MariaDB 全文搜寻引擎 Mroonga 详解
在上一篇文章《MySQL的全文搜索FullText方案分析》中我简单的介绍了一下现行常见的几种全文搜索的方案。在其中我提到过这个由日本人开发的Mroonga 全文搜索引擎,由于此引擎在网路中鲜有资料能询,索性我自己来写一篇关于此引擎的用法,同时也会向大家说明此引擎在使用过程中如何避免踩坑。
Mroonga 的原理
Mroonga 实际上是一个MySQL 系的关系型SQL 中的插件,但又与一般的Plugin 有所区别。Mroonga 实际上在MySQL 中会被当作一个存储引擎所被SQL 辨识。然而实际上Mroonga 其实只是一个中间件,他的核心带了一个完整的Groonga。与SphinxSearch 的MySQL 外挂SphinxSE 作为一个中间件的原理类似,但又与SphinxSE 不同的是Mroonga 中已经自带了Groonga,所以并不需要像使用了SphinxSE 后还需安装一个SphinxSearch 本体程式。不管是SphinxSE 还是Mroonga,两者实现原理基本是一致的。
虽说Mroonga 也算是SphinxSearch 师门中的一个弟子,但在实际使用过程中就能发现,Mroonga 算是洗心革面重新做了人,与祖师SphinxSearch 彻底不同的是,使用的作业指令与MySQL 保持了最大的相容,基本可以说是MySQL 的FullText 全文搜索指令如何写,Mroonga 就如何写,格式可以说是一模一样。反观SphinxSearch,正宗俄国血统,作业指令基本就突出了一个暴力美学,与正常的SQL 指令相差非常大。
Mroonga 的使用限制
Mroonga 的使用限制其实是源自Groonga 的内部限制。
表(table)的限制:
- 单个Key(PRIMARY KEY 或UNIQUE KEY)的大小最大为4KiB,也就是4KB。
- 单个索引中所有Key(PRIMARY KEY 或UNIQUE KEY)的大小最大为4GiB,也就是4GB。
-
单表最大的记录数(Maximum Records):
- 无主键的表(Not have PRIMARY KEY)最大记录条数为1073741815 条。差不多10 亿。
- 有主键(PRIMARY KEY)或者使用了B 树(B-TREE)的主键(PRIMARY KEY USING BTREE)的最大记录条数为1073741823 条。差不多也是10 亿。
- 使用了杂凑表(HASH)的主键(PRIMARY KEY USING HASH)的最大记录条数为536870912 条。差不多是5 亿。
另外,如果表中的主键的值(Value of PRIMARY KEY)为非数字的情况下,例如是中文,那表将会无法变更为Mroonga。
表中的列(Column)的限制:
- 单个列(Column)的数据存储大小最大为256GiB,也就是256GB。
全文索引(FULLTEXT INDEX)的限制:
- 单个全文索引中不重复条目的情况下最大可索引268435455 条记录,约2.68 亿。
- 单个全文索引的大小最大为256GiB,也就是256GB。
列(Column)中的值(Value)的限制:
列(Column)中的值(Value)不能为NULL。如果你设置了NULL将会根据类型被自动转换为相应的值。举个例子就是,比如你的值是DATE或者DATETIME,NULL将会被转换成0 或者1970-01-01 00:00:00。字符串类型(String)的值将会被转换成空字符(empty)。其实与NULL没区别但就是不能是NULL的意思。此限制根据官方的说明说的是只会影响存储模式(Storage Mode),但实际上也同样会影响中间件模式(Wrapper Mode)的索引内容。这限制直接导致了以下类似的SQL 指令无法使用:
... VALUES (NULL)... WHERE xx = NULL
无法使用的SQL 指令:
CREATE TABLE (...) CHARSET not_listed_charset_aboveINSERT INTO (geometry_column_name) VALUES (GeomFromText('LineString(...)'))INSERT INTO (...) VALUES (NULL)START TRANSACTION
仅支持以下类型的字符集(Character):
- ASCII
- BINARY
- CP932
- EUCJPMS
- KOI8R
- LATIN1
- SJIS
- UJIS
- UTF8
- UTF8MB4
字符集(Character)的使用是可以支持该字符集的排序规则(Collations)的。例如utf8_general_ci等。
Mroonga 的工作模式选择
Mroonga 有两种工作模式,一种是存储模式(Storage Mode),另一种是中间件模式(或者称为包装器模式,Wrapper Mode)。这两种模式的作业原理不一样,下面将简单说明一下两种模式的原理与有什么优缺点。
- 存储模式Storage Mode
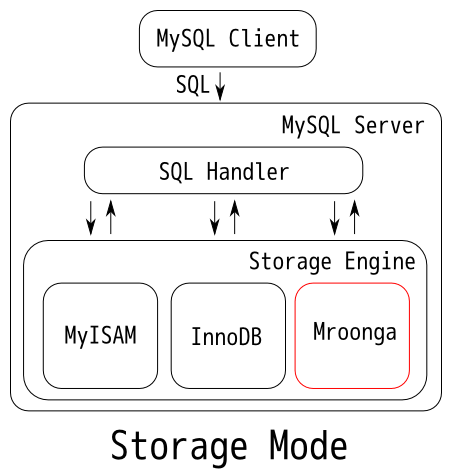
在此模式下,Mroonga 将作为一种存储引擎与MyISAM 或InnoDB 一样,直接提供存储功能与SQL 进行交互。在MySQL 中我们直接查看的话,表的存储引擎都会展示为Mroonga。但由于Mroonga 实际上只是个中间件,实际上数据都会存储在Groonga 中。所以我们可以简单的理解为,在此模式下,所有的数据并不存放在SQL 中,而是直接存储在Groonga 中。
存储模式的优点:
存储模式带来的优点是显而易见的,一是更高的搜索速度与更低的性能开销。这里我拿Mroonga 与MyISAM 进行对比。众所周知,MyISAM 在执行搜索作业(SELECT)之时,会对所涉及的表自动加上读取锁(Read Lock),同时在更改数据之时(UPDATE/DELETE/INSERT 等),又会对所涉及的表自动加上写入锁(Write Lock)。但Mroonga 在执行搜索作业的时候并不会对表进行加锁作业,所以搜索效能会比MyISAM 所使用的性能开销更小。同时在数据更新之后Groonga 内部能做到即时更新索引,且开销会比中间件模式更低。二是在存储模式下,数据只会存储一份。这意味着占用硬盘的空间会比中间件模式更小。这个优点其实说的有点牵强,但我们可以来看看现在企业级固态硬盘SSD 的价格与容量,在荷包不是特别充裕的情况下,这点就有点重要了。
存储模式的缺点:
但存储模式并不是全是优点,相反此模式下的缺点也非常突出。首先,存储模式下的Mroonga 存储引擎不支持事务(Transaction)。这点上来说,如果你之前使用的是MyISAM 引擎准备迁移至Mroonga 的话,这是没问题的。但如果你使用的是InnoDB,那就千万别直接迁移至Mroonga 的存储模式。
缺点二,在不使用SSD固态硬盘的情況下,同时表内数据量较大时,除了全文搜索Full Text Search以外,一定时间内的首次查询速度都会比MyISAM慢。因为Groonga 使用的是列存储(Column Based Storage)而不是行存储(Row Based Storage),Mroonga 需要从Groonga 中提取数据经过转换后才会交给SQL,这个转换过程很明显是需要时间和性能开销的。然而如果只是取一行数据的话,那这个转换过程的时间与性能的开销可以忽略不计。但如果一次取个几千条几万条数据呢?例如这句LIMIT 9900, 100我要取这10000 条数据中的最后100 条且我要求是这行的所有数据都取出来并不使用全文搜索的方式而使用一般的SELECT,那Mroonga 就需要同时定位所有的列到此位置并同时取出进行转换,同时Groonga 的档案存储方式使用了分散式存储,按照列分散的存储在了不同的文件中,这个读取数据过程将会占用非常高的IO 资源。如果这时使用的是HDD 机械硬盘,将直接导致查询速度肉眼可见的龟速。但这个问题其实也是可以解决的,优化的办法就是使用SSD 固态硬盘。因为随便一个正常的SSD 固态硬盘,读取的IOPS 都是几万以上。而HDD 机械硬盘的读取IOPS 都是70~100 IOPS,就算是10000RPM 的企业级SAS HDD,其读取的IOPS 也不会超过230 IOPS。但以至于为何是一定时间内的首次查询速度都会比MyISAM 慢呢而不是每次都慢的原因是有快取(Cache)的存在。当然如果快取过期了下次查询的速度又会慢了。但为何全文搜索Full Text Search 的速度就没龟速呢,直接原因就是全文搜索是在Groonga 建立的FullText Index 索引中进行特征码搜索,之后就能直接快速的提出所需要的数据。
缺点三,这个问题其实是个玄学问题。Mroonga的存储模式稳定性存在不确定因素。这个其实我并没有直接的测试数据与证据能直接证明Mroonga 作为存储引擎的可靠性不行,但由于这种直接替代的存储引擎的作业方式是否能保证数据的安定?这个可能还需要时间的检验。
综上所述,如果要使用存储模式进行作业,我能给出的建议是:
- 使用可靠性和性能都高的SSD 固态硬盘,同时记忆体最好大于或者等于16GB,CPU 性能最好不要太弱(比如Celeron 或者Atom 就算了吧)。
- 在使用SELECT 进行查询作业的时候,做到需要什么值取什么值,例如
SELECT value1, value2,不要直接SELECT *全部取了。 - 如果是从老数据库迁移过来的话,最好是MyISAM 迁移至Mroonga。
- 如果可以建议将整个库的所有表都变更为Mroonga 存储引擎,避免出现
JOIN了不是Mroonga 的表影响性能。 - 备份作业一定要做好。
很明显,此模式比较适合不想做太多改动就能用上全文搜索引擎和主要是以搜索为主要服务的项目。唯独不适用于需要使用InnoDB 特性的项目,例如EC 电子商务平台等对支持事务作业的项目。
- 中间件模式(包装器模式,Wrapper Mode)
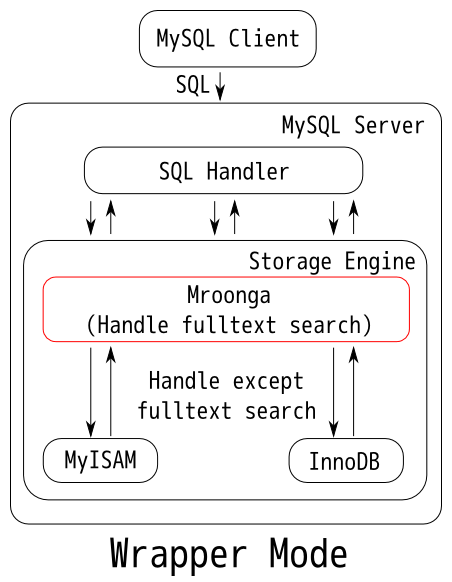
在此模式下,Mroonga 将作为SQL 处理模组(SQL Handler)与存储引擎之间的一个中间件。Mroonga 只会处理FullText 的全文搜索SQL 指令。按照官方给出的说明图中我们可以看出Mroonga 作为一个存储引擎展现给SQL 处理模组,但实际数据将会全部交给其他存储引擎,同时将所有除FullText 全文搜索指令以外的指令都交由其存储引擎来进行处理。实际上我们可以这么理解,Mroonga 的中间件模式下,对MySQL 而言,MySQL 依旧是将Mroonga 认作一个存储引擎,实际上Mroonga 内部包了一层其他存储引擎做数据的存储。
但官方未说明的是,Groonga 此时又做了什么呢。根据我翻看其原始程式码的结果来看,实际上此实现并非想象中的复杂,Mroonga 作为一个中间件,除了SELECT 指令以外的SQL 指令,都将会同时发给其他存储引擎与Groonga。意思就是Groonga 内依旧留有一份数据。但由于Mroonga 只在处理FullText 全文搜索指令之时,才会只向Groonga 发送搜索指令。其他的SELECT 指令都会只交给其他存储引擎处理。
但由于Groonga 并不支持事务(Transaction)作业,如果使用的是InnoDB 的特性或者一些特有机能的话,例如事务作业,Mroonga 将会在事务作业结束后根据结果向Groonga 同步一次存储引擎内的数据并更新全文搜索索引。然而实际上并非所有的InnoDB 事务作业指令都能成功转换为非事务作业,所以Mroonga 会定期向Groonga 发送一次同步存储引擎内的数据并重建索引的作业指令。
中间件模式的优点:
很明显,中间件模式下能支持其他存储引擎的特性了。例如InnoDB 的事务作业等等。实际上这个模式下的原理与我们使用其他独立的全文搜索引擎的原理是一样的。例如SphinxSearch 的直接连接SQL 模式而非通过SphinxSE 插件连接,在全文搜索引擎内部与SQL 中都存有一份数据来做各自的处理。这样就能实现互不干扰互相独立作业。
中间件模式的缺点:
中间件模式也非常明显,通过上面的原理分析我们能很轻松的看出在数据更改作业下,写入的性能开销会非常大。事实上也是如此。毕竟要同时向两边写入数据更新,如是使用了一些Groonga 本身并不能支持的特性的情况下,例如事务作业,Mroonga 只能采取全量数据更新并重建索引的作业。当然,如果在表中数据量并不多的情况下,这个处理资源占用并不会非常明显。但如果是一个几十万起步的表,在执行以上操作之时将会占用大量的CPU、IO 与记忆体资源。
缺点二,在使用了一些Groonga本身并不能支持的特性的情況下,更改写入数据之后在一定时间内会出现存储引擎内的数据内容与Groonga中的数据内容与全文搜索索引不一致的情況。造成这点的原因也可以从上面说的原理中看出,重新更新数据与重建索引是需要一定处理时间的,在处理完成之前数据肯定是会出现不同步的情况。
缺点三,这问题其实还是个玄学问题。还是这个中间件模式的可靠性存疑。虽然Mroonga 在中间件模式下的实现原理与SphinxSearch 的普通索引模式一致,但不代表Mroonga 就与SphinxSearch 一样并不会影响到MySQL。例如SphinxSearch 在自身进程崩溃的情况下,他并不会影响到MySQL 的作业。但Mroonga 并不是这样。Mroonga 就算是使用中间件模式,SQL 处理模组依旧是将此表认定为Mroonga 存储引擎并将所有的指令都交给Mroonga 来进行处理。而就算使用了其他存储引擎进行存储,也都是被包在Mroonga 中。所以能很明显看出一点就是,如果Mroonga 的中间件出现了些什么问题,最坏的情况也会导致数据损毁。
综上所述,如果要使用中间件模式进行作业,我能给出的建议是:
- 使用可靠性和性能都高的SSD 固态硬盘,同时记忆体最好大于或者等于16GB,CPU 性能最好不要太弱(比如Celeron 或者Atom 就算了吧)。
- 建议将所有可能涉及到FullText 全文搜索作业的表都转变为此模式以免造成
JOIN了不是Mroonga 的表影响性能。 - 备份作业
一定一定一定要做好。
此模式很明显,如果你不是使用什么InnoDB 的特性的话,例如事务作业等等,我并不推荐使用此模式。我们对数据库的要求最低底线是保证数据安全。但很明显此模式下会造成数据损毁的隐患并不小。这个道理其实很简单,结构越复杂的东西出错的可能性越高。
Mroonga 的安装
Mroonga 的安装我大致给他分成两种,一种是独立安装Mroonga,另一种是直接使用高版本MariaDB 自带的Mroonga。
独立安装Mroonga
独立安装Mroonga 的话可以参考他们的官方文档《如何安装Mroonga》,因为针对系统与使用的SQL 不用,都有不一样的安装方法,这里就不细讲了。毕竟以后如果安装方式有任何更新,官方文档肯定更新的最快,所以我在这边细说如何安装也没有任何意义。这种方式适合使用MySQL、Percona 或者是没有自带Mroonga 的MariaDB 版本或者想在已经自带了Mroonga 的MariaDB 上安装新版本的Mroonga。
使用自带Mroonga 的MariaDB
这种方式其实对于像我这种大部分都在用MariaDB 的人来说,是最简单的方式。虽然简单,但MariaDB 自带的Mroonga 版本并不是最新的,且并不是所有的MariaDB 版本都自带了Mroonga。
如果要使用自带Mroonga 的MariaDB,需要安装以下版本号或以上的MariaDB:
| Mroonga Version | Introduced | Maturity |
|---|---|---|
| 7.07 | MariaDB 10.2.11和MariaDB 10.1.29 | Stable |
| 5.04 | MariaDB 10.1.6 | Stable |
| 5.02 | MariaDB 10.0.18,MariaDB 10.1.5 | Stable |
| 5.0 | MariaDB 10.0.17 | Stable |
| 4.06 | MariaDB 10.0.15 | Stable |
在上图所示的MariaDB 版本或者更新的版本中,我们只需使用MySQL Client 连接至MariaDB 的命令行控制台中使用以下命令就能启用:
mysql> INSTALL SONAME 'ha_mroonga';
但如果你现在所安装的MariaDB 版本中并无自带Mroonga 并且同时使用的是Ubuntu 或者Debian 的系统,且你的MariaDB 是通过APT 包管理器安装的,你可以使用以下命令安装Mroonga 的MariaDB 外挂:
sudo apt-get install mariadb-plugin-mroonga
除此之外,请使用独立安装Mroonga 的方式进行安装。
安装完毕后,我们可以在MySQL 命令行控制台中使用以下命令查看Mroonga 引擎的情况:
mysql> SHOW ENGINES;
正常的话此命令的展示结果类似下面这样:

如果你想能获取到Groonga 中的最后一条插入的数据的ID,可以使用以下的命令新增一个用户自定义函数(UDF, User-Defined Function):
mysql> CREATE FUNCTION last_insert_grn_id RETURNS INTEGER SONAME 'ha_mroonga.so';
这样就能使用last_insert_grn_id这个函数获取到Groonga 中的最后一条插入的数据的ID。
Mroonga 的使用
正如本文标题所说,我的目的是用Mroonga 的全文搜索取代LIKE模糊搜索机能。看到这里肯定有人会问,为什么拿一个全文搜索引擎来替代LIKE模糊搜索机能呢?这个问题的答案其实很简单,我需要更高的搜索性能和更低的伺服器性能占用。且我研究了这么多年的全文搜索引擎的经验来看,一般全文搜索引擎中都要经历一个断词的作业。然而根据我的实际经验来看,实际上断词这个作业只是为了降低全文搜索引擎压力而必须的一个作业而已,实际上还会因为断词误差导致搜索结果不准确。我对搜索的定义其实就是要求他对关键词准确匹配,在CJK 语言(中国语Chinese,日本语Japanese,韩国语Korean)中实际上准确率最高的搜索方式就是将一句话例如“我吃饱了”拆成一个个字进行搜索。在LIKE模糊搜索下我一般是这么处理:
SELECT ... WHERE (`field` LIKE '%我%') AND (`field` LIKE '%吃%') AND (`field` LIKE '%饱%') AND (`field` LIKE '%了%') LIMIT 50;
类似如此的处理方式来进行搜索。当然,肉眼可见在一个大型数据库中这搜索速度将会十分龟速,以上这句搜索指令将会对全表进行最低4 次的扫描。
以此为基础我要如何使用Mroonga 进行替代操作呢?接下来将会从零开始说明如何一步步从模糊搜索切换为Mroonga。
- 1. 将表的存储改为Mroonga
不管是要用存储模式还是中间件模式,都得将表的存储引擎改为Mroonga,唯一的区别就只是是否对表的备注说明中加入模式的关键词。
将现有的表更改为存储模式:
mysql> ALTER TABLE `table` ENGINE = Mroonga;
将现有的表更改为中间件模式:
mysql> ALTER TABLE `table` ENGINE = Mroonga COMMENT = 'engine "MyISAM"';
这里的MyISAM 可以选择InnoDB。
但如果只是新建一个表,那一切就容易的多了。
新建一个表并使用存储模式:
mysql> CREATE TABLE `table` ( id INT PRIMARY KEY AUTO_INCREMENT, content VARCHAR(255), FULLTEXT INDEX (content) ) ENGINE = Mroonga DEFAULT CHARSET utf8mb4 COLLATE utf8mb4_general_ci;
utf8mb4 与utf8mb4_general_ci 也可按需要选择。
新建一个表并使用中间件模式:
mysql> CREATE TABLE `table` ( id INT PRIMARY KEY AUTO_INCREMENT, content VARCHAR(255), FULLTEXT INDEX (content) ) ENGINE = Mroonga COMMENT = 'engine "MyISAM"' DEFAULT CHARSET utf8mb4 COLLATE utf8mb4_general_ci;
从上面的指令可以很简单的看出,存储模式与中间件模式的选择只是COMMENT的内容有无而已。中间件模式需要对COMMENT加上相应的标记COMMENT = 'engine "MyISAM"'。
- 2. 建立全文索引并选择相应的解析器
由于Mroonga 的目的是做到最大兼容,所以我们要使用全文搜索之前必须得为此建立一个全文搜索索引。同时,Mroonga 的解析器的概念与MySQL 的FullText 索引的解析器概念也是一样的。唯一不同的是,Mroonga 为了更方便的热切换解析器,解析器选择依旧是用了对COMMENT添加描述关键词来进行设置。
Mroonga 的解析器其实有15 种可选,由于我的目标是替代模糊搜索,所以我选择的解析器为TokenBigramSplitSymbolAlphaDigit。由于正常的模糊搜索是会对空格敏感的,所以要做到100% 替代的话不能使用TokenBigramIgnoreBlankSplitSymbolAlphaDigit这个解析器。其他的解析器的说明可以参考Mroonga 官方的说明文档《如何为全文搜索索引指定解析器》。
新建全文搜索索引并指定解析器:
mysql> FULLTEXT INDEX (column_fulltext) COMMENT 'tokenizer "TokenBigramSplitSymbolAlphaDigit"'
当然,这个解析器是可以热更换的,我们直接修改COMMENT 的内容即可。
更换全文搜索索引的解析器:
mysql> ALTER TABLE `DataBase`.`table` ADD FULLTEXT `column_fulltext` (`column`) COMMENT 'tokenizer \"TokenBigramSplitSymbolAlphaDigit\"';
从上面的指令我们还是能看出Mroonga 的设计理念,为了最大化兼容MySQL 的正常SQL 指令,并没有使用一些非正常指令。但是这设定解析器的方式是有限制的,限制来源于MySQL。因为在MySQL 5.5 版本开始才支持对索引设置COMMENT 描述内容。所以如果你使用的是低于这个版本的MySQL,需要你在my.cnf中设定一个固定的参数mroonga_default_tokenizer=TokenBigramSplitSymbolAlphaDigit来进行指定解析器的操作。然而这样就无法做到热设置解析器了。
- 3. 使用全文搜索索引进行全文搜索
到这步,我们就已经可以开始使用Mroonga 来进行全文搜索了。Mroonga 的全文搜索指令与正常的MySQL FullText 全文搜索使用的语法结构是一致的。Mroonga 的全文搜索模式有两种,一种是普通的布尔搜索模式(BOOLEAN MODE),另一种是自然语言模式(NATURAL LANGUAGE MODE)。简单来说,就是布尔搜索模式下只有匹配与不匹配,没有其他结果,类似的使用场景为精准搜索。而自然语言模式下提供的并不是一个精准搜索而是提供一个近似内容,类似的使用场景为搜索关键字补全候选功能等。其实这两个模式也是MySQL 的FullText 所提供的标准模式,所以用法也与MySQL 没有区别。
回归到我的目标上,我要替代模糊搜索,例如以下这条LIKE 指令:
SELECT ... WHERE (`field` LIKE '%我%') AND (`field` LIKE '%吃%') AND (`field` LIKE '%饱%') AND (`field` LIKE '%了%') LIMIT 50;
使用Mroonga 我们需要这么写:
SELECT ...USE INDEX(column_fulltext) WHERE (MATCH(field) AGAINST('*D+ "我" "吃" "饱" "了"' IN BOOLEAN MODE)) LIMIT 50;
同时以下这条指令与上面这条指令的效果一致:
SELECT ...USE INDEX(column_fulltext) WHERE (MATCH(field) AGAINST('*D+ "我"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "吃"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "饱"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "了"' IN BOOLEAN MODE)) LIMIT 50;
以上是关键词的AND 搜索示例。那如果我要使用的是多个关键词中只要出现一个就命中的OR 模式呢?例如以下这条指令:
SELECT ... WHERE (`field` LIKE '%我%' OR `field` LIKE '%吃%' OR `field` LIKE '%饱%' OR `field` LIKE '%了%') LIMIT 50;
使用Mroonga 我们需要这么写:
SELECT ...USE INDEX(column_fulltext) WHERE (MATCH(field) AGAINST('*D+ "我" OR "吃" OR "饱" OR "了"' IN BOOLEAN MODE)) LIMIT 50;
那如果我要AND 和OR 混写呢?无问题,例如以下这条:
SELECT ... WHERE (`field` LIKE '%我%') AND (`field` LIKE '%吃%') AND (`field` LIKE '%饱%') AND (`field` LIKE '%了%') AND (`field` LIKE '%塞%' OR `field` LIKE '%林%' OR `field` LIKE '%老%' OR `field` LIKE '%目%') LIMIT 50;
使用Mroonga 我们可以这么写:
SELECT ...USE INDEX(column_fulltext) WHERE (MATCH(field) AGAINST('*D+ "塞" OR "林" OR "老" OR "目"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "我" "吃" "饱" "了"' IN BOOLEAN MODE)) LIMIT 50;
同理,也可以这样写:
SELECT ...USE INDEX(column_fulltext) WHERE (MATCH(field) AGAINST('*D+ "塞" OR "林" OR "老" OR "目"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "我"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "吃"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "饱"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "了"' IN BOOLEAN MODE)) LIMIT 50;
那么假如我要在搜索的同时去掉某些关键词呢?例如以下这样的指令:
SELECT ... WHERE (`field` LIKE '%我%') AND (`field` LIKE '%吃%') AND (`field` LIKE '%饱%') AND (`field` LIKE '%了%') AND (`field` LIKE '%塞%' OR `field` LIKE '%林%' OR `field` LIKE '%老%' OR `field` LIKE '%目%') AND (`field` NOT LIKE '%靠北%') LIMIT 50;
使用Mroonga 我们可以这么写:
SELECT ...USE INDEX(column_fulltext) WHERE (MATCH(field) AGAINST('*D+ "塞" OR "林" OR "老" OR "目" -"靠北"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "我" "吃" "饱" "了" -"靠北"' IN BOOLEAN MODE)) LIMIT 50;
或者这样:
SELECT ...USE INDEX(column_fulltext) WHERE (MATCH(field) AGAINST('*D+ "塞" OR "林" OR "老" OR "目"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "我"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "吃"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "饱"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ "了"' IN BOOLEAN MODE)) AND (MATCH(field) AGAINST('*D+ -"靠北"' IN BOOLEAN MODE)) LIMIT 50;
以上就是使用Mroonga 进行全文搜索的一些例子。我们可以总结一下:
- AND 关键词
使用方式:
...AGAINST('*D+ "我" "吃"' IN ... 或者
...AGAINST('*D+ "我"' IN ... AND ...AGAINST('*D+ "吃"' IN ...
- OR 关键词
使用方式:
...AGAINST('*D+ "我" OR "吃"' IN ...
- 不需要的关键词
使用方式:
...AGAINST('*D+ "我" OR "吃" -"靠北"' IN ...
可以看到,如果我们希望过滤掉搜索结果中出现某个关键词的结果,我们可以使用-关键词的方式设置一个过滤。
这么看下来,可能大家还有最后一个问题,这个*D+是什么鬼。其实这个*D+的用处是指定默认搜索模式为AND 搜索。如果使用的*D那就是默认模式为OR 搜索。
如果不加此模式指定的话,那我们必须在每个关键词前指定这个关键是究竟是AND 还是OR 还是NOT。他们的关系是这样的:
- '+ 关键词' 代表着这个关键词为AND,必须存在。
- '- 关键词' 代表着这个关键词为NOT,不能出现。
- '关键词' 什么都不加的话代表着这个关键词为OR,有就出现没有就算了。
同理,如果我们不指定默认运算符的话,将下面这条指令变成Mroonga 指令:
SELECT ... WHERE (`field` LIKE '%我%') AND (`field` LIKE '%吃%') AND (`field` LIKE '%饱%') AND (`field` LIKE '%了%') AND (`field` LIKE '%塞%' OR `field` LIKE '%林%' OR `field` LIKE '%老%' OR `field` LIKE '%目%') AND (`field` NOT LIKE '%靠北%') LIMIT 50;
变成不设置默认搜索模式的Mroonga 搜索指令的话就应该是这样:
SELECT ...USE INDEX(column_fulltext) WHERE (MATCH(field) AGAINST('+"我" +"吃" +"饱" +"了" "塞" "林" "老" "目" -"靠北"' IN BOOLEAN MODE)) LIMIT 50;
是不是更简单了呢?是不是有人想问了为什么一开始不告诉大家有这么一种简单的写法?其实原因很简单,这种简单的写法很容易出现定义不清晰导致搜索出不是想要的结果,而且有很多复杂的搜索指令是完全无法实现的。所以尽量还是别使用这种简单的指令来进行搜索。
最后,其实Mroonga 还支持正则表达式的搜索,但前提条件是将解析器改为TokenRegexp(COMMENT 'tokenizer"TokenRegexp"),示例如下:
SELECT ...USE INDEX(column_fulltext) WHERE MATCH(field) AGAINST ('*SS content @~ "\\\\A/var/log/auth"' IN BOOLEAN MODE);
具体的正则表达式搜索可参考官方文档《如何使用正则表达式进行搜索》。
总结
说实话,我最开始寻找全文搜索引擎的原因就是需要找一个能花最少力气修改原始程式码就能从模糊搜索迁移的方案。在我测试过几乎所有的全文搜索引擎之后,几乎没有一款能满足我的需求。直到我知道了Mroonga 的存在之后进行了相应的测试,我发现Mroonga 最合适的用途就是这个,花最少的力气替代LIKE模糊搜索。
当然我并不是说其他的全文搜索引擎不好,只是不合适这个需求。
诚然,我承认Mroonga 的效能在所有全文搜索引擎里并不是最好的,但我要求本来也不高,只要能比MySQL 原生的模糊搜索快就行了。事实上Mroonga 也胜任了这点。
Mroonga 力求不过多改变MySQL的使用体验应该说是他最大的亮点。
所以当你有类似的需求的时候,不妨来考虑一下Mroonga。
原文:https://deepskyfire.com/sub/23.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号