HTTP详解
1. HTTP协议
1.1. 定义
HTTP,超文本传输协议。超越文本的网络传输协议。
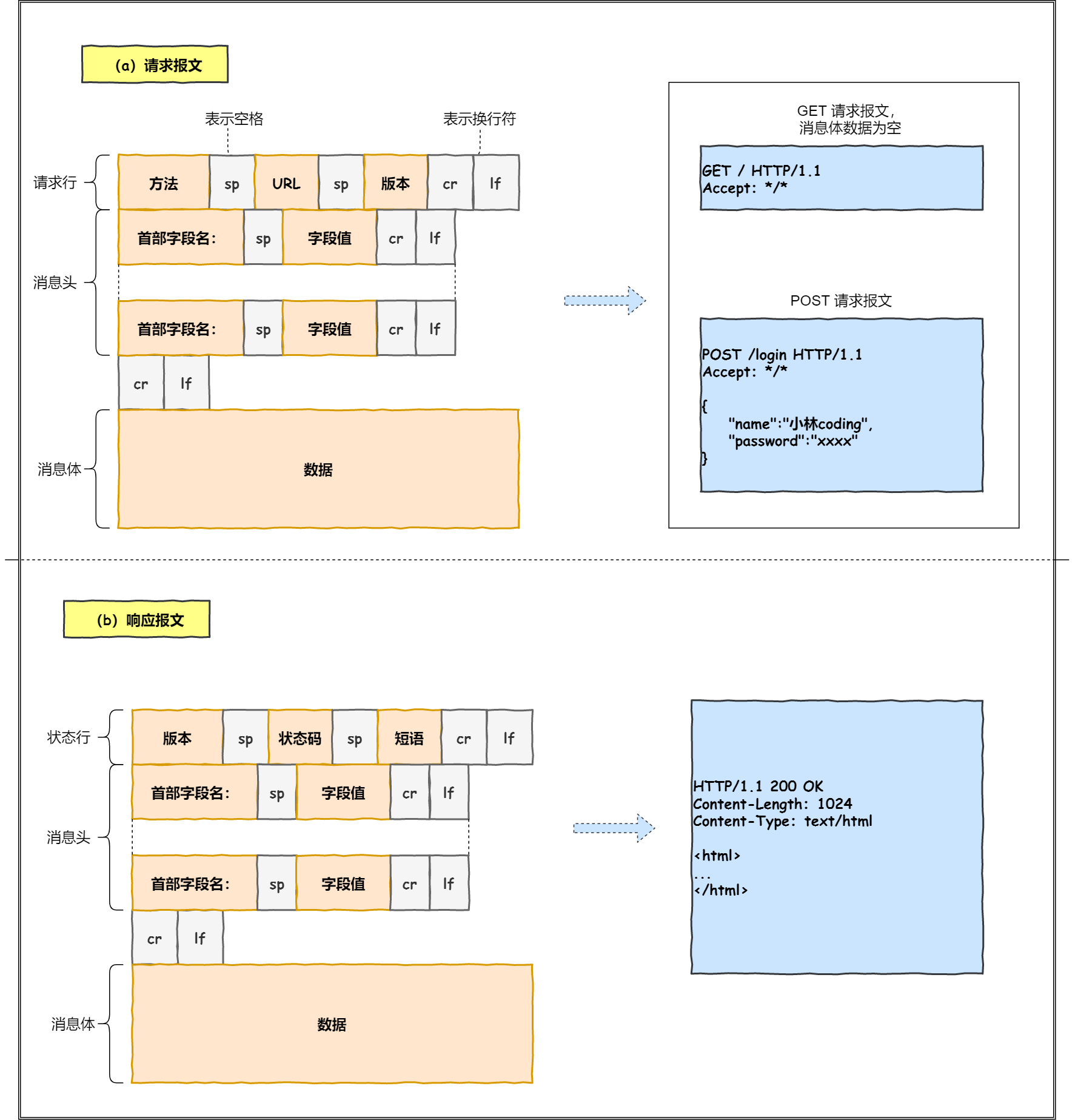
1.2. 状态码

2XX 成功
- 200 OK
最常见的成功状态码,表示一切正常。如果是非 HEAD 请求,服务器返回的响应头都会有 body 数据。 - 204 No Content
常见的成功状态码,与 200 OK 基本相同,但响应头没有 body 数据。 - 206 Partial Content
应用于 HTTP 分块下载或断点续传,表示响应返回的 body 数据并不是资源的全部,而是其中的一部分。
3XX 重定向
- 301 Moved Permanently
表示永久重定向,说明请求的资源已经不存在了,需改用新的 URL 再次访问。 - 302 Found
表示临时重定向,说明请求的资源还在,但暂时需要用另一个 URL 来访问。
301 和 302 都会在响应头里使用字段 Location,指明后续要跳转的 URL,浏览器会自动重定向新的 URL。
- 304 Not Modified
表示资源未修改,重定向已存在的缓冲文件,告诉客户端可以继续使用缓存资源。
4XX 客户端错误
- 400 Bad Request
表示客户端错误通用的错误码。 - 403 Forbidden
表示服务器禁止访问资源,并不是客户端的请求出错。 - 404 Not Found
表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端
5XX 服务器错误
- 500 Internal Server Error
表示服务器错误笼统通用的错误码。 - 502 Bad Gateway
通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。 - 503 Service Unavailable
表示服务器当前很忙,暂时无法响应客户端,类似“网络服务正忙,请稍后重试”的意思。
1.3. 常见消息头字段
- Host
指明请求的服务器域名 - Content-Length
表明此次数据的长度,用于区分HTTP Body部分的边界,避免TCP粘包问题。 - Connection
Connection: Keep-Alive表示长连接。 - Content-Type
表明此次数据的格式,如Content-Type: text/html; Charset=utf-8。 - Content-Encoding
表明此次数据的压缩方式,如Content-Encoding: gzip。 - Content-Encoding
表明可以接受哪些数据压缩方式,如Accept-Encoding: gzip, deflate。
1.4. 常见请求方法
1.4.1 GET
从服务器获取指定的资源(一般用于查询资源)。
- 参数一般在URL中,URL规定只能支持 ASCII,所以参数需要转义
- HTTP对于URL长度没有限制,但是浏览器有限制。故URL中参数过多会请求失败。
- 具有幂等性
- 结果可缓存(浏览器缓存)
- Get请求也可以有body,但是没人这样用
1.4.2 POST
根据请求负荷(报文body)对指定的资源做出处理(一般用于新增资源)。
- 参数一般在body体中,对于格式没有限制
- 浏览器不会限制body体大小
- 不具有幂等性
1.4.3 PUT
根据请求负荷(报文body)对指定的资源做出更新处理(一般用于更新资源)。
- 参数一般在body体中,对于格式没有限制
- 不具有幂等性
1.4.4 DELETE
根据请求负荷(报文body)对指定的资源做出删除处理(一般用于删除资源)。
- 具有幂等性
1.5. 缓存技术
对于一些具有重复性的 HTTP 请求,可以将数据缓存避免每次都去请求。
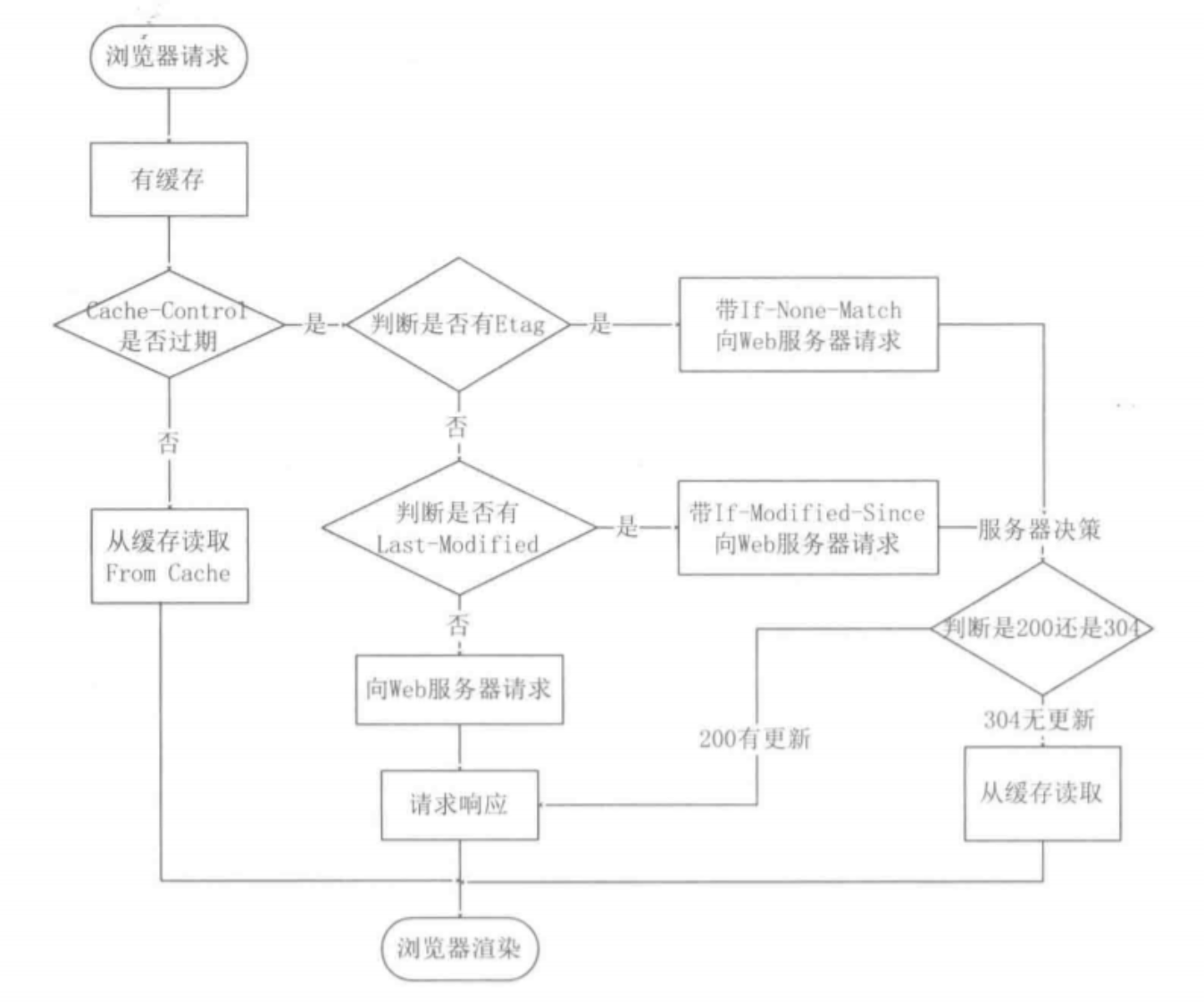
1.5.1 强制缓存
只要浏览器判断缓存没有过期,则直接使用浏览器的本地缓存,决定是否使用缓存的主动性在于浏览器这边。状态码200,但是会有说明200 (from disk cache)。
响应消息头中采用Cache-Control(相对时间 HTTP1.1引入)或者Expires(绝对时间 HTTP1.0引入)字段实现强制缓存,表示资源在客户端缓存的有效期。
1.5.2 协商缓存
开启强制缓存的Cache-Control过期后,才能进行协商缓存。
协商缓存就是与服务端协商之后,通过协商结果来判断是否使用本地缓存。状态码304。
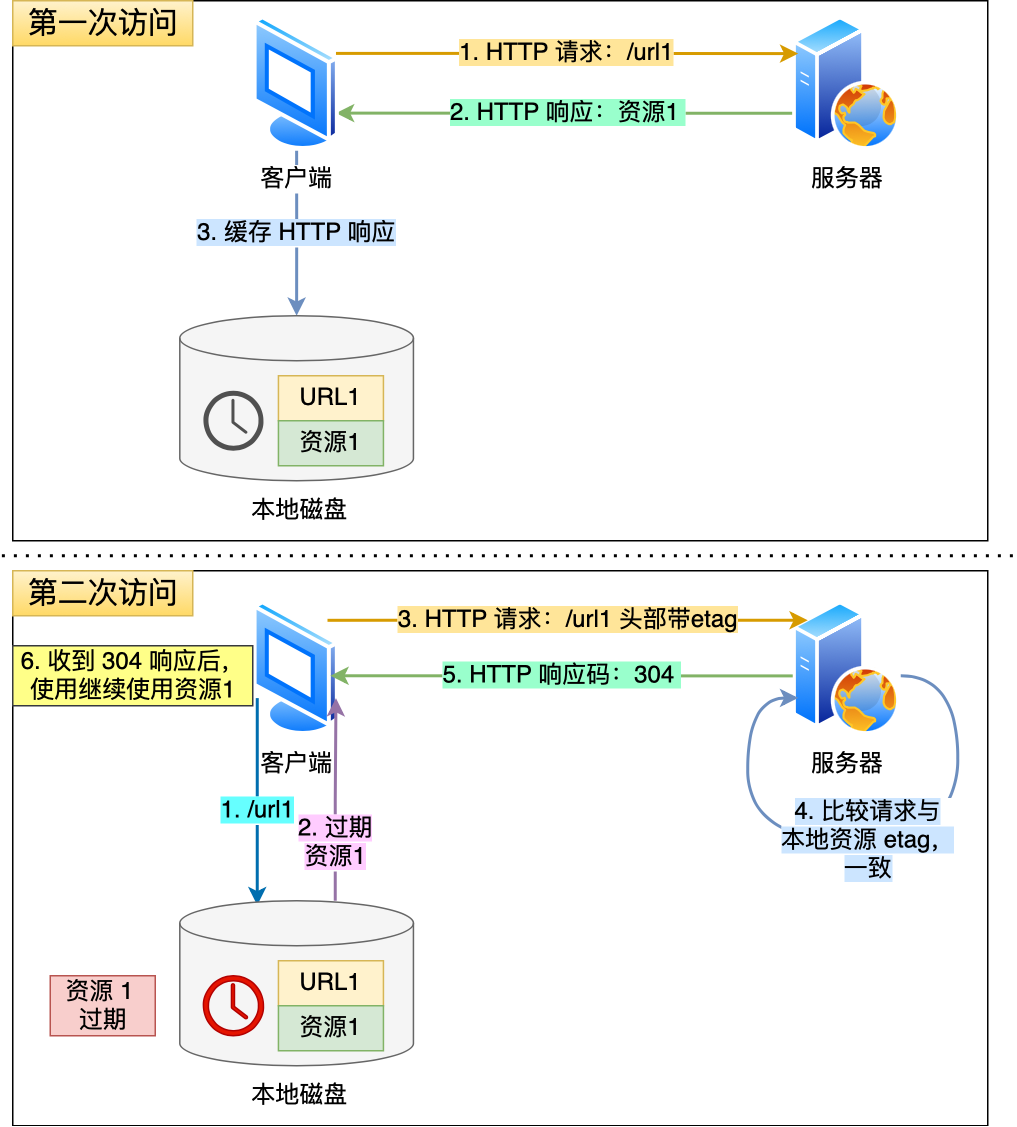
有两个实现方式。响应头部可以选择两个字段:
- Etag字段
若Etag不同,那么资源被变更,需要返回新的资源。第二次请求头部携带Last-Modified的值的是If-None-Match字段。 - Last-Modified
当前修改时间若比Last-Modified更新,那么资源被变更,需要返回新的资源。第二次请求头部携带Last-Modified的值的是If-Modified-Since字段。
1.5.3 HTTPS与HTTP的区别
1.5.3.1 区别
- HTTPS为加密数据传输,因为在TCP和HTTP间加入了中间层TLS安全协议
- HTTPS在TCP三次握手后,还需要进行TLS的握手过程
- HTTPS默认端口号为443
- HTTPS需要向CA(证书权威机构)申请证书,保证服务器的身份可信
1.5.3.2 解决了哪些问题
- 信息加密:交互信息无法被窃取
- 校验机制:无法篡改通信内容,篡改了无法通过校验
- 身份证书:可信的身份证明
更多信息可以参考HTTPS详解。
1.6. HTTP1.1
1.6.1 长连接
减少了 TCP 连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载。
持久连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。
1.6.2 更强大的缓存控制
引入了Cache-Control头部,引入了协商缓存。
1.6.3 同一个服务器支持多个域名服务
引入了Host头部,支持区分不同请求域名。
1.6.4 管道化
在同一个 TCP 连接里面,客户端可以发起多个请求,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。但是服务器必须按照接收请求的顺序发送对这些管道化请求的响应。
HTTP/1.1 管道解决了请求的队头阻塞,但是没有解决响应的队头阻塞。
队头堵塞:如果服务端在处理 A 请求时耗时比较长,那么后续的请求的处理都会被阻塞住。
这个技术非默认开启,且基本没有浏览器支持。
1.7. HTTP2

性能优化点:
- 头部压缩
- 二进制格式
- 并发传输
- 服务器主动推送资源
1.7.1 头部压缩
HTTP1.1中只支持通过Content-Encoding:gizp来对body进行压缩,对于头部则没有压缩方式。
针对于HTTP1.1中的固定头部字段、重复字段值、ASCII编码效率低的问题,分别推出了压缩、避免重复、二进制编码的处理方式。
1.7.1.1 PACK算法
HTTP2头部压缩使用的是HPACK算法,主要包括三部分:
- 静态字典
- 动态字典
- Huffman编码(压缩算法)
客户端和服务器两端都会建立和维护「字典」,用长度较小的索引号表示重复的字符串,再用 Huffman 编码压缩数据,可达到 50%~90% 的高压缩率。
静态字典
HTTP/2 为61组高频出现在头部的字符串和字段建立了一张静态表。
比如index为2对应的头部键值对为method:Get,而有些没有头部值的是变化值,由Huffman编码处理再发送。
动态字典
静态表只包含了 61 种高频出现在头部的字符串,不在静态表范围内的头部字符串就要自行构建动态表,它的 Index 从 62 起步,会在编码解码的时候随时更新。
动态表生效有一个前提:必须同一个连接上,重复传输完全相同的 HTTP 头部。
比如,第一次发送时头部中的「User-Agent 」字段数据有上百个字节,经过 Huffman 编码发送出去后,客户端和服务器双方都会更新自己的动态表,添加一个新的 Index 号 62。那么在下一次发送的时候,就不用重复发这个字段的数据了,只用发 1 个字节的 Index 号就好了,因为双方都可以根据自己的动态表获取到字段的数据。
1.7.2 二进制格式
HTTP2.0将HTTP1.1的文本格式改成了二进制格式进行传输。比如,HTTP2.0的响应报文分为了头部帧和数据帧来传输,对应帧类型中的两类。
其中,帧的通用结构如下。

其中:
- 帧长度:表明帧数据(Frame Playload)的长度
- 帧类型:数据帧和控制帧两类,具体如图所示。
- 标志位:可以保存 8 个标志位,用于携带简单的控制信息。
- END_HEADERS 表示头数据结束标志,相当于 HTTP/1 里头后的空行(“\r\n”);
- END_Stream 表示单方向数据发送结束,后续不会再有数据帧。
- PRIORITY 表示流的优先级;
- 流标识符:标识该 Frame 属于哪个 Stream,接收方可以根据这个信息从乱序的帧里找到相同 Stream ID 的帧,从而有序组装信息。最高位占位不使用。
- 实际数据:Frame Payload存放的是通过 HPACK 算法压缩过的 HTTP 头部和包体。
1.7.3 Stream并发传输
引入Stream概念,多个Stream复用同一个TCP连接。
HTTP1.1中,在同一个连接中,是请求响应模型只能串行化,而HTTP2.0通过Stream就可以并发地请求响应了。
一个TCP连接中包含多个Stream(每个stream都对应一个独立的请求-响应对),每个Stream 里可以包含多个 Message(Message 对应 HTTP/1 中的请求或响应,由 HTTP 头部和包体构成), 一个Message里面可以包含多个Frame帧。
不同 Stream 的帧是可以乱序发送的,而同一 Stream 内部的帧必须是严格有序的。浏览器可以通过Frame中的流标识符重新组装各自Stream信息。
同一个连接中的 Stream ID 是不能复用的,只能顺序递增,所以当 Stream ID 耗尽时,需要发一个控制帧 GOAWAY,用来关闭 TCP 连接。
1.7.4 主动推送资源
例如nginx如下配置时,会在客户端请求test.html主动推送test.css文件。
location /test.html {
http2_push /test.css;
}
客户端发起的请求,必须使用的是奇数号 Stream,服务器主动的推送,使用的是偶数号 Stream。
服务器在推送资源时,会通过 PUSH_PROMISE 帧传输 HTTP 头部,并通过帧中的 Promised Stream ID 字段告知客户端,接下来会在哪个偶数号 Stream 中发送包体。
如上图,在 Stream 1 中通知客户端 CSS 资源即将到来,然后在 Stream 2 中发送 CSS 资源,注意 Stream 1 和 2 是可以并发的。
1.7.5 缺点
1.7.5.1 TCP队头阻塞
HTTP2.0解决了HTTP1.1的响应队头阻塞,但是依然存在更底层的TCP队头阻塞。
TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且有序的。
如果序列号较低的 TCP 段在网络传输中丢失了,即使序列号较高的 TCP 段已经被接收了,应用层也无法从内核中读取到这部分数据。
由于Stream复用同一个TCP连接,那么就算有的Stream数据已经到齐,但是前面的Stream还在等待某个TCP包重传,后续的Stream数据依然无法读取而被阻塞。
1.7.5.2 握手延迟
HTTP2.0基于TLS1.2+实现,故需要进行TCP的3次握手及TLS1.2的4次握手,需要3个(客户端ACK和ClientHello一起发送)RTT(往返时延)时间。
1.7.5.3 网络迁移重连
TCP 连接是由四元组(源 IP 地址,源端口,目标 IP 地址,目标端口)确定,如果IP 地址或者端口变动了,就会导致需要 TCP 与 TLS 重新握手。比如5G切WIFI。
1.8. HTTP3
2022.6.6已正式发布。
HTTP3.0基于UDP协议,完全解决了HTTP2.0协议因为TCP协议带来的队头阻塞、握手延迟、网络迁移重连问题。HTTP3.0引入了基于UDP实现的应用层QUIC协议。
1.8.1 QUIC协议
基于UDP协议的基础上,在应用层实现了连接管理、拥塞窗口、流量控制的特性。因为原生UDP协议是是一个简单、不可靠的传输协议,无序、没有连接。
1.8.1.1 无队头阻塞
QUIC协议和HTTP2.0也有类似的Stream划分,但是QUIC协议每个Stream的数据包到齐后便可被读取,不受其他Stream等待丢失包重传的影响。
1.8.1.2 更短的握手延迟
握手延迟仅 1 RTT,握手的目的是为确认双方的「连接 ID」。
HTTP/3 的 QUIC 协议并不是与 TLS 分层,而是 QUIC 内部包含了 TLS,它在自己的帧会携带 TLS 里的“记录”,再加上 QUIC 使用的是 TLS 1.3,因此仅需 1 个 RTT 就可以「同时」完成建立连接与密钥协商。
甚至在第二次连接的时候,应用数据包可以和 QUIC 握手信息(连接信息 + TLS 信息)一起发送,达到 0-RTT 的效果。
1.8.1.3 支持网络迁移
QUIC 协议没有用四元组的方式来“绑定”连接,而是通过连接 ID 来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己。
移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感。
1.8.2 HTTP3协议
1.8.2.1 二进制帧
二进制帧结构如下。

HTTP3.0不需要再定义Stream等信息,而是直接使用QUCI协议里的Stream,故帧头部只保留了帧类型及数据长度。
HTTP3.0压缩算法由HTTP2.0的HPACK升级为了QPACK,编码方式相似。
只是QPACK 的静态表扩大到 91 项,并且动态表使用了2个单向Stream进行客户端和服务端之间的动态表同步,避免了HTTP2.0中动态表还没建议就使用索引的情况。
1.8.2.2 HTTP3.0整体结构

1.8.2.3 HTTP3.0 UDP报文整体结构

2. HTTP与RPC区别
2.1 HTTP和RPC的本质
TCP是个基于字节流的二进制传输协议,对于应用来说,是没有办法合理截断来解码成有效信息的。所以,基于TCP的各种应用层协议诞生了,其中既有各种RPC协议,也有HTTP协议。
首先分清楚一点,HTTP是一个协议,RPC是一种调用方式(远程过程调用Remote Procedure Call)。像gRPC、Thrift等都是RPC的具体协议,这些协议能对比的才是HTTP协议。
TCP和RPC协议在七八十年代就发展了,而HTTP协议90年代才出现。所以,为何已经有了能通信的RPC系列协议,还需要HTTP协议呢?
因为浏览器的发展,HTTP协议在B/S架构发展壮大一统天下,而如果每个企业都需要定制的用RPC协议去走C/S架构,泛用性则不足,所以当前RPC协议基本用于微服务间内部使用。
RPC协议和HTTP协议不是对立的二选一关系,毕竟RPC是一种调用方式,所以HTTP协议也是可以作为RPC协议来使用的。
比如gRPC协议底层使用HTTP/2作为传输协议,同时使用Protocol Buffers作为接口描述语言。HTTP/2提供了高效的双向流传输机制,使得gRPC能够实现高性能的RPC通信。而Protocol Buffers则用于定义服务接口和数据结构,使得不同语言之间的gRPC通信更加方便和一致。
Protobuf是一种用于序列化结构数据的工具,实现数据的存储与交换,与编程语言和开发平台无关。
Protobuf的优点包括:
高效:Protobuf序列化后的数据体积小,速度快。
跨语言、跨平台:Protobuf的协议描述语言(.proto文件)可以描述不同语言的数据结构,通过编译生成不同语言的源代码,实现跨语言、跨平台的通信。
兼容性:Protobuf可以方便地扩展数据结构,更新数据结构时不会破坏依赖旧格式编译出来的程序。
2.2 HTTP与RPC区别
服务发现
- HTTP
DNS域名系统 - RPC
服务注册中心: 管理分布式系统中的服务的注册。当一个微服务实例启动时,它会向注册中心注册自己的信息和地址,告诉注册中心它提供了哪些服务以及在哪个端口监听请求。
服务发现中心:管理分布式系统中的服务发现。当一个微服务需要使用另一个微服务时,它会向注册中心发起请求,查询可用的服务实例。
底层连接
主流HTTP/1.1默认使用长连接,RPC也类似默认TCP长连接。
使用上,SDK也基本都会建立连接池,区别不大。
传输内容
基于TCP传输的消息,无非都是消息头Header和消息体Body。
但是HTTP1.1的头部有大量冗余的非压缩数据,只支持Body体压缩,效率不高。RPC协议则可以自定义压缩方式,也不用考虑浏览器行为,对于HTTP/1.1效率一般更高。
不过HTTP2.0/3.0的性能已经提上来了,甚至比很多RPC协议更好。HTTP协议演进可以参考HTTP详解。
3. HTTP与WebSocket区别
WebSocket用于主动向客户端推送数据。使用HTTP的话,一般是通过轮询实现。
3.1 轮询
网页的前端代码里不断定时发 HTTP 请求到服务器,服务器收到请求后给客户端响应消息。
3.1.1 短轮询
登录页面二维码出现之后,前端网页根本不知道用户扫没扫,于是不断去向后端服务器询问,看有没有人扫过这个码。而且是以大概 1 到 2 秒的间隔去不断发出请求,这样可以保证用户在扫码后能在 1 到 2 秒内得到及时的反馈,不至于等太久。
但这样,会有两个比较明显的问题:
- HTTP请求虽然很小,但也消耗带宽,增加下游服务器的负担。
- 最坏情况下,用户在扫码后,需要等个 1~2 秒,正好才触发下一次 HTTP 请求,然后才跳转页面,用户会感到明显的卡顿。
3.1.2 长轮询
发起一个请求,在较长时间内等待服务器响应的机制。
比如百度网盘扫码登录将HTTP请求将超时设置的30秒,在这 30 秒内只要服务器收到了扫码请求,就立马返回给客户端网页。如果超时,那就立马发起下一次请求。
3.2 主动推送
像页游这种,主动推送数据的WebSocket肯定比各种轮询更优。
浏览器在 TCP 三次握手建立连接之后,都统一使用 HTTP 协议先进行一次通信。
如果此时是普通的 HTTP 请求,那后续双方就还是老样子继续用普通 HTTP 协议进行交互,这点没啥疑问。
如果这时候是想建立 WebSocket 连接,就会在 HTTP 请求里带上一些特殊的header 头,如下:
Connection: Upgrade
Upgrade: WebSocket
Sec-WebSocket-Key: T2a6wZlAwhgQNqruZ2YUyg==\r\n
浏览器想升级协议(Connection: Upgrade),并且想升级成 WebSocket 协议(Upgrade: WebSocket)。同时带上一段随机生成的 base64 码(Sec-WebSocket-Key),发给服务器。
如果服务器正好支持升级成 WebSocket 协议。就会走 WebSocket 握手流程,同时根据客户端生成的 base64 码,用某个公开的算法变成另一段字符串,放在 HTTP 响应的 Sec-WebSocket-Accept 头里,同时带上101状态码,发回给浏览器。HTTP 的响应如下:
HTTP/1.1 101 Switching Protocols\r\n
Sec-WebSocket-Accept: iBJKv/ALIW2DobfoA4dmr3JHBCY=\r\n
Upgrade: WebSocket\r\n
Connection: Upgrade\r\n
之后,浏览器也用同样的公开算法将base64码转成另一段字符串,如果这段字符串跟服务器传回来的字符串一致,那验证通过。
WebSocket连接便建立了。
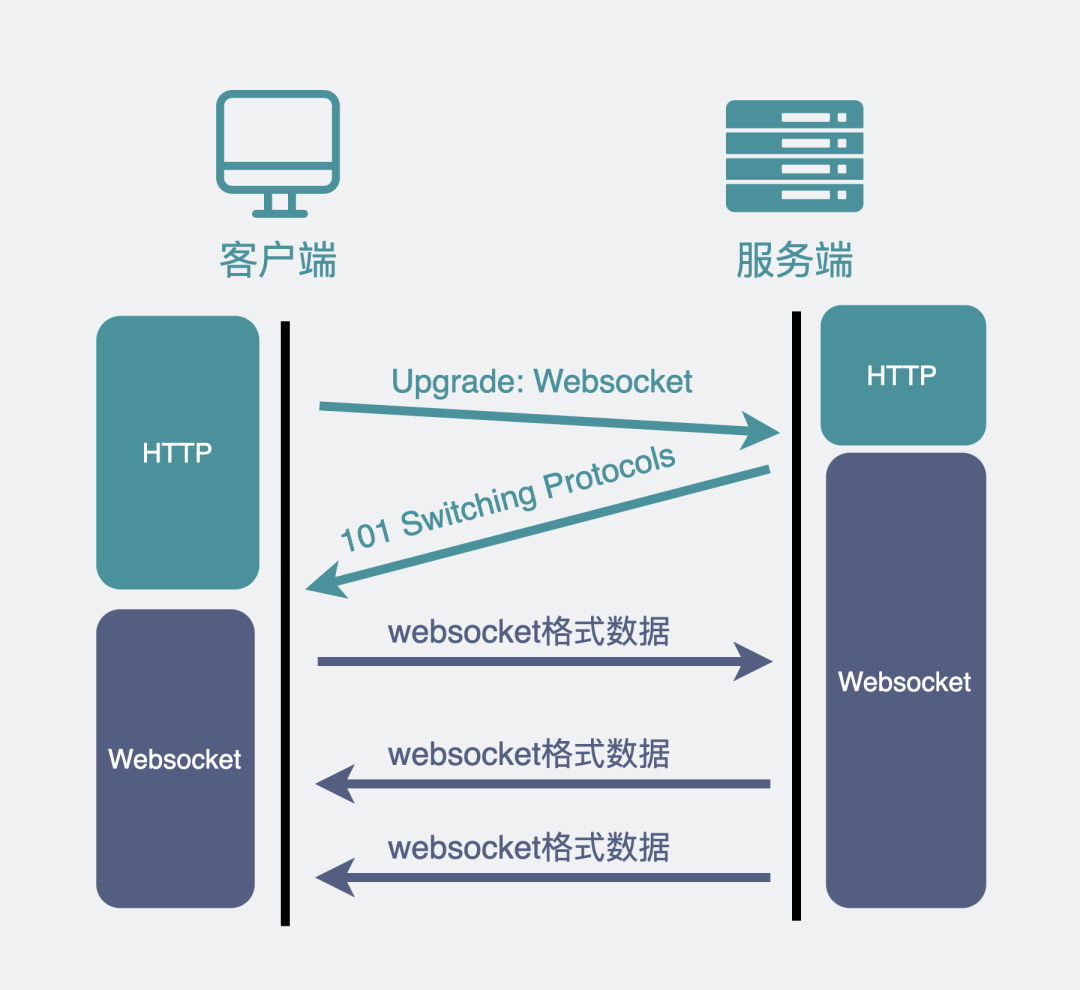
抓包如下。
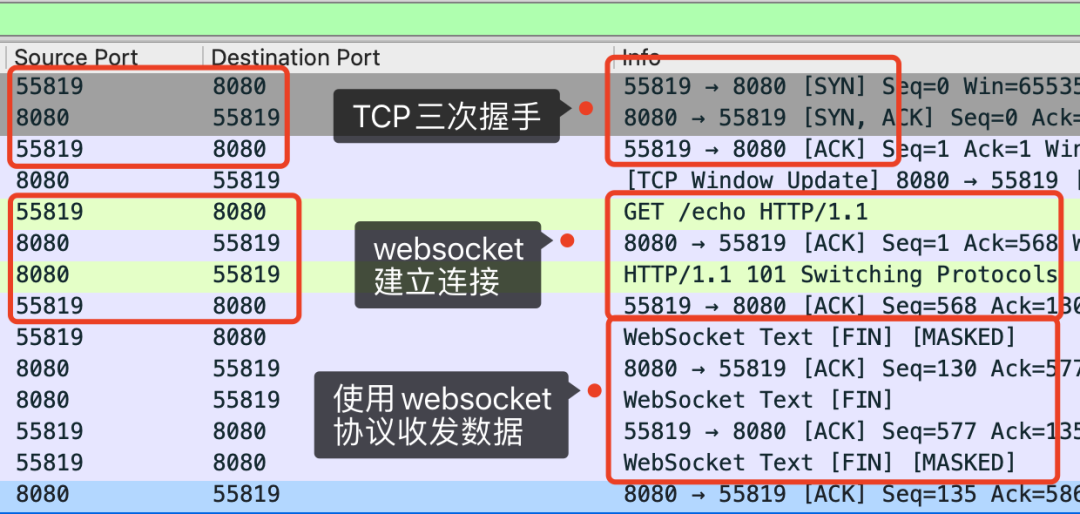
所以,WebSockett会先利用HTTP协议加上一些特殊的 header 头进行握手升级操作,但是连接建立后,就和HTTP无关了。后续都是用 WebSocket 的数据格式进行收发数据。
3.2 使用场景
WebSocket用于客户端和服务器端频繁交互的场景,比如网页游戏、网页聊天室等。HTTP协议则是平常访问某图片、文字、视频等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号