Python实现 利用朴素贝叶斯模型(NBC)进行问句意图分类
另外:点击右下角魔法阵上的【显示目录】,可以导航~~
朴素贝叶斯分类(NBC)
这篇博客的重点不在于朴素贝叶斯分类的原理,而在于怎么用朴素贝叶斯分类器解决实际问题。所以这边我就简单介绍以下我们使用的模型。
NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。贝叶斯方法是以贝叶斯原理为基础,使用概率统计的知识对样本数据集进行分类。它假设特征条件之间相互独立,先通过已给定的训练集,以特征词之间独立作为前提假设,学习从输入到输出的联合概率分布,再基于学习到的模型,输入X求出使得后验概率最大的输出Y。
程序简介
这是一个糖尿病医疗智能问答的子模块。目的是把糖尿病患者提出的问题对其意图进行分类,以便后续根据知识图谱对问句进行回答。
对于意图分类这个子模块,我的思路是自己构建数据集和类别,再对问句进行分词,槽值替换,去停用词,根据特征词构建one-hot向量后,调用skearn模块的朴素贝叶斯接口建模,对问句进行分类。
要解决这个意图分类问题,有以下几点需要注意:
- 在缺少大量而准确的数据集的情况下,深度学习模型并不是一个很好的选择,没有足够多的样本,难以训练好那么多的参数。于是我在这里选择朴素贝叶斯的方法。
- 由于缺少现成的数据集,我自己构建了数据集。这里有些讲究:每个类别最好数量均衡;每个类别要注意包含一些关键词,各个关键词数量均衡,搭配均衡。
- “一型糖尿病可以吃草莓吗?“ 与 ”二型糖尿病可以吃苹果吗?“在意图上是一个类别的问题,然而重叠的特征词似乎只有“可以”,“吃”,“吗”,而这些有点类似于停用词了。但我们人类能看出它们是一个意图,是因为“一型糖尿病”,“二型糖尿病”,“草莓”,“苹果”这些实词。但我们不可能在数据集里穷举所有的病名和水果名甚至其它食物,那如何让它们被识别为一类呢?所以这里我进行了槽值替换。将所有病名都替换为”[DISEASE]";所有蔬菜水果都替换为"[FOOD]"。替换后再统计词频进行训练,效果就比较好。
最终我实现了这样一个分类器,它的接口为
- 输入:糖尿病患者提出的问句
- 输出:问句的意图分类
github地址:https://github.com/PengJiazhen408/Naive-Bayesian-Classifier
分类流程
问句-->槽值替换-->分词-->根据vocab.txt 生成特征向量 --> 模型预测生成标签 --> 标签转换为类别(中文)
如:
| 问句 | 槽值替换后 | 分词后 | one-hot 特征词向量 | 标签 | 类别 |
|---|---|---|---|---|---|
| 糖尿病可以吃草莓吗 | [DISEASE]可以吃[FOOD]吗 | [/DISEASE/]/可以/吃/[/FOOD/]/吗 | [1, 0, 0, 0, 0, 0, 0, 0, 1 ....] | 2 | 饮食 |
| 胰岛素的副作用 | [DRUG]的副作用 | [/DRUG/]/的/副作用 | [0, 0, 0, 1, 0, 0, 0, 0, 0 ....] | 5 | 用药情况 |
| 糖尿病吃什么药 | [DISEASE]吃什么药 | [/DISEASE/]/吃什么/药 | [1, 0, 0, 0, 0, 0, 0, 0, 0 ....] | 3 | 用药治疗 |
| 糖尿病高血糖怎么治 | [DISEASE][DISEASE]怎么治 | [/DISEASE/]/[/DISEASE/]/怎么/治 | [2, 0, 0, 0, 0, 0, 0, 1, 0 ....] | 0 | 治疗 |
字典(dict)构造:用于jieba分词和槽值替换
类别
| 文件名 | 内容 | 例子 |
|---|---|---|
| category.txt | 食物集合名 | 如:海鲜,早餐等 |
| check.txt | 检查项目名 | 如:测血糖,抽血等 |
| department.txt | 科室名 | 如:内分泌科,儿科等 |
| disease.txt | 疾病名 | 如:糖尿病,一型糖尿病等 |
| drug.txt | 药物名 | 如:胰岛素,二甲双胍等 |
| food.txt | 食物和水果 | 如:苹果,绿豆等 |
| style.txt | 生活方式名 | 如:运动,跑步,洗澡等 |
| symptom.txt | 症状名 | 如:头疼,腹泻等 |
格式
-
一个词一行
-
每个文件第一个词是类别名,如[DISEASE],[DRUG] 用于槽值替换
数据集构建
-
训练集(train_data.txt): 各类50例
-
测试集(test_data.txt): 各类5或10例
-
格式:问句 类别(中文)
-
注意事项:每个类别要注意包含一些关键词,各个关键词数量均衡,搭配均衡
代码分析
共有4个主程序:
- data_pro.py 处理原始数据集,生成类别文件,将类别转换为数字标签并存为文件
- extract.py 根据训练数据,经过槽值替换,分词,人工筛选等步骤,生成 vocab.txt
- main.py 模型训练,测试,单句预测
- predict.py 根据训练好的模型,批量预测
data_pro.py: 由train_data.txt, test_data.txt生成 class.txt, train.txt, test.txt
导入模块
from utils import open_data
from random import shuffle
import os加载原始数据集(train_data.txt, test_data.txt)
def open_data(path):
contents, labels = [], []
with open(path, 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
lin = line.strip()
if not lin:
continue
content, label = lin.split('\t')
contents.append(content)
labels.append(label)
return contents, labels
# 加载原始数据
x_train, c_train = open_data('data_orig/train_data.txt')
x_test, c_test = open_data('data_orig/test_data.txt')对类别列表去重,生成class.txt
# 识别所有类,生成类别列表和字典,并保存类别列表
if not os.path.exists('data'):
os.mkdir('data')
class_list = list(set(c_train))
with open('data/class.txt', 'w', encoding='utf-8') as f:
f.writelines(content+'\n' for content in class_list)
class_dict = {}
for i, item in enumerate(class_list):
class_dict[item] = str(i)将每个问句的类别(中文)转换为标签(数字)
打乱数据集,保存在train.txt, test.txt
def pro_data(x, c, str):
y = [class_dict[i] for i in c]
all_data = list(zip(x, y))
shuffle(all_data)
x[:], y[:] = zip(*all_data)
folder = 'data/'
save_sample(folder, str, x, y)
return x, y
def save_sample(data_folder, str, x, y):
path = data_folder + str + '.txt'
with open(path, 'w', encoding='utf-8') as f:
for i in range(len(x)):
content = x[i] + '\t' + y[i] + '\n'
f.write(content)
# 类别转换为标签, 打乱顺序, 保存
x_train, y_train = pro_data(x_train, c_train, 'train')
x_test, y_test = pro_data(x_test, c_test, 'test')extract.py: 由train.txt, stopwords.txt 生成 特征列表 vocab.txt
加载train.txt,提取其所有问句;加载stopwords.txt,生成停用词表
def open_data(path):
contents, labels = [], []
with open(path, 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
lin = line.strip()
if not lin:
continue
content, label = lin.split('\t')
contents.append(content)
labels.append(label)
return contents, labels
# 加载问句列表和停用词表
questions, _ = open_data('data/train.txt')
stopwords = [line.strip() for line in open("data/stopwords.txt", 'r', encoding="utf-8").readlines()]对问句槽值替换。步骤:
- 加载dict中的文件,生成同义词表的字典,key:每个词,value:该词所在文件第一个词
- 问句分词
- 遍历问句的每个词,用同义词表进行替换
- 返回替换后的句子
如:
| 原句 | 分词 | 替换 |
|---|---|---|
| 糖尿病可以吃草莓吗 | 糖尿病/可以/吃/草莓/吗 | DISEASE]可以吃[FOOD]吗 |
| 胰岛素的副作用 | 胰岛素/的/副作用 | [DRUG]的副作用 |
| 糖尿病吃什么药 | 糖尿病/吃什么/药 | [DISEASE]吃什么药 |
| 糖尿病高血糖怎么治 | 糖尿病/高血糖/怎么/治 | [DISEASE][DISEASE]怎么治 |
def load_jieba():
# jieba加载词典
for _, _, filenames in os.walk('dict'):
for filename in filenames:
jieba.load_userdict(os.path.join('dict', filename))
# jieba分词时,对下列这些词继续往下分
del_words = ['糖尿病人', '常用药', '药有', '感冒药', '特效药', '止疼药', '中成药', '中药', '止痛药', '降糖药', '单药', '喝啤酒',
'西药', '怎样才能', '要测', '要验', '能测', '能验', '喝酒', '喝奶', '吃糖', '喝牛奶', '吃肉', '茶好', '吃水果']
# jieba分词时,不要把下列这些词分开
add_words = ['DISEASE', 'SYMPTOM', 'CHECK', 'FOOD', 'STYLE', 'CATEGORY', '会不会', '能不能', '可不可以', '是不是', '要不要',
'应不应该', '啥用', '什么用', '吃什么', '喝什么']
for word in del_words:
jieba.del_word(word)
for word in add_words:
jieba.add_word(word)def synonym_sub(question):
# dict文件夹中的每个文件是一个同义词表
# 1读取同义词表:并生成一个字典。
combine_dict = {}
for _, _, filenames in os.walk('dict'):
for filename in filenames:
fpath = os.path.join('dict', filename)
# 加载同义词
synonyms = []
with open(fpath, 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
synonyms.append(line.strip())
for i in range(1, len(synonyms)):
combine_dict[synonyms[i]] = synonyms[0]
# with open('synonym.txt', 'w', encoding='utf-8') as f:
# f.write(str(combine_dict))
# 2将语句切分
seg_list = jieba.cut(question, cut_all=False)
temp = "/".join(seg_list)
# print(temp)
# 3
final_sentence = ""
for word in temp.split("/"):
if word in combine_dict:
word = combine_dict[word]
final_sentence += word
else:
final_sentence += word
# print(final_sentence)
return final_sentencload_jieba()
# 槽值替换
for i in range(len(questions)):
questions[i] = synonym_sub(questions[i])分词,统计各个词词频,按照词频从大到小对词语排序,生成词语列表
词语列表除去停用词表中的词语;除去长度为1的词;加上对分类有用的长度为1的词,如 ‘吃’,‘药’,‘治’等
将词语列表(也即特征列表)保存在vocab.txt
# 分词
words = jieba.cut("\n".join(questions), cut_all=False)
print(words)
# 统计词频
word_count = {}
stopwords = [line.strip() for line in open("data/stopwords.txt", 'r', encoding="utf-8").readlines()]
for word in words:
if word not in stopwords:
if len(word) == 1:
continue
word_count[word] = word_count.get(word, 0) + 1
items = list(word_count.items())
items.sort(key=lambda x: x[1], reverse=True)
# vocab中添加的单字
single = ['吃', '喝', '药', '能', '治', '啥', '病', '查', '测', '检', '验', '酒', '奶', '糖']
with open('data/vocab.txt', 'w', encoding='utf-8') as f:
for item in items:
f.write(item[0]+'\n')
for word in single:
f.write(word + '\n')停用词表构造:人工筛选出vocab.txt中对分类无意义的词,加入到stopwords.txt中。再重复运行extract.py
main.py: 模型训练,测试,预测
导入模块,预设路径
from utils import *
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
import numpy as np
from termcolor import colored
import matplotlib.pyplot as plt
import seaborn as sns
import pickle
import pandas as pd
data_dir = 'data'加载train.txt, test.txt, class.txt
# 加载训练集 测试集 类别
q_train, y_train = open_data(os.path.join(data_dir,'train.txt'))
q_test, y_test = open_data(os.path.join(data_dir, 'test.txt'))
classes = [line.strip() for line in open(os.path.join(data_dir, 'class.txt'), 'r', encoding="utf-8").readlines()]模型训练:训练集问句-->槽值替换-->分词-->根据vocab.txt 生成特征向量 --> (特征向量,标签) 作为模型输入 --> 训练模型
def qes2wb(questions):
# 加载vocab
data_folder = 'data/'
vocab = [line.strip() for line in open(data_folder+'vocab.txt', 'r', encoding="utf-8").readlines()]
# 问句,槽值替换后, 分词,转换为词袋向量
vecs = []
load_jieba()
for question in questions:
sen = synonym_sub(question)
# print(sen)
words = list(jieba.cut(sen, cut_all=False))
# print('/'.join(words))
vec = [words.count(v) for v in vocab]
vecs.append(vec)
return vecs# 转为词袋模型
x_train = qes2wb(q_train)
# 建模
model = MultinomialNB()
model.fit(x_train, y_train)
# 保存模型
with open('MultinomialNB.pkl', 'wb') as f:
pickle.dump(model, f)模型测试:测试集问句-->槽值替换-->分词-->根据vocab.txt 生成特征向量 --> 模型预测生成预测标签
def qes2wb(questions):
# 加载vocab
data_folder = 'data/'
vocab = [line.strip() for line in open(data_folder+'vocab.txt', 'r', encoding="utf-8").readlines()]
# 问句,槽值替换后, 分词,转换为词袋向量
vecs = []
load_jieba()
for question in questions:
sen = synonym_sub(question)
# print(sen)
words = list(jieba.cut(sen, cut_all=False))
# print('/'.join(words))
vec = [words.count(v) for v in vocab]
vecs.append(vec)
return vecs# 转为词袋模型
x_test = qes2wb(q_test)
# 测试
p_test = model.predict(x_test)
y_test = np.array(y_test)
p_test = np.array(p_test)
模型评价:预测标签与真实标签比对,输出评价指标,分析 bad cases, 可视化混淆矩阵
# 输出模型测试结果
print(metrics.classification_report(y_test, p_test, target_names=classes))
# for i, c in enumerate(classes):
# print("%d: %s" % (i, c), end='\t')
# print('\n')
# print(metrics.classification_report(y_test, p_test))
# 输出错误
errors = []
for i in range(len(y_test)):
if y_test[i] != p_test[i]:
errors.append((y_test[i], q_test[i], p_test[i]))
print('---Bad Cases---')
for y, q, p in sorted(errors):
print('Truth: %-20s Query: %-30s Predict: %-20s' % (classes[int(y)], q, classes[int(p)]))
# 混淆矩阵
# 用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
# 计算混淆矩阵
confusion = metrics.confusion_matrix(y_test, p_test)
plt.clf()
plt.title('分类混淆矩阵')
sns.heatmap(confusion, square=True, annot=True, fmt='d', cbar=False,
xticklabels=classes,
yticklabels=classes,
linewidths=0.1, cmap='YlGnBu_r')
plt.ylabel('实际')
plt.xlabel('预测')
plt.xticks(rotation=-13)
plt.savefig('分类混淆矩阵.png', dpi=100)模型评价结果:
precision recall f1-score support
治疗 0.91 1.00 0.95 10
检查项目 0.91 1.00 0.95 10
饮食 0.90 0.90 0.90 10
用药治疗 1.00 1.00 1.00 10
并发症 1.00 1.00 1.00 10
用药情况 0.77 1.00 0.87 10
遗传与传染 1.00 1.00 1.00 10
病因 0.83 1.00 0.91 5
其它 0.89 0.80 0.84 10
症状 1.00 0.50 0.67 10
保健与护理 1.00 1.00 1.00 10
accuracy 0.92 105
macro avg 0.93 0.93 0.92 105
weighted avg 0.93 0.92 0.92 105---Bad Cases---
Truth Query Predict
保健与护理 糖尿病如何降低血糖 遗传与传染
病因 糖尿病是如何造成的 保健与护理
其它 压力大会引起糖尿病吗 病因
其它 糖尿病并发症咋办 并发症
其它 糖尿病并发症应注意什么 并发症
其它 糖尿病并发症怎么治 治疗
其它 糖尿病并发症的病因 并发症 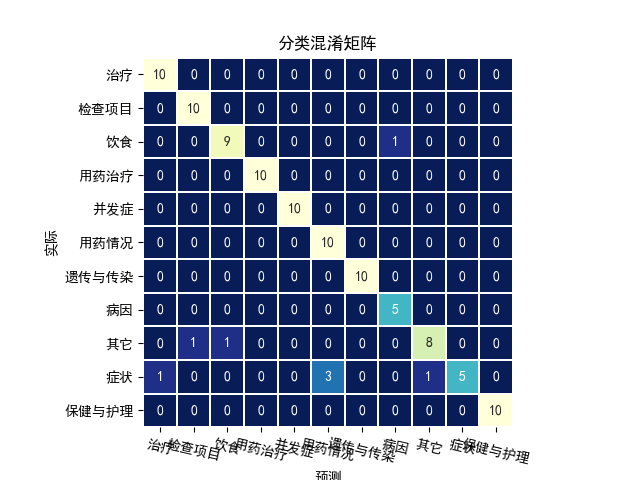
单句预测:输入问句-->提取特征(槽值替换 --> 分词 --> 转换为向量)--> 模型预测 --> 输出预测的意图
def qes2wb(questions):
# 加载vocab
data_folder = 'data/'
vocab = [line.strip() for line in open(data_folder+'vocab.txt', 'r', encoding="utf-8").readlines()]
# 问句,槽值替换后, 分词,转换为词袋向量
vecs = []
load_jieba()
for question in questions:
sen = synonym_sub(question)
# print(sen)
words = list(jieba.cut(sen, cut_all=False))
# print('/'.join(words))
vec = [words.count(v) for v in vocab]
vecs.append(vec)
return vecs# 单句预测
while True:
query = input(colored('请咨询:', 'green'))
x_query = qes2wb([query])
# print(x_query)
p_query = model.predict(x_query)
# print(p_query)
print('意图: ' + classes[int(p_query[0])])预测结果:
请咨询:糖尿病可以吃草莓吗
意图: 饮食
请咨询:胰岛素的副作用
意图: 用药情况
请咨询:糖尿病吃什么药
意图: 用药治疗
请咨询:糖尿病高血糖怎么治
意图: 治疗predict.py: 批量预测
导入模块,预设路径
from utils import *
import pandas as pd
import pickle
import os
classes_dir = 'data'
data_dir = 'predict_data'加载class.txt(类别),question.csv(问句列表),模型
批量预测:问句 -->提取特征(槽值替换 --> 分词 --> 转换为向量)--> 模型预测
保存结果到result.csv
# 加载类别和问句
classes = [line.strip() for line in open(os.path.join(classes_dir, 'class.txt'), 'r', encoding="utf-8").readlines()]
sentence_csv = pd.read_csv(os.path.join(data_dir, 'question.csv'), sep='\t', names=['title'])
sentences = sentence_csv['title'].tolist()
# 加载模型
if os.path.exists('MultinomialNB.pkl'):
with open('MultinomialNB.pkl', 'rb') as f:
model = pickle.load(f)
else:
raise Exception("Please run main.py first!")
# 预测
x_query = qes2wb(sentences)
p_query = model.predict(x_query)
results = [classes[int(p)] for p in p_query]
# 保存结果
dataframe = pd.DataFrame({'title': sentences, 'classes': results})
dataframe.to_csv(os.path.join(data_dir, 'result.csv'), index=False, sep=',')result.csv
| title | classes |
|---|---|
| 糖尿病可以吃草莓吗 | 饮食 |
| 胰岛素的副作用 | 用药情况 |
| 糖尿病吃什么药 | 用药治疗 |
| 糖尿病高血糖怎么治 | 治疗 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号