
一文带你入门Transformer
让我们初学一下Transformer,它确实相对难以理解,下面让我们开始吧!朋友们.
Don't worry about it
前提
- 在这里我们用x<t>表示文本位置→输入
- 用Tx表示文本长度
- 用y<t>表示输出的文本位置
- 用Ty表示输出的文本长度
目前这里有一个文本
X: Harry Potter and hermione granger invented a new spell
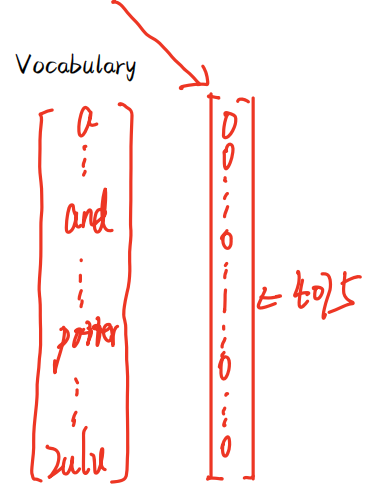
这里我们用one-hot独热矩阵,每一个文本都会对应于1个one - hot,
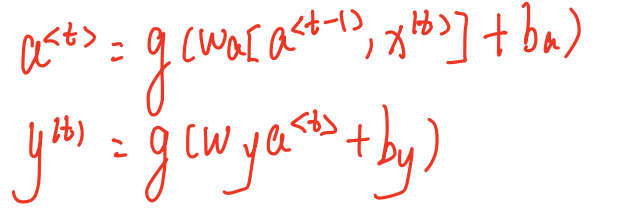
但是我们一个输入文本就要有一个 one-hot,这样就会造成大量的参数,于是提出了RNN
接下来我们学习RNN
RNN模型
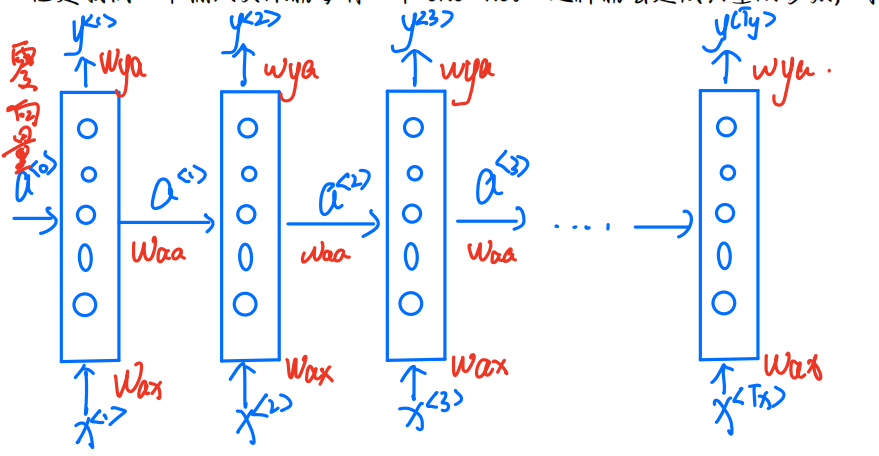
这里的Wax、 Waa、 Wya都是参数,就和我们之前学神经网络的W是一个意思
下面我们来学习网络的前向传播
向前传播

这里的g是激活函数,b是偏置,我们对式子进行简化,是不是看到式子的时候前面的模型就明白怎么运转的了
反向传播的时候,框架会自动为你实现
上面的模型都是针对Tx=Ty的,当然面对不同的情况会有不同的模型
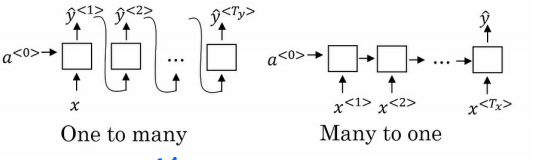
我们看一下第一个模型
One to many RNN moudle
Cats average 15 hours of sleep a day.
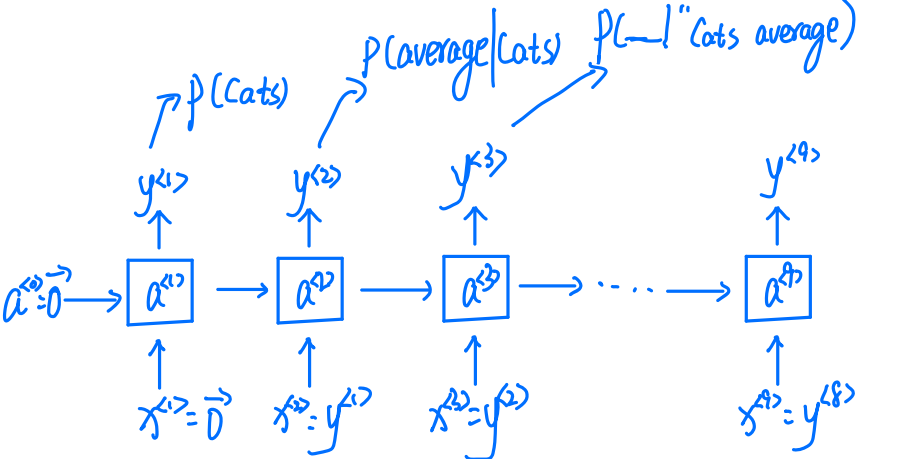
接下来我们讨论RNNs梯度消失的问题。
RNNs梯度消失
- 如果碰到梯度爆炸的问题就是出现了 Nan,就只用使用gradient clipping.
- The cat, which ate already... was full。我们如何确保让机器认识cat是单数,就是依赖问题,尽管现在依赖问题依旧就没有解决
GRU
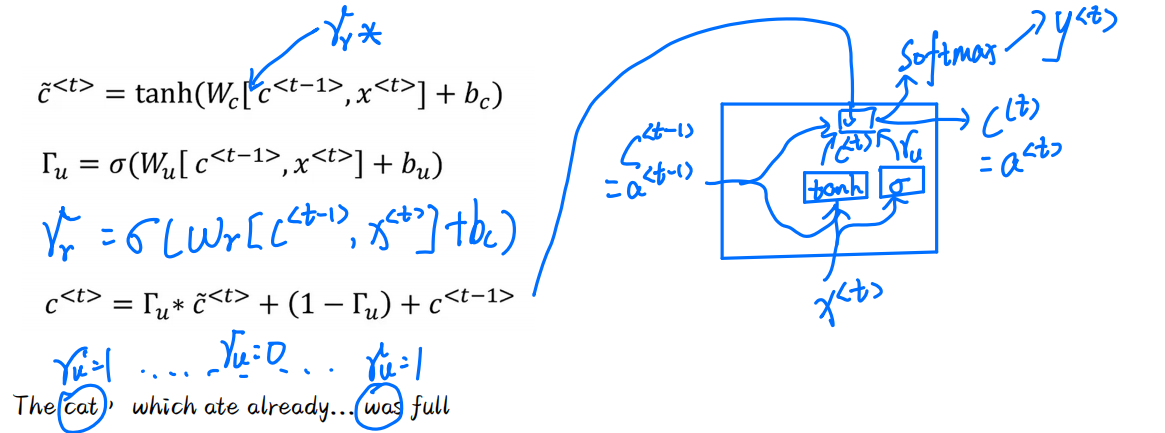
这是一个简单的模型,方便理解,这里有两个门,因此我们也称GRU为2门控
LSTM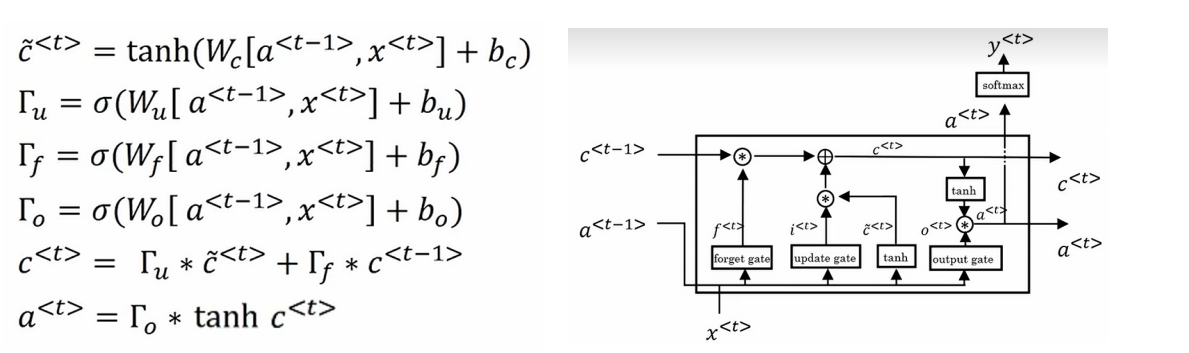
这里有3个门,因此我们称LSTM为3门控
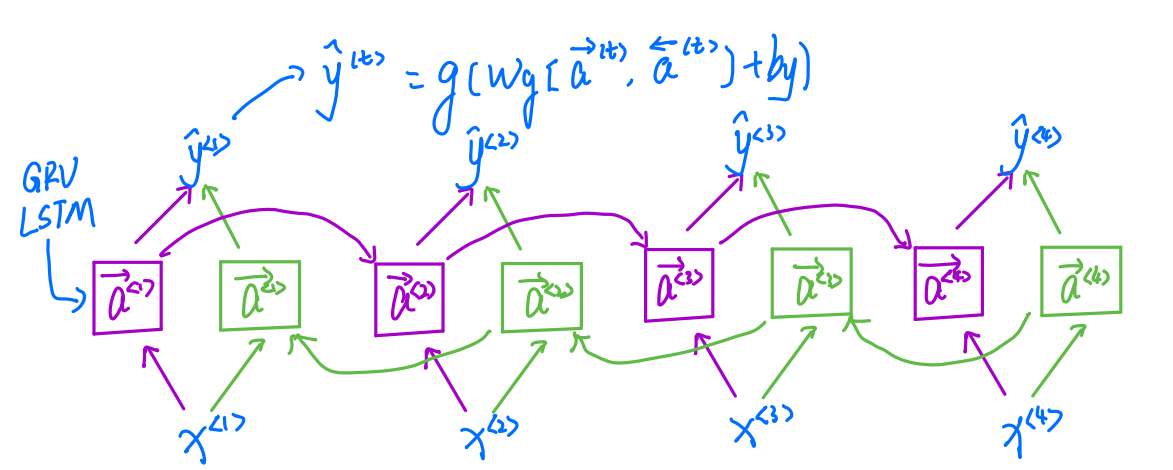
BRNN
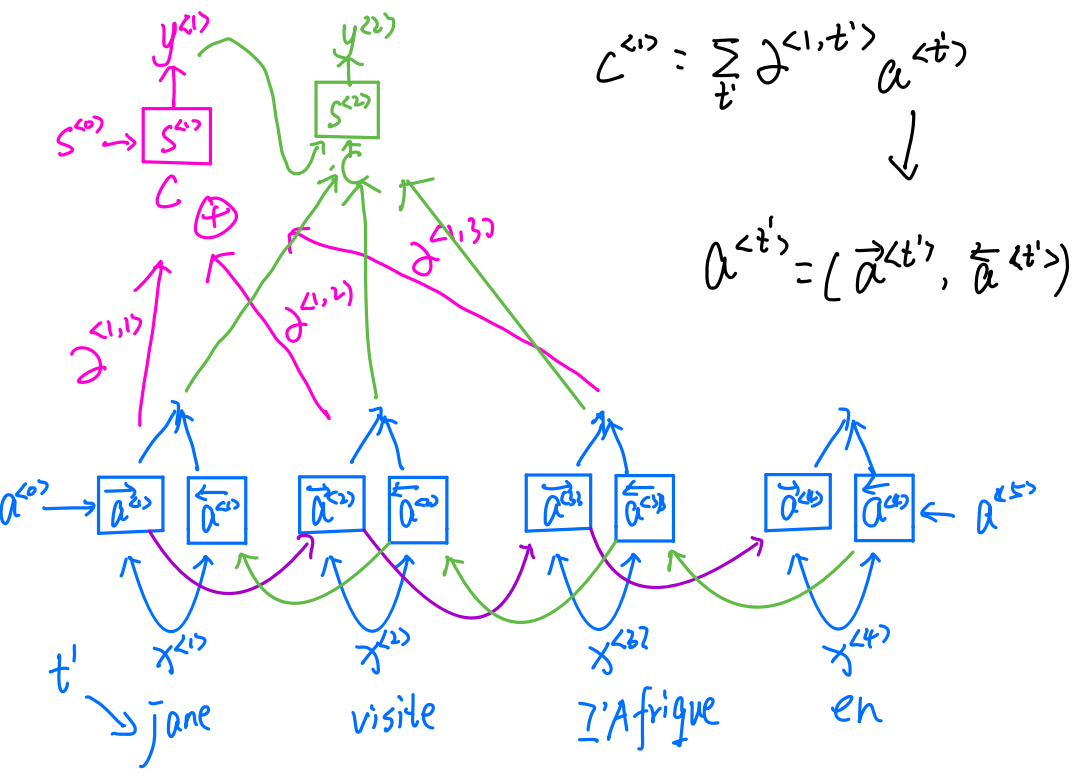
这里是非常重要的,这里没听的话,后面的注意力模型是不容易看懂的!
这并不是正,逆传播,而是正反同时开始在时间t输出的y可以同时被过去和未来所影响,
对于复杂的问题我们会使用到深度RNNs。
下面我们来看一下注意力模型。
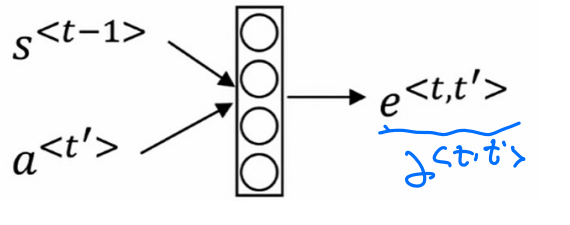
注意力模型
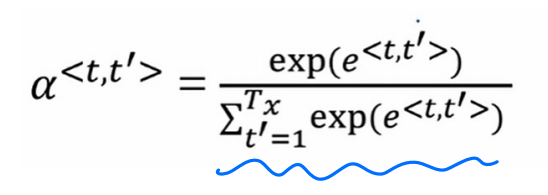
这是注意力的计算公式,我们可以把其想像成一个小的网络
接下来我们学习transformer网络,,最有效前的模型。(其实就是注意力模型+ CNN)
Transformer
- 自注意力模型
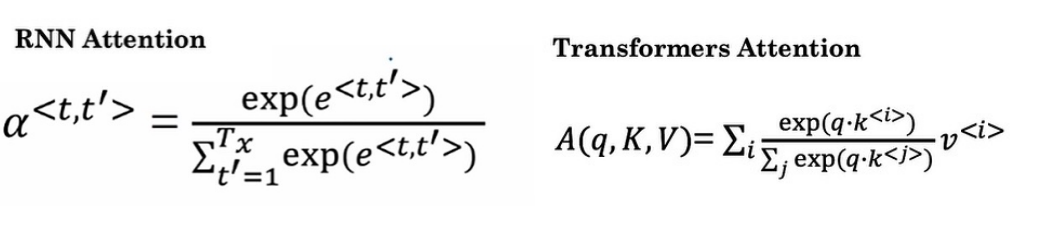
我们将其softmax改变一下
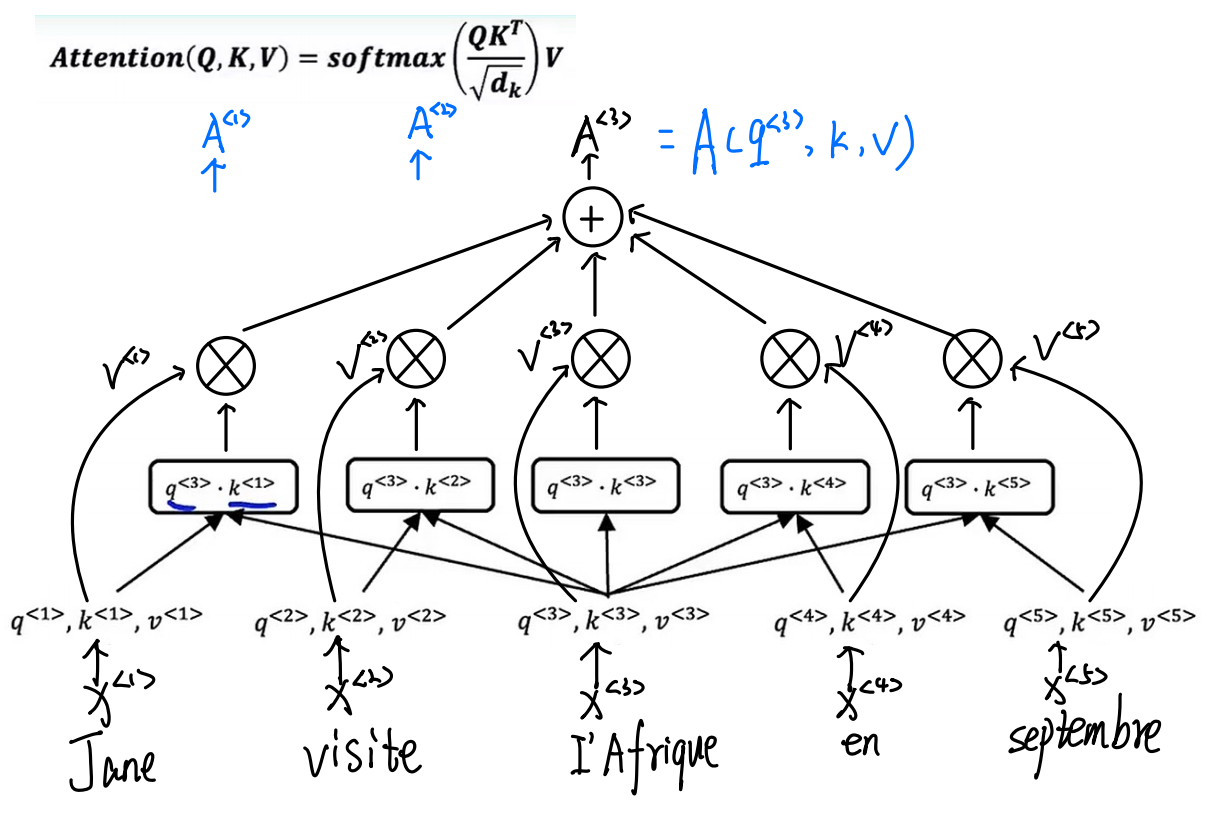
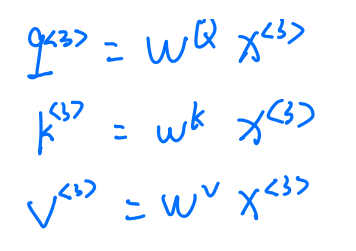
-
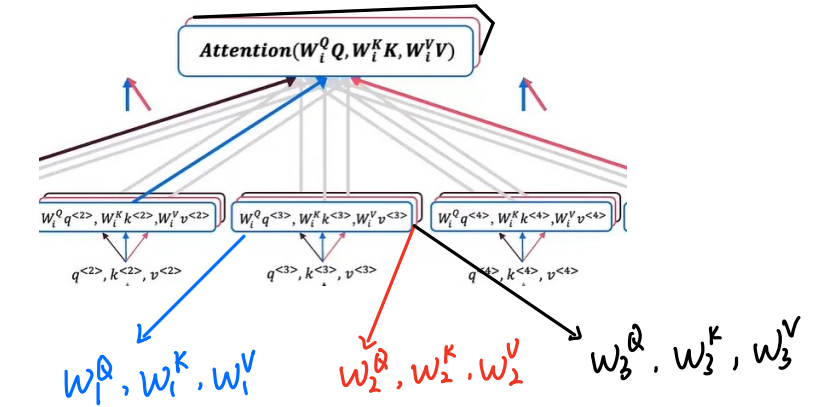
多头注意力机制
其实就是对自注意力机制进行一个for循环
当然每一个通道都有一组参数
- Transformer
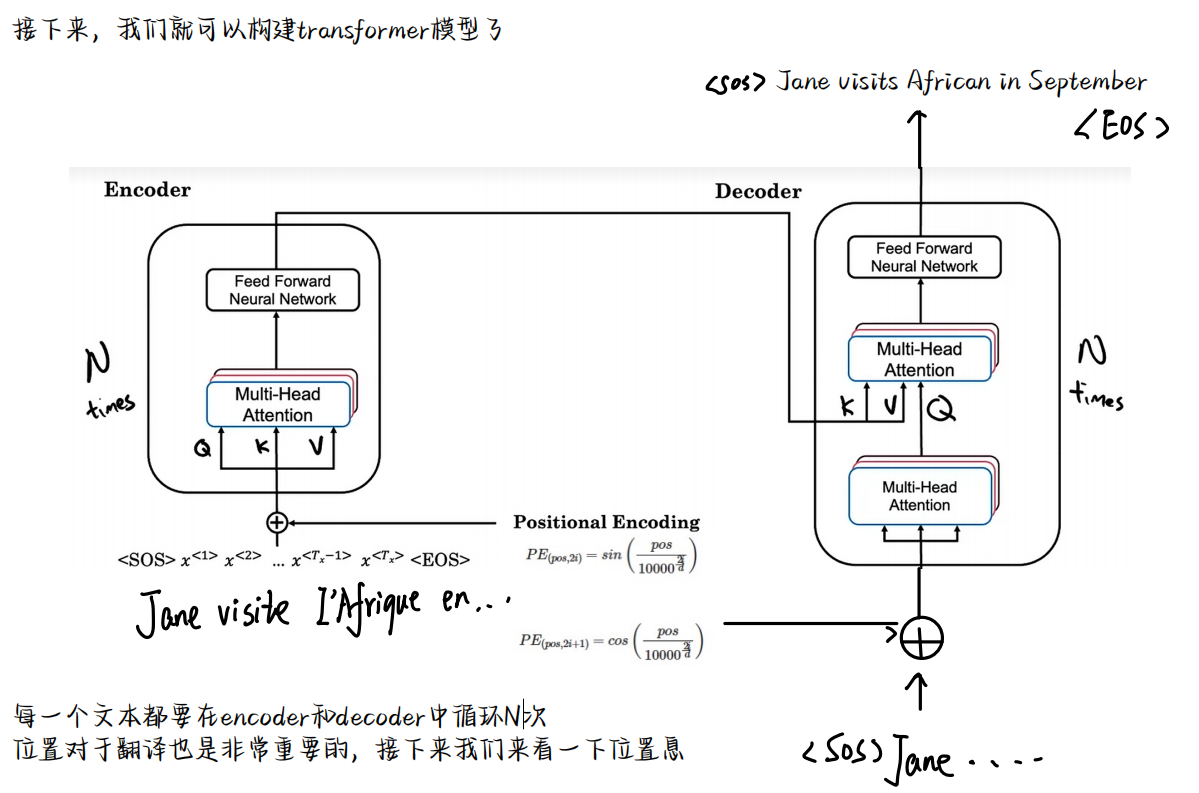
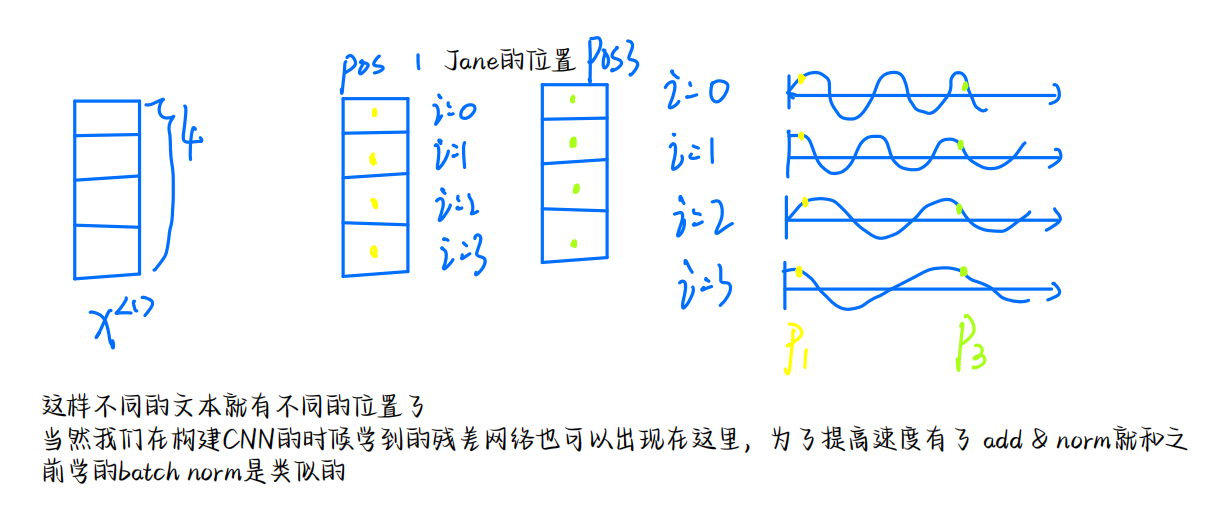
我们定义一个深度为4的向量
到此我们的Transformer就整理完了,当然这也在不断的完善,随学随记!
努力不一定有回报,但是一定有收获!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律