Java常用并发工具类
同步工具类存在的意义
管程或者信号量可以解决所有的并发问题,那么同步工具类存在的意义是什么呢?
两个字:方便。
针对不同的并发场景,使用对应的工具类可以快速完成业务开发。
1. 锁工具
1.1 ReadWriteLock
- 读锁
- 写锁
1.1.1 使用场景
-
允许多个线程同时读共享变量
-
只允许一个线程写共享变量
-
如果一个线程正在执行写操作,此时禁止读线程读共享变量
其实就是读锁共享锁,写锁互斥锁。除了同时读以外,其余场景均阻塞。
| 读 | 写 | |
|---|---|---|
| 读 | √ | × |
| 写 | × | × |
1.1.2 例子
class Cache<K, V> {
private final ReadWriteLock lock = new ReentrantReadWriteLock();
private final Lock writeLock = lock.writeLock();
private final Lock readLock = lock.readLock();
private final Map<K, V> cache = new HashMap<>();
// 只有1个线程可以修改值
public void put(K key, V val) {
writeLock.lock();
try {
cache.put(key, val);
} finally {
writeLock.unlock();
}
}
// 多个线程可同时获取值
public V get(K key) {
readLock.lock();
try {
return cache.get(key);
} finally {
readLock.unlock();
}
}
}
1.1.3 读写锁的降级
ReadWriteLock不支持读锁升级为写锁
锁的降级指的是写锁降级为读锁,具体操作是在写锁还未释放时就申请读锁。
锁降级预防是当前线程刚写完数据,还没进行数据处理,便被其他线程再次修改数据且不感知的情况。
锁降级例子如下, 假设Cache作为旁路缓存使用,采用数据懒加载的模式。
class Cache<K, V> {
private final ReadWriteLock lock = new ReentrantReadWriteLock();
private final Lock writeLock = lock.writeLock();
private final Lock readLock = lock.readLock();
private final Map<K, V> cache = new HashMap<>();
public V get(K key) {
V val;
readLock.lock();
try {
val = cache.get(key);
} finally {
readLock.unlock();
}
if (val != null) {
return val;
}
writeLock.lock();
val = cache.get(key);
if (val == null) { // 二次检查,避免多个线程都阻塞在写锁且再次进行数据库读取
try {
// 从数据库获取数据data, 假设有值
cache.put(key, val);
// 释放写锁前获取读锁,锁降级
readLock.lock();
} finally {
writeLock.unlock();
}
}
try {
// 使用数据val
} finally {
readLock.unlock(); // 完全释放锁,此时其他线程可以修改缓存值
}
return val;
}
}
1.2. StampedLock
- 写锁
- 读锁
- 乐观读
1.2.1 使用场景
- 写锁和读锁除了新增变量
long stamp外,语义类似ReadWriteLock - 重要的是,StampedLock的乐观读,允许一个线程获取写锁。故性能比ReadWriteLock更好。
乐观读tryOptimisticRead()需要配合validate(long stamp)验证乐观读到验证期间的这批数据(比如可以同时读多个变量)是否改变。
有点类似于MySQL的MVCC,重点是保证读的那批数据是保证一致性的,验证成功后便可继续处理,不用管处理期间值的变化。但若是乐观读期间数据变化了,便需要加乐观读锁。
1.2.2 使用例子
- 读模板
final StampedLock sl = new StampedLock();
// 乐观读
long stamp = sl.tryOptimisticRead();
// 读入方法局部变量
......
// 校验stamp
if (!sl.validate(stamp)){
// 升级为悲观读锁
stamp = sl.readLock();
try {
// 读入方法局部变量
.....
} finally {
//释放悲观读锁
sl.unlockRead(stamp);
}
}
//使用方法局部变量执行业务操作
......
- 写模板
long stamp = sl.writeLock();
try {
// 写共享变量
......
} finally {
sl.unlockWrite(stamp);
}
1.2.3 锁的降级与升级
StampedLock 支持锁的降级(tryConvertToReadLock()方法)和升级(tryConvertToWriteLock()方法)
1.3. CountDownLatch
假如泡茶有三个步骤:
- 烧水1min
- 洗杯子2min
- 泡茶1min
可以发现只有泡茶依赖烧水和洗杯子,而烧水和洗杯子之间毫无关联。
假如串行地泡茶,那么需要4分钟。如果可以一个人烧水,一个人洗杯子,那么只要3分钟。
引入线程池的话,若是仅利用管程实现需要加入计数器,且为了计数器的并发安全,要么引入原子类主线程while循环等待,要么加锁实际成了串行,都不是个好方案。利用CountDownLatch可以很方便完成。
@Setter
public class Test {
private CountDownLatch downLatch;
public void water() {
try {
System.out.println(LocalDateTime.now() + " 开始烧水");
Thread.sleep(1000);
System.out.println(LocalDateTime.now() + " 结束烧水");
downLatch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void cup() {
try {
System.out.println(LocalDateTime.now() + " 开始洗杯子");
Thread.sleep(2000);
System.out.println(LocalDateTime.now() + " 结束洗杯子");
downLatch.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void tea() {
try {
System.out.println(LocalDateTime.now() + " 等待泡茶");
downLatch.await(); // 等待烧水和洗杯子结束
System.out.println(LocalDateTime.now() + " 结束泡茶\n" );
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws InterruptedException {
Test test = new Test();
ExecutorService executors = Executors.newFixedThreadPool(2);
//for (int i = 0; i < 4; i++) { //泡茶4批次注释
test.setDownLatch(new CountDownLatch(2));
executors.submit(test::water);
executors.submit(test::cup);
test.tea();
//}
}
}
打印如下
2023-12-01T00:31:07.440 等待泡茶
2023-12-01T00:31:07.440 开始洗杯子
2023-12-01T00:31:07.440 开始烧水
2023-12-01T00:31:08.445 结束烧水
2023-12-01T00:31:09.445 结束洗杯子
2023-12-01T00:31:10.446 结束泡茶
1.4. CyclicBarrier
假如我们现在需要泡4批次的茶,即将CountDownLatch中注释的for循环启用。
其实稍微想想就可以发现泡茶期间的时间被浪费了,因为完全可以直接进行第2批次的烧水和洗杯子,如下图所示。
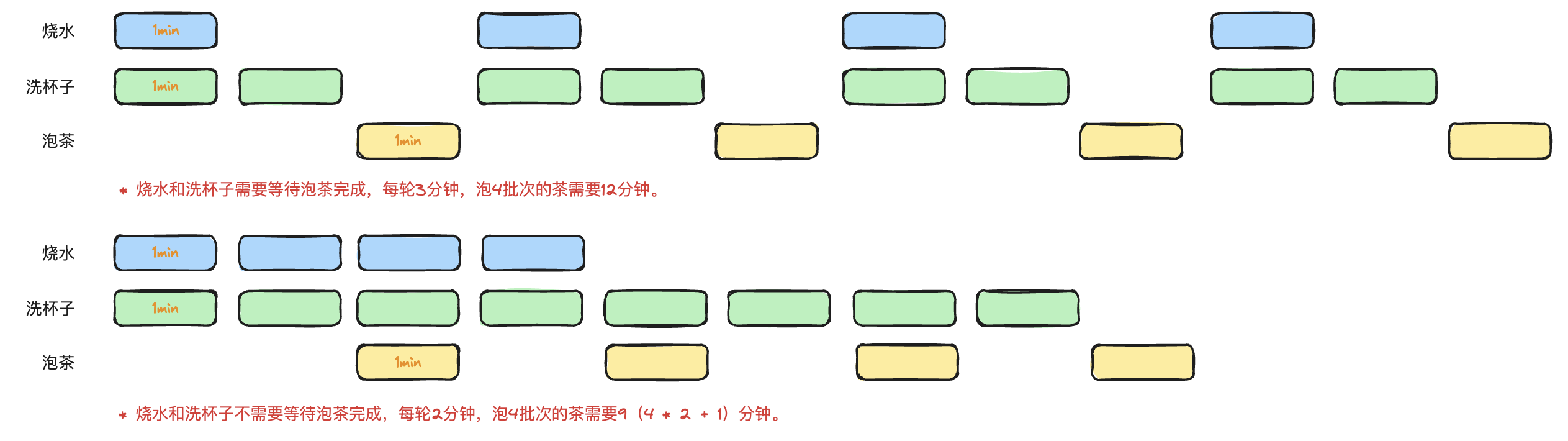
那么为了泡茶不阻塞,所以需要将泡茶也丢到子线程中执行,并且需要维持烧水/洗杯子这两步和泡茶间的依赖关系。
CyclicBarrier很轻松就能解决这个并发场景。
-
CyclicBarrier除了设置同步次数以外,还能设置次数为0时的回调函数。
-
CyclicBarrier会自动重置同步次数。
@Setter
public class Test {
private CyclicBarrier cyclicBarrier;
public void water() {
try {
System.out.println(LocalDateTime.now() + " 开始烧水");
Thread.sleep(1000);
System.out.println(LocalDateTime.now() + " 结束烧水");
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
public void cup() {
try {
System.out.println(LocalDateTime.now() + " 开始洗杯子");
Thread.sleep(2000);
System.out.println(LocalDateTime.now() + " 结束洗杯子");
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
public void tea() {
try {
System.out.println(LocalDateTime.now() + " 等待泡茶");
Thread.sleep(1000);
System.out.println(LocalDateTime.now() + " 结束泡茶" );
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService teaExecutor = Executors.newFixedThreadPool(1); // 泡茶线程池
ExecutorService executors = Executors.newFixedThreadPool(2); // 烧水/洗杯子
Test test = new Test();
CyclicBarrier cyclicBarrier = new CyclicBarrier(2, () -> teaExecutor.execute(test::tea)); // 回调函数默认使用主线程,利用线程池异步执行
test.setCyclicBarrier(cyclicBarrier);
for (int i = 0; i < 4; i++) {
executors.submit(test::water);
executors.submit(test::cup);
}
}
}
打印如下, 可以看到泡茶4批次用时为9s,和预期符合。
2023-12-01T01:23:47.279 开始烧水
2023-12-01T01:23:47.279 开始洗杯子
2023-12-01T01:23:48.284 结束烧水
2023-12-01T01:23:49.284 结束洗杯子
2023-12-01T01:23:49.287 等待泡茶
2023-12-01T01:23:49.287 开始烧水
2023-12-01T01:23:49.287 开始洗杯子
2023-12-01T01:23:50.287 结束泡茶
2023-12-01T01:23:50.289 结束烧水
2023-12-01T01:23:51.288 结束洗杯子
2023-12-01T01:23:51.288 开始烧水
2023-12-01T01:23:51.288 开始洗杯子
2023-12-01T01:23:51.288 等待泡茶
2023-12-01T01:23:52.293 结束泡茶
2023-12-01T01:23:52.293 结束烧水
2023-12-01T01:23:53.293 结束洗杯子
2023-12-01T01:23:53.293 开始烧水
2023-12-01T01:23:53.293 等待泡茶
2023-12-01T01:23:53.293 开始洗杯子
2023-12-01T01:23:54.300 结束烧水
2023-12-01T01:23:54.300 结束泡茶
2023-12-01T01:23:55.298 结束洗杯子
2023-12-01T01:23:55.299 等待泡茶
2023-12-01T01:23:56.304 结束泡茶
2. 容器工具
2.1 同步容器(Synchronized Collections)
同步容器性能差,因为就是管程的基础实现(一个共享变量,访问入口直接加锁)。
同步容器都是在public接口上加个synchronized实现,串行执行,并发度低。
举例一些常见的同步容器。
- List
- java.util.Vector
- java.util.Stack
- Java.util.Collections.synchronizedList(List
list)
- Set
- Java.util.Collections.synchronizedSet(Set
s)
- Java.util.Collections.synchronizedSet(Set
- Map
- java.util.HashTable
- java.util.Collections.synchronizeMap(Map<K,V> m)
2.2 并发容器(Concurrent Collections)
Jdk1.5引入了java.util.concurrent包,专为并发场景设计。

2.2.1 List
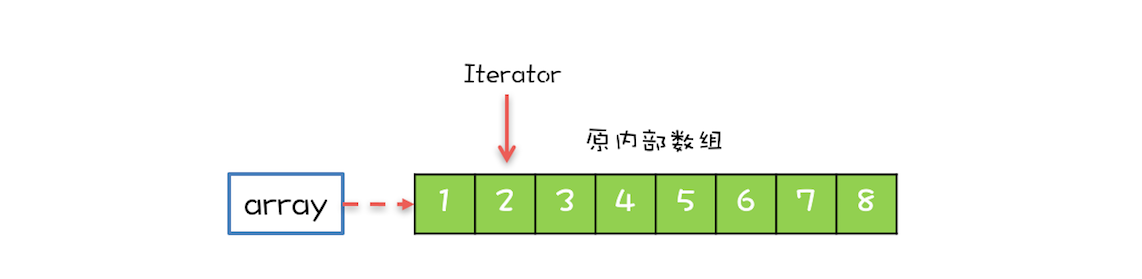
2.2.1.1 CopyOnWriteArrayList
List中唯一的并发容器类,看名字可知写时复制。这套思想在redis执行bgsave也有使用。
2.2.2 Map
2.2.2.1 ConcurrentHashMap
-
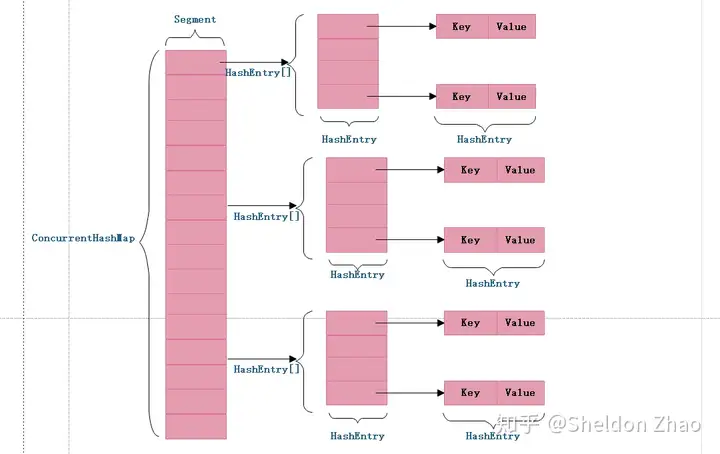
Jdk1.7
Jdk1.7使用分段锁机制,结构:Segment + HashEntry ,加锁:ReentrantLock。
每段(Segment )通过继承 ReentrantLock 来进行加锁,其实就类似于一个HashTable。通过二次映射的分段式加锁,来提升并发度。
并发级别(concurrencyLevel)默认16,其实就是有16个段,最多可以支持16个并发写。这个值只能在初始化时指定。
-
Jdk1.8
结构同HashMap类似:数组 + 链表 + 红黑树,加锁:CAS + volatile + synchronized

- 去掉了分段锁机制,使用一个包含键值对的Node数组来存储信息。锁粒度降低到了首节点。
- 解决哈希冲突的链表过长时会转为红黑树,提供O(log n)时间复杂度查询
- 通过CAS操作进行无锁扩容,使用volatile实现扩容可见性
transient volatile Node<K,V>[] table; - 读操作全程不需要加锁,仅利用volatile实现可见性;利用CAS操作进行增删改,故不加锁也不存在两个线程同时读取写入的竞态条件
get源码如下。static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; //可以看到这些都用了volatile修饰 volatile V val; volatile Node<K,V> next;- 首先计算hash值,定位到该table索引位置,如果是首节点符合就返回
- 如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
- 以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); //计算hash if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) {//读取首节点的Node元素 if ((eh = e.hash) == h) { //如果该节点就是首节点就返回 if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } //hash值为负值表示正在扩容,这个时候查的是ForwardingNode的find方法来定位到nextTable来 //eh=-1,说明该节点是一个ForwardingNode,正在迁移,此时调用ForwardingNode的find方法去nextTable里找。 //eh=-2,说明该节点是一个TreeBin,此时调用TreeBin的find方法遍历红黑树,由于红黑树有可能正在旋转变色,所以find里会有读写锁。 //eh>=0,说明该节点下挂的是一个链表,直接遍历该链表即可。 else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null; while ((e = e.next) != null) {//既不是首节点也不是ForwardingNode,那就往下遍历 if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; }
2.2.2.2 ConcurrentSkipListMap
跳表,redis中sorted set类型底层实现也有使用。时间复杂度O(log n)。
ConcurrentSkipListMap不仅线程安全,键值对也是有序的。查询效率相对ConcurrentHashMap低点。

2.2.3 Set
2.2.3.1 CopyOnWriteArraySet
原理同CopyOnWriteArrayList。
2.2.3.1 ConcurrentSkipListSet
原理同ConcurrentSkipListMap。
2.2.4 Queue
- 阻塞队列都用 Blocking 关键字标识
- 单端队列(队尾入队,队首出队)使用 Queue 标识
- 双端队列使用 Deque 标识。Deque接口/类都继承自Queue接口/类。
2.2.4.1 单端阻塞队列
- ArrayBlockingQueue
内部数组实现 - LinkedBlockingQueue
内部链表实现 - SynchronousQueue
无队列,生产者线程的入队操作必须等待消费者线程的出队操作 - LinkedTransferQueue
融合 LinkedBlockingQueue 和 SynchronousQueue 的功能,性能比 LinkedBlockingQueue 更好 - PriorityBlockingQueue
按照优先级出队 - DelayQueue
支持延时出队,按照延时时间排序出队
2.2.4.2 双端阻塞队列
LinkedBlockingDeque
2.2.4.3 单端非阻塞队列
ConcurrentLinkedQueue
2.2.4.4 双端非阻塞队列
ConcurrentLinkedDeque
3. 原子类工具

3.1 原子类基础类型
AtomicBoolean、AtomicInteger、 AtomicLong,主要涉及以下方法:
getAndIncrement() //原子化i++
getAndDecrement() //原子化的i--
incrementAndGet() //原子化的++i
decrementAndGet() //原子化的--i
//当前值+=delta,返回+=前的值
getAndAdd(delta)
//当前值+=delta,返回+=后的值
addAndGet(delta)
//CAS操作,返回是否成功
compareAndSet(expect, update)
//以下四个方法
//新值可以通过传入func函数来计算
getAndUpdate(func)
updateAndGet(func)
getAndAccumulate(x,func)
accumulateAndGet(x,func)
3.2 原子化的对象引用类型
AtomicReference/AtomicStampedReference/AtomicMarkableReference,其中AtomicStampedReference可以解决 ABA 问题,AtomicMarkableReference用于表示引用值是否已逻辑删除。
AtomicStampedReference类更新的时候会带上stamp值,通过CAS更新
boolean compareAndSet(
V expectedReference,
V newReference,
int expectedStamp,
int newStamp)
AtomicMarkableReference通过Mark值来标记是否已删除。
如果一个线程想要删除这份数据,但同时另一个线程正在使用这份数据,那么这个线程可能会在数据被删除前先读取一份副本,然后在其上执行一些操作。在这个过程中,如果原始数据被标记为已删除,那么正在使用数据的线程可能会发现这个标记,从而避免使用已经删除的数据。
boolean compareAndSet(
V expectedReference,
V newReference,
boolean expectedMark,
boolean newMark)
3.3 原子化数组
tomicIntegerArray、AtomicLongArray、 AtomicReferenceArray,比起原子类基础类型主要是多了个索引参数。
3.4 原子化对象属性更新器
AtomicIntegerFieldUpdater、AtomicLongFieldUpdater 和 AtomicReferenceFieldUpdater,利用它们可以原子化地更新对象的属性,这三个方法都是利用反射机制实现的,创建更新器的方法如下:
public static <U> AtomicXXXFieldUpdater<U> newUpdater(Class<U> tclass, String fieldName)
需要注意的是,对象属性必须是 volatile 类型的,只有这样才能保证可见性;如果对象属性不是 volatile 类型的,newUpdater() 方法会抛出 IllegalArgumentException 这个运行时异常。
newUpdater() 的方法参数只有类的信息,没有对象的引用,而更新对象的属性,一定需要对象的引用,那这个参数是在哪里传入的呢?是在原子操作的方法参数中传入的。例如 compareAndSet() 这个原子操作,相比原子化的基本数据类型多了一个对象引用 obj。
原子化对象属性更新器相关的方法,相比原子化的基本数据类型仅仅是多了对象引用参数.
3.5 原子化的累加器
DoubleAccumulator、DoubleAdder、LongAccumulator 和 LongAdder,这四个类仅仅用来执行累加操作。
相比原子化的基本数据类型,速度更快,但是不支持 compareAndSet() 方法。如、
4. 异步协同工具
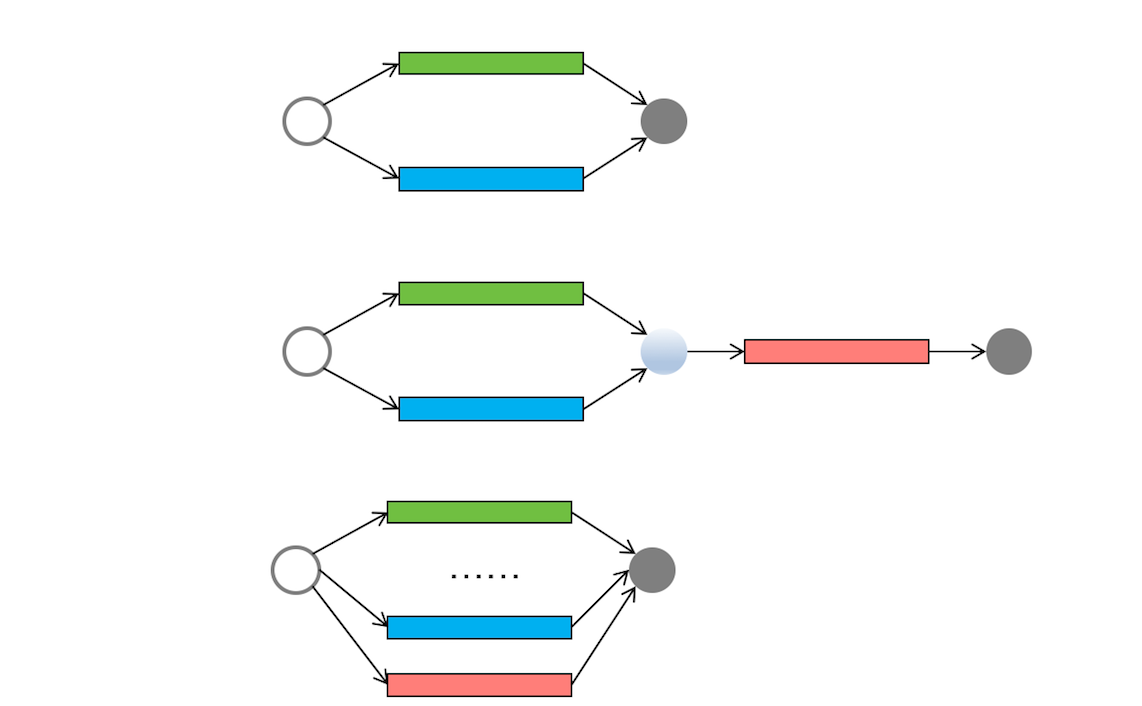
异步协同可以分为4种:
- 简单依赖
- 串行/集合编排
- 批量执行
- 分治执行
4.1. Future接口
4.1.1 Future接口
// 取消任务
boolean cancel(boolean mayInterruptIfRunning);
// 判断任务是否已取消
boolean isCancelled();
// 判断任务是否已结束
boolean isDone();
// 获得任务执行结果
get();
// 获得任务执行结果,支持超时
get(long timeout, TimeUnit unit);
两个get方法都是阻塞式地等待结果返回。
4.1.2 FutureTask类
FutureTask实现了RunnableFuture接口,拥有Runnable接口及Future接口的特性。
public interface RunnableFuture<V> extends Runnable, Future<V> { ... }
进阶版泡茶流程。

好,现在可以泡茶了。可以看到泡茶依赖于烧开水/洗茶壶/洗茶杯/拿茶叶,而烧开水又依赖于洗水壶。烧开水的时间较久,
所以可以两个线程,线程A执行洗水壶->烧开水->泡茶,线程B执行洗茶壶->洗茶杯->拿茶叶。
利用FutureTask可以直接start/join原始实现,这里使用线程池利用Future即可。
ExecutorService service = Executors.newFixedThreadPool(2);
Future<String> futureB = service.submit(() -> {
System.out.println("T2:洗茶壶...");
TimeUnit.SECONDS.sleep(1);
System.out.println("T2:洗茶杯...");
TimeUnit.SECONDS.sleep(2);
System.out.println("T2:拿茶叶...");
TimeUnit.SECONDS.sleep(1);
return "龙井";
});
Future<String> futureA = service.submit(() -> {
System.out.println("T1:洗水壶...");
TimeUnit.SECONDS.sleep(1);
System.out.println("T1:烧开水...");
TimeUnit.SECONDS.sleep(15);
String tf = futureB.get();
System.out.println("T1:泡茶...");
return "上茶:" + tf;
});
System.out.println(futureA.get());
service.shutdown();
4.2. CompletableFuture接口
CompletableFuture支持异步任务的编排。
- 无需手工维护线程关系,如上个例子中的futureA还需要显式等待
futureB.get()完成。 - 语义更清晰,可以专注于业务代码实现
这里将泡茶独立成一个单独任务。

CompletableFuture<Void> f1 = CompletableFuture.runAsync(() -> {
try {
System.out.println("T1:洗水壶...");
TimeUnit.SECONDS.sleep(1);
System.out.println("T1:烧开水...");
TimeUnit.SECONDS.sleep(15);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
CompletableFuture<String> f2 = CompletableFuture.supplyAsync(() -> {
try {
System.out.println("T2:洗茶壶...");
TimeUnit.SECONDS.sleep(1);
System.out.println("T2:洗茶杯...");
TimeUnit.SECONDS.sleep(2);
System.out.println("T2:拿茶叶...");
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "龙井";
});
CompletableFuture<String> f3 = f1.thenCombine(f2, (__, f2Result) -> "上茶:" + f2Result); // f1无返回值用__代替
System.out.println(f3.get());
默认情况下 CompletableFuture 会使用公共的 ForkJoinPool 线程池,这个线程池默认创建的线程数是 CPU 的核数。生产代码建议自定义线程池使用。
观察实现的接口,可以发现异步等待及结果返回都是通过Future实现,那么异步任务编排肯定就是通过CompletionStage<T>接口实现的了。
public class CompletableFuture<T> implements Future, CompletionStage<T> { ... }
4.2.1 CompletionStage接口
- 不带Async系列的方法: 沿用上一个执行任务所使用的线程池进行处理
- 带Async系列的方法
- 不指定线程池:使用默认ForkJoinPool线程池
- 指定线程池: 使用指定线程池
4.2.1.1 串行编排
// thenApply系列有参有返回
CompletionStage<R> thenApply(fn);
CompletionStage<R> thenApplyAsync(fn);
// thenAccept系列有参无返回
CompletionStage<Void> thenAccept(consumer);
CompletionStage<Void> thenAcceptAsync(consumer);
// thenRun系列无参无返回
CompletionStage<Void> thenRun(action);
CompletionStage<Void> thenRunAsync(action);
// thenCompose系列会新创建子流程,结果等同thenApply系列方法
CompletionStage<R> thenCompose(fn);
CompletionStage<R> thenComposeAsync(fn);
thenApply的使用例子如下。
CompletableFuture<String> f0 = CompletableFuture
.supplyAsync(() -> "Hello World")
.thenApply(s -> s + " QQ")
.thenApply(String::toUpperCase);
System.out.println(f0.get()); // HELLO WORLD QQ
4.2.1.2 汇聚编排
AND关系
// thenCombine系列有参有返回
CompletionStage<R> thenCombine(other, fn);
CompletionStage<R> thenCombineAsync(other, fn);
// thenAcceptBoth系列有参无返回
CompletionStage<Void> thenAcceptBoth(other, consumer);
CompletionStage<Void> thenAcceptBothAsync(other, consumer);
// runAfterBoth系列无参无返回
CompletionStage<Void> runAfterBoth(other, action);
CompletionStage<Void> runAfterBothAsync(other, action);
OR关系
// applyToEither系列有参有返回
CompletionStage applyToEither(other, fn);
CompletionStage applyToEitherAsync(other, fn);
// acceptEither系列有参无返回
CompletionStage acceptEither(other, consumer);
CompletionStage acceptEitherAsync(other, consumer);
// runAfterEither系列无参无返回
CompletionStage runAfterEither(other, action);
CompletionStage runAfterEitherAsync(other, action);
4.2.1.3 异常处理编排
// 类似try{}catch{}中的 catch{}
CompletionStage exceptionally(fn);
// 类似try{}finally{}中的 finally{},支持返回结果
CompletionStage<R> handle(fn);
CompletionStage<R> handleAsync(fn);
// 类似try{}finally{}中的 finally{},不支持返回结果
CompletionStage<R> whenComplete(consumer);
CompletionStage<R> whenCompleteAsync(consumer);
4.3. CompletionService
小明要做一个询价应用,这个应用需要从三个电商询价,然后保存在自己的数据库里。如何优化?
// 向电商S1询价,并保存
r1 = getPriceByS1();
save(r1);
// 向电商S2询价,并保存
r2 = getPriceByS2();
save(r2);
// 向电商S3询价,并保存
r3 = getPriceByS3();
save(r3);
首先考虑异步化询价。
// 创建线程池
ExecutorService executor =
Executors.newFixedThreadPool(3);
// 异步向电商S1询价
Future<Integer> f1 =
executor.submit(
()->getPriceByS1());
// 异步向电商S2询价
Future<Integer> f2 =
executor.submit(
()->getPriceByS2());
// 异步向电商S3询价
Future<Integer> f3 =
executor.submit(
()->getPriceByS3());
// 获取电商S1报价并保存
r=f1.get();
executor.execute(()->save(r));
// 获取电商S2报价并保存
r=f2.get();
executor.execute(()->save(r));
// 获取电商S3报价并保存
r=f3.get();
executor.execute(()->save(r));
虽然异步了,但是如果f1.get()和后续依然有阻塞关系。再次优化。
// 创建阻塞队列
BlockingQueue<Integer> bq = new LinkedBlockingQueue<>();
//电商S1报价异步进入阻塞队列
executor.execute(()-> bq.put(f1.get()));
//电商S2报价异步进入阻塞队列
executor.execute(()-> bq.put(f2.get()));
//电商S3报价异步进入阻塞队列
executor.execute(()-> bq.put(f3.get()));
//异步保存所有报价
for (int i=0; i<3; i++) {
Integer r = bq.take();
executor.execute(()->save(r));
}
这样可以实现先返回的报价先入库。
CompletionService便是这样的一个并发工具类,内部通过一个阻塞队列实现优先返回的结果先出队列。但是队列保存的是Future对象,而非具体结果。
构造函数如下。
ExecutorCompletionService(Executor executor); \\ 默认阻塞队列为无界的 LinkedBlockingQueue
ExecutorCompletionService(Executor executor, BlockingQueue> completionQueue)。
支持的方法如下。
Future<V> submit(Callable<V> task);
Future<V> submit(Runnable task, V result);
Future<V> take() throws InterruptedException;
Future<V> poll();
Future<V> poll(long timeout, TimeUnit unit) throws InterruptedException;
利用CompletionService优化后的代码如下。
// 创建线程池
ExecutorService executor = Executors.newFixedThreadPool(3);
// 创建CompletionService
CompletionService<Integer> cs = new ExecutorCompletionService<>(executor);
// 异步向电商S1询价
cs.submit(()->getPriceByS1());
// 异步向电商S2询价
cs.submit(()->getPriceByS2());
// 异步向电商S3询价
cs.submit(()->getPriceByS3());
// 将询价结果异步保存到数据库
for (int i=0; i<3; i++) {
Integer r = cs.take().get();
executor.execute(()->save(r));
}
4.4. Fork/Join
Fork/Join 计算框架主要包含两部分,一部分是分治任务的线程池 ForkJoinPool,另一部分是分治任务 ForkJoinTask。
类似于 ThreadPoolExecutor 和 Runnable 的关系,都可以理解为提交任务到线程池,只不过分治任务有自己独特类型 ForkJoinTask。
ForkJoinTask 是一个抽象类,它的方法有很多,最核心的是 fork() 方法和 join() 方法,其中 fork() 方法会异步地执行一个子任务,而 join() 方法则会阻塞当前线程来等待子任务的执行结果。
ForkJoinTask 有两个抽象子类——RecursiveAction 和 RecursiveTask,都是用递归的方式来处理分治任务的。
这两个子类都定义了抽象方法 compute(),不过RecursiveAction没有返回值,而 RecursiveTask有返回值的。需要自定义实现类使用。
计算斐波那契数列的例子。
public static void main(String[] args) {
//创建分治任务线程池
ForkJoinPool fjp = new ForkJoinPool(4);
//创建分治任务
Fibonacci fib = new Fibonacci(6);
//启动分治任务
Integer result = fjp.invoke(fib);
//输出结果
System.out.println(result);
}
static class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) { // compute()方法没有入参,通过构造函数传参
this.n = n;
}
protected Integer compute() {
if (n <= 1) {
return n;
}
Fibonacci f1 = new Fibonacci(n - 1);
Fibonacci f2 = new Fibonacci(n - 2);
//创建子任务
f1.fork();
f2.fork();
//等待子任务结果,并合并结果
return f2.join() + f1.join(); // 子任务的join必须倒序,类似出栈
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号