Linux 性能监控与故障排查:主要性能指标说明及监控方法
一台 Linux 服务器的四类指标如下:
- CPU:使用率、平均负载(load average)
- RAM:used | free | buffer/cache | avaliable
- Disk:空闲容量大小、IO 状态
- Network:网速、延迟、丢包率等
下面详细地说明各项系统参数的意义、它们的正常状态,以及出现异常时如何进行故障排查。
零、前置准备
很多的监控工具 Ubuntu/CentOS 都不自带,需要手动安装,在开始前我们最好先把所有可能用得上的监控工具都装上。(它们都很小,基本不占空间)
# ubuntu/debian
sudo apt-get install \
sysstat iotop fio \
nethogs iftop
# centos
# 需要安装 epel 源,很多监控工具都在该源中!
# 也可使用[阿里云 epel 源](https://developer.aliyun.com/mirror/epel)
sudo yum install epel-release
sudo yum install \
sysstat iotop fio \
nethogs iftop
大一统的监控工具
下面介绍两个非常方便的大一统监控工具,它们将一台服务器的所有监控数据汇总到一个地方,方便监控。
多机监控推荐用 prometheus+grafana,不过这一套比较吃性能,个人服务器没必要上。
NetData: 极简安装、超详细超漂亮的 Web UI
这里只介绍单机监控。NetData 也支持中心化的多机监控,待进一步研究。netdata 也可以被用作 prometheus 的 exporter.
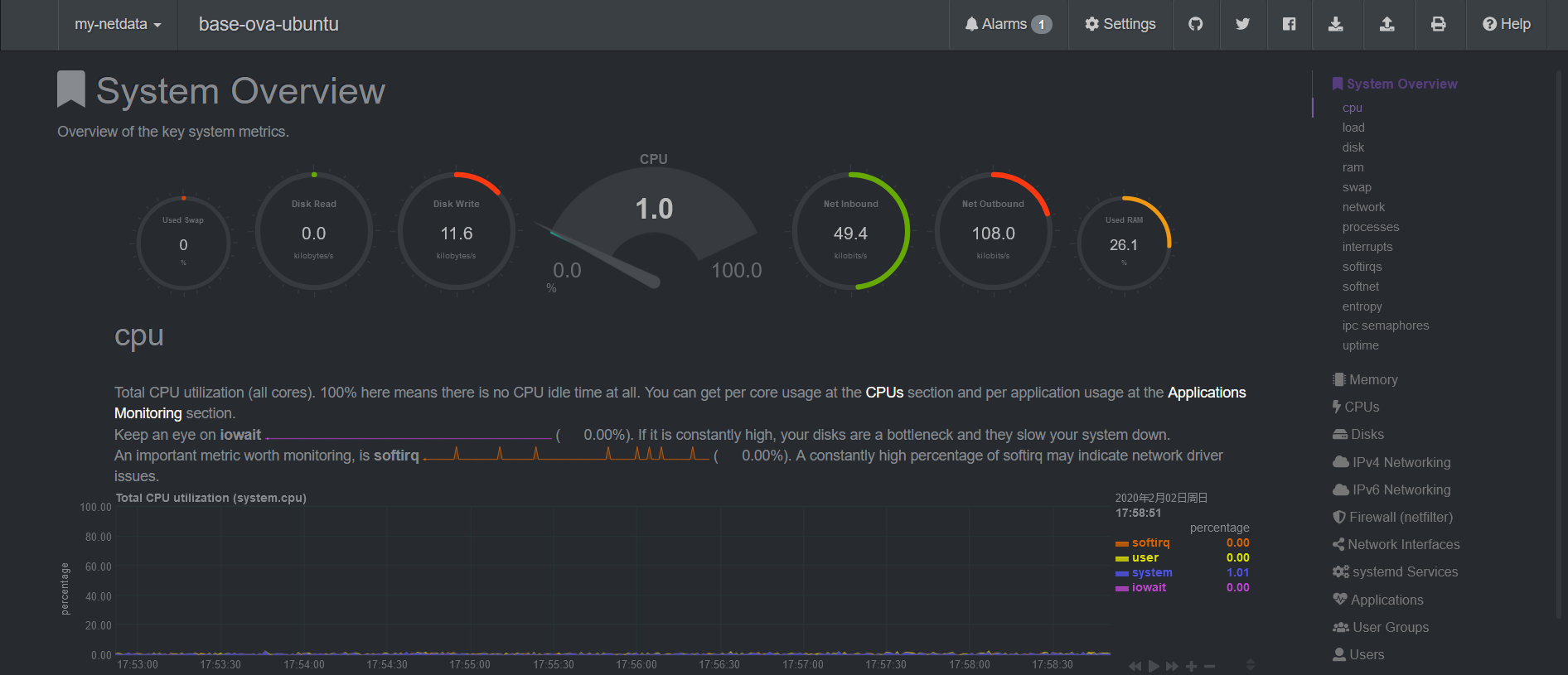
NetData 我要吹爆!它是 Github 上最受欢迎的系统监控工具,目前已经 44.5k star 了。
CPU 占用率低(0.1 核),界面超级漂亮超级详细,还对各种指标做了很详细的说明,安装也是一行命令搞定。相当适合萌新运维。
默认通过 19999 端口提供 Web UI 界面。
sudo apt-get install netdata
# 然后修改 /etc/netdata/netdata.conf,绑定 ip 设为 0.0.0.0
sudo systemctl restart netdata
现在就可以访问 http://<server-ip>:19999 查看超级漂亮超级详细的监控界面了!
Glances: 同样极简安装、方便的命令行 UI
netdata 只以 Web 服务器的方式提供 Web UI,因此必须常驻后台。
如果只是想要临时在 ssh 控制台进行监控,可以使用 Glances,安装命令如下:
sudo apt-get install glances
sudo yum install glances
启动命令:glances,可提供 CPU、RAM、NetWork、Disk 和系统状态等非常全面的信息。(只是不够详细)
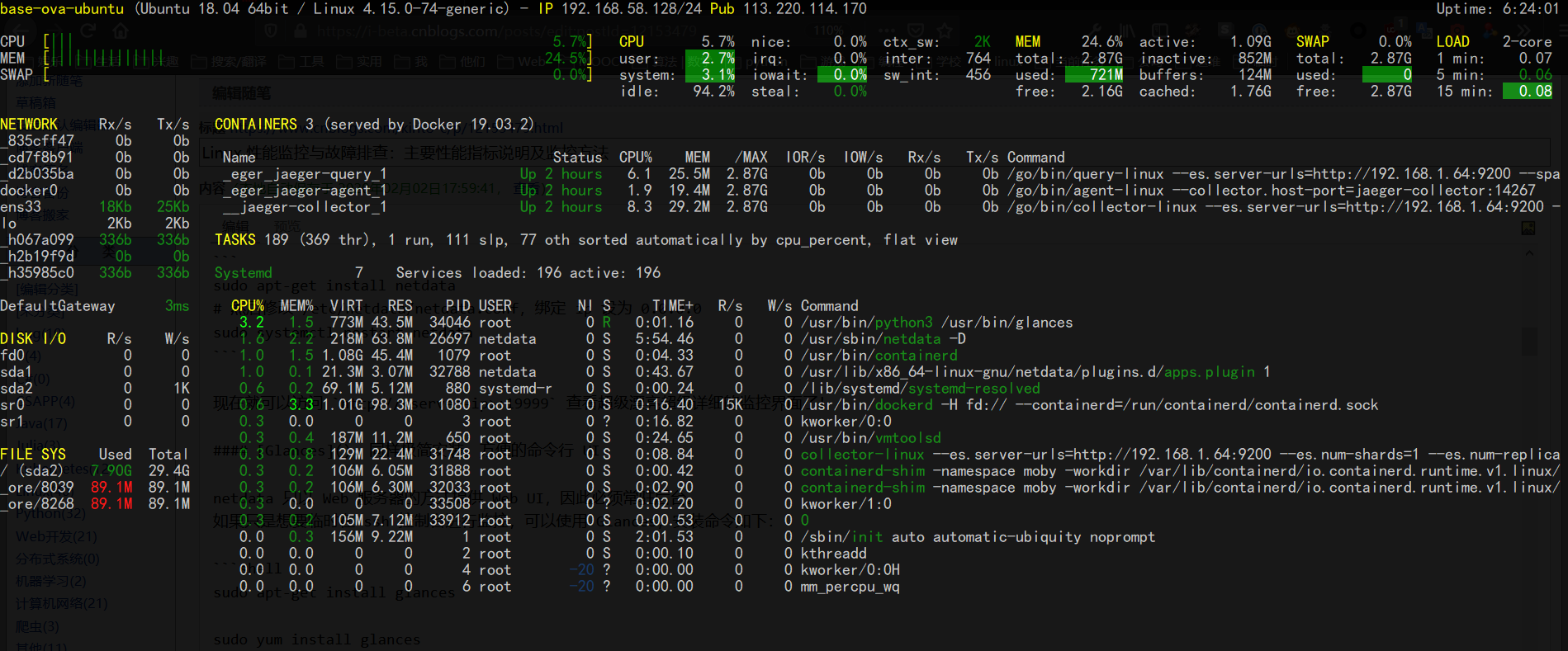
glances 同样提供中心化的多机监控,还有 Web 界面,但是和 netdata 相比就有些简陋了。不作介绍。
一、CPU 指标
1. CPU 使用率
CPU 使用率即 CPU 运行在非空闲状态的时间占比,它反应了 CPU 的繁忙程度。使用 top 命令我们可以得到如下信息:
%Cpu(s): 0.0 us, 2.3 sy, 0.0 ni, 97.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
us(user):表示 CPU 在用户态运行的时间百分比,通常用户态 CPU 高表示有应用程序比较繁忙。典型的用户态程序包括:数据库、Web 服务器等。sy(sys):表示 CPU 在内核态运行的时间百分比(不包括中断),通常内核态 CPU 越低越好,否则表示系统存在某些瓶颈。ni(nice):表示用 nice 修正进程优先级的用户态进程执行的 CPU 时间。nice 是一个进程优先级的修正值,如果进程通过它修改了优先级,则会单独统计 CPU 开销。id(idle):表示 CPU 处于空闲态的时间占比,此时,CPU 会执行一个特定的虚拟进程,名为 System Idle Process。wa(iowait):表示 CPU 在等待 I/O 操作完成的时间占比,通常该指标越低越好,否则表示 I/O 可能存在瓶颈,需要用 iostat 等命令做进一步分析。- iowait 只考虑 Synchronous File IO,It does NOT count time spent waiting for IPC objects such as sockets, pipes, ttys, select(), poll(), sleep(), pause() etc.
hi(hardirq):表示 CPU 处理硬中断所花费的时间。硬中断是由外设硬件(如键盘控制器、硬件传感器等)发出的,需要有中断控制器参与,特点是快速执行。si(softirq):表示 CPU 处理软中断所花费的时间。软中断是由软件程序(如网络收发、定时调度等)发出的中断信号,特点是延迟执行。st(steal):表示 CPU 被其他虚拟机占用的时间,仅出现在多虚拟机场景。如果该指标过高,可以检查下宿主机或其他虚拟机是否异常。
2. 平均负载(Load Average)
top 命令的第一行输出如下:
top - 21:11:00 up 8 min, 0 users, load average: 0.52, 0.58, 0.59
其中带有三个平均负载的值,它们的意思分别是** 1 分钟(load1)、5 分钟(load5)、15 分钟(load15)内系统的平均负载**。
平均负载(Load Average)是指单位时间内,系统处于 可运行状态(Running / Runnable) 和 不可中断态 的平均进程数,也就是 平均活跃进程数。
我们知道实际上一个 CPU 核只能跑一个进程,操作系统通过分时调度提供了多进程并行的假象。所以当平均负载(平均活跃进程数)不大于 CPU 逻辑核数时,系统可以正常运转。
如果平均负载超过了核数,那就说明有一部分进程正在活跃中,但是它却没有使用到 CPU(同一时间只能有 1 个进程在使用 CPU),这只可能有两个原因:
- 这部分进程在排队等待 CPU 空闲。
- 这部分 CPU 在进行 IO 操作。
不论是何种状况,都说明系统的负载过高了,需要考虑降负或者升级硬件。
理想状态下,系统满负荷工作,此时平均负载 = CPU 逻辑核数(4核8线程 CPU 有8个逻辑核)。但是,在实际生产系统中,不建议系统满负荷运行。通用的经验法则是:平均负载 <= 0.7 * CPU 逻辑核数。
- 当平均负载持续大于 0.7 * CPU 逻辑核数,就需要开始调查原因,防止系统恶化;
- 当平均负载持续大于 1.0 * CPU 逻辑核数,必须寻找解决办法,降低平均负载;
- 当平均负载持续大于 5.0 * CPU 逻辑核数,表明系统已出现严重问题,长时间未响应,或者接近死机。
除了关注平均负载值本身,我们也应关注平均负载的变化趋势,这包含两层含义。一是 load1、load5、load15 之间的变化趋势;二是历史的变化趋势。
- 当 load1、load5、load15 三个值非常接近,表明短期内系统负载比较平稳。此时,应该将其与昨天或上周同时段的历史负载进行比对,观察是否有显著上升。
- 当 load1 远小于 load5 或 load15 时,表明系统最近 1 分钟的负载在降低,而过去 5 分钟或 15 分钟的平均负载却很高。
- 当 load1 远大于 load5 或 load15 时,表明系统负载在急剧升高,如果不是临时性抖动,而是持续升高,特别是当 load5 都已超过
0.7 * CPU 逻辑核数时,应调查原因,降低系统负载。
日常运维时,应该重点关注上述三个负载值之间的关系。
3. CPU 使用率与平均负载的关系
CPU 使用率是单位时间内 CPU 繁忙程度的统计。而平均负载不仅包括正在使用 CPU 的进程,还包括等待 CPU 或 I/O 的进程(前面讲过平均负载过高的两种情况)。
因此 CPU 使用率是包含在平均负载内的。这两个参数有两种组合需要注意:
- 两个参数值都很高:需要降低 CPU 使用率!
- CPU 使用率很低,可平均负载却超过了CPU逻辑核数:IO 有瓶颈了!需要排查 内存/磁盘/网络 的问题。
- 最常遇到的场景:内存用尽导致负载飙升。
二、RAM 内存指标
free # 单位 kb
free -m # 单位 mb
free -g # 单位 gb
不考虑 Swap 时,建议以 Avaliable 值为可用内存的参考,因为 buffer/cache 中的内存不一定能完全释放出来!因为:
- OS 本身需要占用一定 buffer/cache
- 通过 tmpfs 等方式被使用的 cache 不能被回收使用
- 通过 cgroups 设置的资源预留无法被别的进程回收利用。(容器资源预留)
内存泄漏
内存泄漏有多种可能,通过监控能确定的只有内存是否在无上限地上升。很难直接通过监控排查。
三、Disk 磁盘指标
Disk 的性能指标主要有:
- bandwidth 带宽,即每秒的 IO 吞吐量
- 连续读写频繁的应用(传输大量连续的数据)重点关注吞吐量,如读写视频的应用。
- IOPS,每秒的 IO 次数
- 随机读写频繁的应用需要关注 IOPS,如大量小文件(图片等)的读写。
我们是 Web 服务器/数据库服务器,主要是随机读写,更关注 IOPS。
0. IO 基准测试
要监控磁盘的指标,首先得有个基准值做参考。
方法一:对整块磁盘进行测试
首先安装磁盘测试工具 fio(安装命令见文章开始),然后将如下内容保存为 fio-rand-rw.fio(Web 服务器/数据库更关注随机读写):
; https://github.com/axboe/fio/blob/master/examples/fio-rand-RW.fio
; fio-rand-RW.job for fiotest
[global]
name=fio-rand-RW
filename=fio-rand-RW
rw=randrw
rwmixread=60
rwmixwrite=40
bs=4K
direct=0
numjobs=4
time_based=1
runtime=900
[file1]
size=4G
ioengine=libaio
iodepth=16
现在运行命令 fio fio-rand-rw.fio 以启动测试,可根据情况调整 .fio 文件中的参数,最后记录测试结果。
方法二:使用 dd 进行磁盘速度测试
使用 dd 测试的好处是系统自带,而且也不会破坏磁盘内容。
# 写入测试,读取 /dev/zero 这个空字符流,写入到 test.dbf 中(就是只测写入)
# 块大小为 8k,也就是说偏向随机写
dd if=/dev/zero of=test.dbf bs=8k count=50000 oflag=dsync # 每次写完一个 block 都同步,伤硬盘,不要没事就测
# 读取 /dev/sda1 中的数据,写入到 /dev/null 这个黑洞中(只测读取)
# 块大小还是 8k,即偏向随机读
dd if=/dev/sda1 of=/dev/null bs=8k
日常监控的数值远低于上面测得的基准值的情况下,基本就可以确定磁盘没有问题。
1. 使用率
通过 df -h 查看磁盘的使用情况,详细排查流程参见 linux 磁盘占用的排查流程
磁盘不足会导致各种问题,比如:
- ElasticSearch 自动将索引设为只读,禁止写入。
- k8s 报告 "Disk Pressure",导致节点无法调度。
- shell 的 tab 补全无法使用,会报错。
2. IO 带宽(吞吐量)以及 IOPS
使用 iostat 查看磁盘 io 的状态(需要安装 sysstat,安装命令见文章开头):
# 每个磁盘一列,给出所有磁盘的当前状态
iostat -d -k 3 # 以 kb 为单位,3 秒刷新一次
iostat -d -m 3 # 以 mb 为单位,其他不变
# 每个进程一列,可用于排查各进程的磁盘使用状态
iotop
将监控值与前述测试得到的基准值进行对比,低很多的话,基本就可以确认磁盘没问题。
四、Network 网络指标
和 IO 指标类似,网络指标主要有:
- socket 连接
- 连接数存在上限,该上限与 Linux 的文件描述符上限等参数有关。
- 广为人知的 DDOS 攻击,通过 TCP 连接的 ACK 洪泛来使服务器瘫痪,针对的就是 TCP 协议的一个弱点。
- 网络带宽(吞吐量)
- PPS(Packets Per Second) 数据包的收发速率
- 网络延迟:一般通过 ping 来确定网络延迟和丢包率
- 丢包率等等
- DNS 解析
客户端与服务器之间的整条网络链路的任何一部分出现故障或配置不当,都可能导致上述的监控参数异常,应用无法正常运行。典型的如交换机、负载均衡器、Kubernetes 配置、Linux 系统参数(sysctl/ulimit)配置不当等。
1. 网络带宽监控
- nethogs: 每个进程的带宽监控,并且进程是按带宽排序的
- 使用:
sudo nethogs - 快速分析出占用大量带宽的进程
- 使用:
- tcpdump/tshark/mitmproxy: 命令行的网络抓包工具,mitmproxy 提供 Web UI 界面,而 tshark 是 wireshark 的命令行版本。
tcpdump -i eth0 -w dump.pcap: 使用 tcpdump 抓 eth0 的数据包,保存到 dump.pcap 中。之后可以通过 scp/ssh 等命令将该 pcap 文件拷贝下来,使用 wireshark 进行分析。
2. Socket
Socket 的状态查看方法,参见 Socket 状态变迁图及命令行查看方法
# 查看 socket 连接的统计信息
# 主要统计处于各种状态的 tcp sockets 数量,以及其他 sockets 的统计信息
ss --summary
ss -s # 缩写
# 查看哪个进程在监听 80 端口
# --listening 列出所有正在被监听的 socket
# --processes 显示出每个 socket 对应的 process 名称和 pid
# --numeric 直接打印数字端口号(不解析协议名称)
ss --listening --processes --numeric | grep 80
ss -nlp | grep 80 # 缩写
ss -lp | grep http # 解析协议名称,然后通过协议名搜索监听
## 使用过时的 netstat
### -t tcp
### -u udp
netstat -tunlp | grep ":80"
# 查看 sshd 当前使用的端口号
ss --listening --processes | grep sshd
## 使用过时的 netstat
netstat -tunlp | grep <pid> # pid 通过 ps 命令获得
# 列出所有的 tcp sockets,包括所有的 socket 状态
ss --tcp --all
# 只列出正在 listen 的 socket
ss --listening
# 列出所有 ESTABLISHED 的 socket(默认行为)
ss
# 统计 TCP 连接数
ss | grep ESTAB | wc -l
# 列出所有 ESTABLISHED 的 socket,并且给出连接的计时器
ss --options
# 查看所有来自 192.168.5 的 sockets
ss dst 192.168.1.5
# 查看本机与服务器 192.168.1.100 建立的 sockets
ss src 192.168.1.5
# 查看路由表
routel
3. 网络延迟、丢包率
通过 ping 命令进行测试,使用 pathping (仅 Windows)进行分段网络延迟与丢包率测试。
4. DNS 故障排查
参见 Linux网络学习笔记(三):域名解析(DNS)——以 CoreDNS 为例
五、Kubernetes 预留资源
Kubernetes 是通过 Linux 的 cgroups 机制实现的资源预留。
这部分被预留的内存等资源,在 OS 的监控中仍然会是空闲状态,即使是通过 kubectl top 也是监控不到这部分预留资源的。
因为这部分资源实际上并未被使用,只是在 k8s 中的一个资源限制而已,预留资源目前是一种隐形的资源限制,无法通过系统监控来查看。
六、问题排查案例
如果服务器出现问题,但是上述四项参数都没有明显异常,就要考虑是不是系统配置或者应用配置的问题了。
1. 僵尸进程
僵尸进程过多,可以在上述指标都非常正常的情况下,使系统响应变得特别慢。
如果通过 top 命令观察到存在僵尸进程,可以使用如下命令将僵尸进程查找出来:
ps -ef| grep defunc
2. sysctl/ulimit 参数设置
sysctl/ulimit 设置不当,可以在上述指标都非常正常的情况下,使系统响应变得特别慢。
案例:为了方便,我在系统的初始化脚本 configure_server.py 里一次性将 redis/elasticsearch/网络 等 sysctl/ulimit 参数全部配置好。结果 elasticsearch 需要设置的 vm.max_map_count 参数导致 redis 服务器在长时间运行后响应变慢。
七、其他可能用到的命令
ps -ef | more: 查看所有进程的资源使用率(CPU/RAM),以及完整的运行命令。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号