深入理解计算机系统(第3章 程序的机器级表示①)
GCC C 语言编译器以汇编代码的形式产生输出,汇编代码是机器代码的文本表示,给出程序中的每一条指令。
然后GCC调用汇编器和链接器,根据汇编代码生成计算机可以执行的机器代码。
本章基于x86-64来学习汇编代码
- 理解编译器的优化能力
- 分析代码中隐含的低效率
- 避免程序漏洞
- 了解典型的编译器在将C程序结构变换成机器代码时所做的转换
源代码与对应的汇编代码的关系通常不太容易理解,这是一种逆向工程(reverse engineering)——通过研究系统和逆向工作,来试图了解系统的创建过程。
3.1 历史观点
- 8086(1978年,29K个晶体管)
- 80286(1982年,134K个晶体管)
- i386(1985年,275K个晶体管)
- i486(1989年,1.2M个晶体管)
- Pentium(1993年,3.1M个晶体管)
- PentiumPro(1995年,5.5M个晶体管)
- Pentium/MMX(1997年,4.5M个晶体管)
- Pentium II(1997年,7M个晶体管)
- Pentium III(1999年,8.2M个晶体管)
- Pentium 4(2000年,42M个晶体管)
- Pentium 4E(2004年,125M个晶体管)
- Core 2(2006年,291M个晶体管)
- Core i7, Nehalem(2008年,781M个晶体管)
- Core i7, Sandy Bridge(201年,1.17G个晶体管)
- Core i7, Haswell(2013年,1.4G个晶体管)
以上处理器的设计都是向后兼容的——较早版本上编译的代码可以在较新的处理器上运行。
摩尔定律(Moore's Law):芯片上晶体管的数量每年都会翻一番。
3.2 程序编码
假设一个C程序,有两个文件p1.c和p2.c。我们用Unix命令行编译这些代码:
linux> gcc -Og -o p p1.c p2.c
其中编译选项-Og告诉编译器使用会生成符合原始C代码整体结构的机器代码的优化等级。(使用较高级别优化产生的代码会严重变形,以至于产生的机器代码和初始源代码之间的关系非常难以理解。因此我们会使用-Og优化作为学习工具,然后当我们增加优化级别时,再看会发生什么。实际中,从得到的程序的性能考虑,较高级别的优化被认为是较好的选择:-O1或-O2)
->预处理器->编译器->汇编器->链接器->
3.2.1 机器级代码
对于机器级编程十分重要的两种抽象:
- 指令集体系结构或指令集架构(Instruction Set Architecture, ISA)
- 虚拟地址
汇编代码表示非常接近于机器代码。与机器代码的二进制格式相比,汇编代码的主要特点是它用可读性更好的文本格式表示。
x86-64的机器代码和原始的C代码差别非常大。一些通常对C语言程序员隐藏的处理器状态都是可见的:
- 程序计数器(通常称为“PC”,在x86-64中用%rip表示)——给出将要执行的下一条指令在内存中的地址。
- 整数寄存器文件,包含16个命名的位置,分别存储64位的值。这些寄存器可以存储地址(对应于C语言的指针)或整数数据。
- 条件码寄存器,保存最近执行的算数或逻辑指令的状态信息,用来实现控制或数据流中的条件变化。(如if、while等)
- 向量寄存器,可以存放一个或多个整数或浮点数值。

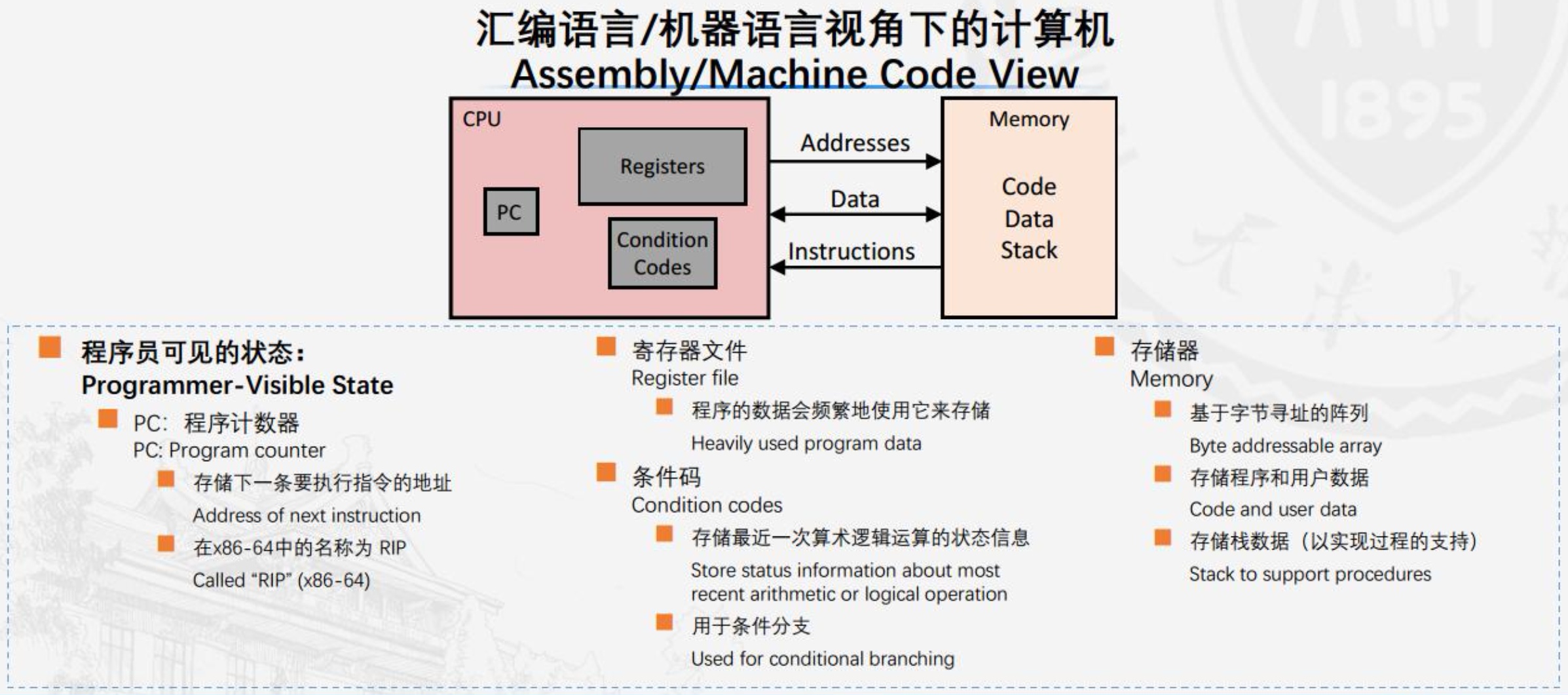
机器代码只是简单地将内存看成一个很大的、按字节寻址的数组。
程序内存包含:程序的可执行机器代码,操作系统需要的一些信息,用来管理过程调用和返回的运行时栈,以及用户分配的内存块(比如说用malloc库函数分配的)。
程序内存用虚拟地址来寻址,在任意给定的时刻,只有有限的一部分虚拟地址被认为是合法的。
操作系统负责管理虚拟地址空间,将虚拟地址翻译成实际处理器内存中的物理地址。
3.2.2 代码示例

在命令行上使用“-S”选项,使GCC运行编译器,产生以.s为后缀的汇编文件。(不会继续调用汇编器产生目标代码文件)
linux> gcc -Og -S sum.c
在命令行上使用“-c”选项,使GCC编译并汇编该代码,产生以.o目标代码文件。(二进制格式,无法直接查看)
linux> gcc -Og -c sum.c
文件sumstore.o中有一段14字节的序列,它的十六进制表示为:
53 48 89 d3 e8 00 00 00 00 48 89 03 5b c3
机器执行的程序只是一个字节序列,它是对一系列指令的编码。
要查看机器代码文件的内容,可使用反汇编器(disassembler)程序。在linux系统中,可使用带“-d”命令行标志的程序OBJDUMP(object dump)。
linux> objdump -d sum.o
结果如下,左侧将字节序列分成了若干组,每组1~5个字节,右侧是等价的汇编语言:

关于机器代码和它的反汇编表示的特性:
- x86-64的指令长度从1到15个字节不等。常用/操作数较少的指令所需的字节数少,不太常用/操作数较多的指令所需字节数较多。
- 从某个给定位置开始,可以将字节唯一地解码成机器指令。
- 反汇编器只是基于机器代码文件中的字节序列来确定汇编代码,不需要访问源代码或汇编代码。
- 反汇编器使用的指令命名规则与GCC生成的汇编代码使用的有细微差别。很多指令结尾的后缀常常可以省略。
生成实际可执行的代码需要对一组目标代码文件运行连接器,而这一组目标代码文件中必须含有一个main函数。假设在文件main.c中调用了sumstore函数。
然后用如下方法生成可执行文件prog:
linux> gcc -Og -o prog main.c sum.c
文件prog不仅包含了两个过程的代码,还包含了用来启动和终止程序的代码,以及用来与操作系统交互的代码。反汇编prog文件的结果如下:
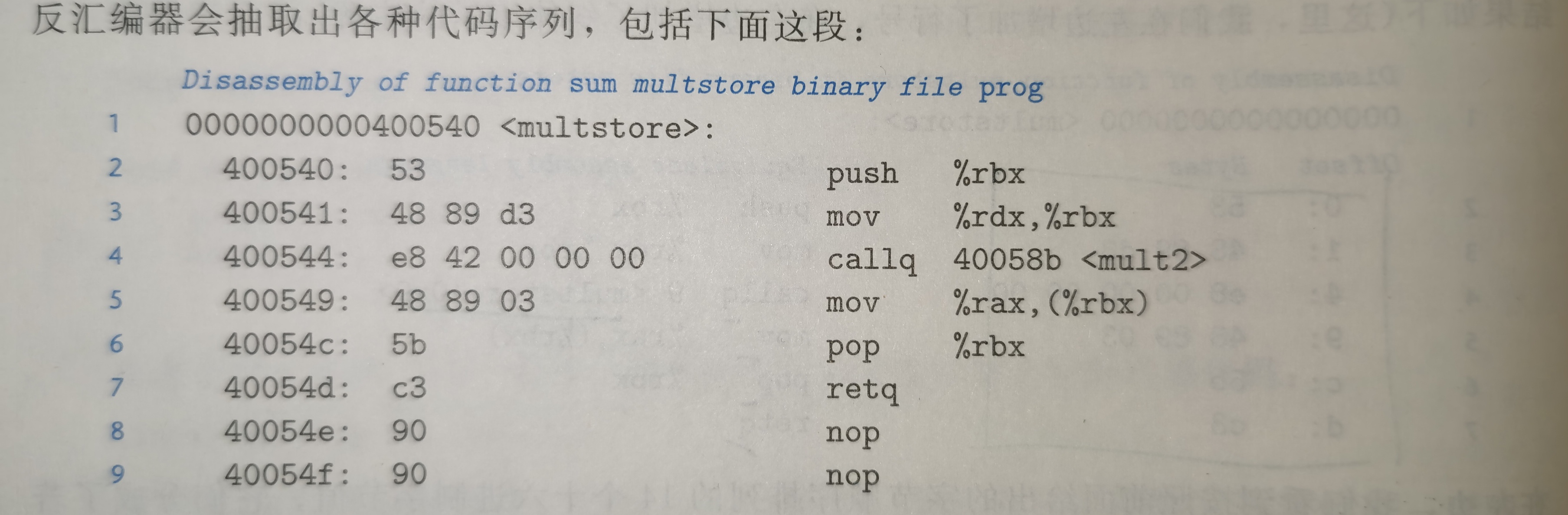
与反汇编sum.c产生的代码有如下三个区别:
- 左侧列出的地址不同(链接器将其移到了一段不同的地址范围中)。
- 链接器填上了callq指令调用函数需要使用的地址(链接器的任务之一就是为函数调用找到匹配的函数的可执行代码的位置)。
- 多了两行代码,为使函数代码变为16字节,使得就存储器系统性能而言,能更好地放置下一个代码块。
3.2.3 关于格式的注解
GCC产生的汇编代码的阅读带来以下困难:
- 它包含一些不需要关心的信息。(所有以'.'开头的行都是指导汇编器和链接器工作的伪指令)
- 它不提供任何程序的描述或它是如何工作的描述。
为了更清楚地说明汇编代码,我们省略大部分伪指令,但包括行号和解释性说明。(这是一种汇编语言程序员写代码的风格)

网络旁注
AT&T与Intel汇编代码格式

区别:
- Intel代码省略了指示大小的后缀。
- Intel代码省略了寄存器名字前的'%'符号。
- Intel代码用不同的方式来描述内存中的位置。
- 在带有多个操作数的指令的情况下,列出操作数的顺序相反。
在C语言中插入汇编代码
- 可以编写完整的函数,放进一个独立的汇编代码文件中,让汇编器和链接器把它和用C语言书写的代码合并起来。
- 可以使用GCC的内联汇编(inline assembly)特性,用asm伪指令可以在C程序中包含简短的汇编代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号