算法导论(第4章 分治策略)
第4章 分治策略
在分治策略中,我们递归地求解一个问题,在每层递归中应用如下三个步骤:
分解(Divide)将问题划分为一些子问题,子问题的形式与原问题一样,只是规模更小。
解决(Conquer)递归地求解出子问题。如果子问题的规模足够小,则停止递归,直接求解。
合并(Combine)将子问题的解组合成原问题的解。
当子问题足够大,需要递归求解时,我们称之为递归情况(recursive case)。
当子问题足够小,不再需要递归时,我们说递归已经“触底”,进入了基本情况(base case)。
递归式与分治方法是紧密相关的,它通过更小的输入上的函数值来描述一个函数。
本章介绍三种求解递归式的方法,即得出算法的“\(Θ\)”或“O”渐近界的方法:
- 代入法 我们猜测一个界,然后用数学归纳法证明这个界是正确的。
- 递归树法 将递归式转换为一棵树,其结点表示不同层次的递归调用产生的代价。然后采用边界和技术来求解递归式。
- 主方法 可求解形如下面公式的递归式的界:
\(T(n) = aT/(n/b) + f(n)\)
其中\(a≥1\),\(b>1\),\(f(n)\)是一个给定的函数。这种形式的递归式刻画了这样一个分治算法:生成\(a\)个子问题,每个子问题的规模是原问题规模的\(1/b\),分解和合并步骤总共花费时间为\(f(n)\)。
递归式技术细节:在实际应用中,我们会忽略递归式声明和求解的一些技术细节,以及向下取整、向上取整和边界条件。
4.1 最大子数组问题
问题描述:
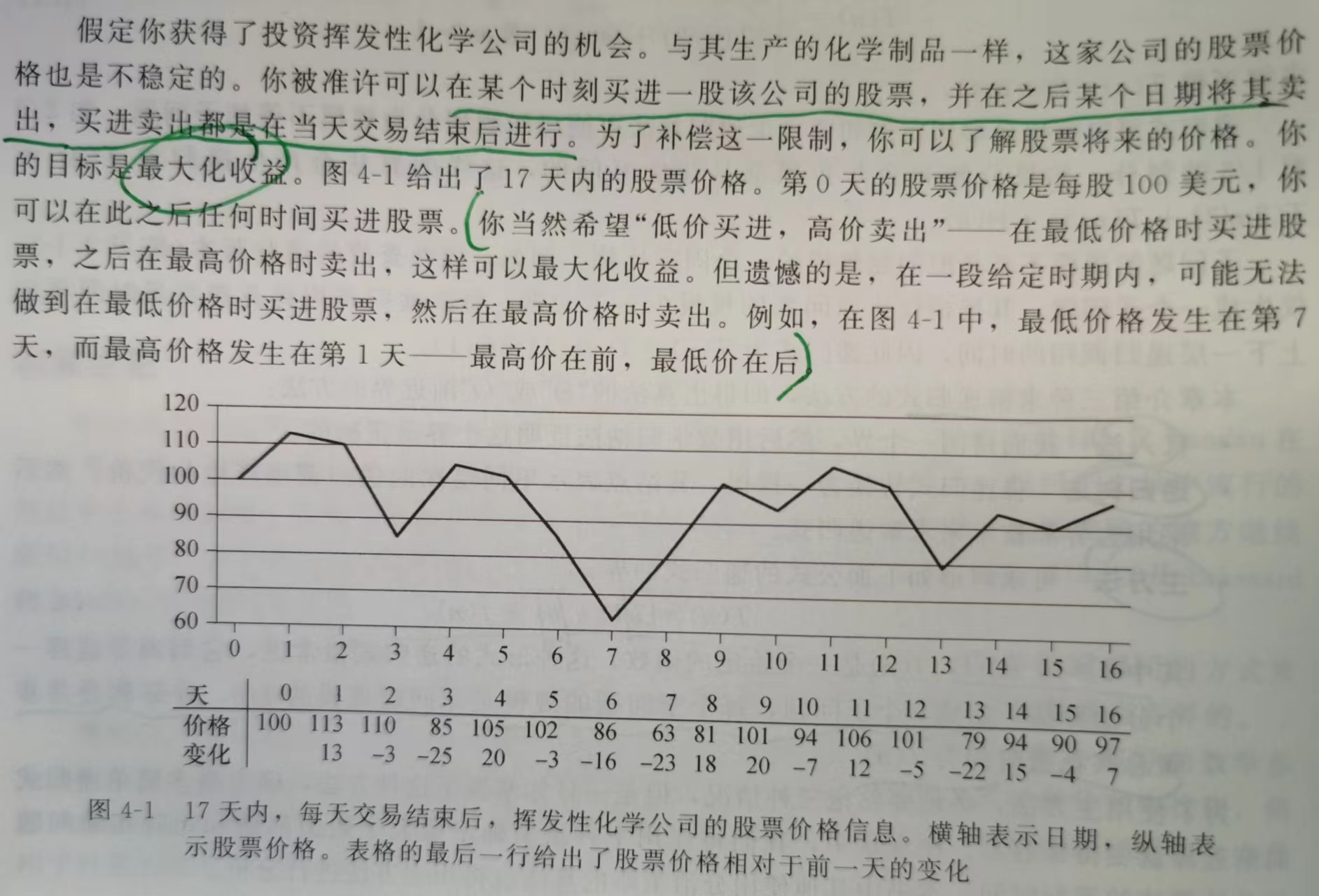
暴力求解方法
简单地尝试每对可能的买进和卖出日期组合,只要卖出日期在买入日期之后即可。
\(n\)天中共有\(C_n^2\)种日期组合。因为\(C_n^2 = \Theta(n^2)\),所以时间复杂度为\(\Omega(n^2)\)。
问题变换
我们考察每日价格变化,将其看做一个数组A。
此时A的非空连续子数组的和为净收益。
那么问题就转化为寻找A的和最大的非空连续子数组——最大子数组(maximum subarray)。

使用分治策略的求解方法
假定我们要寻找子数组\(A[low..high]\)的最大子数组。使用分治技术意味着我们要将子数组划分为两个规模尽量相等的子数组——找到子数组的中央位置\(mid\),然后考虑求解两个子数组\(A[low..mid]\)和\(A[mid+1..high]\)。那么\(A[low..high]\)的任何连续子数组\(A[i..j]\)所处的位置必然是以下三种情况之一:
- 完全位于子数组\(A[low..mid]\)中(左子数组)
- 完全位于子数组\(A[mid+1..high]\)中(右子数组)
- 跨越了中点
我们可以递归地求解\(A[low..mid]\)和\(A[mid+1..high]\)的最大子数组,因为这两个子问题仍是最大子数组问题,只是规模更小。因此剩下的全部工作就是寻找跨越中点的最大子数组,然后在三种情况中选取和最大者。

过程FIND-MAX-CROSSING-SUBARRAY接收数组\(A\)和下标\(low\)、\(mid\)和\(high\)为输入,返回一个下标元组划定跨越中点的最大子数组的边界,并返回最大子数组中值的和。
FIND-MAX-CROSSING-SUBARRAY(A, low, mid, high)
1 left-sum = -∞
2 sum = 0
3 for i = mid downto low
4 sum = sum + A[i]
5 if sum > left-sum
6 left-sum = sum
7 max-left = i
8 right-sum = -∞
9 sum = 0
10 for j = mid + 1 to high
11 sum = sum + A[j]
12 if sum > right-sum
13 right-sum = sum
14 max-right = j
15 return (max-left, max-right, left-sum + right-sum)
如果子数组\(A[low..high]\)包含\(n\)个元素(\(n = high - low + 1\)),则调用FIND-MAX-CROSSING-SUBARRAY(A, low, mid, high)花费\(\Theta(n)\)时间。(每次迭代花费\(\Theta(1)\),总循环迭代次数为\(n\))
有了一个线性时间的FIND-MAX-CROSSING-SUBARRAY,我们就可以设计求解最大子数组问题的分治算法的伪代码:
FIND-MAXIMUM-SUBARRAY(A, low, high)
1 if high == low
2 return (low, high, A[low]) //base case: only one element
3 else
4 mid = ⌊(low + high)/2⌋
5 (left-low, left-high, left-sum) = FIND-MAXIMUM-SUBARRAY(A, low, mid)
6 (right-low, right-high, right-sum) = FIND-MAXIMUM-SUBARRAY(A, mid + 1, high)
7 (cross-low, cross-high, cross-sum) = FIND-MAX-CROSSING-SUBARRAY(A, low, mid, high)
8 if left-sum >= right-sum and left-sum >= cross-sum
9 return (left-low, left-high, left-sum)
10 else if right-sum >= left-sum and right-sum >= cross-sum
11 return (right-low, right-high, right-sum)
12 else
13 return (cross-low, cross-high, cross-sum)
初始调用FIND-MAXIMUM-SUBARRAY(A, 1, A.length)即可求出\(A[1..n]\)的最大子数组。
分治算法的分析
我们建立一个递归式来描述递归过程FIND-MAXIMUM-SUBARRAY的运行时间:
\(T(n) = \Theta(1)——(n = 1)\)
\(T(n) = 2T(n/2) + \Theta(n)——(n > 1)\)
解得\(T(n) = \Theta(nlgn)\)。
利用分治方法得到了一个渐近复杂性优于暴力求解方法的算法。
实际上,最大子数组问题存在一个不使用分治方法的线性时间的算法,见练习4.1-5。
4.2 矩阵乘法的Strassen算法
若\(A = (a_{ij})\)和\(B = (b_{ij})\)是\(n×n\)方阵,则对\(i, j = 1, 2, …, n\),定义乘积\(C = A · B\)中的元素\(c_{ij} = \sum_{k = 1}^{n}a_{ik}·b_{kj}\)。我们需要计算\(n^2\)个矩阵元素,每个元素是\(n\)个值之和。
SQUARE-MATRIX-MULTIPLY(A, B)
1 n = A.rows
2 let C be a new n×n matrix
3 for i - 1 to n
4 for j = 1 to n
5 c_{ij} = 0
6 for k = 1 to n
7 c_{ij} = c_{ij} + a_{ik}·b_{kj}
8 return C
不难得出,过程SQUARE-MATRIX-MULTIPLY花费\(\Theta(n^3)\)时间。
一个简单的分治算法
为简单起见,我们不妨设\(n\)为2的幂。(在每个分解步骤中,\(n×n\)矩阵都被划分为4个\(n/2×n/2\)的子矩阵)
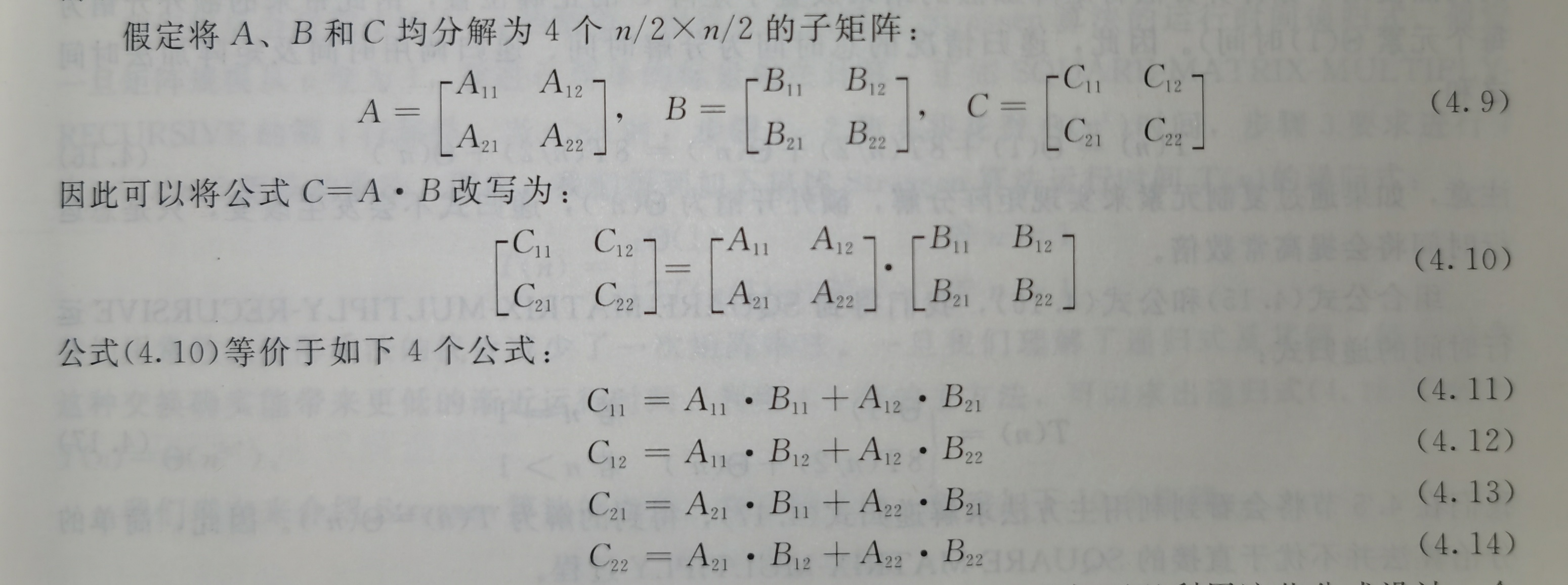
我们可以利用这些公式设计一个直接的递归分治算法:
SQUARE-MATRIX-MULTIPLY-RECURSIVE(A, B)
1 n = A.rows
2 let C be a new n×n matrix
3 if n == 1
4 c_{11} = a_{11}·b_{11}
5 else partition A, B, and C as in equations (4.9)
6 C_{11} = SQUARE-MATRIX-MULTIPLY-RECURSIVE(A_{11}, B_{11}) + SQUARE-MATRIX-MULTIPLY-RECURSIVE(A_{12}, B_{21})
7 C_{12} = SQUARE-MATRIX-MULTIPLY-RECURSIVE(A_{11}, B_{12}) + SQUARE-MATRIX-MULTIPLY-RECURSIVE(A_{12}, B_{22})
8 C_{21} = SQUARE-MATRIX-MULTIPLY-RECURSIVE(A_{21}, B_{11}) + SQUARE-MATRIX-MULTIPLY-RECURSIVE(A_{22}, B_{21})
9 C_{22} = SQUARE-MATRIX-MULTIPLY-RECURSIVE(A_{21}, B_{12}) + SQUARE-MATRIX-MULTIPLY-RECURSIVE(A_{22}, B_{22})
10 return C
这段伪代码掩盖了一个微妙但重要的实现细节——在第5行应该如何分解矩阵
如果我们真的创建12个新的\(n/2×n/2\)矩阵,将会花费\(\Theta(n^2)\)时间复制矩阵元素。实际上,我们可以不必复制元素就能完成矩阵分解,其中的诀窍是使用下标计算——通过原矩阵的一组行下标和一组列下标来指明一个子矩阵。此时执行第5行只需\(\Theta(1)\)的时间。
我们建立一个递归式来描述递归过程SQUARE-MATRIX-MULTIPLY-RECURSIVE的运行时间:
\(T(n) = \Theta(1)——(n = 1)\)
\(T(n) = 8T(n/2) + \Theta(n^2)——(n > 1)\)
解得\(T(n) = \Theta(n^3)\)。
简单的分治算法并不优于直接的SQUARE-MATRIX-MULTIPLY过程。
Strassen方法
Strassen算法的核心思想是令递归树稍微不那么茂盛一点——只递归进行7次而不是8次\(n/2×n/2\)矩阵的乘法。
Strassen算法不是那么直观(这可能是本书陈述最不充分的地方了),包含4个步骤:
- 按公式(4.9)将输入矩阵A、B和输出矩阵C分解为\(n/2×n/2\)的子矩阵。采用下标计算方法,此步骤花费\(\Theta(1)\)时间,与SQUARE-MATRIX-MULTIPLY-RECURSIVE相同。
- 创建10个\(n/2×n/2\)的矩阵\(S_1, S_2, …, S_10\),每个矩阵保存步骤1中创建的两个子矩阵的和或差。花费时间为\(\Theta(n^2)\)。
- 用步骤1中创建的子矩阵和步骤2中创建的10个矩阵,递归地计算7个矩阵积\(P_1, P_2, …, P_7\)。每个矩阵\(P_i\)都是\(n/2×n/2\)的。
- 通过\(P_i\)矩阵的不同组合进行加减运算,计算出结果矩阵\(C\)的子矩阵\(C_{11}, C_{12}, C{21}, C_{22}\)。花费时间\(\Theta(n^2)\)。
我们建立一个递归式来描述Strassen算法的运行时间:
\(T(n) = \Theta(1)——(n = 1)\)
\(T(n) = 7T(n/2) + \Theta(n^2)——(n > 1)\)
解得\(T(n) = \Theta(n^{lg7})\)。
Strassen方法的渐近复杂性低于直接的SQUARE-MATRIX-MULTIPLY过程。
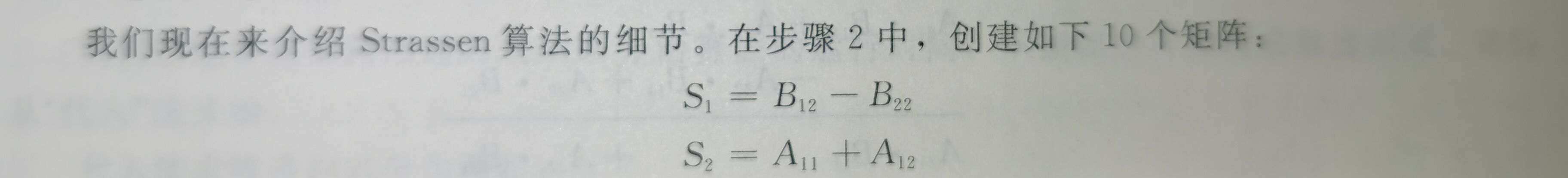



4.3 用代入法求解递归式
代入法求解递归式分为两步:
- 猜测解的形式。
- 用数学归纳法求出解中的常数,并证明解是正确的。
当将归纳假设应用于较小的值时,我们将猜测的解代入函数,因此得名“代入法”。这种方法很强大,但我们必须能猜出解的形式,以便将其带入。
下面给出运用代入法求解递归式的例子:

做出好的猜测
- 启发式方法——使用递归树来做出好的猜测。(4.4节)
- 如果要求解的递归式与曾经见过的递归式类似,那么猜测一个类似的解是合理的。
- 先证明递归式较松的上界和下界,然后缩小不确定的范围。
微妙的细节
有时可能正确猜出了递归式解的渐进解,但莫名其妙地在归纳证明时失败了。问题常常出在归纳假设不够强,我们可以将猜测减去一个低阶项。

避免陷阱
使用渐近符号很容易出错,我们需要显式地证明。
eg:
\(T(n) = O(n)\) ×
\(T(n) \leqslant cn\) ✓
改变变量

4.4 用递归树方法求解递归式
在递归树中,每个结点表示一个单一子问题的代价,子问题对应某次递归函数调用。我们将树中每层中的代价求和,得到每层代价,然后将所有层的代价求和,得到所有层次的递归调用的总代价。
下面我们根据递归式\(T(n) = 3T(\lfloor n/4 \rfloor) + \Theta(n^2)\)构造其递归树:
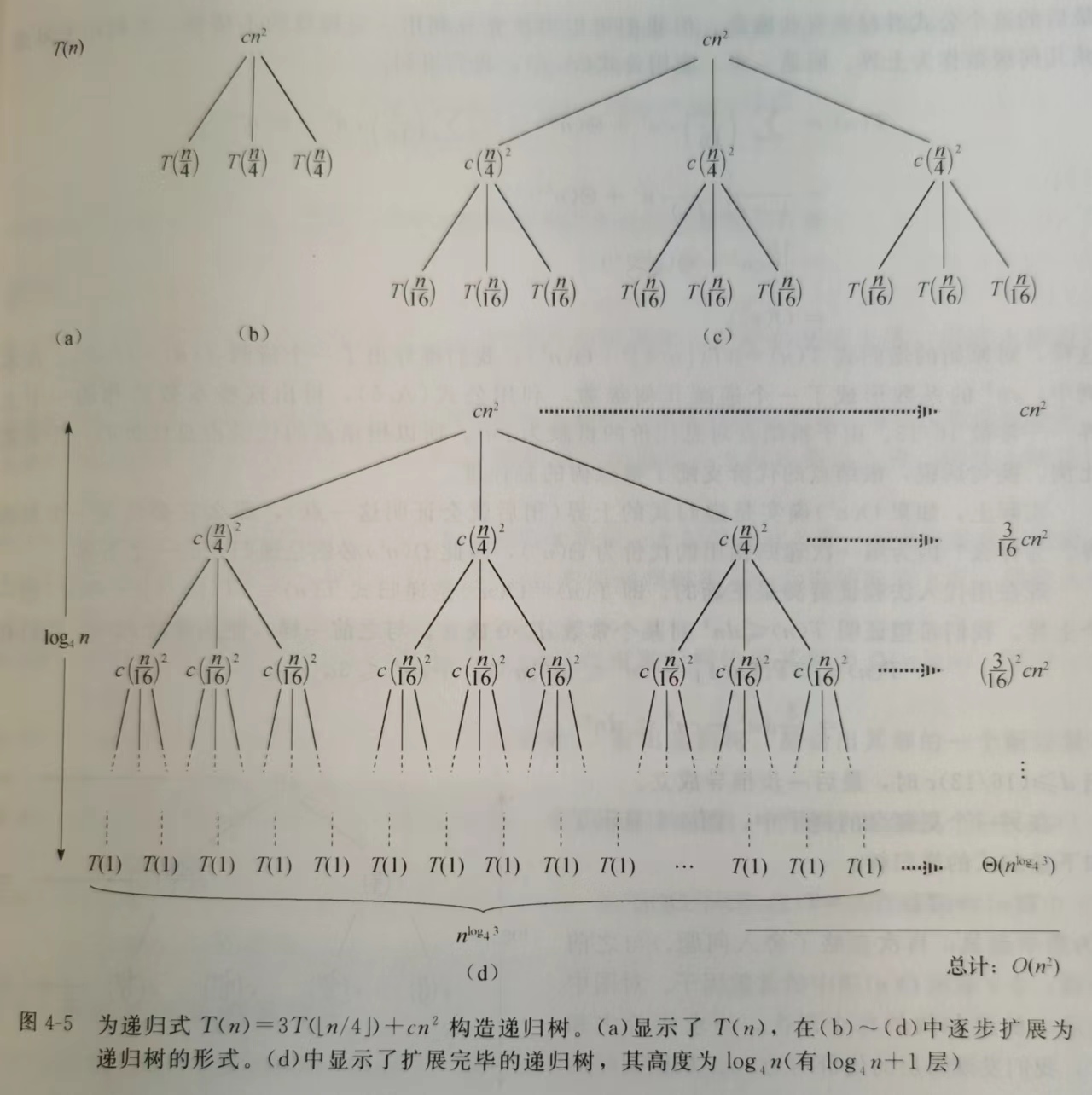
递归树的深度:从根到叶的最长简单路径。
每一层的代价:求一层中每一个节点的代价之和。
整棵树的代价(对\(T(n)\)作渐进分析):求所有层次的代价之和。
由此可以寻找到解的一个上界——生成了好的猜测。然后即可用代入法来验证猜测是否正确。
4.5 用主方法求解递归式
主方法为\(T(n) = aT(n/b) + f(n)\)形式的递归式提供了一种“菜谱”式的求解方法。
上述递归式描述的是这样的一种算法的运行时间:
- 它将规模为\(n\)的问题分解为\(a\)个子问题,每个子问题的规模为\(n/b\),其中\(a\)和\(b\)都是正常数。
- \(a\)个子问题递归地进行求解,每个花费时间\(T(n/b)\)。
- 函数\(f(n)\)包含了问题分解和子问题解合并的代价。
从技术的正确性方面看,此递归式实际上并不是良好定义的,因为\(n/b\)可能不是整数。但其替换为\(T(\lfloor n/b\rfloor)\)或\(T(\lceil n/b\rceil)\)并不会影响递归式的渐进性质(这将在4.6节得到证明)。
主定理
定理4.1(主定理)
令\(a \geqslant 1\)和\(b > 1\)是常数,\(f(n)\)是一个函数,\(T(n)\)是定义在非负整数上的递归式:
\(T(n) = aT(n/b) + f(n)\)
其中我们将\(n/b\)解释为\(\lfloor n/b\rfloor\)或\(\lceil n/b\rceil\)。那么\(T(n)\)有如下渐近界:
- 若对某个常数\(\epsilon > 0\)有\(f(n) = O(n^{log_b{a} - \epsilon})\),则\(T(n) = \Theta(n^{log_b{a}})\)。
- 若\(f(n) = \Theta(n^{log_b{a}})\),则\(T(n) = \Theta(n^{log_b{a}}lg{n})\)。
- 若对某个常数\(\epsilon > 0\)有\(f(n) = \Omega(n^{log_b{a} + \epsilon})\),且对某个常数\(c < 1\)和所有足够大的\(n\)有\(af(n/b) \leqslant cf(n)\)(正则),则\(T(n) = \Theta(f(n))\)。
注意:这三种情况并未覆盖\(f(n)\)的所有可能性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号