

21、Linux-的网络IO模型
1.IO基本概述
1.什么是IO
所谓IO,无非就是输入输出,其实大家更多关注的是磁盘IO。事实上当我们在网络中传送一些数据时,他本质上也是一种IO。
2.网络中的IO是什么样?
拿用户请求Nginx这样的web服务器获取磁盘中的文件时,系统是如何处理的?
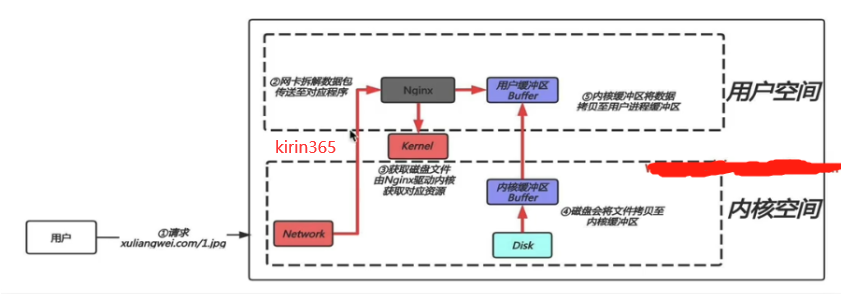
图片来源网络
通过上面的例子,用户每一次请求都会发生一次IO操作:而每次IO,都要经由两个阶段:
第一步:将数据从磁盘中加载至内核的内存空间(缓存区),等待数据准备完成,时间较长。
第二步:将数据从内核缓冲区复制到用户空间的进程内存(缓存区),时间较短。
第三步:Nginx封装数据为响应报文发送。
2.IO网络模型
1.IO模型分为、同步、异步、阻塞、非阻塞
同步/异步(关注的是消息通知机制)
同步∶调用者发指定给被调用者,被调用者需要获取一些资源后在返回给调用者,那么此时调用者需要等待被调用者返回消息,也就意味着调用者啥也干不了。(举例:当我们将衣服扔进洗衣服,那么衣服洗完没洗完也不知道,那就需要过一段时间去看一下,对于调用者来说很繁忙。)
异步︰调用者发指定给被调用者,被调用者需要获取一些资源后在返回给调用者,此时"”被调用者"会主动将当前的运行状态通知给调用者。(举例:当我们将衣服扔进洗衣机,当洗衣机完成洗衣服之前我们可以做点别的事情,等洗完后洗衣机会通知,此时我在去晾衣服。)
阻塞/非阻塞(关注的是“调用者"在等待"被调用者"返回结果之前所处的状态)
阻塞∶指IО操作需要彻底完成后才返回到用户空间,调用结果返回之前,调用者被挂起。(举例︰将衣服仍给洗衣机,然后人一直在旁边等着,什么时候洗完什么时候执行下一步动作。)
非阻塞︰指IО操作被调用后立即返回给用户进程一个状态值,无需等待lО操作彻底完成,在最终的调用结果返回之前,调用者不会被挂起。(举例︰将衣服仍给洗衣机,然后可以去干其他的事情,等洗完后,在去处理。)
2.IO模型组合起来又有很多种情况
同步阻塞︰将衣服仍到洗衣机,然后守在洗衣机旁边,等待他什么时候洗完什么时候处理。
同步非阻塞︰将衣服仍到洗衣机,然后可以去干别的事情,那是否洗完不知道,就需要时不时看一下。异步阻塞:将衣服仍给洗衣机,还是会在旁边等着(阻塞),洗衣机洗完了会通知。
异步非阻塞∶将衣服仍给洗衣机,可以去干其他事情,等待洗衣机洗完了会通知,然后在去取衣服。
3.五种常见的IO网络模型
3.1同步阻塞
1.当用户进程调用了recvfrom()这个系统调用,希望从磁盘获取数据
2.kernel就开始了IO的第一个阶段,准备数据,如果数据需要很长时间,那么就需要一直等待。
3.当kernel数据准备好了,会将数据从kernel中拷贝到用户进程内存,然后kernel返回数据结果,用户进程才解除阻塞状态,可以做其他事情。
总结,同步阻塞IO的特点就是在IO执行的两个阶段都被阻塞了。那么也就意味着一个进程只能响应一个用户请求,剩下请求会被挂起,会造成每次只能响应一个请求。
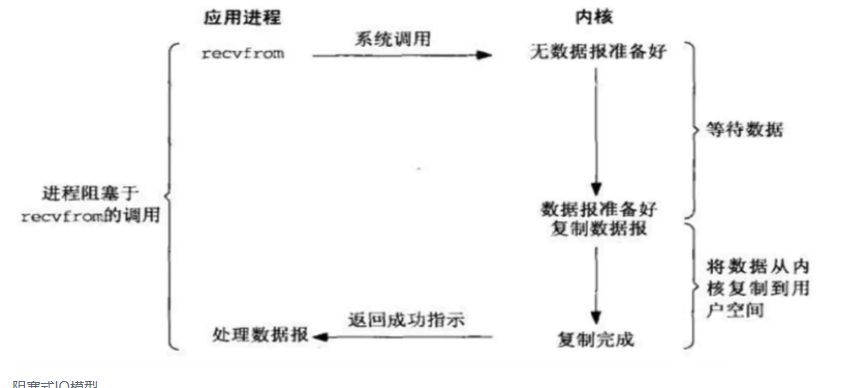
阻塞式IO模型
3.2同步非阻塞IO
1.当用户进程调用了recvfrom()这个系统调用,希望从磁盘获取数据。
2.那么是否完成并不知道,需要一次一次的去问。
3.当kernel 中的数据准备好了,此时用户进程再次发起系统调用,那么它马上就将数据拷贝到了用户进程内存。所以,非阻塞lO的特点是用户进程需要不断的主动询问kernel数据好了没有。好处︰用户进程可以处理其他任务,坏处︰任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作。
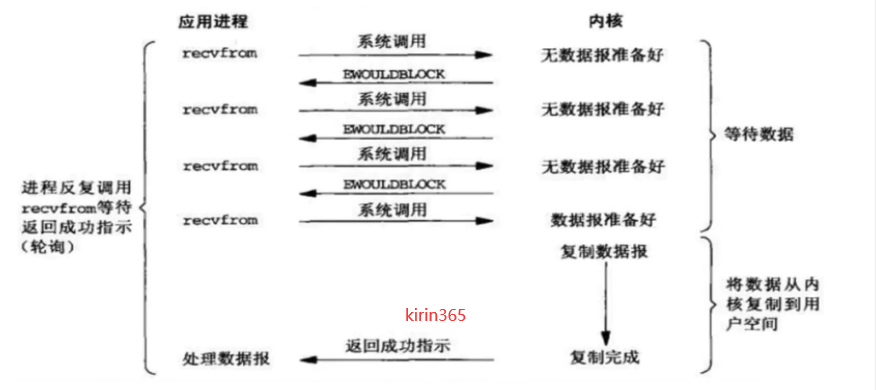
非阻塞式IO
3.3IO多路复用
1.当用户进程发起调用请求,不用直接与内核交互,而是找一个应用代理进程select,当用户进程调用了select,那么整个进程会阻塞在select上(因为是由select与内核进行交互,需要等待select返回结果)。
2.kernel会“监视"select负责的数据,当任何一个进程的数据准备好了,select就会返回。
3.当select用户进程返回结果后,用户程序会再次进行系统调用,将kernel数据拷贝到用户进程。总结,select代理进程,它这一个进程可以接收多个用户进程的请求。(像办签证一样)
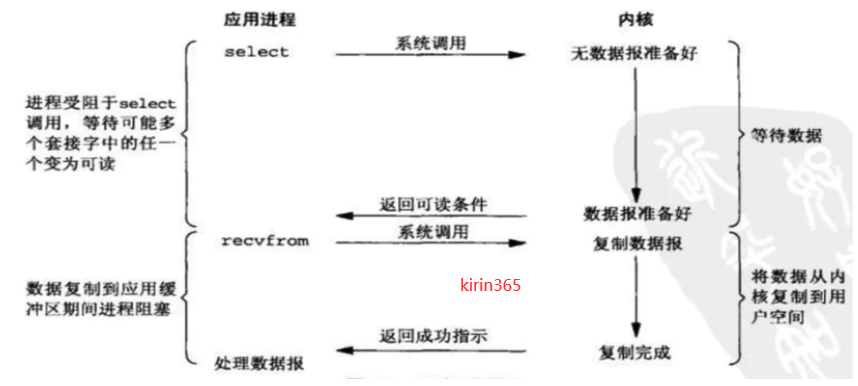
IO复用模型
3.4信号驱动IO
1.当用户进程调用了recvfrom)这个系统调用,希望从磁盘获取数据。
⒉磁盘文件中的数据如果还没有读取到内核时,没关系,进程还可以继续运行并不阻塞。
3.当磁盘数据复制到内核中后,会通知用户进程数据准备就绪。
4.用户进程在发指定将内核中数据复制到用户进程中,此时进程会进入阻塞状态。
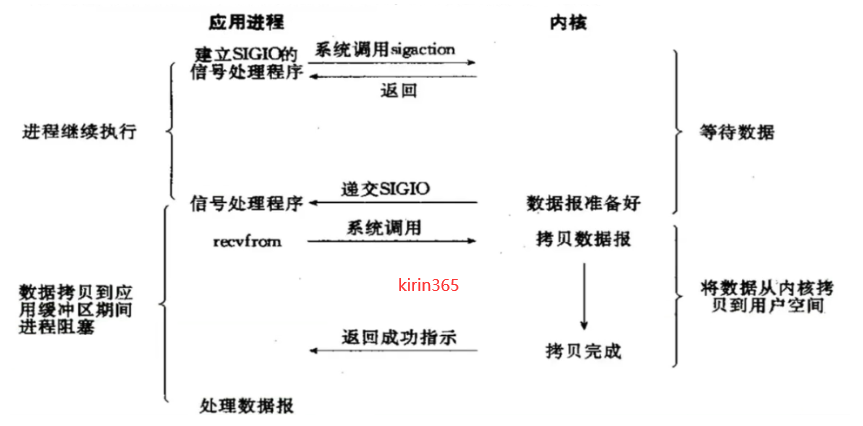
信号驱动IO模型
3.5异步非阻塞IO
1.当用户进程调用了recvfrom()这个系统调用,希望从磁盘获取数据。
2.kernel收到后,会立刻返回,所以不会对用户进程产生任何阻塞。
3.kernel等待数据准备完成,并将内核数据拷贝到用户进程内存,当这一切都完成之后,kernel会给用户进程发送—个回调函数通知用户进程本次IO完成。
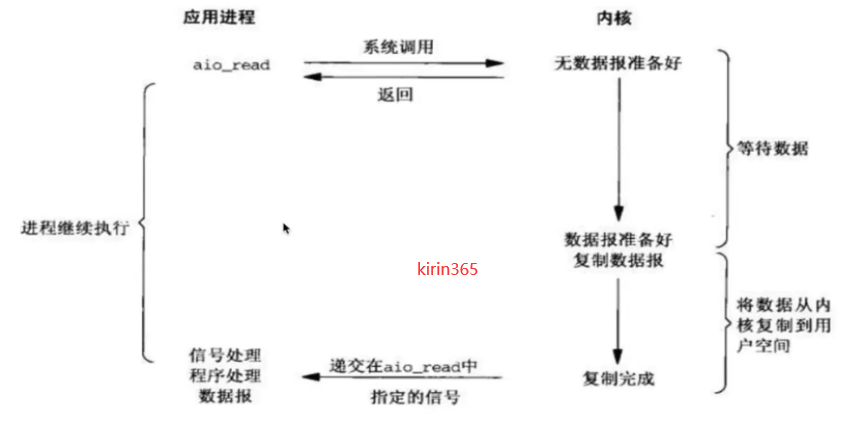
4.IO模型的实现
1.IO模型具体实现方式由以下几种:
Select : Linux实现对应,IO/复用模型,BSD4.2最早实现
Poll: Linux实现,对应IO复用模型,System V unix最早实现
Epoll : Linux实现,对应IO复用模型,具有信号驱动I/O模型某些特性
2.select、poll、epoll区别?
无论是select、poll、epoll都可以面对多个用户进程的请求,它相当于一个代理人,收集很多用户进程的请求,收集完成后,它帮你从磁盘上获取数据,复制到内核中,那么这个数据准备没准备好,它的实现机制是不一样的。

通知方式∶假设有一个用户数据准备好了,那么还有很多用户数据没准备好,那么如何通知呢?
select和poll是遍历扫描,效率低下。
epoll采用回调机制, epoll会主动通知,效率会更高。
lO效率:假设100个用户发请求和1000个用户发请求,在遍历的时候的性能一样吗?
select和poll用户的请求越多,所需要遍历的就越多,需要耗时就越长。
epool采用的是回调方式,无论有多少用户,它发送的时间是一样的。
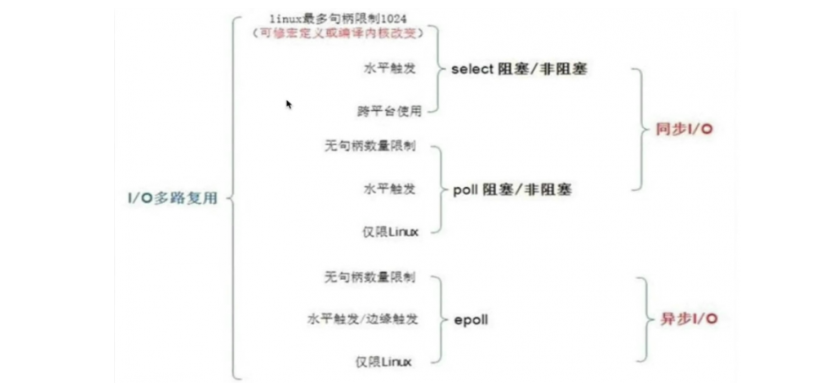
那么nginx从最初设计时,就是使用的事件驱动式IO,使用边缘触发机制。同时nginx还支持异步O,用了近几年最新的服务端编程技术,来支持较好的并发
本文来自博客园,作者:kirin(麒麟),转载请注明原文链接:https://www.cnblogs.com/kirin365/articles/16339063.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号