(二) MySQL索引
- 普通索引(非唯一索引):
- 唯一索引:要求键值不能重复(但是可以有多个NULL值)
- 主键索引:是特殊的唯一索引,不允许键值为NULL
- 全文索引:针对较大的文本类型数据,提升like语句的查询效率
唯一索引和普通索引:Change Buffer对普通索引的插入操作进行了优化,从而有更快的插入速度,但是阿里规约中:唯一索引优于普通索引(强制)
索引模型
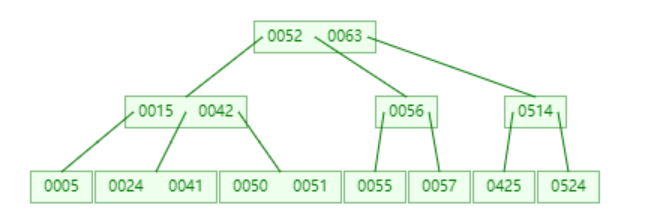
B-tree(多路平衡查找树)
- 关键字只出现一次(非叶子节点也存储数据)
- 搜索性能等于关键字全集内做一次二分查找
- 自动层次控制:页分裂和页合并
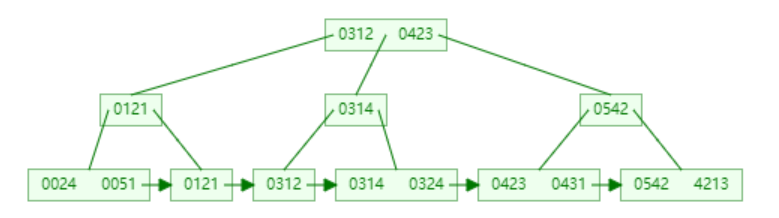
B+tree (增强的多路平衡查找树)
- 非叶子节点都是冗余的关键字索引数据,所有关键字和数据均存储在叶子节点
- 相较于B-tree,B+tree的非叶子节点存储的关键字数更多(路数更多),树的层级更少(因此能有效减少磁盘IO)
- B+tree所有叶子节点构成了一个有序链表,在范围查找时效率更高(全表遍历也更快)
- B+tree的查询效率更稳定(查询均需抵达叶子节点)
自适应Hash(Adaptive Hash Index)
- Hash的时间复杂度时O(1),只能用于等值查询,不能用于范围查询
- Hash冲突时采用拉链法解决
innoDB中只存在自适应hash,由引擎自行维护,存储在缓冲池中,作为热点数据的优化机制。
(show variables like 'innodb_adaptive_hash_index';默认值 ON)
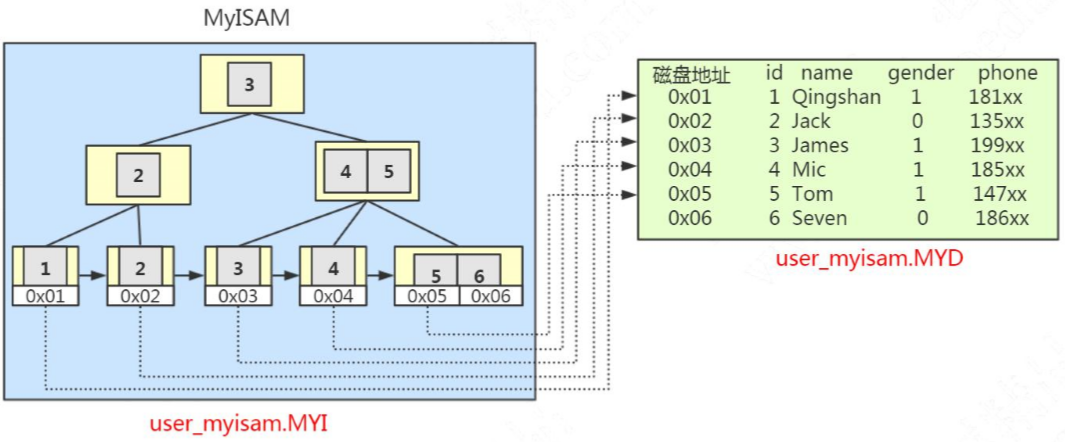
MyISAM和InnoDB的数据结构实现
MyISAM(非聚簇索引 + 叶子节点存储磁盘地址 + 数据文件)
InnoDB(聚簇索引 + 叶子节点存储数据值 --- 非聚簇索引存储主键)
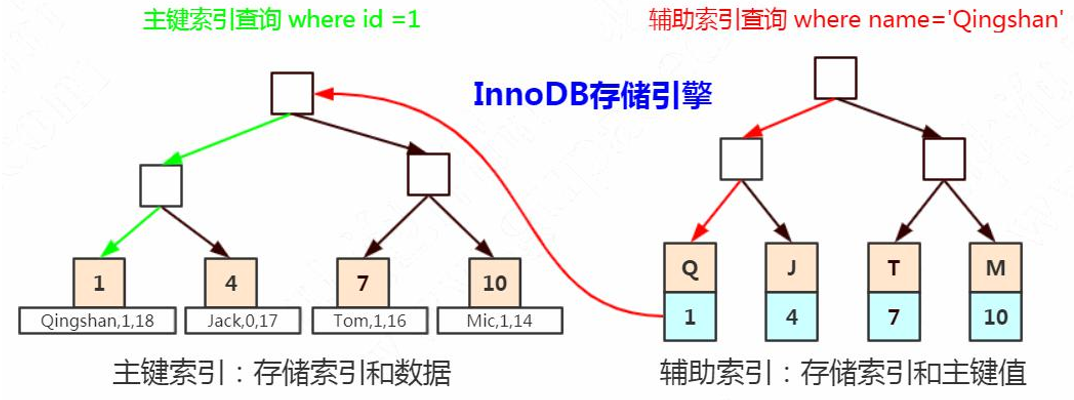
InnoDB必有主键索引:
- 如果已定义主键,则直接选择主键作为主键索引
- 如果不存在主键,则使用不带有NULL值的唯一索引作为主键索引
- 如果也不存在不带NULL值的唯一索引,则选择内置的6字节长的ROWID作为主键索引(递增,不可被选用 < 此为与Oracle InnoDB的不同)
InnoDB建议使用递增的主键
- 递增的主键,在插入时近似顺序写入,会有更高的效率。
- 数据页到达阈值时只需要分配新的页,不会导致页分裂,索引也更易于维护
缺点:在高并发工作负载时,可能导致间隙锁竞争,调优参数:innodb_autoinc_lock_mode
回表: 在辅助索引中一次查询到主键的值后,再次回到主键索引查找数据的过程叫回表
索引使用原则
联合索引最左匹配原则
PS:单列索引,亦有最左匹配原则:"LIKE %abc" 类型的查询无法使用索引
- 对于多列索引,如
CREATE INDEX idx_name_phone on tb_user(name,phone);
只有存在(对name的查询)或(同时对name和phone的查询)时索引生效 - 对于联合索引(A,B,C),对于查找类型(A)和查找类型(A,B)均可生效
覆盖索引 (EXPLAIN:Using index)`:
如果辅助索引中包含了查询所需要的所有信息,则可以从辅助索引中直接获得结果集,无须回表
索引条件下推(ICP)
set optimizer_switch = 'index_condition_pushdown=on';
不使用索引条件下推优化时的查询过程:
- 获取下一行,首先读取索引信息,然后根据索引将整行数据读取出来。
- 然后通过where条件判断当前数据是否符合条件,符合返回数据。
使用索引条件下推优化时的查询过程(EXPLAIN:Using index condition):
- 获取下一行的索引信息。
- 检查索引中存储的列信息是否符合索引条件,如果符合将整行数据读取出来,如果不符合跳过读取下一行。
- 用剩余的判断条件,判断此行数据是否符合要求,符合要求返回数据。
索引的比较是在存储引擎进行的,数据记录的比较,是在Server层进行的
索引的创建与使用
索引创建
- 散列度:索引应建立在散列度较高的属性列上
- 使用递增的id作为主键索引,尽量与业务无关(类顺序写入,优化IO,避免页分裂)
- 建立索引的属性列不应频繁更新(避免页分裂和索引维护)
- 建立组合索引,并把散列度高的值放在前面
- 在用于where判断/order排序/join(on)的字段上创建索引
- 对于长度较长的字段,应该选取合适的长度作为索引
SELECT count(distinct LEFT(field, prefix_size))/count(*) from table
索引(未生效情况)
- 索引列上使用函数、表达式、算符:
a + 1 = 2或count(a,b) = 'kiqi' - 字符串不加引号,出现隐式转换
- 未满足最左前缀匹配原则
LIKE "%kiqi"或未满足联合索引最左匹配原则 - or语句前后没有同时使用索引:当or左右查询字段只有一个是索引,该索引失效,只有当or左右查询字段均为索引时,才会生效
- 部分负向查询:不能(
NOT LIKE),部分情况可以(!=、<>)
索引的使用规则:基于开销(cost),而非规则或语义,即:当全文查询开销小于使用索引时,则有可能不采用索引。
欢迎疑问、期待评论、感谢指点 -- kiqi,愿同您为友
-- 星河有灿灿,愿与之辉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号