel_size
padding(int or tuple, optional) - 输入的每一条边补充0的层数
输入:
input:需要转换的tensor
indices:Maxpool1d的索引号
output_size:一个指定输出大小的torch.Size
大小:
input: (N,C,H_in,W_in)
output:(N,C,H_out,W_out)
也可以使用output_size指定输出的大小
>>> pool = nn.MaxPool2d(2, stride=2, return_indices=True)
>>> unpool = nn.MaxUnpool2d(2, stride=2)
>>> input = Variable(torch.Tensor([[[[ 1, 2, 3, 4],
... [ 5, 6, 7, 8],
... [ 9, 10, 11, 12],
... [13, 14, 15, 16]]]]))
>>> output, indices = pool(input)
>>> unpool(output, indices)
Variable containing:
(0 ,0 ,.,.) =
0 0 0 0
0 6 0 8
0 0 0 0
0 14 0 16
[torch.FloatTensor of size 1x1x4x4]
>>> # specify a different output size than input size
>>> unpool(output, indices, output_size=torch.Size([1, 1, 5, 5]))
Variable containing:
(0 ,0 ,.,.) =
0 0 0 0 0
6 0 8 0 0
0 0 0 14 0
16 0 0 0 0
0 0 0 0 0
[torch.FloatTensor of size 1x1x5x5]
11. pytorch learning rate decay
本文主要是介绍在pytorch中如何使用learning rate decay.
先上代码:
def adjust_learning_rate(optimizer, decay_rate=.9):
for param_group in optimizer.param_groups:
param_group['lr'] = param_group['lr'] * decay_rate
什么是param_groups?
optimizer通过param_group来管理参数组.param_group中保存了参数组及其对应的学习率,动量等等.所以我们可以通过更改param_group['lr']的值来更改对应参数组的学习率.
# 有两个`param_group`即,len(optim.param_groups)==2
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)
#一个参数组
optim.SGD(model.parameters(), lr=1e-2, momentum=.9)
12. os.walk
1.载入
要使用os.walk,首先要载入该函数
可以使用以下两种方法
- import os
- from os import walk
2.使用
os.walk的函数声明为:
walk(top, topdown=True, onerror=None, followlinks=False)
参数
- top 是你所要便利的目录的地址
- topdown 为真,则优先遍历top目录,否则优先遍历top的子目录(默认为开启)
- onerror 需要一个 callable 对象,当walk需要异常时,会调用
- followlinks 如果为真,则会遍历目录下的快捷方式(linux 下是 symbolic link)实际所指的目录(默认关闭)
os.walk 的返回值是一个生成器(generator),也就是说我们需要不断的遍历它,来获得所有的内容。
每次遍历的对象都是返回的是一个三元组(root,dirs,files)
- root 所指的是当前正在遍历的这个文件夹的本身的地址
- dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
如果topdown 参数为真,walk 会遍历top文件夹,与top文件夹中每一个子目录。
常用用法:
def get_files(mydir):
res = []
for root, dirs, files in os.walk(mydir, followlinks=True):
for f in files:
if f.endswith(".jpg") or f.endswith(".png") or f.endswith(".jpeg") or f.endswith(".JPG"):
res.append(os.path.join(root, f))
return res
13. replace
语法:
str.replace(old, new[, max])
参数
- old – 这是要进行更换的旧子串。
- new – 这是新的子串,将取代旧的子字符串(子串可以为空)。
- max – 如果这个可选参数max值给出,仅第一计数出现被替换。
返回值
此方法返回字符串的拷贝与旧子串出现的所有被新的所取代。如果可选参数最大值给定,只有第一个计数发生替换。
str = "this is string example....wow!!! this is really string";
print str.replace("is", "was");
print str.replace("is", "was", 3);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号