


SQL Server数据存储的形式
- 预读:用估计信息,去硬盘读取数据到缓存。预读100次,也就是估计将要从硬盘中读取了100页数据到缓存。
- 物理读:查询计划生成好以后,如果缓存缺少所需要的数据,让缓存再次去读硬盘。物理读10页,从硬盘中读取10页数据到缓存。
- 逻辑读:从缓存中取出所有数据。逻辑读100次,也就是从缓存里取到100页数据。
SQL Server存储的最小单位是页,每一页大小为8K,SQL Server对于页的读取是原子性的,要么读完一页,要么完全不读。即使是仅仅要获得一条数据,也要读完一页。而页之间的数据组织结构为B树结构。所以SQL Server对于逻辑读、预读、物理读的单位是页。
先来看一个查询:
DBCC DROPCLEANBUFFERS --清空缓存 SET STATISTICS IO ON --开启IO统计 SELECT * FROM Person --查询语句
显示消息如下:
(147517 行受影响) 表 'Person'。扫描计数 1,逻辑读取 2237 次,物理读取 6 次,预读 2226 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响)
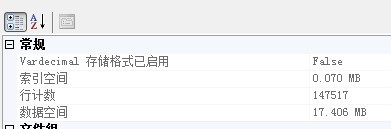
上表的大小是17.406M。
每一页存储的数据是:8K=8192字节-96字节(页头)-36字节(行偏移)= 8060字节。
17.406*1024*1024 / 8060 ≈ 2 264
另外表中还有一些非数据占用的空间,因此上式的结果约等于逻辑读次数。
基本上,逻辑读、物理读、预读都等于是扫描了多少个页。
从执行顺序上理解各种读
SQL Server的查询从理解各种读的步骤来看,可以理解为以下图:
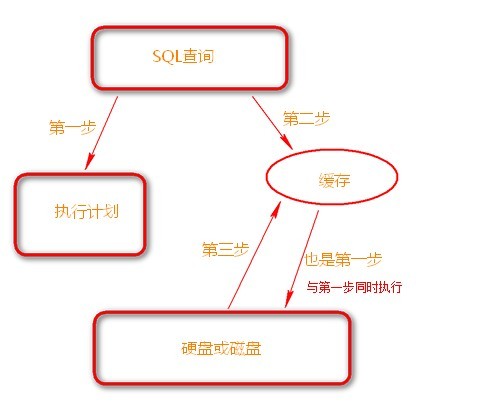 (图是CareySon大哥的)
(图是CareySon大哥的)
通过上图来讲解各种读:
当SQL Server执行一个查询语句时,SQL Serer会开始第一步,生成查询计划,同时用估计的数据去磁盘读取数据(预读),这两个第一步是并行的。SQL Server通过这种方式来提高查询性能。
查询计划生成好了以后去缓存读取数据,当发现缓存缺少所需要的数据后让缓存再次去读硬盘(物理读),然后从缓存中取出所有数据(逻辑读)。
估计的页数可以通过DMV看到
SELECT page_count FROM sys.dm_db_index_physical_stats (DB_ID('TestDataCenter'),OBJECT_ID('Person'),NULL,NULL,'sampled')
显示结果如下:

SQL Server就是根据这个东西进行预读。
如果此时我们再执行上面的查询语句:
SELECT * FROM Person --查询语句
看到消息如下:
(147517 行受影响) 表 'Person'。扫描计数 1,逻辑读取 2237 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响)
为什么这次全部都是逻辑读呢。因为刚才读过一次,数据全部都已经在缓存当中了,只需要从缓存中读就可以了,不需要再读取硬盘。
本文学习自:http://www.cnblogs.com/CareySon/archive/2011/12/23/2299127.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!