AI Agent
AI Agent
Brief
Agent的核心决策逻辑是让LLM根据动态变化的环境信息选择执行具体的行动或者对结果作出判断,并影响环境,通过多轮迭代重复执行上述步骤,直到完成目标。
精简的决策流程:P(感知)→ P(规划)→ A(行动)
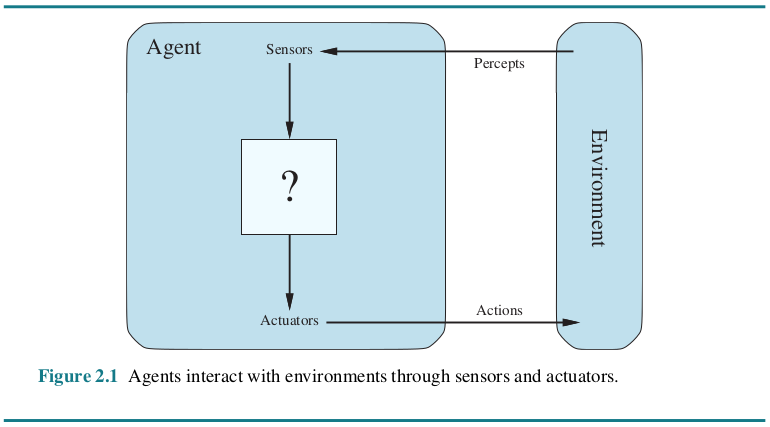
- 感知(Perception)是指Agent从环境中收集信息并从中提取相关知识的能力。 //Observation
- 规划(Planning)是指Agent为了某一目标而作出的决策过程。 //Thought
- 行动(Action)是指基于环境和规划做出的动作。
其中,Policy是Agent做出Action的核心决策,而行动又通过观察(Observation)成为进一步Perception的前提和基础,形成自主地闭环学习过程。
Complex
什么是AI Agent?
AI Agent指的是一个系统或程序,它能够通过设计工作流程和利用可用工具,自主地代表用户或其他系统执行任务。
除自然语言处理功能外,AI Agent还可涵盖决策、解决问题、与外部环境交互和执行操作等多种功能。这些代理可以部署在各种应用中,以解决各种企业环境下的复杂任务,从软件设计和IT自动化到代码生成工具和对话助手。它们利用大型语言模型(LLM)的先进自然语言处理技术,逐步理解和响应用户输入,并确定何时调用外部工具。
AI Agent如何工作?
AI Agent的核心是大语言模型(LLM)。因此,AI Agent通常被称为LLM Agent。
传统的LLM根据用于训练它们的数据生成响应,并受到知识和推理的限制。相比之下,Agent技术利用后台工具调用来获取最新信息、优化工作流程并自主创建子任务,从而实现复杂的目标。在此过程中,Agent会逐渐学会适应用户的期望。这种工具调用可以在没有人工干预的情况下实现,并拓宽了这些人工智能系统在现实世界中应用的可能性。AI Agent为实现用户设定的目标而采取的方法包括以下三个阶段:
- goal initialization and planning
根据用户的目标和Agent的可用工具,AI Agent进行任务分解,以提高性能。从本质上讲,AI Agent创建了一个由具体任务和子任务组成的计划,以完成复杂的目标。 - reasoning using available tools
AI Agent根据自己感知到的信息采取行动。通常情况下,AI Agent不具备处理复杂目标中所有子任务所需的全部知识库。为了解决这个问题,AI Agent会使用现有的工具。这些工具包括外部数据集、网络搜索、应用程序接口甚至其他Agent。从这些工具中检索到缺失的信息后,Agent就可以更新其知识库。这意味着,在每一步行动中,Agent都会重新评估其行动计划并进行自我修正。 - learning and reflection
AI Agent利用反馈机制,如其他AI Agent和human-in-the-loop(HITL),来提高其反应的准确性。
在Agent形成对用户的响应后,Agent会将学习到的信息与用户的反馈一起存储起来,以提高性能并根据用户的偏好调整未来的目标。如果使用了其他Agent来实现目标,也可以使用它们的反馈。多智能体反馈对于减少人类用户提供指导的时间尤为有用。不过,用户也可以在Agent的整个行动和内部推理过程中提供反馈,使结果与预期目标更加一致。反馈机制可以改进Agent的推理能力和准确性,这通常被称为迭代改进。为了避免重复同样的错误,AI Agent还可以在知识库中存储有关以前障碍的解决方案的数据。
基于智能体的AI chatbot
- 普通人工智能聊天机器人没有可用的工具、记忆和推理能力。它们只能实现短期目标,无法提前规划。
它需要用户持续输入信息才能做出回应。它们可以对常见的提示做出回应,这些回应很可能与用户的期望一致,但对于用户及其数据所特有的问题却表现不佳。由于这些聊天机器人没有记忆,如果回复不理想,它们就无法从错误中吸取教训。 - 相比之下,基于Agent的人工智能聊天机器人会随着时间的推移学会适应用户的期望,提供更个性化的体验和更全面的回复。它们可以在没有人工干预的情况下创建子任务,并考虑不同的计划,从而完成复杂的任务。这些计划还可以根据需要进行自我修正和更新。基于Agent的人工智能聊天机器人与普通聊天机器人不同,它们会对工具进行评估,并利用现有资源填补信息空白。
推理范式
AI Agent的构建没有统一的标准架构。有几种范式可用于解决多步骤问题。
ReAct(Reasoning And Acting)
利用这种范式,我们可以指导Agent首先进行think和plan,然后再决定使用哪些工具,并对响应进行迭代改进。通过这些 Think-Act-Observe的循环来逐步解决问题。通过提示词结构,可以指示Agent慢慢推理,并显示每次的“思考”。在这一框架中,Agent会不断用新的推理更新其上下文。这可以解释为一种Chain-of-Thought(COT)提示形式。
ReWOO(Reasoning WithOut Observation)
ReWOO方法与ReAct不同,它消除了行动规划对工具输出的依赖。取而代之的是,Agent进行前期规划。在收到用户的初始提示后,Agent就会预测要使用哪些工具,从而避免重复使用工具。 从以人为本的角度来看,这种做法是可取的,因为用户可以在计划执行前对其进行确认。ReWOO的工作流程由三个模块组成。
- 计划模块中,Agent根据用户的提示预测下一步操作。
- 第二阶段需要收集调用这些工具产生的输出结果。
- 最后,Agent将初始计划与工具输出配对,以制定响应。这种提前规划的做法可以大大减少token的使用,降低计算复杂度,并减少中间工具失效造成的影响。
AI Agent的类型
AI Agent可以开发出不同级别的能力。对于简单的目标,可以选择简单的Agent,以限制不必要的计算复杂性。从最简单到最先进,主要有5种类型:
Simple reflex agents
- 根据当前感知采取行动。
- 不拥有任何记忆,如果缺少信息,也不会与其他代理互动。
- 根据一组所谓的条件反射或规则发挥作用。(preprogrammed)
- 只在完全可观察、可获取所有必要信息的环境中有效。
例子:自动调温器每晚在设定时间打开供暖系统。例如,这里的条件动作规则是,如果是晚上8点,则启动供暖系统。
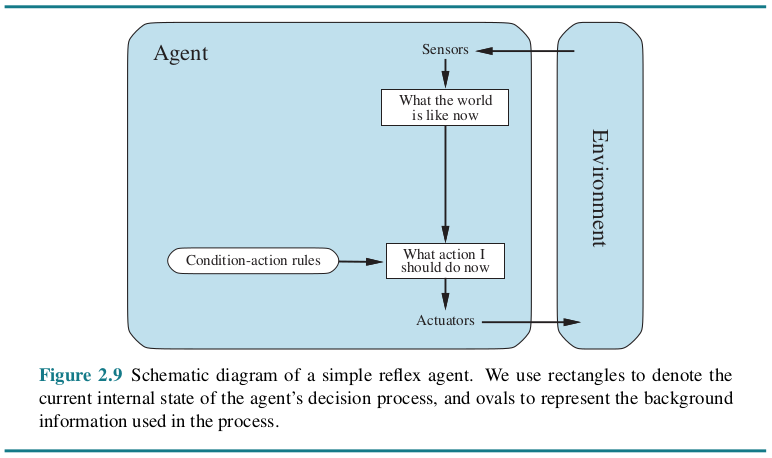
Model-based reflex agents
- 利用当前的感知和记忆来维持世界的内部模型。随着不断接收新信息,模型也会随之更新。
- 行动取决于其模型、条件反射、先前的概念和当前状态。
- 与前者相比,可以在记忆中存储信息,并能在部分可观察和不断变化的环境中运作。但是,仍然受到其规则集的限制。
例子:机器人吸尘器。当它清洁一个肮脏的房间时,它会感知家具等障碍物,并围绕它们进行调整。机器人还会存储一个已清洁区域的模型,以免陷入重复清洁的怪圈。
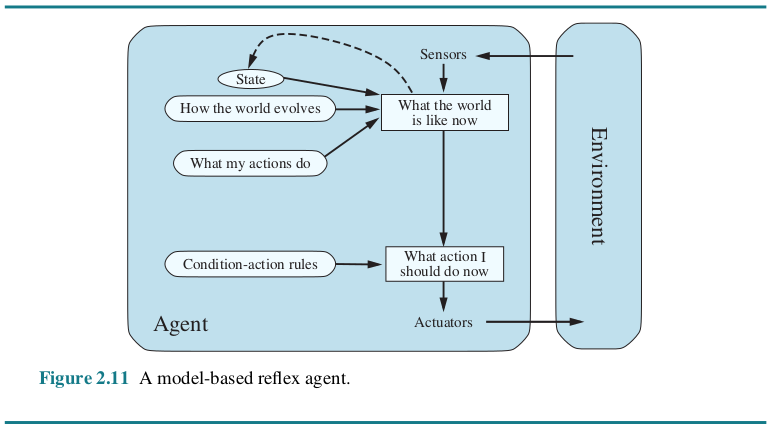
Goal-based agents
- 除了内部模型之外,还有一个或一组目标。
- Agent寻找能达到目标的行动序列,并在行动之前对这些行动进行规划。
- 与前者相比,这种搜索和规划提高了效率。
例子:导航系统可为用户推荐到达目的地的最快路线。该模型会考虑到达目的地的各种路线,换句话说,也就是目标。(在这个例子中,规则规定,如果找到一条更快的路线,Agent就会推荐这条路线。)
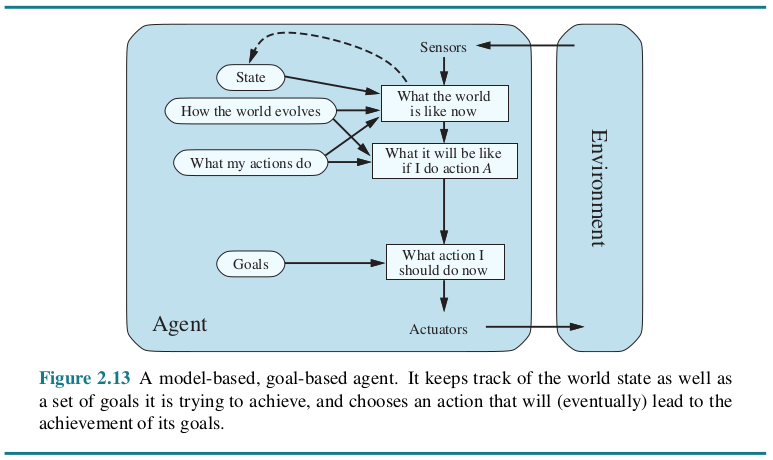
Utility-based agents
- Agent选择的行动序列除了能达到目标之外,还能能使效用或回报(reward)最大化。(效用通过效用函数来计算。该函数根据一组固定标准为每种方案分配一个效用值,即衡量行动有用性或行动会让Agent“快乐”到什么程度的指标。这些标准可以包括实现目标的进度、时间要求或计算复杂度等因素。)
- 选择能使预期效用最大化的行动。
例子:导航系统会向你推荐一条通往目的地的路线,这条路线既能优化燃油效率,又能最大限度地减少堵车时间和过路费用等等。(假设Agent通过这组标准来衡量效用,从而选择最有利的路线。)
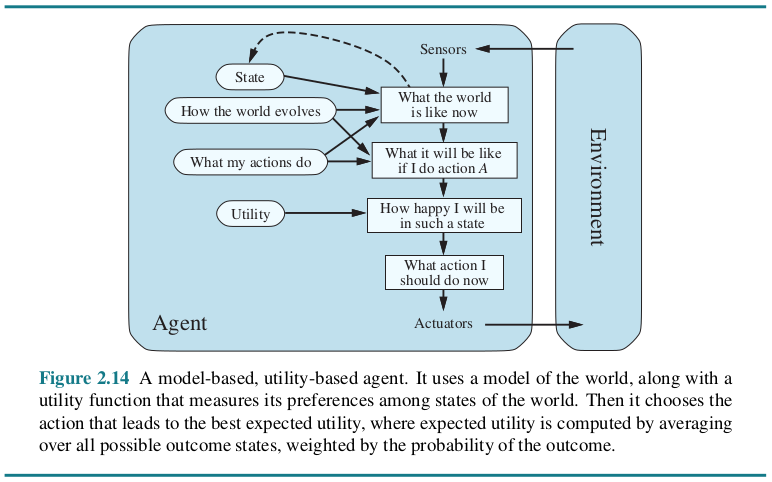
Learning agents
除了上述Agent拥有的能力之外,还有着独一无二的学习能力。——新的经验会被Agent自主地添加到它们的初始知识库中。这种学习增强了Agent在陌生环境中工作的能力。
学习型Agent的推理可能是基于效用或目标的,由四个主要元素组成:
- learning:通过环境中的规则和传感器学习环境中的知识,从而提高Agent的知识水平。
- critic:向Agent提供反馈,说明其响应的质量是否符合性能标准。
- performance:该元素负责基于学习的结果选择action。
- problem generator:它为将要采取的action提出各种建议。
例子:电子商务网站上的个性化推荐。这些Agent会在记忆中跟踪用户的活动和偏好。这些信息被用来向用户推荐某些产品和服务。每次做出新的推荐时,都会重复这样的循环。出于学习目的,用户的活动会被持续存储。这样,Agent就能不断提高其准确性。
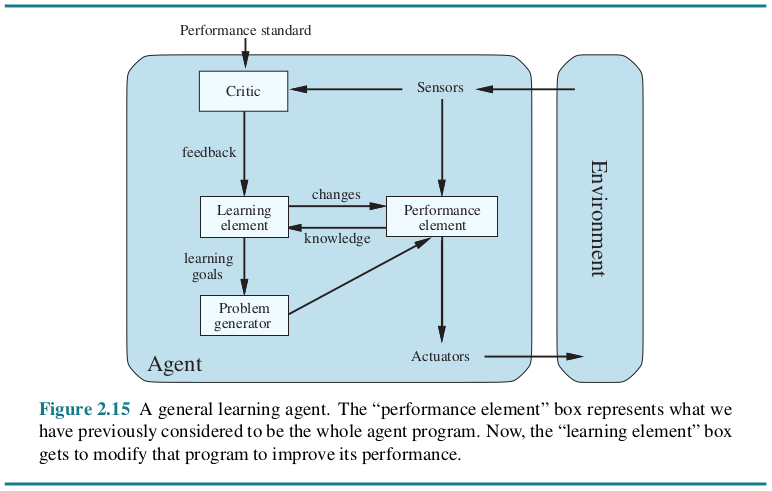
工程实现
Agent = LLM+Planning+Feedback+Tool use
工程实现上可以拆分出四大块核心模块:推理、记忆、工具、行动
AI Agent的应用
客户体验
AI Agent可以集成到网站和应用程序中,通过充当虚拟助理、提供心理健康支持、模拟面试和其他相关任务来提升客户体验。有许多无代码模板可供用户实施,使创建这些AI Agent的过程更加简单。
医疗保健
AI Agent可用于现实世界中的各种医疗保健应用。Multi-Agent系统尤其适用于在此类环境中解决问题。从为急诊科病人制定治疗计划到管理药物流程,这些系统都能节省医疗专业人员的时间和精力,使他们能够完成更紧急的任务。
应急响应
在发生自然灾害时,AI Agent可以利用深度学习算法检索社交媒体网站上需要救援的用户信息。这些用户的位置可以绘制成地图,协助救援部门在更短的时间内救出更多的人。因此,无论是在琐碎的任务中还是在拯救生命的情况下,AI Agent都能极大地造福人类生活。
优势
- 任务自动化——低成本、快速、大规模地实现目标
- 更高的性能——Multi-Agent > Single-Agent(单个Agent如果能从其他擅长相关领域的Agent那里获得知识和反馈,将有助于信息合成。这种后台协作和填补信息空白的能力是Agent框架所独有的。)
- 响应质量——为用户提供的响应更全面、更准确、更个性化。
挑战和限制
- Multi-Agent依赖性——在实现Multi-Agent框架时,存在发生故障的风险。建立在相同基础模型上的Multi-Agent系统可能会遇到共同的缺陷。这些缺陷可能会导致所有相关Agent出现全系统故障,或暴露出易受不利攻击的弱点。(数据治理data governance)
- 无限的反馈循环——AI Agent如果无法制定全面的计划或对其发现进行反思,就会发现自己在重复调用相同的工具,从而引发无限的反馈循环。(实时人工监控real-time human monitoring)
- 计算复杂性——从零开始构筑AI Agent既耗时,计算成本也可能非常高昂。训练一个高性能Agent可能需要大量资源。此外,根据任务的复杂程度,Agent可能需要数天才能完成任务。
一些好的做法
- 活动日志
为解决Multi-Agent依赖问题,开发人员可向用户提供Agent的行动日志。这种透明度能让用户深入了解迭代决策过程,提供发现错误的机会。 - 中断
防止AI Agent运行时间过长。尤其是在出现意外的无限反馈循环、某些工具的访问权限发生变化或因设计缺陷而出现故障的情况下。实现这一目标的方法之一是实现可中断性。
选择是否以及何时中断Agent需要深思熟虑,因为某些终止可能弊大于利。例如,在危及生命的紧急情况下,让有故障的Agent继续提供协助可能比完全关闭它更安全。 - 独特的标识符
为了降低Agent系统被恶意使用的风险,可以使用独特的标识符。如果要Agent访问外部系统时必须使用这些标识符,就可以更容易地追踪Agent的开发者、部署者及其用户的来源。如果出现恶意使用Agent或Agent造成意外伤害的情况,这将特别有帮助。 - 人工监督
为了在Agent的学习过程中进行协助,特别是在新环境中的早期阶段,偶尔提供人工反馈可能会有所帮助。这可以让Agent将其表现与预期标准进行比较,并做出相应调整。这种形式的反馈有助于提高Agent对用户偏好的适应性。
除此之外,最好的做法是在Agent采取具有重大影响的行动之前,先征得人类的同意。例如,从群发电子邮件到金融交易等行为都需要人类的确认。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号