

MVCC 实现原理?
MVCC 实现原理?
MVCC(Multiversion concurrency control) 就是同一份数据保留多版本的一种方式,进而实现并发控制。在查询的时候,通过read view和版本链找到对应版本的数据。
作用:提升并发性能。对于高并发场景,MVCC比行级锁开销更小。
MVCC 实现原理如下:
MVCC 的实现依赖于版本链,版本链是通过表的三个隐藏字段实现。
DB_TRX_ID:当前事务id,通过事务id的大小判断事务的时间顺序。DB_ROLL_PTR:回滚指针,指向当前行记录的上一个版本,通过这个指针将数据的多个版本连接在一起构成undo log版本链。DB_ROW_ID:主键,如果数据表没有主键,InnoDB会自动生成主键。
每条表记录大概是这样的:

使用事务更新行记录的时候,就会生成版本链,执行过程如下:
- 用排他锁锁住该行;
- 将该行原本的值拷贝到
undo log,作为旧版本用于回滚; - 修改当前行的值,生成一个新版本,更新事务id,使回滚指针指向旧版本的记录,这样就形成一条版本链。
下面举个例子方便大家理解。
1、初始数据如下,其中DB_ROW_ID和DB_ROLL_PTR为空。

2、事务A对该行数据做了修改,将age修改为12,效果如下:

3、之后事务B也对该行记录做了修改,将age修改为8,效果如下:
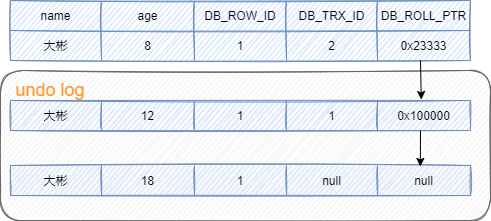
4、此时undo log有两行记录,并且通过回滚指针连在一起。
接下来了解下read view的概念。
read view可以理解成将数据在每个时刻的状态拍成“照片”记录下来。在获取某时刻t的数据时,到t时间点拍的“照片”上取数据。
在read view内部维护一个活跃事务链表,表示生成read view的时候还在活跃的事务。这个链表包含在创建read view之前还未提交的事务,不包含创建read view之后提交的事务。
不同隔离级别创建read view的时机不同。
-
read committed:每次执行select都会创建新的read_view,保证能读取到其他事务已经提交的修改。
-
repeatable read:在一个事务范围内,第一次select时更新这个read_view,以后不会再更新,后续所有的select都是复用之前的read_view。这样可以保证事务范围内每次读取的内容都一样,即可重复读。
read view的记录筛选方式
前提:DATA_TRX_ID 表示每个数据行的最新的事务ID;up_limit_id表示当前快照中的最先开始的事务;low_limit_id表示当前快照中的最慢开始的事务,即最后一个事务。

- 如果
DATA_TRX_ID<up_limit_id:说明在创建read view时,修改该数据行的事务已提交,该版本的记录可被当前事务读取到。 - 如果
DATA_TRX_ID>=low_limit_id:说明当前版本的记录的事务是在创建read view之后生成的,该版本的数据行不可以被当前事务访问。此时需要通过版本链找到上一个版本,然后重新判断该版本的记录对当前事务的可见性。 - 如果
up_limit_id<=DATA_TRX_ID<low_limit_i:- 需要在活跃事务链表中查找是否存在ID为
DATA_TRX_ID的值的事务。 - 如果存在,因为在活跃事务链表中的事务是未提交的,所以该记录是不可见的。此时需要通过版本链找到上一个版本,然后重新判断该版本的可见性。
- 如果不存在,说明事务trx_id 已经提交了,这行记录是可见的。
- 需要在活跃事务链表中查找是否存在ID为
总结:InnoDB 的MVCC是通过 read view 和版本链实现的,版本链保存有历史版本记录,通过read view 判断当前版本的数据是否可见,如果不可见,再从版本链中找到上一个版本,继续进行判断,直到找到一个可见的版本。
