
转:c++内存分配
第一篇:
http://my.oschina.net/pollybl1255/blog/140323
BSS段:(bss segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。
例如:
#include <stdio.h>
int g1=0, g2=0, g3=0;
int max(int i)
{
int m1=0,m2,m3=0,*p_max;
static n1_max=0,n2_max,n3_max=0;
p_max = (int*)malloc(10);
printf("打印max程序地址\n");
printf("in max: 0x%08x\n\n",max);
printf("打印max传入参数地址\n");
printf("in max: 0x%08x\n\n",&i);
printf("打印max函数中静态变量地址\n");
printf("0x%08x\n",&n1_max); //打印各本地变量的内存地址
printf("0x%08x\n",&n2_max);
printf("0x%08x\n\n",&n3_max);
printf("打印max函数中局部变量地址\n");
printf("0x%08x\n",&m1); //打印各本地变量的内存地址
printf("0x%08x\n",&m2);
printf("0x%08x\n\n",&m3);
printf("打印max函数中malloc分配地址\n");
printf("0x%08x\n\n",p_max); //打印各本地变量的内存地址
if(i) return 1;
else return 0;
}
int main(int argc, char **argv)
{
static int s1=0, s2, s3=0;
int v1=0, v2, v3=0;
int *p;
p = (int*)malloc(10);
printf("打印各全局变量(已初始化)的内存地址\n");
printf("0x%08x\n",&g1); //打印各全局变量的内存地址
printf("0x%08x\n",&g2);
printf("0x%08x\n\n",&g3);
printf("======================\n");
printf("打印程序初始程序main地址\n");
printf("main: 0x%08x\n\n", main);
printf("打印主参地址\n");
printf("argv: 0x%08x\n\n",argv);
printf("打印各静态变量的内存地址\n");
printf("0x%08x\n",&s1); //打印各静态变量的内存地址
printf("0x%08x\n",&s2);
printf("0x%08x\n\n",&s3);
printf("打印各局部变量的内存地址\n");
printf("0x%08x\n",&v1); //打印各本地变量的内存地址
printf("0x%08x\n",&v2);
printf("0x%08x\n\n",&v3);
printf("打印malloc分配的堆地址\n");
printf("malloc: 0x%08x\n\n",p);
printf("======================\n");
max(v1);
printf("======================\n");
printf("打印子函数起始地址\n");
printf("max: 0x%08x\n\n",max);
return 0;
}
打印结果:
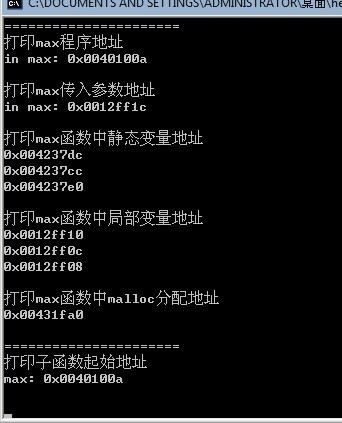
可以大致查看整个程序在内存中的分配情况:
可以看出,传入的参数,局部变量,都是在栈顶分布,随着子函数的增多而向下增长.
函数的调用地址(函数运行代码),全局变量,静态变量都是在分配内存的低部存在,而malloc分配的堆则存在于这些内存之上,并向上生长.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
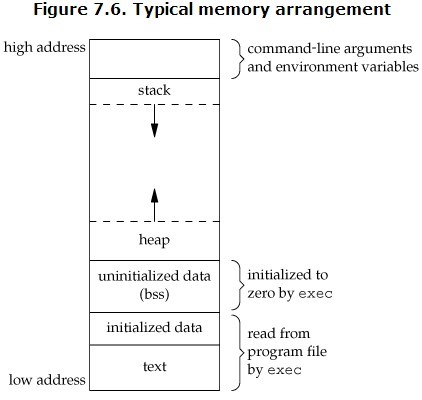
在操作系统中,一个进程就是处于执行期的程序(当然包括系统资源),实际上正在执行的程序代码的活标本。那么进程的逻辑地址空间是如何划分的呢?
引用:
图1做了简单的说明(Linux系统下的)
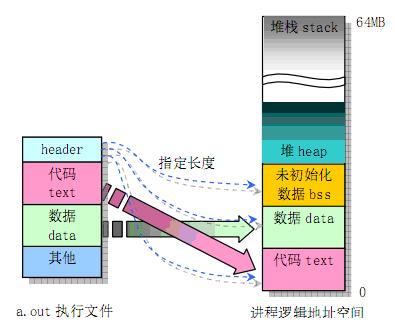
左边的是UNIX/LINUX系统的执行文件,右边是对应进程逻辑地址空间的划分情况。
首先是堆栈区(stack),堆栈是由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。栈的申请是由系统自动分配,如在函数内部申请一个局部变量 int h,同时判别所申请空间是否小于栈的剩余空间,如若小于的话,在堆栈中为其开辟空间,为程序提供内存,否则将报异常提示栈溢出。
其次是堆(heap),堆一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。堆的申请是由程序员自己来操作的,在C中使用malloc函数,而C++中使用new运算符,但是堆的申请过程比较复杂:当系统收到程序的申请时,会遍历记录空闲内存地址的链表,以求寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,此处应该注意的是有些情况下,新申请的内存块的首地址记录本次分配的内存块大小,这样在delete尤其是delete[]时就能正确的释放内存空间。
接着是全局数据区(静态区) (static),全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 另外文字常量区,常量字符串就是放在这里,程序结束后有系统释放。
最后是程序代码区,放着函数体的二进制代码。
举例说明一下:
int a = 0; //全局初始化区
char *p1; //全局未初始化区
int main()
{
int b; // 栈
char s[] = "abc"; //栈
char *p2; //栈
char *p3 = "123456"; //123456\0在常量区,而p3在栈上。
static int c =0; //全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20); //分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); //123456\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
return 0;
}
第二篇:
http://blog.csdn.net/yeyuangen/article/details/6766567
1.函数代码存放在代码段。声明的类如果从未使用,则在编译时,会优化掉,其成员函数不占代码段空间。
全局变量或静态变量,放在数据段,
局部变量放在栈中,
用new产生的对象放在堆中,
内存分为4段,栈区,堆区,代码区,全局变量区
BSS段:BSS段(bss segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。
BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。
2.代码段、数据段、栈是CPU级别的逻辑概念,堆是语言级别的逻辑概念
3.还有一个常量区,其中的内容不许修改。
常见的 char *p = "hello"; 这里面的"hello"就保存在常量区
4.如1楼所说,把代码段、数据段,栈,堆这些并列在一起不太合适
代码段、数据段、堆栈段,这是一个概念
堆、栈、全局区、常量区,这是另一个概念
5.STACK(栈)临时局部
HEAP(堆)动态
RW(读写)全局
RO(只读)代码
Char* s=”Hello,World”; S中“H”存放在内存RO中且不能修改。
6.CPU寄存器:CPU寄存器,其实就是来控制代码段和数据段的指令及数据读取的地方,当然,CPU也有自己存放数据的地方,那就是通用寄存器里的数据寄存器,通常是EDX寄存器,C语言里有个register,就是把数据放在这个寄存器里,这样读取数据就相当的快了,因为不用去内存找,就省去了寻址和传送数据的时间开销。他还有一些寄存器是用来指示当前代码段的位置、数据段的位置、堆栈段的位置等等(注意这里存放的只是相应的代码或数据在内存中的地址,并不是实际的值,然后根据这个地址,通过地址总线和数据总线,去内存中获取相应的值),不然在执行代码的时候,指令和数据从哪取呢?呵呵。。。他里面还有标志寄存器,用来标识一些状态位,比如标识算术溢出呀等等。。。。。
————————————————————————————————————————————————————————————————
内存分段(笔记)
在冯诺依曼的体系结构中必须有:代码段,堆栈段,数据段
因为冯氏结构,本质就是取址,执行的过程
编译器和系统在为变量分配是从高地址开始分配的.
全局变量和函数参数在内存中的存储是由低地值到高地址的.
函数参数为什么会放到堆区呢?
这是因为我们的函数是在程序运行中进行动态的调用的.
在函数的编译阶段根本无法确定他会调用几次,会需要多少内存.
即使可以确定那时候就为变量分配好内存着实也是一种浪费。
所以编译器为函数参数选择动态的分配..即在每次调用函数时才为它动态的进行分配空间.
####################################################
内存分为4段,栈区,堆区,代码区,全局变量区
BSS段:BSS段(bss segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域。
BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。
数据段:数据段(data segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
代码段:代码段(code segment/text segment)通常是指用来存放程序执行代码的一块内存区域。
这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。
在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。代码段是存放了程序代码的数据,
假如机器中有数个进程运行相同的一个程序,那么它们就可以使用同一个代码段。
堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,
可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);
当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
栈(stack):栈又称堆栈, 是用户存放程序临时创建的局部变量,
也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。
除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。
由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
(1)内存分段和内存分页一样都是一种内存管理技术,分段:权限保护,分页:虚拟内存.
(2)分段后,程序员可以定义自己的段,各段有独立的地址空间,象进程的地址空间互相独立一样.
(3)同一个类的实例分配在一个段中,只有该类的方法可以访问,如果其他类的方法去访问,会因为段保护而出错.可以从硬件上实现类的数据保护和隐藏
####################################################################
分段好处:
cpu中的段寄存器-------段址(base)和偏移值的上限(limit)。
段址:有效地址 中,如果有效地址大于limit,便会引发异常。这样就可以限制程序不能范围当前段外的数据,不能访问其他程序的数据。
面向对象的好处:对象就是一块连续的内存中的数据
寄存器是特殊形式的内存,嵌入到处理器内部。
每个进程需要访问内存中属于自身的区域,因此,可将内存划分成小的段,按需分发给进程。
寄存器用来存储和跟踪进程当前维护的段。偏移寄存器(Offset Registers)用来跟踪关键的数据放在段中的位置。
在进程被载入内存中时,基本上被分裂成许多小的节(section)。我们比较关注的是6个主要的节:
(1) .text 节
.text 节基本上相当于二进制可执行文件的.text部分,它包含了完成程序任务的机器指令。
该节标记为只读,如果发生写操作,会造成segmentation fault。在进程最初被加载到内存中开始,该节的大小就被固定。
(2).data 节
.data节用来存储初始化过的变量,如:int a =0 ; 该节的大小在运行时固定的。
(3).bss 节
栈下节(below stack section ,即.bss)用来存储为初始化的变量,如:int a; 该节的大小在运行时固定的。
(4) 堆节
堆节(heap section)用来存储动态分配的变量,位置从内存的低地址向高地址增长。内存的分配和释放通过malloc() 和 free() 函数控制。
(5) 栈节
栈节(stack section)用来跟踪函数调用(可能是递归的),在大多数系统上从内存的高地址向低地址增长。
同时,栈这种增长方式,导致了缓冲区溢出的可能性。
(6)环境/参数节
环境/参数节(environment/arguments section)用来存储系统环境变量的一份复制文件,
进程在运行时可能需要。例如,运行中的进程,可以通过环境变量来访问路径、shell 名称、主机名等信息。
该节是可写的,因此在格式串(format string)和缓冲区溢出(buffer overflow)攻击中都可以使用该节。
另外,命令行参数也保持在该区域中。
################################################################################
以win32程序为例。
程序执行时,操作系统将exe文件映射入内存。exe文件格式为头数据和各段数据组成。
头数据说明了exe文件的属性和执行环境,段数据又分为数据段,代码段,资源段等,段的多少和位置由头数据说明。
也就是说,不仅仅只是代码段和数据段。这些段由不同的编译环境和编译参数控制,由编译器自动生成exe的段和文件格式。
当操作系统执行exe时,会动态建立堆栈段,它是动态的,并且属于操作系统执行环境。
也就是说,程序在内存的映射一个为exe文件映射,包括数据段、代码段等它是不变的。
另一个为堆栈段,它是随程序运行动态改变的。
1、编译器把源代码转化成分立的目标代码(.o或者.obj)文件,这些文件中的代码已经是可执行的机器码或者是中间代码。
但是其中变量等事物的地址只是一些符号。
2、接下来是通过链接器处理这些目标代码,主要目的就是把分立的目标代码连接成一份完整的可执行代码,
并将其中的地址符号换成相对地址。如果这时候产生错误,我们就可以得到一份地址符号列表,而不是变量列表。
3、执行程序的时候操作系统分配足够的内存空间,建立好系统支撑结构后把二进制可执行代码读入内存中。
在读入过程中内存首址就成了程序的“绝对地址”(实际上还是相对地址,不过是操作系统里的相对地址了)。
于是绝对地址+相对地址(就是偏移量)就得到了变量的地址。
因此,CS的值是由系统填入的,而其它S寄存器的值则是根据程序代码中附加的信息计算后得到的。
第三篇:
http://www.cnblogs.com/daocaoren/archive/2011/06/29/2092957.html
栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。在一个进程中,位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用。和堆一样,用户栈在程序执行期间可以动态地扩展和收缩。
堆,就是那些由 new 分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个 new 就要对应一个 delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。堆可以动态地扩展和收缩。
自由存储区,就是那些由 malloc 等分配的内存块,他和堆是十分相似的,不过它是用 free 来结束自己的生命的。
全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的 C 语言中,全局变量又分为初始化的和未初始化的(初始化的全局变量和静态变量在一块区域,未初始化的全局变量与静态变量在相邻的另一块区域,同时未被初始化的对象存储区可以通过 void* 来访问和操纵,程序结束后由系统自行释放),在 C++ 里面没有这个区分了,他们共同占用同一块内存区。
常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改,而且方法很多)
明确区分堆与栈
在 BBS 上,堆与栈的区分问题,似乎是一个永恒的话题,由此可见,初学者对此往往是混淆不清的,所以我决定拿他第一个开刀。
首先,我们举一个例子:
这条短短的一句话就包含了堆与栈,看到 new,我们首先就应该想到,我们分配了一块堆内存,那么指针 p 呢?他分配的是一块栈内存,所以这句话的意思就是:在栈内存中存放了一个指向一块堆内存的指针 p。在程序会先确定在堆中分配内存的大小,然后调用 operator new 分配内存,然后返回这块内存的首地址,放入栈中,他在 VC6 下的汇编代码如下:

0040102Acall operator new (00401060)
0040102Fadd esp,4
00401032mov dword ptr [ebp-8],eax
00401035mov eax,dword ptr [ebp-8]
00401038mov dword ptr [ebp-4],eax
这里,我们为了简单并没有释放内存,那么该怎么去释放呢?是 delete p 么?噢,错了,应该是 delete []p,这是为了告诉编译器:我删除的是一个数组,VC6 就会根据相应的 Cookie 信息去进行释放内存的工作。
好了,我们回到我们的主题:堆和栈究竟有什么区别?
主要的区别由以下几点:
1、管理方式不同;
2、空间大小不同;
3、能否产生碎片不同;
4、生长方向不同;
5、分配方式不同;
6、分配效率不同;
管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak。
空间大小:一般来讲在 32 位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在VC6下面,默认的栈空间大小是1M(好像是,记不清楚了)。当然,我们可以修改:打开工程,依次操作菜单如下:Project->Setting->Link,在 Category 中选中 Output,然后在 Reserve 中设定堆栈的最大值和 commit。注意:reserve 最小值为 4Byte;commit 是保留在虚拟内存的页文件里面,它设置的较大会使栈开辟较大的值,可能增加内存的开销和启动时间。
碎片问题:对于堆来讲,频繁的 new/delete 势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,在他弹出之前,在他上面的后进的栈内容已经被弹出,详细的可以参考数据结构,这里我们就不再一一讨论了。
生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
分配方式:堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由 malloc 函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是 C/C++ 函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
从这里我们可以看到,堆和栈相比,由于大量 new/delete 的使用,容易造成大量的内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用户态和核心态的切换,内存的申请,代价变得更加昂贵。所以栈在程序中是应用最广泛的,就算是函数的调用也利用栈去完成,函数调用过程中的参数,返回地址,EBP 和局部变量都采用栈的方式存放。所以,我们推荐大家尽量用栈,而不是用堆。
虽然栈有如此众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,还是用堆好一些。
无论是堆还是栈,都要防止越界现象的发生(除非你是故意使其越界),因为越界的结果要么是程序崩溃,要么是摧毁程序的堆、栈结构,产生以想不到的结果,就算是在你的程序运行过程中,没有发生上面的问题,你还是要小心,说不定什么时候就崩掉,那时候 debug 可是相当困难的 :)
对了,还有一件事,如果有人把堆栈合起来说,那它的意思是栈,可不是堆,呵呵,清楚了?
static 用来控制变量的存储方式和可见性
函数内部定义的变量,在程序执行到它的定义处时,编译器为它在栈上分配空间,函数在栈上分配的空间在此函数执行结束时会释放掉,这样就产生了一个问题: 如果想将函数中此变量的值保存至下一次调用时,如何实现? 最容易想到的方法是定义一个全局的变量,但定义为一个全局变量有许多缺点,最明显的缺点是破坏了此变量的访问范围(使得在此函数中定义的变量,不仅仅受此 函数控制)。需要一个数据对象为整个类而非某个对象服务,同时又力求不破坏类的封装性,即要求此成员隐藏在类的内部,对外不可见。
static 的内部机制:
静态数据成员要在程序一开始运行时就必须存在。因为函数在程序运行中被调用,所以静态数据成员不能在任何函数内分配空间和初始化。这样,它的空间分配有三个可能的地方,一是作为类的外部接口的头文件,那里有类声明;二是类定义的内部实现,那里有类的成员函数定义;三是应用程序的 main()函数前的全局数据声明和定义处。
静态数据成员要实际地分配空间,故不能在类的声明中定义(只能声明数据成员)。类声明只声明一个类的“尺寸和规格”,并不进行实际的内存分配,所以在类声明中写成定义是错误的。它也不能在头文件中类声明的外部定义,因为那会造成在多个使用该类的源文件中,对其重复定义。
static 被引入以告知编译器,将变量存储在程序的静态存储区而非栈上空间,静态数据成员按定义出现的先后顺序依次初始化,注意静态成员嵌套时,要保证所嵌套的成员已经初始化了。消除时的顺序是初始化的反顺序。
static 的优势:
可以节省内存,因为它是所有对象所公有的,因此,对多个对象来说,静态数据成员只存储一处,供所有对象共用。静态数据成员的值对每个对象都是一样,但它的 值是可以更新的。只要对静态数据成员的值更新一次,保证所有对象存取更新后的相同的值,这样可以提高时间效率。引用静态数据成员时,采用如下格式:
<类名>::<静态成员名>
如果静态数据成员的访问权限允许的话(即 public 的成员),可在程序中,按上述格式来引用静态数据成员。
Ps:
(1) 类的静态成员函数是属于整个类而非类的对象,所以它没有this指针,这就导致了它仅能访问类的静态数据和静态成员函数。
(2) 不能将静态成员函数定义为虚函数。
(3) 由于静态成员声明于类中,操作于其外,所以对其取地址操作,就多少有些特殊,变量地址是指向其数据类型的指针,函数地址类型是一个“nonmember 函数指针”。
(4) 由于静态成员函数没有 this 指针,所以就差不多等同于 nonmember 函数,结果就产生了一个意想不到的好处:成为一个 callback 函数,使得我们得以将 c++ 和 c-based x window 系统结合,同时也成功的应用于线程函数身上。
(5) static 并没有增加程序的时空开销,相反她还缩短了子类对父类静态成员的访问时间,节省了子类的内存空间。
(6) 静态数据成员在<定义或说明>时前面加关键字 static。
(7) 静态数据成员是静态存储的,所以必须对它进行初始化。
(8) 静态成员初始化与一般数据成员初始化不同:
初始化在类体外进行,而前面不加 static,以免与一般静态变量或对象相混淆;
初始化时不加该成员的访问权限控制符 private、public;
初始化时使用作用域运算符来标明它所属类;
所以我们得出静态数据成员初始化的格式:
<数据类型><类名>::<静态数据成员名>=<值>
(9) 为了防止父类的影响,可以在子类定义一个与父类相同的静态变量,以屏蔽父类的影响。这里有一点需要注意:我们说静态成员为父类和子类共享,但我们有重复定义了静态成员,这会不会引起错误呢?不会,我们的编译器采用了一种绝妙的手法:name-mangling 用以生成唯一的标志。
第四篇:
http://blog.csdn.net/rujielaisusan/article/details/4622197
内存分配方式
内存分配方式有三种:
[1] 从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量, static 变量。
[2] 在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中 ,效率很高,但是分配的内存容量有限。
[3] 从堆上分配,亦称动态内存分配 。程序在运行的时候用 malloc 或 new 申请任意多少的内存,程序员自己负责在何时用 free 或 delete 释放内存。动态内存的生存期由程序员决定 ,使用非常灵活,但如果在堆上分配了空间,就有责任回收它,否则运行的程序会出现内存泄漏,频繁地分配和释放不同大小的堆空间将会产生堆内碎块。
2. 程序的内存空间
一个程序将操作系统分配给其运行的内存块分为 4 个区域,如下图所示。
代码区 (code area) 程序内存空间
全局数据区 (data area)
堆区 (heap area)
栈区 (stack area)
一个由 C/C++ 编译的程序占用的内存分为以下几个部分 ,
1 、栈区( stack ) 由编译器自动分配释放 ,存放为运行函数而分配的局部变量、函数参数、返回数据、返回地址等。其操作方式类似于数据结构中的栈。
2 、堆区( heap ) 一般由程序员分配释放, 若程序员不释放,程序结束时可能由 OS 回收 。分配方式类似于链表。
3 、全局区(静态区)( static )存放全局变量、静态数据、常量。程序结束后有系统释放
4 、文字常量区 常量字符串就是放在这里的。 程序结束后由系统释放。
5 、程序代码区存放函数体(类成员函数和全局函数)的二进制代码。
下面给出例子程序,
int a = 0; // 全局初始化区
char *p1; // 全局未初始化区
int main() {
int b; // 栈
char s[] = /"abc/"; // 栈
char *p2; // 栈
char *p3 = /"123456/"; //123456//0 在常量区, p3 在栈上。
static int c =0;// 全局(静态)初始化区
p1 = new char[10];
p2 = new char[20];
// 分配得来得和字节的区域就在堆区。
strcpy(p1, /"123456/"); //123456//0 放在常量区,编译器可能会将它与 p3 所指向的 /"123456/" 优化成一个地方。
}
堆与栈的比较
1 申请方式
stack: 由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为 b 开辟空间。
heap: 需要程序员自己申请,并指明大小,在 C 中 malloc 函数, C++ 中是 new 运算符。
如 p1 = (char *)malloc(10); p1 = new char[10];
如 p2 = (char *)malloc(10); p2 = new char[20];
但是注意 p1 、 p2 本身是在栈中的。
2 申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表 ,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的 delete 语句才能正确的释放本内存空间。
由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
3 申请大小的限制
栈:在 Windows 下 , 栈是向低地址扩展的数据结构,是一块连续的内存的区域。 这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS 下,栈的大小是 2M (也有的说是 1M ,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示 overflow 。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
4 申请效率的比较
栈由系统自动分配,速度较快。但程序员是无法控制的 。
堆是由 new 分配的内存,一般速度比较慢,而且容易产生内存碎片 , 不过用起来最方便 。
另外,在 WINDOWS 下,最好的方式是用 VirtualAlloc 分配内存,他不是在堆,也不是栈,而是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
5 堆和栈中的存储内容
栈:在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的 C 编译器中,参数是由右往左入栈的 ,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
6 存取效率的比较
char s1[] = /"a/";
char *s2 = /"b/";
a 是在运行时刻赋值的;而 b 是在编译时就确定的;但是,在以后的存取中,在栈上的数组比指针所指向的字符串( 例如堆 ) 快。 比如:
int main(){
char a = 1;
char c[] = /"1234567890/";
char *p =/"1234567890/";
a = c[1];
a = p[1];
return 0;
}
对应的汇编代码
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器 cl 中,而第二种则要先把指针值读到 edx 中,再根据 edx 读取字符,显然慢了。
7 小结
堆和栈的主要区别由以下几点:
1 、管理方式不同;
2 、空间大小不同;
3 、能否产生碎片不同;
4 、生长方向不同;
5 、分配方式不同;
6 、分配效率不同;
管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生 memory leak 。
空间大小:一般来讲在 32 位系统下,堆内存可以达到 4G 的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在 VC6 下面,默认的栈空间大小是 1M 。当然,这个值可以修改。
碎片问题:对于堆来讲,频繁的 new/delete 势必会造成内存空间的不连 续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内 存块从栈中间弹出,在他弹出之前,在他上面的后进的栈内容已经被弹出,详细的可以参考数据结构。
生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
分配方式:堆都是动态分配的 ,没有静态分配的堆。栈有 2 种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由 malloca 函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现 。
分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是 C/C++ 函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构 / 操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
从这里我们可以看到,堆和栈相比,由于大量 new/delete 的使用,容易造成大量的内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用户态和核心态的切换,内存的申请,代价变得更加昂贵。所以栈在程序中是应用最广泛的,就算是函数的调用也利用栈去完成,函数调用过程中的参数,返回地址, EBP 和局部变量都采用栈的方式存放。所以,我们推荐大家尽量用栈,而不是用堆。
虽然栈有如此众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,还是用堆好一些。
无论是堆还是栈,都要防止越界现象的发生(除非你是故意使其越界),因为越界的结果要么是程序崩溃,要么是摧毁程序的堆、栈结构,产生以想不到的结果。
4.new/delete 与 malloc/free 比较
从 C++ 角度上说,使用 new 分配堆空间可以调用类的构造函数,而 malloc() 函数仅仅是一个函数调用,它不会调用构造函数,它所接受的参数是一个 unsigned long 类型。同样, delete 在释放堆空间之前会调用析构函数,而free 函数则不会。
class Time{
public:
Time(int,int,int,string);
~Time(){
cout<</"call Time/'s destructor by:/"<<name<<endl;
}
private:
int hour;
int min;
int sec;
string name;
};
Time::Time(int h,int m,int s,string n){
hour=h;
min=m;
sec=s;
name=n;
cout<</"call Time/'s constructor by:/"<<name<<endl;
}
int main(){
Time *t1;
t1=(Time*)malloc(sizeof(Time));
free(t1);
Time *t2;
t2=new Time(0,0,0,/"t2/");
delete t2;
system(/"PAUSE/");
return EXIT_SUCCESS;
}
结果:
call Time/'s constructor by:t2
call Time/'s destructor by:t2
从结果可以看出,使用 new/delete 可以调用对象的构造函数与析构函数,并且示例中调用的是一个非默认构造函数。但在堆上分配对象数组时,只能调用默认构造函数,不能调用其他任何构造函数
第五篇:
http://blog.csdn.net/loveyumomo/article/details/23244367
一、预备知识—程序的内存分配
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区—存放函数体的二进制代码。
二、例子程序
这是一个前辈写的,非常详细
//main.cpp
#include <stdio.h>
int a = 0; 全局初始化区
char *p1; 全局未初始化区
main()
{
int b; 栈
char s[] = "abc"; 栈
char *p2; 栈
char *p3 = "123456"; 123456\0在常量区,p3在栈上。
static int c =0; 全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); 123456\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
二、堆和栈的理论知识
2.1申请方式
stack:
由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap:
需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在栈中的。
2.2
申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,
会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
2.4申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
2.5堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.6存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:
#i nclude
void main()
{
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return;
}
对应的汇编代码
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读到edx中,在根据edx读取字符,显然慢了。
2.7小结:
堆和栈的区别可以用如下的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
下面是另一篇,总结的比上面好:
堆和栈的联系与区别dd
在bbs上,堆与栈的区分问题,似乎是一个永恒的话题,由此可见,初学者对此往往是混淆不清的,所以我决定拿他第一个开刀。
首先,我们举一个例子:
void f() { int* p=new int[5]; }
这条短短的一句话就包含了堆与栈,看到new,我们首先就应该想到,我们分配了一块堆内存,那么指针p呢?他分配的是一块栈内存,所以这句话的意思就是:在栈内存中存放了一个指向一块堆内存的指针p。在程序会先确定在堆中分配内存的大小,然后调用operator new分配内存,然后返回这块内存的首地址,放入栈中,他在VC6下的汇编代码如下:
00401028 push 14h
0040102A call operator new (00401060)
0040102F add esp,4
00401032 mov dword ptr [ebp-8],eax
00401035 mov eax,dword ptr [ebp-8]
00401038 mov dword ptr [ebp-4],eax
这里,我们为了简单并没有释放内存,那么该怎么去释放呢?是delete p么?澳,错了,应该是delete []p,这是为了告诉编译器:我删除的是一个数组,VC6就会根据相应的Cookie信息去进行释放内存的工作。
好了,我们回到我们的主题:堆和栈究竟有什么区别?
主要的区别由以下几点:
1、管理方式不同;
2、空间大小不同;
3、能否产生碎片不同;
4、生长方向不同;
5、分配方式不同;
6、分配效率不同;
管理方式:对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生memory leak。
空间大小:一般来讲在32位系统下,堆内存可以达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定的空间大小的,例如,在VC6下面,默认的栈空间大小是1M(好像是,记不清楚了)。当然,我们可以修改:
打开工程,依次操作菜单如下:Project->Setting->Link,在Category 中选中Output,然后在Reserve中设定堆栈的最大值和commit。
注意:reserve最小值为4Byte;commit是保留在虚拟内存的页文件里面,它设置的较大会使栈开辟较大的值,可能增加内存的开销和启动时间。
碎片问题:对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,在他弹出之前,在他上面的后进的栈内容已经被弹出,详细的可以参考数据结构,这里我们就不再一一讨论了。
生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
分配方式:堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
从这里我们可以看到,堆和栈相比,由于大量new/delete的使用,容易造成大量的内存碎片;由于没有专门的系统支持,效率很低;由于可能引发用户态和核心态的切换,内存的申请,代价变得更加昂贵。所以栈在程序中是应用最广泛的,就算是函数的调用也利用栈去完成,函数调用过程中的参数,返回地址,EBP和局部变量都采用栈的方式存放。所以,我们推荐大家尽量用栈,而不是用堆。
虽然栈有如此众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,还是用堆好一些。
无论是堆还是栈,都要防止越界现象的发生(除非你是故意使其越界),因为越界的结果要么是程序崩溃,要么是摧毁程序的堆、栈结构,产生以想不到的结果,就算是在你的程序运行过程中,没有发生上面的问题,你还是要小心,说不定什么时候就崩掉,那时候debug可是相当困难的:)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号