leetcoed 212. 单词搜索 II(dfs回溯 字典树)
链接:https://leetcode-cn.com/problems/word-search-ii/
题目
给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
用例
示例 1:
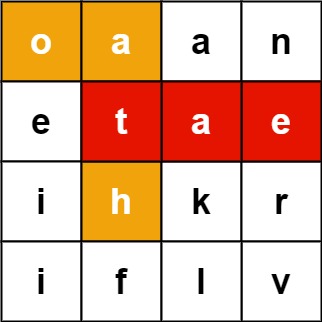
输入:board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"]
输出:["eat","oath"]
示例 2:
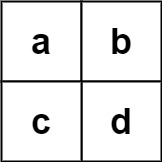
输入:board = [["a","b"],["c","d"]], words = ["abcb"]
输出:[]
提示:
m == board.length
n == board[i].length
1 <= m, n <= 12
board[i][j] 是一个小写英文字母
1 <= words.length <= 3 * 104
1 <= words[i].length <= 10
words[i] 由小写英文字母组成
思路
就是个暴力搜索题,但是直接对已有单词集合遍历会超时,需要把单词集合转换为字典树,不仅可以减少前缀相同单词的检索,也方便查询首字符相同的单词
我一开始写的将首字母相同的单词存hash表,然后进行遍历
class Solution {
public:
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
unordered_map<char,vector<string>>wordDic;
for(auto &n: words)
{
wordDic[n[0]].push_back(n);
}
vector<string>ans;
for(int i=0;i<board.size();++i)
{
for(int j=0;j<board[0].size();++j)
{
if(wordDic[board[i][j]].size()>0)
{
for(int p =0;p<wordDic[board[i][j]].size();++p)
{
if(wordDic[board[i][j]][p]==" ")
continue;
if(wordDic[board[i][j]][p].size()==1)
{
ans.push_back(wordDic[board[i][j]][p]);
wordDic[board[i][j]][p]=" ";
continue;
}
if(backtracking(board,wordDic[board[i][j]][p],i,j,0))
{
ans.push_back(wordDic[board[i][j]][p]);
wordDic[board[i][j]][p]=" ";
}
}
}
}
}
return ans;
}
private:
bool backtracking(vector<vector<char>>&board,string &waitfind,int x,int y,int index)
{
if(waitfind[index]!=board[x][y])
return false;
if(index ==waitfind.size()-1)
return true;
char mem=board[x][y];
board[x][y]=0;
if(x>0)
{
if(board[x-1][y]==waitfind[index+1])
{ if(backtracking(board,waitfind,x-1,y,index+1))
{
board[x][y]=mem;
return true;
}
}
}
if(x< board.size()-1)
{
if(board[x+1][y]==waitfind[index+1])
{ if(backtracking(board,waitfind,x+1,y,index+1))
{
board[x][y]=mem;
return true;
}
}
}
if(y>0)
{
if(board[x][y-1]==waitfind[index+1])
{ if(backtracking(board,waitfind,x,y-1,index+1))
{
board[x][y]=mem;
return true;
}
}
}
if(y< board[0].size()-1)
{
if(board[x][y+1]==waitfind[index+1])
{ if(backtracking(board,waitfind,x,y+1,index+1))
{
board[x][y]=mem;
return true;
}
}
}
board[x][y]=mem;
return false;
}
};
超时了
使用Trie字典树实现
struct TrieNode {
string word;
unordered_map<char,TrieNode *> children;
TrieNode() {
this->word = "";
}
};
void insertTrie(TrieNode * root,const string & word) {
TrieNode * node = root;
for (auto c : word){
if (!node->children.count(c)) {
node->children[c] = new TrieNode();
}
node = node->children[c];
}
node->word = word;
}
class Solution {
public:
int dirs[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
bool dfs(vector<vector<char>>& board, int x, int y, TrieNode * root, set<string> & res) {
char ch = board[x][y];
if (!root->children.count(ch)) {
return false;
}
root = root->children[ch];
if (root->word.size() > 0) {
res.insert(root->word);
}
board[x][y] = '#';
for (int i = 0; i < 4; ++i) {
int nx = x + dirs[i][0];
int ny = y + dirs[i][1];
if (nx >= 0 && nx < board.size() && ny >= 0 && ny < board[0].size()) {
if (board[nx][ny] != '#') {
dfs(board, nx, ny, root,res);
}
}
}
board[x][y] = ch;
return true;
}
vector<string> findWords(vector<vector<char>> & board, vector<string> & words) {
TrieNode * root = new TrieNode();
set<string> res;
vector<string> ans;
for (auto & word: words){
insertTrie(root,word);
}
for (int i = 0; i < board.size(); ++i) {
for (int j = 0; j < board[0].size(); ++j) {
dfs(board, i, j, root, res);
}
}
for (auto & word: res) {
ans.emplace_back(word);
}
return ans;
}
};
相关知识(字典树 前缀树)
链接:https://leetcode-cn.com/problems/implement-trie-prefix-tree/
字典树实现
class Trie {
private:
vector<Trie*>childern;
bool isEnd;
Trie* searchPrefix(string prefix)
{
Trie* node =this;
for(auto ch : prefix)
{
ch-='a';
if(node->childern[ch]==nullptr)
return nullptr;
node=node->childern[ch];
}
return node;
}
public:
/** Initialize your data structure here. */
Trie() {
childern=vector<Trie*>(26);
isEnd=false;
}
/** Inserts a word into the trie. */
void insert(string word) {
Trie* node=this;
for(auto ch : word)
{
ch-='a';
if(node->childern[ch]==nullptr)
{
node->childern[ch] =new Trie();
}
node=node->childern[ch];
}
node->isEnd=true;
}
/** Returns if the word is in the trie. */
bool search(string word) {
Trie *node=this->searchPrefix(word);
return node != nullptr &&node->isEnd;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix) {
return this->searchPrefix(prefix)!=nullptr;
}
};
/**
* Your Trie object will be instantiated and called as such:
* Trie* obj = new Trie();
* obj->insert(word);
* bool param_2 = obj->search(word);
* bool param_3 = obj->startsWith(prefix);
*/
复杂度分析
时间复杂度:初始化为 O(1)O(1),其余操作为 O(|S|)O(∣S∣),其中 |S|∣S∣ 是每次插入或查询的字符串的长度。
空间复杂度:O(|T|\cdot\Sigma)O(∣T∣⋅Σ),其中 |T|∣T∣ 为所有插入字符串的长度之和,\SigmaΣ 为字符集的大小,本题 \Sigma=26Σ=26。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号