深度学习基本概念的了解
机器学习的思路:利用一些训练数据,使机器能够总结出一些规律,然后用这些规律来分析未知数据。
举个生活的例子:
Q:为什么高考前需要大量的刷题??请从深度学习解答一下。
高考为例,高考的题目我们没有做过,但是高中三年我们做过很多很多题目,由此学会了解题方法,因此考场上面对陌生问题也可以算出答案。
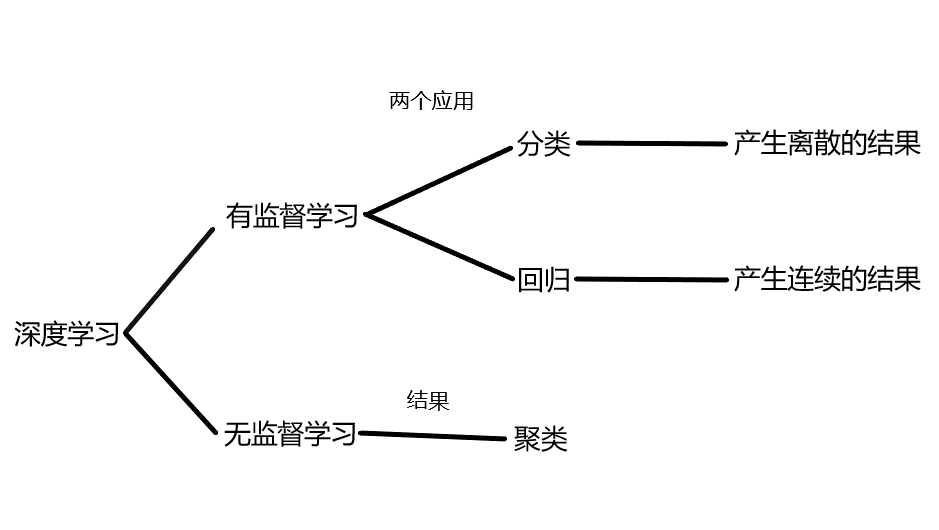
申明:非原创,转载自《有监督学习、无监督学习、分类、聚类、回归等概念》
如有侵权,请联系删除。
这篇是很久之前写的了.. 后来才开始上 Andrew Ng 老师的 MOOC,发现其实老师讲得很好了,建议有时间看看他的《Machina Learning》,只看第一节课就可以很了解这些概念了。
主要内容
- 有监督学习、无监督学习、分类、聚类、回归等概念
有监督学习、无监督学习、分类、聚类、回归等概念
这里举一个给书本分类的例子。部分参考 什么是无监督学习? - 王丰的回答 - 知乎 。
-
特征(feature)
数据的特征。
书的内容。
-
标签(label)
数据的标签。
书属于的类别,例如“计算机”“图形学”“英文书”“教材”等。
-
学习(learning)
将很多数据丢给计算机分析,以此来训练该计算机,培养计算机给数据分类的能力。换句话说,学习指的就是找到特征与标签的映射(mapping)关系。这样当有特征而无标签的未知数据输入时,我们就可以通过已有的关系得到未知数据标签。
把很多书交给一个学生,培养他给书本分类的能力。
-
有监督学习(supervised learning)
不仅把训练数据丢给计算机,而且还把分类的结果(数据具有的标签)也一并丢给计算机分析。
由于计算机在学习的过程中不仅有训练数据,而且有训练结果(标签),因此训练的效果通常不错。训练结束之后进行测试不仅把书给学生进行训练给书本分类的能力,而且把分类的结果(哪本书属于哪些类别)也给了学生做标准参考。
计算机进行学习之后,再丢给它新的未知的数据,它也能计算出该数据导致各种结果的概率,给你一个最接近正确的结果。
-
无监督学习(unsupervised learning)
只给计算机训练数据,不给结果(标签),因此计算机无法准确地知道哪些数据具有哪些标签,只能凭借强大的计算能力分析数据的特征,从而得到一定的成果,通常是得到一些集合,集合内的数据在某些特征上相同或相似。
只给学生进行未分类的书本进行训练,不给标准参考,学生只能自己分析哪些书比较像,根据相同与相似点列出清单,说明哪些书比较可能是同一类别的。
-
半监督学习(semi-supervised learning)
给计算机大量训练数据与少量的分类结果(具有同一标签的集合)。
给学生很多未分类的书本与少量的清单,清单上说明哪些书属于同一类别。
-
聚类(clustering)
无监督学习的结果。聚类的结果将产生一组集合,集合中的对象与同集合中的对象彼此相似,与其他集合中的对象相异。
没有标准参考的学生给书本分的类别,表示自己认为这些书可能是同一类别的(具体什么类别不知道)。
-
分类(classification)
有监督学习的两大应用之一,产生离散的结果。
例如向模型输入人的各种数据的训练样本,产生“输入一个人的数据,判断是否患有癌症”的结果,结果必定是离散的,只有“是”或“否”。
-
回归(regression)
有监督学习的两大应用之一,产生连续的结果。
例如向模型输入人的各种数据的训练样本,产生“输入一个人的数据,判断此人20年后今后的经济能力”的结果,结果是连续的,往往得到一条回归曲线。当输入自变量不同时,输出的因变量非离散分布。
看不懂可以再看看下面这个例子:)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号