Mysql索引优化
Mysql索引优化
准备数据
-
建立一个测试用表
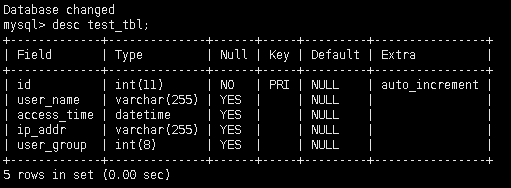
-
往表中插入10w条随机数据的存储过程
CREATE DEFINER=`root`@`%` PROCEDURE `insert_tbl`(in max_num int(10))
BEGIN
declare i int default 0;
set autocommit=0;
repeat
set i=i+1;
insert into test_tbl (id,user_name,access_time,ip_addr,user_group)values(null,rand_string(rand()*7+3),rand_datetime(2015,5),rand_ip(),rand_num());
until i = max_num
end repeat;
commit;
END
1)随机字符串函数(param表示生成字符串的长度)
CREATE DEFINER=`root`@`%` FUNCTION `rand_string`(n int) RETURNS varchar(255) CHARSET latin1
BEGIN
declare chars_str varchar(52) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str=concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i=i+1;
end while;
return return_str;
END
2)随机日期函数(param1表示最小,param2表示年份波动)
CREATE DEFINER=`root`@`%` FUNCTION `rand_datetime`(n year, num int) RETURNS varchar(255) CHARSET latin1
BEGIN
declare aDatetime varchar(255) default '';
set aDatetime=concat(concat(n+floor((rand()*num)),'-',
lpad(floor(2 + (rand() * 11)),2,0),'-',
lpad(floor(3 + (rand() * 25)),2,0)), #最多到每月27号
' ',
concat(lpad(floor(0 + (rand() * 23)),2,0),':',
lpad(floor(0 + (rand() * 60)),2,0),':',
lpad(floor(0 + (rand() * 60)),2,0)));
return aDatetime;
END
3)随机ip函数
CREATE DEFINER=`root`@`%` FUNCTION `rand_ip`() RETURNS varchar(255) CHARSET latin1
BEGIN
declare ip varchar(255) default '';
set ip = concat(FLOOR(100 + RAND() * 26), '.',
FLOOR(0 + RAND() * 256), '.',
FLOOR(0 + RAND() * 256), '.',
FLOOR(0 + RAND() * 256));
return ip;
END
4)随机数字函数(已指定范围在0-127,可以修改为传参指定)
CREATE DEFINER=`root`@`%` FUNCTION `rand_num`() RETURNS int(8)
BEGIN
declare i int default 0;
set i = floor(0+rand()*128);
return i;
END
索引类型
查看表的索引

增加索引
-- primary key每个表只允许存在一个,而且不重复不为空
alter table test_tbl add unique unique_index(ip_addr) #唯一索引,不许重复,允许为空
alter table test_tbl add index normal_index(user_name) #普通索引,没有限制
alter table test_tbl add index union_index(user_name,access_time,user_group) #组合索引,包含多列避免回表
删除某个索引
drop index index_name on test_tbl;
Explain执行计划
explain列的含义
| 列项 | 含义 |
|---|---|
| id | 每个select关键字对应一个唯一id |
| select_type | 查询类型 |
| partitions | 匹配的分区信息 |
| type | 单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际使用的索引 |
| key_len | 实际使用的索引长度 |
| ref | 索引的哪一列被使用 |
| rows | 预估需要读取的记录数目 |
| filtered | 经过滤剩余的记录条数百分比 |
| extra | 额外信息 |
说明:
| select_type字段 | 含义 |
|---|---|
| SIMPLE | 简单查询,不包含子查询或union查询 |
| PRIMARY | 查询中包含复杂的子部份,最外层标记为主查询 |
| SUBQUERY | 在select或where中包含子查询 |
| DERIVED | 在from中的子查询标记为衍生,查询结果存放在临时表中 |
| UNION | select出现在union之后 |
| UNION RESULT | 从union结果表中获取查询结果 |
| type字段 | 含义 |
|---|---|
| null | 优化阶段分解查询语句,执行阶段不访问表或索引 |
| system | 表中只有一条记录(等同于系统表) |
| const | 通过索引一次命中(如where后跟主键条件) |
| eq_ref | 唯一性索引扫描 |
| ref | 非唯一性索引扫描,可能会找到符合条件的索引行 |
| ref_or_null | 类似ref但可以搜索null |
| index_merge | 索引合并 |
| range | 只检索给定范围的行(between,><,in) |
| index | 遍历索引树 |
| all | 从硬盘中遍历全表已找到匹配行 |
extra字段:
| Extra字段 | 含义 |
|---|---|
| Using filesort | 对数据作外部排序,而不是按表内索引顺序读取 |
| Using temporary | 使用临时表保存中间结果(排序,分组) |
| Using index | 使用覆盖索引(同时有using where表示索引不是读取数据而是查找键值) |
| Using where | 条件查询 |
| Using join buffer | 使用连接缓存 |
| impossible where | where子句总为false |
| distinct | 一旦找到匹配行就不再搜索 |
| select tables optimized away | 没有遍历就返回数据 |
索引优化原则
- 不以通配符开头
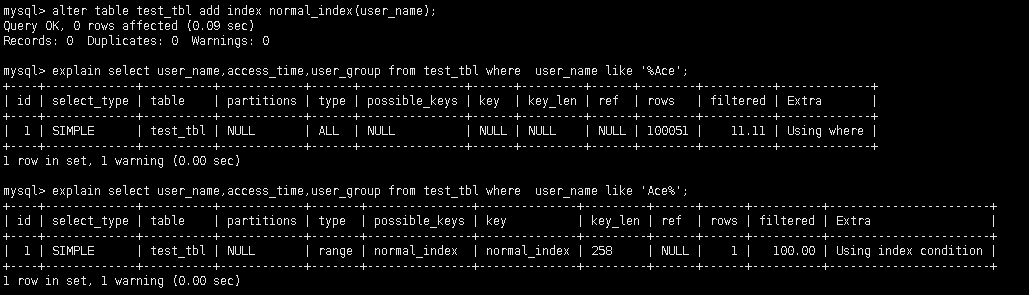
- 数据无隐式转化
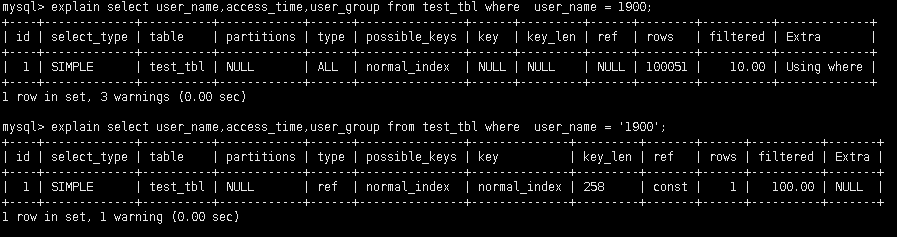
所以字符串要用引号
- 索引列上作计算,函数,类型转化等将使索引失效

-
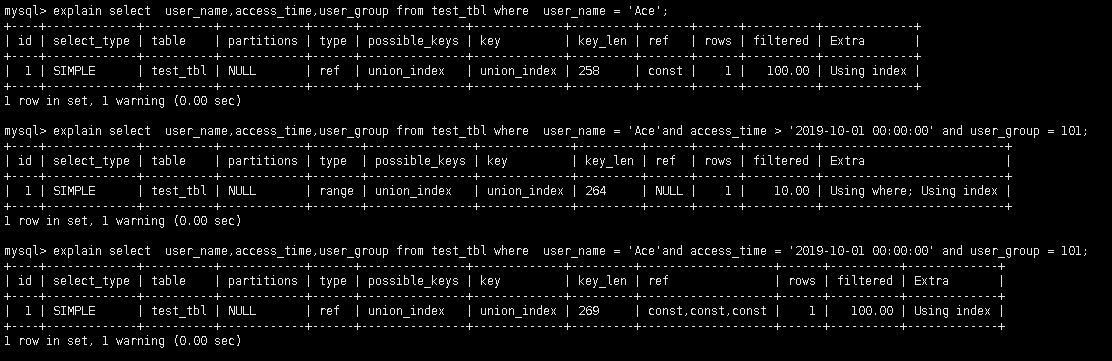
覆盖索引
select值取出需要的列,尽量避免select *。另外可将查询列加入形成组合索引避免回表
-
最佳左前缀法则
where条件从索引的最左前列开始且不跳过索引列使用,下列情况索引失效

-
范围列右边的索引列失效
关注key_len长度
保持学习,保持思考,保持对世界的好奇心!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号