A TL Strategy for Improving the Data Efficiency of DRL Control
Paper1
A Transfer Learning Strategy for Improving the Data Efficiency of Deep Reinforcement Learning Control in Smart Buildings: https://ieeexplore.ieee.org/document/10454120
Motivation
- RL算法需要大量数据用于学习,我们需要提高训练和数据利用的效率。
- TL方法是一种利用从源任务中学习到的知识来使目标任务受益的方法。(举一反三)
Challenge
迄今为止,TL方法主要用于监督学习中,而监督学习中的数据是静态的,强化学习中的数据通常与时间相关,取决于智能体先前选择的动作。TL方法在强化学习中的应用更具挑战性,因为问题被表述为马尔可夫决策过程,这是一个随机过程。
Method
采用了一个名为Yarnell Station House的研究房屋的模型来训练和测试所提出的方法。
- 通过在源模型的参数中添加随机噪声,建模生成10座不同的建筑物,又生成了10个模型。
- 使用DQN算法为每个模型训练一个单独的RL智能体。
- 从10个预训练的RL智能体到源模型的RL智能体进行迁移学习。
- 性能评估。
Algorithm
DQN

Student Distillation
在RL任务背景下,Student Distillation方法可以描述为训练一个智能体(即学生)模仿多个智能体(即教师)的行为。该方法的目标是将学到的策略从教师转移到学生身上。这种迁移使学生从许多更好的策略中学习。——简而言之,学生的策略\(\pi\)是通过向这些老师学习从而提炼出来的。
Evaluation
在HVAC控制任务中测试了所提出的TL方法,并将TL方法与三个传统控制器进行了比较。结果表明,所提出的TL方法可以达到与离线部署相当的累积奖励,且性能明显优于其他两种控制器。
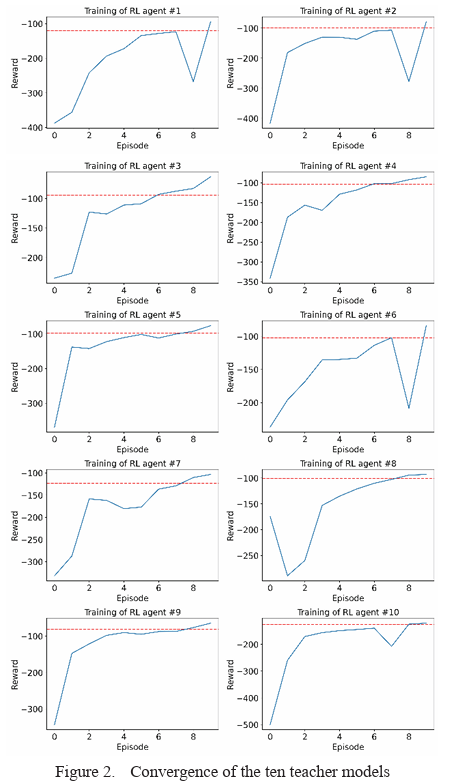
Convergence of the DQN Training
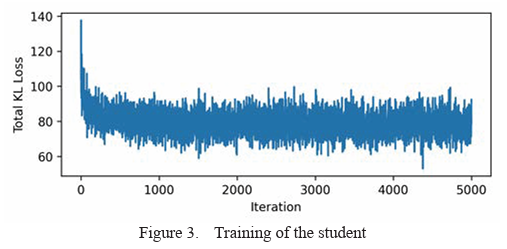
Policy Distillation
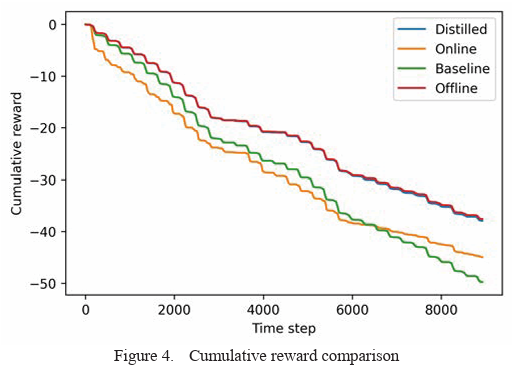
Conclusion
该文章提出了一种迁移学习方法,通过减少数据需求来提高RL算法的效率。结果表明,提出的迁移学习方法是一种很有前途的方法,可以利用类似的强化学习任务的信息,从而强化学习训练中的数据需求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号