
【线性判别】Fisher线性判别(转)
今天读paper遇到了Fisher线性判别的变体, 所以来学习一下, 所以到时候一定要把PRMl刷一遍呀
以下两篇论文一起阅读比较好:
论文1: https://blog.csdn.net/Rainbow0210/article/details/52892805
在前文《贝叶斯决策理论》中已经提到,很多情况下,准确地估计概率密度模型并非易事,在特征空间维数较高和样本数量较少的情况下尤为如此。
实际上,模式识别的目的是在特征空间中设法找到两类(或多类)的分类面,估计概率密度函数并不是我们的目的。
前文已经提到,正态分布情况下,贝叶斯决策的最优分类面是线性的或者是二次函数形式的,本文则着重讨论线性情况下的一类判别准则——Fisher判别准则。
为了避免陷入复杂的概率的计算,我们直接估计判别函数式中的参数(因为我们已经知道判别函数式是线性的)。
首先我们来回顾一下线性判别函数的基本概念:




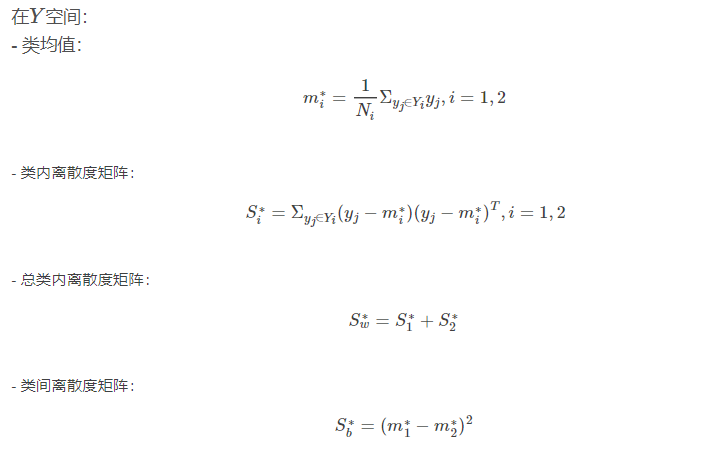


第二篇: https://blog.csdn.net/qq_18870127/article/details/79097735
应用统计方法解决模式识别问题时,一再碰到的问题之一就是维数问题。在低维空间里解析上或计算上行得通的方法,在高维空间里往往行不通。因此,降低维数有时就会成为处理实际问题的关键。
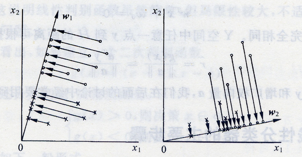
问题描述:如何根据实际情况找到一条最好的、最易于分类的投影线,这就是Fisher判别方法所要解决的基本问题。
考虑把d维空间的样本投影到一条直线上,形成一维空间,即把维数压缩到一维。然而,即使样本在d维空间里形成若干紧凑的互相分得开的集群,当把它们投影到一条直线上时,也可能会是几类样本混在一起而变得无法识别。但是,在一般情况下,总可以找到某个方向,使在这个方向的直线上,样本的投影能分得开。下图可能会更加直观一点:
从d维空间到一维空间的一般数学变换方法:假设有一集合Г包含N个d维样本x1, x2, …, xN,其中N1个属于ω1类的样本记为子集Г1, N2个属于ω2类的样本记为子集Г2 。若对xn的分量做线性组合可得标量:
yn = wTxn, n=1,2,…,N
这样便得到N个一维样本yn组成的集合,并可分为两个子集Г1’和Г2’ 。
实际上,w的值是无关紧要的,它仅是yn乘上一个比例因子,重要的是选择w的方向。w的方向不同,将使样本投影后的可分离程度不同,从而直接影响的分类效果。因此,上述寻找最佳投影方向的问题,在数学上就是寻找最好的变换向量w*的问题。
Fisher准则函数的定义
几个必要的基本参量:
1.
在d维X空间
(1)各类样本的均值向量mi
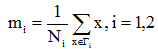
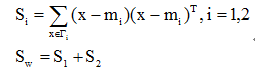
(3)样本类间离散度矩阵Sb
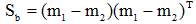
2. 在一维Y空间
(1)各类样本的均值
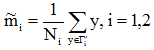
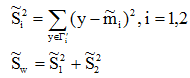
Fisher准则函数定义
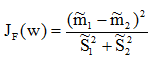
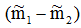 是两类均值之差,
是两类均值之差,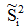 是样本类内离散度。显然,应该使JF(w)的分子尽可能大而分母尽可能小,即应寻找使JF(w)尽可能大的w作为投影方向。但上式中并不显含w,因此须设法将JF(w)变成w的显函数。
是样本类内离散度。显然,应该使JF(w)的分子尽可能大而分母尽可能小,即应寻找使JF(w)尽可能大的w作为投影方向。但上式中并不显含w,因此须设法将JF(w)变成w的显函数。由各类样本的均值可推出:
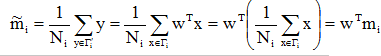
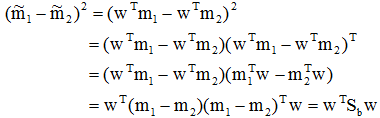
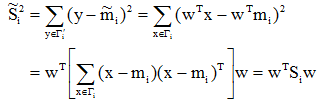
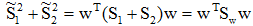
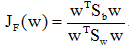
为求使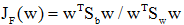
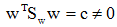
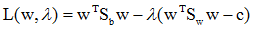
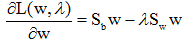
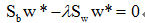
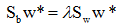
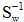 ,可得:
,可得: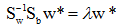
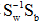 的特征值问题。利用
的特征值问题。利用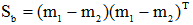 的定义,将上式左边的
的定义,将上式左边的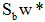 写成:
写成: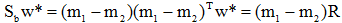
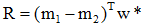 为一标量,所以
为一标量,所以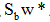 总是在向量
总是在向量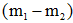 的方向上。因此λw*可写成:
的方向上。因此λw*可写成: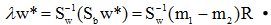
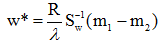
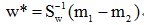
w*是使Fisher准则函数JF(w)取极大值时的解,也就是d维X空间到一维Y空间的最佳投影方向。有了w*,就可以把d维样本x投影到一维,这实际上是多维空间到一维空间的一种映射,这个一维空间的方向w*相对于Fisher准则函数JF(w)是最好的。利用Fisher准则,就可以将d维分类问题转化为一维分类问题,然后,只要确定一个阈值T,将投影点yn与T相比较,即可进行分类判别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号