
Selenium---Pom思想
在学习selenium中接触到POM,POM(Page Object Model)页面对象模型,这种设计模式就是将每个测试页面都写一个页面对象类class,然后将界面的繁琐的元素定位封装在这个页面对象中,只对外提供必要的操作接口。
POM思想的好处:
POM将页面定位和业务操作分开,分离了测试对象和测试脚本。之前在一开始练习的时候,都是在测试脚本中既进行元素定位,又进行一些业务操作,并通过unittest执行测试。现在如果UI更改了界面,测试脚本则不需要做修改,只要更改页面对象中的元素定位即可,提高了可维护性。
POM的目的:是为了解决前端中UI变化频繁,从而造成测试自动化脚本维护的成本越来越大。
如图: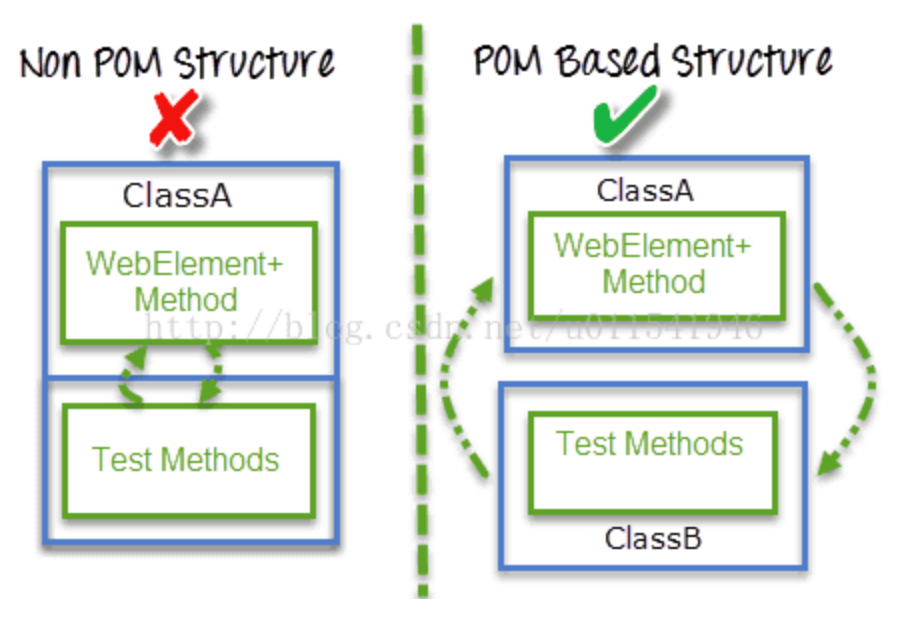
左侧就是页面对象元素和测试代码都写在一个文件中,如果需要更改前端页面,那么就要修改页面元素定位,从而要修改这个类中的测试代码,就会相当混乱。
右侧,采取POM后,把页面元素和业务逻辑和测试脚本分离到两个不同的类文件中。ClassA只写页面元素定位和业务逻辑代码操作的封装,ClassB只写测试脚本,不关心如何元素定位,如果前端UI发生变化,那么只需要去修改ClassA的元素定位,而不需要去动ClassB的测试代码。
POM主要有以下优点:
①把web ui对象从测试脚本中分离出来,业务代码和测试脚本实现分离
②每个待测页面对应一个页面类,页面的元素写到这个页面类中
③页面类主要包括了该页面的元素定位,和这些元素的业务操作封装的方法
④代码高复用,从而减少测试脚本代码量
⑤层次清晰,同时多个人编写也不会互相影响
⑥建议页面类和业务逻辑方法都能有特定意思的类名,方便理解
⑦每个页面类都继承一个基类,所以要将一些常用的页面操作方法直接封装成一个BasePage类,供所有页面类去继承
※BasePage页面基类中的定位元素方法:
#定位元素的方法
def find_element(self,selector):
"""
这个地方为什么是根据=>来切割字符串,请看页面里定位元素的方法
submit_btn = "id=>su"
login_lnk = "xpath => //*[@id='u1']/a[7]" # 百度首页登录链接定位
如果采用等号,结果很多xpath表达式中包含一个=,这样会造成切割不准确,影响元素定位
:param selector:
:return: element
"""
element = ''
if '=>' not in selector:
return self.driver.find_element_by_id(selector)
selector_by = selector.split('=>')[0]
selector_value = selector.split('=>')[1]
print(selector_value)
if selector_by == "i" or selector_by == "id":
try:
element = self.driver.find_element_by_id(selector_value)
mylog.info("成功找到元素 %s" %selector_value)
except NoSuchElementException as e:
mylog.error(e)
self.get_screenshots()
elif selector_by == "n" or selector_by == "name":
element = self.driver.find_element_by_name(selector_value)
elif selector_by == "c" or selector_by == "class_name":
element = self.driver.find_element_by_class_name(selector_value)
elif selector_by == "l" or selector_by == "link_text":
element = self.driver.find_element_by_link_text(selector_value)
elif selector_by == "p" or selector_by == "partial_link_text":
element = self.driver.find_element_by_partial_link_text(selector_value)
elif selector_by == "t" or selector_by == "tag_name":
element = self.driver.find_element_by_tag_name(selector_value)
elif selector_by == "x" or selector_by == "xpath":
try:
element = self.driver.find_element_by_xpath(selector_value)
mylog.info("成功找到元素 %s" %selector_value)
except NoSuchElementException as e:
mylog.error(e)
self.get_screenshots()
elif selector_by == "s" or selector_by == "selector_selector":
element = self.driver.find_element_by_css_selector(selector_value)
else:
raise NameError("Please enter a valid type of targeting elements.")
print(element)
return element

