爬取b站评论的简单尝试
最近新学了点爬虫基础,拿b站评论试试。 首先,要知道b站是不可能把评论都放在一个html文件里发给你,即便打开chrome的开发者工具也只会看到如下图的样子 ,这里用的是b站后浪视频做例子(图片请在新标签页打开,压缩的太狠了)
细心的同学会发现,在网页端打开一个视频主页向下拖动至评论区的时候,会看到一闪而过的“正在加载“字样,随后评论才被加载出来,而网页url并未改变也没有刷新,这意味着评论是在网页不刷新的前提下再次发送请求得到的数据,我们通常把这种请求叫做ajax,也就是异步的JavaScript 和XML。
那么当你能看到评论的时候,说明已经收到含有评论的响应了,下面的工作就是找到这个含有数据的响应。而那么多响应如何快速找到呢,慢的方法:根据时间线,在加载完评论后选择时间最近的响应一个个看过去,主要看xhr和script的响应。当然,还有更快的方式,api的路径一般都不会乱起,在filter搜索框里输入”reply“,效果如下
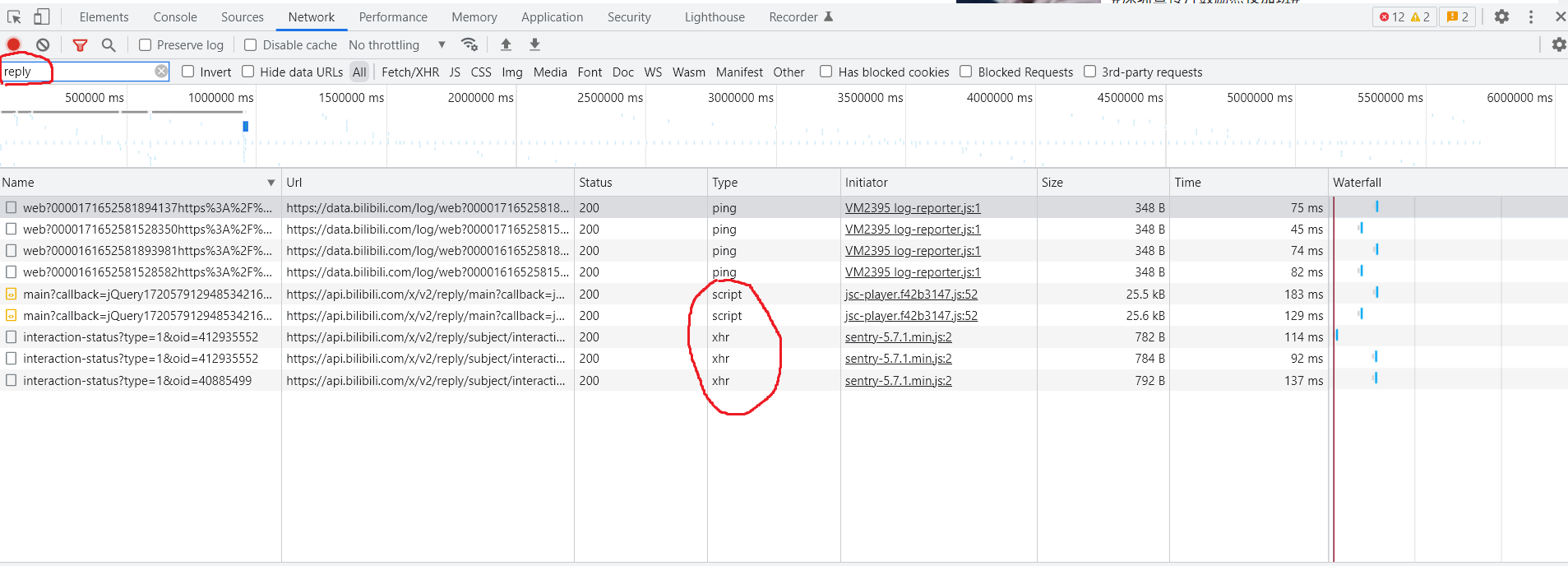
重点看红框标注的xhr和script类型,最终在script类型下找到
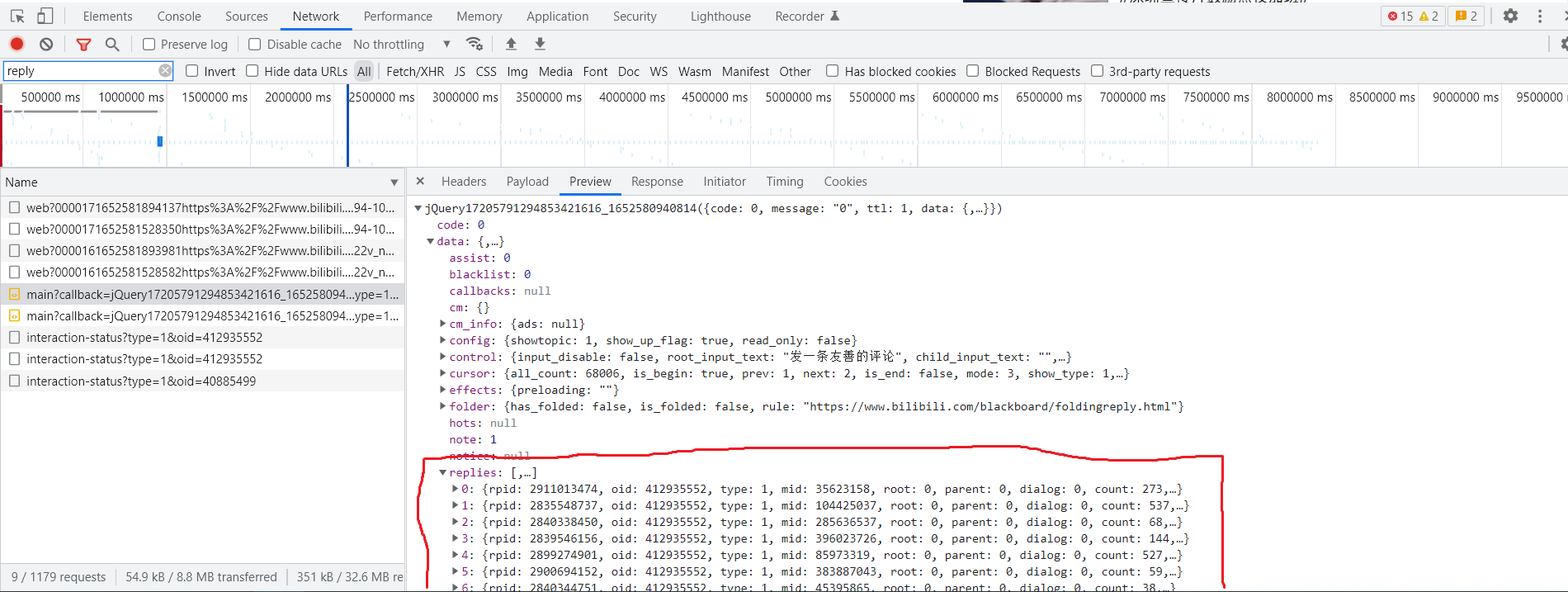
分析可得,评论请求每20条一组,第一组由于置顶评论会单独放在”top_replies"里,所以只有19条。另外,我只爬取了最外部的评论,楼中楼同理。得
找到数据之后事情就简单了,无非是分析api和参数,请求再解析即可。
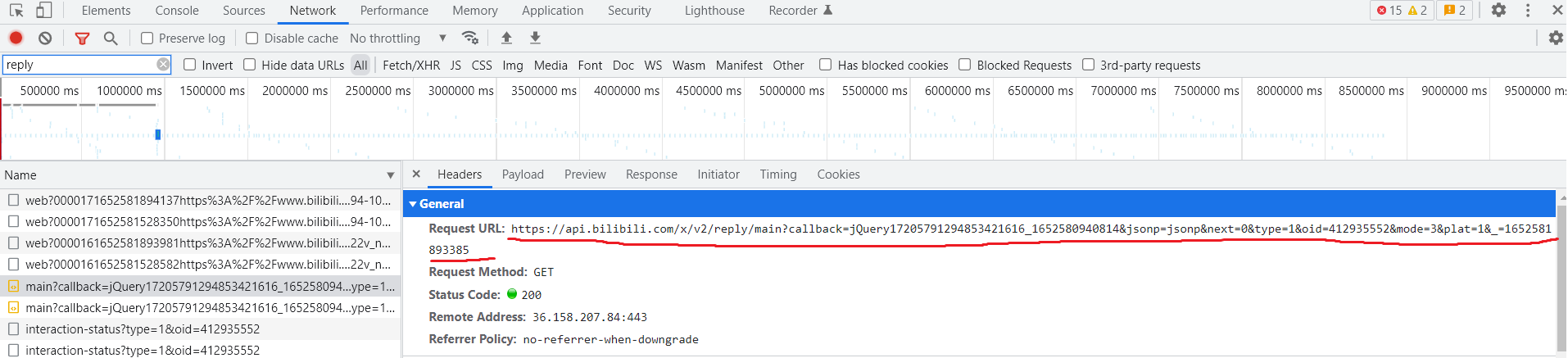
如图找到request url,分析有效参数,展开来看
https://api.bilibili.com/x/v2/reply/main
?callback=jQuery17205791294853421616_1652580940814
&jsonp=jsonp
&next=0
&type=1
&oid=412935552
&mode=3
&plat=1
&_=1652581893385
只有2个参数和我们有关,即next和oid,next是下一组评论的序号,oid是视频的av号(这里是百度看了一些帖子),callback和_参数即便删了也没有发现什么副作用,所以最后决定加上的参数为jsonp、type、mode、plat、next、oid,其中需要改变的参数只有next和oid。
我们先解决oid的问题。
视频的ulr里可以直接找到bv号,那么事情就好办了,这里提供bv转av的api,https://api.bilibili.com/x/web-interface/view,参数是bvid,获取到含av号的json数据,aid即为av号

再解决next的问题。
理论上,我们只要next+=1,就可以请求下条数据,但评论总是有限的,什么时候停止呢?分析之前的数据可以找到一个叫“is_end”的值,根据笔者尝试,这就是判断当前评论组是否是最后一组的变量
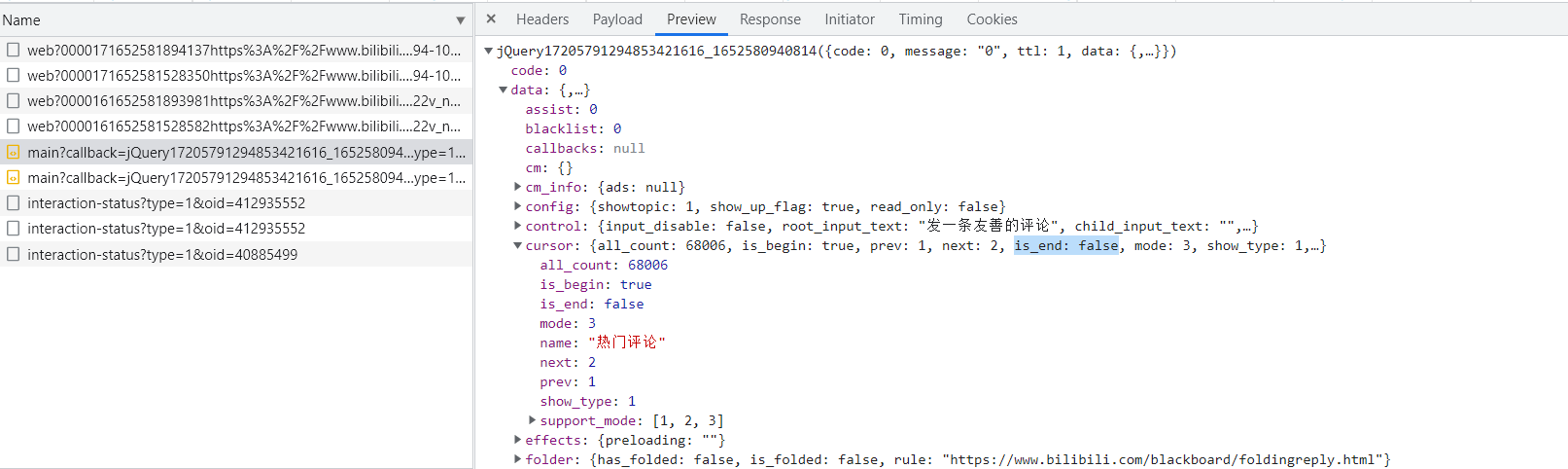
那么只要每次判断一下is_end即可,next也被解决。
下面是代码
1 import requests 2 import re 3 import json 4 5 headers = { 6 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36', 7 'cookie':'' # 在请求头里复制自己的cookie 8 } 9 bv2av_api = 'https://api.bilibili.com/x/web-interface/view' 10 content_api = 'https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&type=1&mode=3&plat=1'
# bv转av,输入如BVxxxxxxxxx,输出一串数字av号
def bv2av(bv:str)->str: response = requests.get(url=bv2av_api,params={'bvid':bv},headers=headers) av = str(response.json()['data']['aid']) return av
def scrape_url(url:str)->dict: bv = url.split('/')[-1] av = bv2av(bv) pattern = re.compile(r'{.*}') # 去除外层的jquery括号,让数据能被json解析 params={'jsonp':'jsonp','type':1,'oid':av,'mode':3,'plat':1} # 构造参数 headers['referer'] = url # 修改referer为当前视频url next = 0 # 初始值为0 with open('text','a+',encoding='utf-8') as file: while True: params['next'] = next response = requests.get(url=content_api,params=params,headers=headers) json_text = pattern.search(response.text).group(0) is_end = json.loads(json_text)['data']['cursor']['is_end'] if is_end: # is_end为True就break break replies_info = json.loads(json_text)['data']['replies'] res = [] for i in replies_info: res.append(i['content']['message']) json.dump(res,file,indent=2,ensure_ascii=False) # 每组评论写入文件 if next!=0: # 坑爹的参数,经过实践发现第一组next为0,第二组next为2,之后依次+1递增,next设为0和1返回数据一样。为了和实际保持一样,出此下策 next+=1 else: next+=2
scrape_url('https://www.bilibili.com/video/BVxxxxxxxxxx') # 填入url即可(spm_id是用户行为标记,不用理会)
数据会保存到当前目录下的text文件,本次爬取仅作学习使用。
