(一) MySQL架构
Mysql 基础
Mysql数据库状态查询语句
(默认session级别,全局为global级别)
(使用set动态修改,服务器重启后失效;修改/etc/my.cnf配置文件,永久生效)
show global variables like 'max_connections' 查看最大连接数(默认151,可设2^14)
show global variables like 'wait_timeout' 非交互式超时时间,如 JDBC 程序
show global variables like 'interactive_timeout' 交互式超时时间,如数据库工具
show global status like 'Thread%' 查看MySQL当前有多少个连接及其状态
show processlist 显示用户正在运行的线程
show variables like 'query_cache%' 查询mysql缓存 - 默认未开启
show status like 'Last_query_cost' 查看查询的开销
show table status from 'xxx' 查看表的存储引擎
Mysql通信方法 - Tcp/IP连接,半双工通信
mysql -h 192.168.0.1 -u root -p root 采用tcp/ip协议以密码连接到mysql服务器。
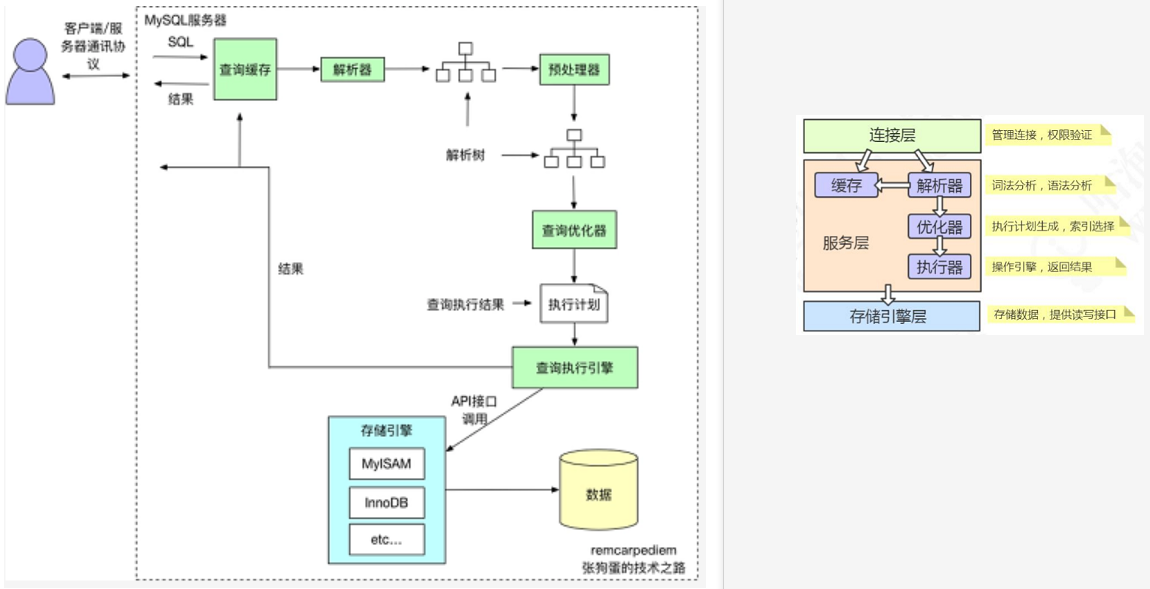
Mysql语句执行流程
- 客户端与Mysql建立连接后,发送来查询语句
- 服务层接受到查询语句,判断是否在缓存中有该语句的缓存
Y -> 直接返回缓存中的结果
N -> 跳转3- 解析器 -> 词法解析 -> 语法解析 -> (预处理器)部分校验 >> 语法树
- 查询优化器 >> 执行计划(基于开销cost的优化器)
- 执行引擎 -> 调用存储引擎的api接口(此接口由mysql提供,实现由具体引擎实现)
PS:EXPLAIN [sql语句]查看语句的执行计划。
存储引擎
MyISAM - 适合只读类型的数据分析项目,无事务
- 支持表级别锁(插入和更新会锁表)
- 不支持事务(带外键的innoDB引擎转为MyISAM会失败)
- 具有较高的插入和查询速度
- 存储了表的行数(count速度快)
- innoDB中不存储该值,使用count(*)时需做全表查询
- 数据以文件类型存储,索引为非聚簇的B+树索引,叶子节点的值为指向数据的指针
InnoDB - 需要实现事务(ACID)的项目,存在并发读写的业务系统
- 支持行级锁和表级锁
- 支持事务,支持外键,实现数据的完整性和一致性
- 支持读写并发,写不阻塞读(MVCC)
- 数据以主键B+树聚簇索引的方式存储,主键索引效率很高,辅助索引中叶子节点存储主键的值,再通过主键索引查找数据。
- 主键的值不建议太长,否则辅助索引会比较大。
- 主键的值建议使用递增ID,保证每次插入时B+索引是从右边扩展的,可以避免页分裂。
Memory - 临时表
内存数据库,提供快速查询,但是数据库重启或崩溃时数据完全丢失,适合做临时表。
CSV - 导入或转储
带有逗号分隔值的文本文件,多用来导入或转储数据。(不支持索引)
Archive - 存档
紧凑的未索引的表用于存储和检索大量很少引用的历史、存档。(不支持索引)
InnoDB引擎 - 内部数据结构
InnoDB 逻辑存储结构
- 表空间(table space): 一张表即为一个表空间
- 段(segment): 表空间由各段组成,如:索引段(非叶子节点数据)、数据段(叶子节点数据)
- 簇/区(extend):1MB - 簇是空间划分的最小单位,由64个连续的页(16KB)组成
- 页(page):16K - 文件系统的页大小为4K,从而引出了双写缓冲区的概念
- 行(row): 数据按行存储,一行即一条数据
Buffer Pool
- 使用缓存页(数据页、索引页)避免频繁的IO页切换
- Change Buffer(Insert Buffer):对非唯一普通索引页进行更新的操作,由于不需要校验操作,可放入Change Buffer中,避免一次IO操作
- Adaptive Hash Index(自适应哈希索引):innoDB引擎会根据访问频率和模式,为部分页创建自适应的hash索引,从而提高执行速度
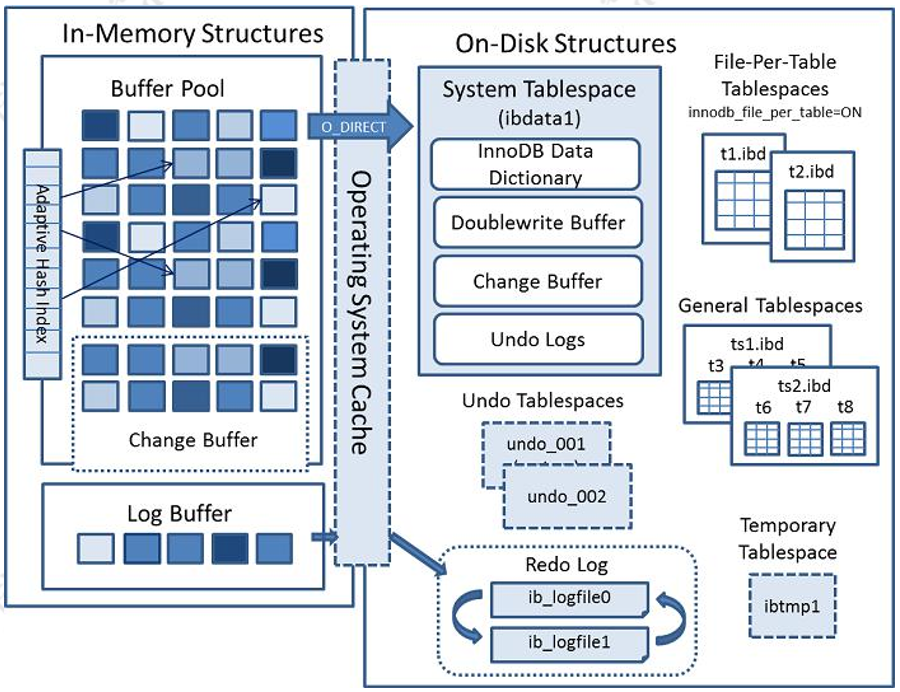
double write(双写缓冲区)
- 部分写失效:操作系统页大小为4k,mysql的页大小为16K,在buffer pool中的页进行刷盘时,可能出现mysql页的一部分刷盘成功时,导致页损坏,此时依靠redo log无法完成数据一致性的修复。
- double write:系统在刷盘之前,先将页顺序写入到双写缓存区中,写入完毕之后再进行刷盘操作。(磁盘顺序写入的性能较高,不会有太大开销)
redo log(重做日志) - 记录页做了什么改动
- redo log会持久化到磁盘中 - 由innodb_flush_log_at_trx_commit参数设置写入机制,有固定大小限制。
- 当数据库宕机或重启时,可使用redo log找回Buffer Pool中未刷盘的数据(WAL技术:Write-Ahead Logging:先写日志,再写磁盘)
undo log(撤销日志) - 记录事务发生之前的数据状态
- 当修改数据出现异常时,使用undo log实现回滚操作(原子性)
- MVCC中,也通过undo log找回原本版本的值。
Binlog(二进制log)
以事件的形式记录了所有的DDL和DML语句,用来做主从复制和数据恢复
redo log和undo log属于本地资源管理器级别的日志,binlog属于分布式事务管理器级别的日志。
二阶段提交
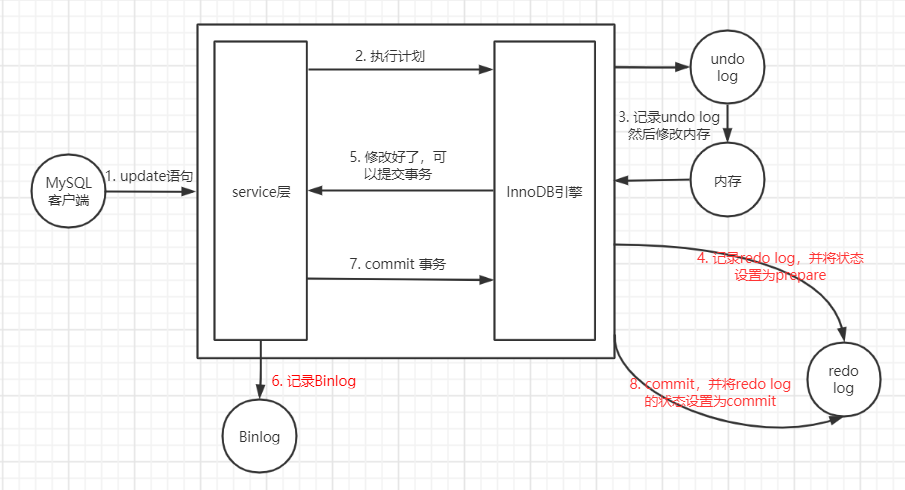
innoDB中,更新语句的底层细节(XA)
- 连接建立后,客户端发送查询语句
- service层: 调用更新操作 -> innoDB引擎
- innoDB引擎:记录undo log -> 执行操作-修改内存 -> 记录redolog(prepare) -> service层
- service层:记录binlog(commit) -> innoDB引擎:提交,更新redolog(commited)
基于(XA协议)的二阶段提交:(预备阶段,提交阶段)
二阶段提交是为了实现分布式事务:
1. 本地资源管理器记录操作日志redolog,标记为prepare阶段
2. 分布式事务管理器记录操作日志binlog,
3. 本地资源管理器提交事务并更新redolog为commit.
原因:只有本地资源管理器和分布式事务管理器均确认提交时才执行提交操作。 避免本地资源池管理器提交完成后,分布式事务管理器因不可预知的原因导致分布式事务中丢失了该条更新记录。
欢迎疑问、期待评论、感谢指点 -- kiqi,愿同您为友
-- 星河有灿灿,愿与之辉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号