
转:《链接、装载与库》里的一个错误:关于调用栈
《链接、装载与库》里的一个错误:关于调用栈
按照原文中描述做了一个PPT:

每次执行push指令时,esp都会减4(因为栈是向低地址增长的),每次pop时esp都会加4。
指令:push a

指令:push b

指令:
1.把main方法当前指令的下一条指定地址(即return address))push到栈中。
2.使用call指令调用目标函数体。

指令:将ebp的当前值push到栈中,即saved ebp。

指令:将esp的值赋给ebp,则意味着进入了foo方法的调用栈。

指令:push c

指令:pop c

指令:将ebp的值赋给esp,意味着恢复foo调用时的栈顶。(这一句和之前没什么区别,具体不太懂?pop以后esp自然就和ebp一样了,懂得人可以给解答么?)
图片同上
指令:将栈顶的值赋给ebp(pop esp),即恢复main调用栈的栈底。 (原文写的是pop ebp,我认为是笔误)

指令:ret,根据esp的位置,即栈顶获得之前保留的return address,继续执行。

如果在foo方法中需要访问那些参数,则需要根据当前ebp中的值,再向高地址偏移后进行访问——因为高地址才是main方法的调用栈。也就是说,地址ebp + 8存放了foo方法的第1个参数,地址ebp + 12存放了foo方法的第2个参数,以此类推。那么地址ebp + 4存放了什么呢?它存放的是return address,即foo方法返回后,需要继续执行下去的main方法指令的地址。
/////////////////////////////// 以下是原文 ////////////////////////////////////
周六老同学聚会,出门前随手从桌上抓起了《程序员的自我修养——链接、装载与库》在路上翻。自从武汉博文出版社的周筠老师送给我这本书后,我基本上还没怎么看过。对这本书第一感觉是“标题党”,主标题起大了,虽然经过解释之后并非无法理解,但还是不太喜欢。但书还是好书,已经看完大半,而且基本上会在近期找个方式推荐一把。不过现在我想细说的并不是推荐相关话题(如适合谁看,该怎么看,结合什么一起看等等),而是想指出书中还未被《勘误》收录的一个错误:P288讲调用栈时,文字描述和配图上的问题。
什么是调用栈呢?这里的“栈”和平时我们谈论的数据结构“栈”关系并不大。数据结构里的“栈”是一种先进后出的容器,日常生活中我们经常使用叠在一起的盘子进行类比。而计算机系统中的“栈”是一种有类似行为的内存区域,每次“压”进去和“弹”出来的都是数据。而这块内存区域,是在CPU进行过程调用时所“形成”,或者说是“使用”。与常见高级语言中的“方法”、“函数”不同,这里的“过程”并不是一种高级的抽象,它是CPU可以识别的概念,它的调用自有call指令与之应对。
那么这个“栈”又是什么形态的呢?它是“从高地址向低地址”扩展的一块区域,使用ebp和esp分别作为单个过程的调用栈的栈底和栈顶:
0xFFFFFFFF
| |
| | 高地址
| |
...
| |
| |
-------------------------
| |
| | 前一个过程的调用栈
| |
------------------------- <-- 当前ebp(栈底)
| |
| | 当前过程的调用栈
| |
------------------------- <-- 当前esp(栈顶)
| |
| |
...
| |
| | 低地址
| |
0x00000000
以上是在32位体系结构中的内存地址示意图。每次执行push指令时,esp都会减4(因为栈是向低地址增长的),每次pop时esp都会加4。当方法main需要调用foo时,它的标准形式为:
- 在main方法的调用栈中,将foo的参数push到栈中。
- 把main方法当前指令的下一条指定地址(即return address))push到栈中。
- 使用call指令调用目标函数体。
请注意,以上3步都处于main的调用栈,其中ebp保存其栈底,而esp保存其栈顶。而在foo方法body的标准形式为:
- 将ebp的当前值push到栈中,即saved ebp。
- 将esp的值赋给ebp,则意味着进入了foo方法的调用栈。
- 剩下的便是根据需要,保存(push)一些寄存器的值,或是计算过程中所需要的临时变量等等。
而在foo方法调用完毕后,便执行前面阶段的逆操作:
- 恢复(pop)一些寄存器的值。
- 将ebp的值赋给esp,意味着恢复foo调用时的栈顶。
- 将栈顶的值赋给ebp(pop ebp),即恢复main调用栈的栈底。
- ret,根据esp的位置,即栈顶获得之前保留的return address,继续执行。
可见,main方法先将foo方法所需的参数压入栈中,然后再改变ebp,进入foo方法的调用栈。因此,如果在foo方法中需要访问那些参数,则需要根据当前ebp中的值,再向高地址偏移后进行访问——因为高地址才是main方法的调用栈。也就是说,地址ebp + 8存放了foo方法的第1个参数,地址ebp + 12存放了foo方法的第2个参数,以此类推。那么地址ebp + 4存放了什么呢?它存放的是return address,即foo方法返回后,需要继续执行下去的main方法指令的地址。在著名的CSAPP中有这么一幅图,具体地展示了这一切:
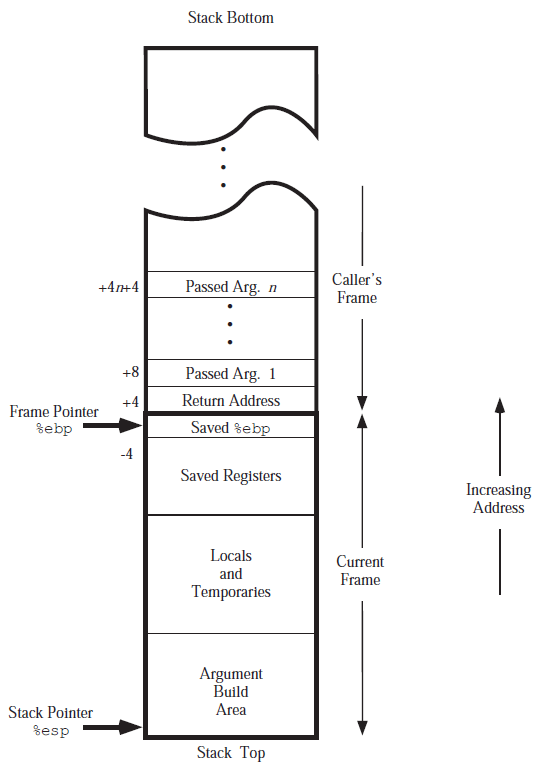
可惜,书中P228却是这样写的:
在参数之后的数据(包括参数)即使当前函数的活动记录,ebp固定在图中所示的位置,不随这个函数的执行而变化,相反地,esp始终指向栈顶,因此随着函数的执行,esp会不断变化。固定不变的ebp可以用来定位函数活动记录的各个数据。在ebp之前首先是这个函数的返回地址,它的地址是ebp - 4,再往前是压入栈中的参数,它们的地址分别是ebp - 8、ebp - 12等,视参数数量和大小而定……
虽然书中的描述正确,但ebp + 4,ebp + 8,ebp + 12等地址都被错误的写成了ebp - 4,ebp - 8,ebp - 12。我估计这可能是由于栈是“从高地址向低地址扩充”的,此时的“之前”应该是“加”而不是“减”的缘故吧。这点的确不太符合人们“从小到大”的计数习惯,一时疏忽容易造成差错。此外,我认为书中配套的这幅示意图,似乎也有一些问题——至少不太妥当。如下:

在这幅图中,ebp的指针指向old (saved) ebp和return address之间,那么ebp地址究竟算是保存了什么值呢?正确说来,ebp地址中保存的应该是old ebp,也就是说,在这幅图中“取值”是由高地址向低地址进行的——这不太自然。而更容易产生“歧义”的是,esp的指针指向了整个“活动记录”的最底部,这给人的感觉似乎是,如果谈起“esp”地址保存的值,则应该向“高地址”来获取(因为“低地址”已经没了)。这就和ebp产生矛盾了。可能正因为如此,我看这幅示意图时总觉得有些别扭,虽然我的确可以将ebp理解为“向下”取值,但总还是想着将ebp往下“掰一格”,使其和esp的方向“感觉上”保持统一。那么更好的做法是什么呢?个人认为,最不会产生歧义的方式,是像CSAPP那样(即前面的那幅图),将指针直接指向某个内存“块”,而不是某个“边界”。
最后还有一个“问题”,那便是“Stack Frame”,即书中的“活动记录”的范围究竟是什么。在CSAPP中,一个Stack Frame是从ebp开始到esp范围的这块内存区域,但《链接》一书却认为它是从方法调用的参数开始到esp。这个区别从上面两幅图中也可以看出。我不知道孰对孰错,但是书中写的很清楚,因此这里肯定不是疏忽。我怀疑是不是“流派”之间的差异所致
虽然《链接、装载与库》中有这么一个小问题,但瑕不掩瑜,它仍然是国内难得踏实的技术书籍。而且,这本书的作者“余甲子”是2006年在读研一的“同学”——所以我经常说,总有一些牛人让我汗颜。此话真的不假。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号