

C++11多线程编程(二)——互斥锁mutex用法
还是那个问题,编程世界中学习一个新的技术点,一定要明白一件事,为什么要出现这个技术点,只有弄懂了这个才能从根本上有学习的动力。那么为什么要出现多线程锁这个东西呢?一句话概括的话。
为了保证数据的准确性!
计算机就是为了计算数据才诞生的,如果不能保证数据准确的话,任何技术都只是空中楼阁,多线程技术也是一样,那么为什么多线程会让数据不准确呢?大家可以看下以下的这个例子
#include <iostream> #include <thread> #include <string> using namespace std; void thread_task() { for (int i = 0; i < 10; i++) { cout << "print thread: " << i << endl; } } int main() { thread t(thread_task); for (int i = 0; i > -10; i--) { cout << "print main: " << i << endl; } t.join(); return 0; }
输出结果
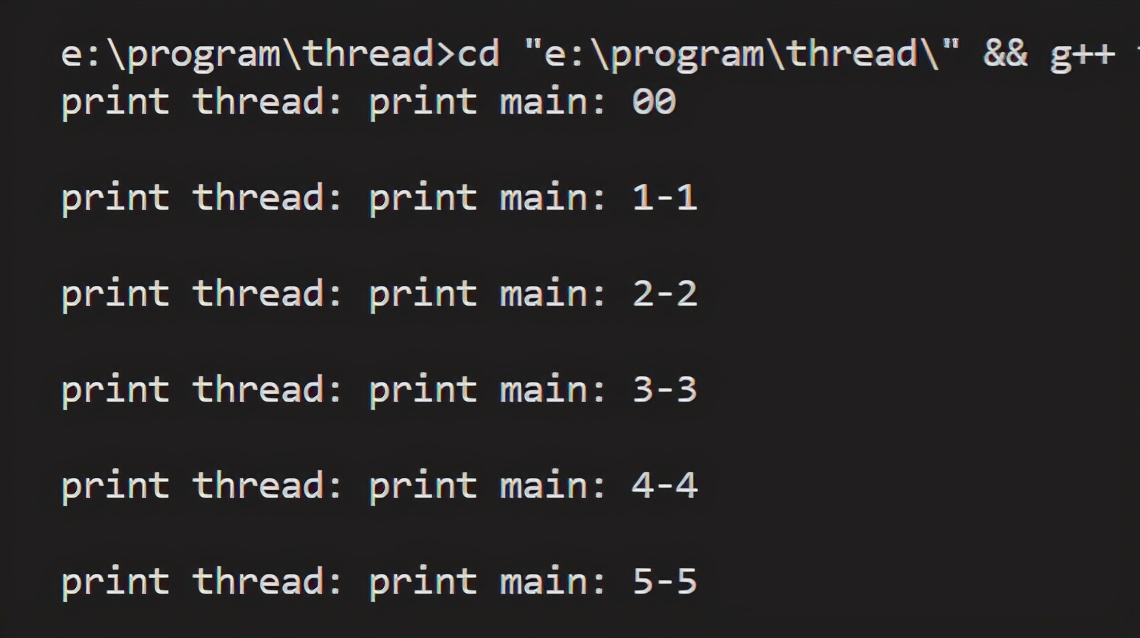
大家可以看到产生了一个很奇怪的现象,按理说输出“print thread:”之后应该跟着i的值,但是i的值却跑到“print main:”的后面了,这显然不是我们能要的结果,那为什么会这样呢?因为多线程执行的话,是操作系统内部控制的,一般是通过时间片轮询来轮流执行的,甚至在多核CPU下是并行执行的。
那么怎么解决这个问题呢?以便我们在一个线程里处理完我们所需要的数据之后,然后才将控制权交出呢?这个就是用到锁这个东西。
假设线程A在执行cout << "print thread: " << i << endl;这个代码之前,在前面锁住一下,当线程B想来抢夺控制权的时候,发现这个地方已经被上锁了,无法抢夺,只能等待,等待它释放。执行完那个代码之后就可以释放锁,然后B线程就是来抢夺控制权了,一旦B获得了控制权也给自己上了锁,防止在执行关键地方的时候被别人夺去控制权。那么C++如何实现加锁的过程的呢?
C++当中用到的一个类是mutex,这个中文就是互斥量的意思,顾名思义,就是一个时刻只能有一个访问,以下是代码
#include <iostream> #include <thread> #include <string> #include <mutex> using namespace std; mutex mt; void thread_task() { for (int i = 0; i < 10; i++) { mt.lock(); cout << "print thread: " << i << endl; mt.unlock(); } } int main() { thread t(thread_task); for (int i = 0; i > -10; i--) { mt.lock(); cout << "print main: " << i << endl; mt.unlock(); } t.join(); return 0; }
在需要加锁的地方,调用metex的lock()方法,解锁的地方unloc()方法,这样就可以顺序的输出了所需要的结果了。
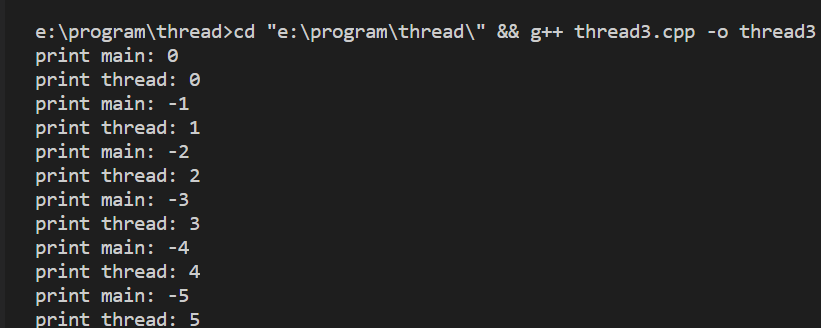
以上就是C++中关于互斥锁的机制,相当的简单容易理解。
更多精彩内容,请关注同名公众:一点月光(alittle-moon)


