

[MySQL] 《数据库系统概念》阅读笔记
第二章 关系数据库
在关系模型(relational model)中,关系用来指代表(table),元组用来指代行(row),表中的一行代表了一组值之间的一种联系,行中的每一列(column)代表一个属性,属性允许的取值集合称为该属性的域(domain),如果域中的元素是不可再分的,则域是原子的。
但是否可再分取决于我们怎么使用域中的元素,比如一个电话号码,看起来它应该是具有原子性的,但如果我们把它再细化拆分出国家编号、地区编号,那么它就不是原子的了。
数据库模式(schema)意思是数据库的逻辑设计,如关系数据库中关系模式就是表的定义,数据库实例(instance)就是特定时刻数据库中数据的一个快照。
为了区分关系中不同的元组引入了码(key)的概念,超码(super key,也叫超键)是一个或多个属性的集合,可以唯一地表示一个元组,一个超码的任意超集也是超码,最小的超码集合称为候选码(candidate key),从这个集合中去掉任何一个元素都不能唯一地标识一个元组。
一个关系中可能有几个不同的属性集合都可以做候选码,如授课时间+授课地点可以唯一地标识一门课(毕竟同一时间同一地点不可能同时进行两门不同的课嘛),授课时间+课程编号+授课教师也可以唯一地标识一门课(课程编号唯一,课程每年都会开并且一个学期有若干个教师都会开设这个课程),往候选码里加入任意其他属性,候选码就退化成了超码,同样去掉任何一个属性它都不能唯一标识一个元组,也不是候选码了。
被数据库设计者选中用以区分元组的候选码称为主码(primary key)。一个关系模式 R1 可能在它的属性中包含了另一个关系模式 R2 的主码,这个属性在 R1 上乘坐参照 R2 的外码(foreign key),R1 称作该外码依赖的参照关系,R2 称作外码的被参照关系。外码需要遵从参照完整性约束,它要求在参照关系中任意元组的特定属性上的取值必然等于被参照关系中某个元组在特定关系中的取值。
比如教师表与课程表,多个教师可能同时开设了同一个课程,所以无法建立课程-教师的外码约束,但是反过来可以建立教师-课程的外码约束,因为教师表里的课程号一定只能对应一个课程表里的行。
关系查询语言(如 SQL)是用来从数据库中请求数据信息的语言,可以分为过程化的和非过程化的。在过程化的语言中用户指导系统对数据库进行一系列的操作以计算出所需要的结果,而非过程化的语言只需要描述所需要的信息,不用给出获取的方式(SQL 就是非过程化的语言)。所有的关系查询语言都提供了一组运算,它们可以施加在单个或者一对关系上,运算的结果总是单个关系。关系代数定义了一组关系运算,对应于加、减、乘、除。数学上的代数运算以一个或多个数字作为输入,返回一个数字作为结果,类似的,关系代数运算以一个或两个关系作为输入,返回一个关系作为输出。关系代数运算包括选择(σ)、投影(π)、自然连接(⋈)、笛卡尔积(×)、并(∪)。
第三章 SQL
SQL 是目前主流的数据库查询语言之一,它由以下几个部分组成:
- 数据定义语言(DDL, Data Define Language):它提供定义/修改关系模式、删除关系的命令。
- 数据操纵语言(DML, Data Manipulation Language):提供对数据库中元组进行增删改查的能力。
- 完整性:DDL 包括定义完整性约束的命令,保存在数据库中的数据必须满足所定义的完整性约束
- 视图(View)定义
- 事务(Transation)控制
- 嵌入式 SLQ 和动态 SQL (定义 SQL 语句如何嵌入到 Java 等通用编程语言中)
- 授权(DDL 包括定义对关系和试图的访问权限的命令)
本章主要介绍 DDL 和 DML
DDL
DDL 可以定义关系模式、属性取值范围、完整性约束、关系所维护的索引集合、安全性与权限、关系在磁盘上的物理存储结构。
SQL 支持字符串、整数、浮点数这样的基本类型,关于字符串,分为 char(定长)和 varchar(可变长)这两种,若属性 A 的类型为 char(10),插入一条数据,其中 A="a",那么该字符串后面会被追加9个空格使其达到所设定的10个字符串的长度。当往 char A 和 varchar B 中存入相同的字符串, A==B 的结果是否为真取决于数据库系统。
-- DDL 语句的通用形式
create table r(
A1 D1,
A2 D2,
...
An Dn,
<Integrity Constraints>,
<Integrity Constraints>;
)
-- 举个例子
create table section(
course_id varchar(8),
sec_id varchar(10),
semester varchar(4),
year numeric(4,0),
building varchar(16),
room_number varchar(10),
time_slot_id varchar(10),
primary key(course_id, sec_id, semester, year),
foreign key(course_id) reference course);
)
上面的例子里最后一行定义了外键,被参照表为 course 表,建立了这个约束之后,如果新插入的 section 元组在 course_id 上的取值没有出现在 course 表中,则这条插入会被阻止,这也就是 DDL 的完整性约束。
关系模式(也就是表)定义好了之后我们可能因为各种各样的原因需要修改这个模式,SQL 也为我们提供了修改关系的语句:
-- 给关系 r 新增一个属性 A, 取值为 D
alter table r add A D;
-- 删除关系 r 中的属性 A
alter table r drop A;
-- 删除关系 r,删除了所有数据以及 r 这个关系模式
drop table r;
DML
对数据的操作主要包括查询和修改。
查询
SQL 的查询语句基本结构由 select、from、where 着三个子句构成,在 from 子句中指定关系,这些关系进行 where 和 select 子句中指定的运算,最后产生一个新的关系作为结果。
- select子句:选择需要输出的属性,可以在末尾加入 distinct 关键字来去重,加 all 关键字显式指明不去重。可以使用加减乘除运算符对属性进行计算,如
select salary * 1.1 from teacher
- where 子句:在 where 子句中可以使用 and、or 和 not 着3个逻辑连接词,逻辑连接词的运算对象可以是包含>、>=、<、<=、=、<>的表达式,如:
where name = "name1" and salary > 7000
- from 子句:在 from 子句里指定要操作的关系,SQL 支持多关系查询,如:
select name, instructor, dept_name, building
from instructor, department
where instructor.dept_name = department.dept_name
上述查询涉及到 instructor 和 department 两个关系,select 子句中的前三个属性来自于 instructor, 最后一个 building 属性来自 department 表。
for each 元组t1 in 关系r1
for each 元组t2 in 关系r2
...
for each 元组tn in 关系rn
把t1,t2, ..., tn 连接成单个元组t,把t加入到结果关系中
可以通过上面这段伪代码所表述的迭代关系来理解多关系查询,多关系查询是一个产生笛卡尔积(也就是上面伪代码所描述的过程)、使用 where 子句中的谓词来过滤笛卡尔积、输出 select 子句中所指定的属性的过程。
笛卡尔积将第一个关系中的每个元组都与第二个关系中的所有元组进行连接,但是有些连接在语义上是毫无意义的,所以 SQL 还支持另外一种连接操作,即自然连接。自然连接只考虑那些在两个关系模式的公共属性上取值相同的元组对。
-- 使用 using 子句来指定要匹配的属性
select name, title
from (instructor natural join teaches) join course using (course_id);
sql 中有 自然连接、内连接、外连接这几种连接,其中外连接又分为左外连接、右外连接和全外连接
自然连接(natural join):自然连接是一种特殊的等值连接,他要求两个关系表中进行比较的必须是相同的属性列,无须添加连接条件,并且在结果中消除重复的属性列。
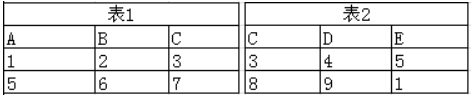
内连接(inner join):内连接基本与自然连接相同,不同之处在于自然连接要求是同名属性列的比较,而内连接则不要求两属性列同名,可以用using或on来指定某两列字段相同的连接条件。
sql语句:Select …… from 表1 inner join 表 2 on 表1.A=表2.E
结果:
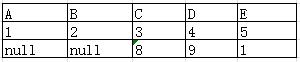
左外连接(left outer join):左外连接是在两表进行自然连接,保留左表全部数据,若右表无对应数据,则在对应的列上填null。
sql语句:Select …… from 表1 left outer join 表2 on 表1.C=表2.C
结果:
右外连接(right outer join):与左外连接相似,保留右表全部数据,左边无对应则填 null。
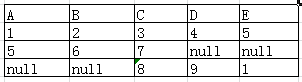
全外连接(full join):两表进行自然连接,保留全部数据
Select …… from 表1 full join 表2 on 表1.C=表2.C
结果:



sql 支持的几种附加运算
- 更名运算:分为属性重命名和关系重命名两种
select old_name as new_name from old_relation as new relation ...
- 字符串运算: 在字符串上可以使用 like 操作符实现模式匹配,% 表示匹配任意子串,_ 表示匹配任意一个字符,如 a% 表示匹配以a开头的任意长度和内容的字符串,%a% 表示匹配任意地方含有 a 字符的字符串,_ 匹配长度为1的字符串。
-- 匹配所有以 ab%cd 开头的字符串,escape 关键字可以用来定义转义字符,这样模式里就可以包含 % 和 _了
... where name like 'ab\%cd%' escape '\';
- 指定元组的显示的排列顺序: order by 关键字默认使用升序,使用 desc 显式指明降序,asc 升序
-- 将结果按照 salary 降序排列,若有相同的 salary 则把这几个元组按照 name 升序排列
select *
from instructor
order by salary desc, name asc;
- where子句谓词:在 where 子句中可以使用 between/not between 来代替 <= and >=,还可以进行元组运算,如(a1, a2) <= (b1,b2),在 a1 <= b1 并且 a2<=b2 时为真
... where (instructor.ID, dept_name) = (teacher.ID, "Biology");
- 集合运算:SQL 中 union、intersect、except 对应数学中的∩(交)、∪(并)、-(差)运算
-- 选出所有在2009年秋天和2010年春天都开了课的课程id
-- union 默认去重,需要保留重复元组可以使用 union all
(select course_id
from section
where semester = "fall" and year = 2009)
union
(select course_id
from section
where semester = "spring" and year = 2010)
- 空值:有 null 参与的算术表达式(+-×÷)结果为 null,而有 null 的比较运算结果为 unknown, unknown 可视为 true 和 false 的中间态,
false and unknown == false, false or unknown == unknown;
如果where 子句谓词对一个元组计算出 false 或 unknown 则该元组不会被加到结果中 - 聚集函数:聚集函数以一个集合为输入,返回单个值,SQL 提供了5个聚集函数 avg、max、min、sum、count。
-- 该查询的结果时一个具有单属性(avg_salary)的关系,其中只包含一个元组
select avg(salary) as avg_salary
from instructor
where dept_name = "comp.sci";
-- 使用 distinct 来去重,count 函数还可以用来计算一个关系中的元组数: select count(*)...
select count(distinct ID)
from teachers
where semester = "spring" and year = 2010;
-- 分组聚集,group by 子句用于结合聚集函数,根据一个列或多个列来对结果进行分组
-- having 子句可以对 group by 产生的分组进行筛选
-- 任何出现在 having 中但没有被聚集的属性必须出现在 group by 中
select dept_name avg(salary) as svg_salary
from instructor
group by dept_name;
having avg(salary) > 42000;
- 嵌套子查询:子查询时嵌套在一个查询中的 select-from-where 表达式,可以嵌入在 where 或 from 子句中,where 子句中的子查询可以通过以下几个连接词来嵌入:
- in/not in:
-- 与 5 聚集函数 中的例子语义一样,查询同时在2009年秋和2010年春都开课了的课程id select distinct course_id from section where semester = "fall" and year = 2009 and course_id in (select course_id from course where semester = "spring" and year = 2010); -- 查询所有不是 Amy 和 Tom 的名字 select distinct name from instructor where name not in ("Amy", "Tom");- some/all:用于与集合里的元素进行比较, > some 至少比集合里的一个元素大,同理还有 < some、 <= some、= some、<>some
注意,<>some 不等价与 not in
<>some 等价于 not a OR not b OR not...,而 not in 等价于 not a AND not b AND not....select name from instructor where salary > some(select salary from instructor where dept_name = "Biology");- exists/not exists:可以使用 not exist 来表示 “关系A包含关系B”,即 not exist (B except A)
- 相关子查询:在子查询里使用了外层查询的一个相关名称,称为相关子查询,如下例中,子查询里使用了外层查询里关系 S 的 ID 属性
select S.ID S.name from student as S where not exists ((select course_id from course where dept_name = "Biology") except (select T.course_id from tales as T where S.ID = T.ID));- from 语句中的子查询:因为子查询的结果是一个关系,所以子查询可以被插入到另一个 select-from-where 查询中任何可以出现关系的位置
select dept_name, avg_salary from (select dept_name, avg(salary) as avg_salary) from instructor group by dept_name) where avg_salary > 42000;
修改
前面讲了对关系模式的修改,接下来讲讲对关系里的元组进行修改
- 删除:
-- 不加 where 子句就是删除所有元组但保留关系模式
delete
from r
where P
- 插入:
insert into r
(column1, column2, column3...)
values
(value1, value2, value3...);
-- 将查询结果插入到关系中
insert into instructor
select ID, name, dept_name, 18000
from student
where dept_name = "Music" and lol_cred > 144;
- 更新:
update instructor
set salary = salary * 1.05;
update instructor
set salary = salary * 1.05
where salary < 42000;
-- 有时候两条更新语句的执行顺序很重要,SQL 提供了 case 结构来进行顺序执行
update instructor
set salary = case
when salary <= 42000 then salary * 1.05
else salary * 1.03
end;
-- case 的一般结构
case
when pred1 then result1
when pred2 then result2
when pred3 then result3
...
when predn then resultn
else result
end
第四章 中级SQL
视图
视图(view)可以看作是一种定制化的关系,某些场景下我们会希望特定用户只能看见特定的属性,这时候就可以提供给特定用户特定视图
-- 定义一个视图 v
create view v as <query expression>
create view faculty as
select ID, name, dept_name
from instructor;
-- 为视图中的字段指定名字
create view department_total_salary(dept_name, total_salayr) as
select dept_name, sum(salary)
from instructor
group by dept_name;
视图可以看成是一条查询语句的别名,由于查询的结果是个关系,所以视图可以出现在任何关系可以出现的位置,它是一种虚关系,只有在被使用的时候才会被执行查询并计算出结果。
虽然视图可以出现在任何关系可以出现的地方,但如果用它来表达更新、插入或删除,会存在一些问题,比如插入,视图中未包含的属性可能存在一些不能取 null 的情况,又或者某个视图涉及到了2个关系,但两个关系用来做映射的属性不包含在视图里,那么即使通过视图插入了一个元组,由于映射连接的属性为 null,找不到在另一个关系中所对应的元组,那么这条插入也不会出现在视图里,所以一般不允许对视图关系进行修改,但如果定义驶入的查询满足一些条件,是可以对视图进行更新的。
事务
事务(transaction)由一个或多个查询/更新语句序列组成,为了保证数据的一致性(如转账操作,一个扣钱一个加钱,这两个操作要么同时成功要么同时失败),事务具有原子性,即一个事务或者在完成所有的语句后进行提交(commit)或者出现问题不能完成所有的操作进行回滚(rollback)撤销所有动作,回到事务开始前的状态,从而不会让数据库出现部分更新的状态。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix