
基于python的数学建模---轮廓系数的确定
直接上代码

from sklearn import metrics import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn import preprocessing import pandas as pd data = pd.read_csv('tae.csv') info_scaled = preprocessing.scale(data) X = info_scaled score = [] for i in range(2, 18): km = KMeans(n_clusters=i, init='k-means++', n_init=10, max_iter=300, random_state=0) km.fit(X) score.append(metrics.silhouette_score(X, km.labels_, metric='euclidean')) plt.figure(dpi=150) plt.plot(range(2, 18), score, marker='o') plt.xlabel('Number of clusters') plt.ylabel('silhouette_score') plt.show()
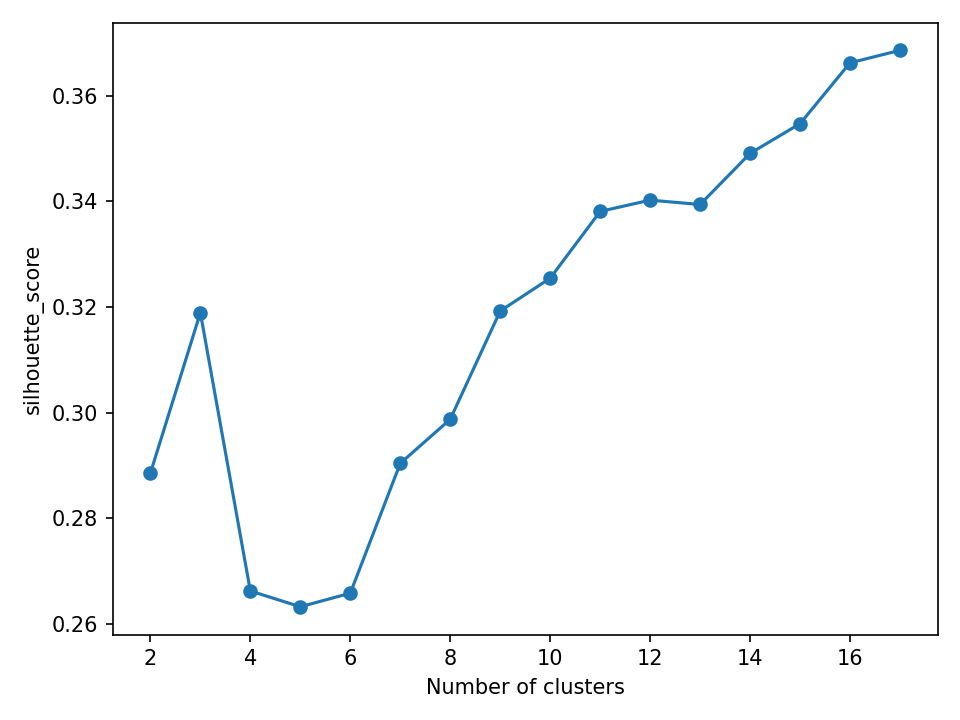
点越高,结果就越准确


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2021-08-10 栈、堆 运行关系