算法设计与分析5_Probabilistic Algorithms
算法设计与分析5_概率算法
算法导论,第五章 概率算法
概率分析相关知识
盲盒问题
盲盒问题: 假设有 \(b\) 种盲盒,每次抽到某个盲盒的概率是 1/b。你想知道,平均需要抽多少次才能集齐所有的盲盒。
计算
-
假设我们一次购买买到一个之前没买到的新的款式,则称作一次命中( hit
问题转化为:求有 b 次命中时,购买次数 n 的期望 -
将购买次数 n 分成若干个阶段,第 i 阶段表示从第i-1 次命中到第 i 次命中之间的购买,购买次数为\(n_i\) ,服从几何分布。
第 i 阶段得到一次命中的概率: \(未买到的款式个数 / 总款式个数 = (b- i+1)/ b\)
几何分布:一系列伯努利试验,其中每次成功概率为p 、失败概率为 1-p ,在获得一次成功前要进行的试验次数服从几何分布。
几何分布期望为1/ p
朴素理解
- 第一次抽,肯定能得到一个新盲盒。
- 第二次抽,抽到没收集过的盲盒的概率是 \(\frac{b-1}{b}\),所以平均需要 \(\frac{b}{b-1}\) 次才能得到另一个新盲盒。
- 第三次抽,抽到没收集过的盲盒的概率是 \(\frac{b-2}{b}\),需要 \(\frac{b}{b-2}\) 次,依此类推。
最终,需要的平均次数是:
\( T_b = b \times \left( \frac{1}{b} + \frac{1}{b-1} + \frac{1}{b-2} + \cdots + 1 \right) \)
第 \(i\) 阶段购买次数为 \(n_i\)。总购买次数 \(n\) 为所有阶段购买次数的总和,即 \(n = \sum_{i=1}^b n_i\)。
- 期望值计算:
- 第 \(i\) 阶段购买次数的期望 \(E[n_i]\) 为 \(\frac{b}{b-i+1}\)。
- 总购买次数的期望 \(E[n]\) 为所有阶段购买次数期望的总和,即 \(E[n] = \sum_{i=1}^b E[n_i] = \sum_{i=1}^b \frac{b}{b-i+1} = b \sum_{i=1}^b \frac{1}{i}\)。
- 利用调和级数的性质,\(\sum_{i=1}^b \frac{1}{i}\) 近似等于 \(\ln b + O(1)\),其中 \(O(1)\) 表示常数项。
- 因此,\(E[n] \approx b (\ln b + O(1))\)。
故,为了集齐所有款式的盲盒,大概需要购买 \(b \ln b\) 次。
- 假设 \(b = 30\),代入公式计算得到预期购买次数约为 103 次。
Sherwood 算法
雇佣问题
假如你要雇用一名新的办公助理,雇用代理每天给你推荐一个应聘者,你面试这个人,然后决定是否雇用他。
支出:支付给雇用代理费用 \(c_i\) 以面试应聘者、支付给雇用者雇用费用\(c_h\)
设计代码:
HIRE_ASSISTANT(n)
best ← 0
for i ← 1 to n do
interview candidate i
if candidate i is better than candidate best
best ← i
hire candiate
总费用:\(O(c_i n+c_h m)\) // m:雇用人数
面试者之间相互商量?
改为概率算法(随机算法):
RANDOMIZED_HIRE_ASSISTANT(n)
randomly permute the list of candidates
best ← 0
for i ← 1 to n do
interview candidate i
if candidate i is better than candidate best
best ← i
hire candiate
雇用费用期望:\(O(c_h \ln{n})\)
Sherwood算法详解
- 分析确定性算法在 平均情况 下的时间复杂度时,通常假定算法的 输入实例满足某一特定的概率分布
很多算法对于 不同输入实例运行时间差别很大可采用 Sherwood 概率算法 消除时间复杂度与输入实例间的依赖关系
对于Sherwood算法,通常有两种方式:
-
在确定性算法的某些步骤引入 随机因素
-
仅对 输入实例随机处理 ,再执行确定性算法
Sherwood 算法能够平滑不同输入实例的执行时间
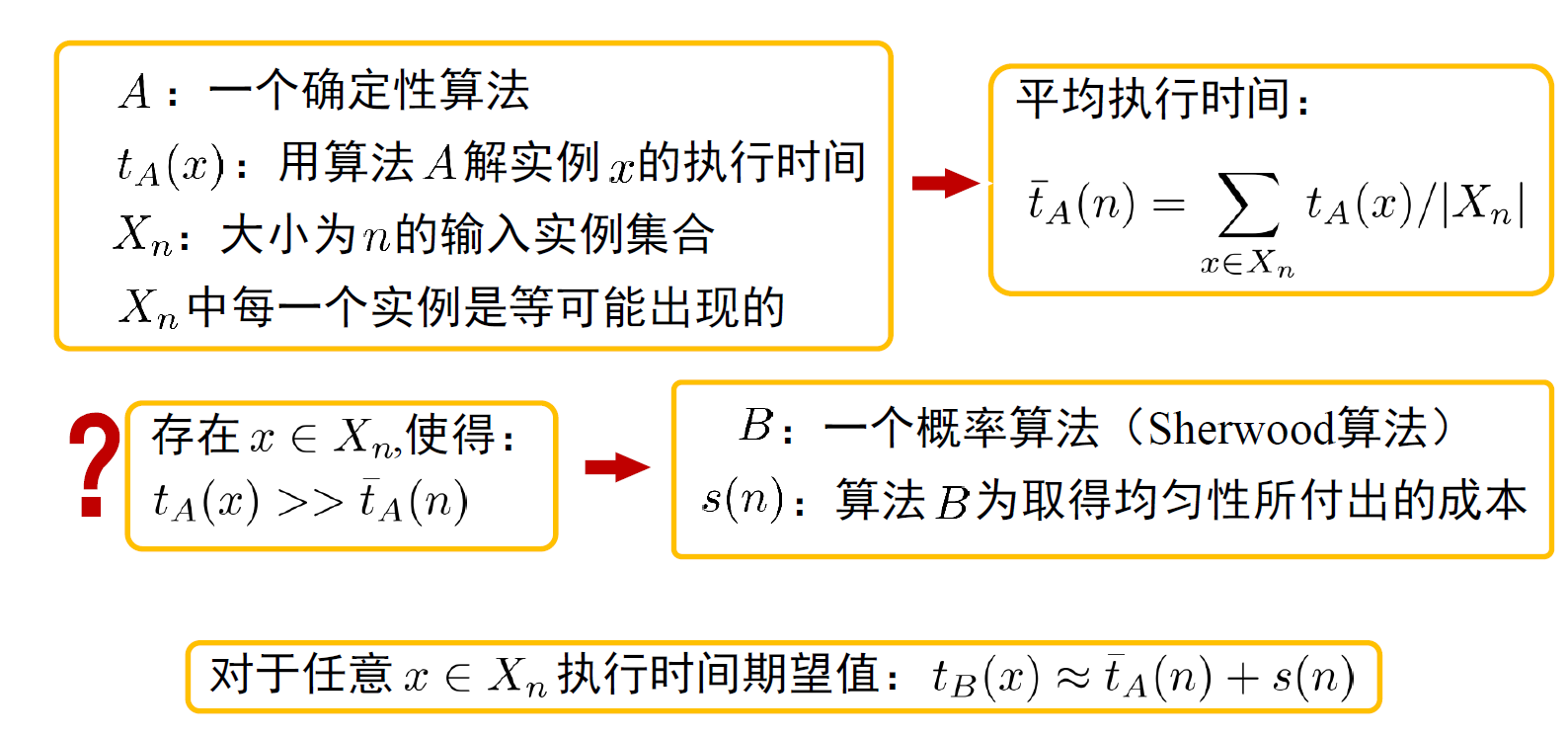
对于任意x执行时间期望值:\(t_B(x) = t_A(n)+s(n)\)

Sherwood 算法的平均执行时间 略为增加
注意:不再有最坏情况的实例,但有最坏的执行时间
例:快速排序
平均时间复杂度 \(O(n\lg{n})\) ,但是对有序数列排序:时间复杂度 \(O(n^2)\)
例如:初始序列:30 25 19 12 6 一次划分:\([6, 25, 19, 12] 30 []\) 划分不均衡
如何提升最坏情况性能?
-
想法一:每次随机选择划分元
初始序列:30 25 19 12 6 , 随机选择划分元位置,位置调整:19 25 30 12 6,一次划分:\([6, 12] 19 [25, 30]\) 划分较均衡 -
想法二:把初始序列打乱
初始序列:30 25 19 12 6,打乱顺序:12 30 6 19 25,一次划分:\([6]12 [30, 19, 25]\) 划分较均衡
引入随机因素
RAND_QUICKSORT(A , low , high)
// A : 待排序数组, low high 排序起始 终止下标
if low < high
i ← low , high ); //low high 随机抽取一个下标
swap(A [ [low ], A [i]
k ← A , low , high
RAND_QUICKSORT(A , low , k 1)
RAND_QUICKSORT(A , k +1, high)
输入实例随机处理
原算法较复杂,很难对其进行修改时可适用
SHUFFLE(A)
n ← A length
for i ← 1 to n 1 do
//在 A i n 中随机选一个元素放在 A i 上
j ← i , n
swap(A [i], A [j])
执行原确定性算法
应用:随机的预处理
f (x) 对应的确定性算法可改造为 Sherwood 算法
RH(x )// 用 Sherwood 算法计算 f x
n ← x //length x 的大小为 n
r ← RANDOM( A_n ) //随机取一元素
z ← u ( x , r ) //将原实例 x 转化为随机实例 z
s ← f ( z ) //用确定性算法求 z 的解 s
return v (r , s ) //将解 s 变换为 x 的解
随机的预处理提供了一种加密计算的可能性
如果:
-
想针对某个实例 x 计算 f x
-
但缺乏计算能力或有效算法,别人可提供服务计算,又不想泄露输入实例 x
可以:
- 使用函数 u 将 x 加密为某一随机实例 z
- 将 z 提交给 f 计算出 f z 的值
- 使用函数 v 转换为 f x
Sherwood算法详解
什么是Sherwood算法?
Sherwood算法,是一种随机化算法,它的核心思想是通过引入随机性来改善算法的性能,特别是针对那些在某些特定输入下性能极差的确定性算法。这种算法的命名来源于罗宾汉的森林,寓意着通过随机化的手段,将算法的性能从最坏情况中“解救”出来。
Sherwood算法的原理
- 确定性算法与随机化算法:
- 确定性算法: 给定相同的输入,总是产生相同的输出。
- 随机化算法: 算法的行为部分依赖于随机数生成器,对于相同的输入,可能产生不同的输出。
- Sherwood算法的思路:
- 对于一个确定性算法A,当它的输入实例为x时所需的计算时间记为tA(x)。
- 与输入实例有关,此时可引入随机性将之改造成一个Sherwood算法。
- 有时候无法直接把确定性算法改造为Sherwood算法,这时候对输入洗牌(随机的预处理)。
Sherwood算法的优势
- 改善最坏情况性能: 通过引入随机性,可以有效地降低算法在最坏情况下的运行时间,使得算法的整体性能更加稳定。
- 简化算法设计: 在某些情况下,通过随机化可以简化算法的设计,使得算法的实现更加容易。
- 提高算法的灵活性: 随机化算法可以适应更多的输入情况,具有更好的通用性。
Sherwood算法的应用场景
- 排序算法: 快速排序、堆排序等算法在某些特殊输入下性能会退化,通过随机化可以改善这种情况。
- 图算法: 在图论中,许多问题都可以通过随机化算法来解决,例如最小生成树问题、图着色问题等。
- 密码学: 随机化是密码学中非常重要的一项技术,例如随机数生成器、加密算法等。
Sherwood算法的实现
实现一个Sherwood算法通常涉及以下步骤:
- 分析原有确定性算法: 找出算法性能瓶颈所在。
- 引入随机性: 在算法的适当位置引入随机数生成器,例如随机化输入顺序、随机选择分支等。
- 评估算法性能: 通过实验或理论分析来评估新算法的性能,包括平均运行时间、最坏情况运行时间等。
Sherwood算法的局限性
- 随机性带来的不确定性: 随机化算法的输出可能不是确定的,这在某些应用场景下可能是不允许的。
- 随机数生成器的质量: 随机数生成器的质量会影响算法的性能,一个好的随机数生成器是至关重要的。
- 算法分析的复杂性: 随机化算法的分析通常比确定性算法更加复杂。
Las Vegas算法和Monte Carlo算法
问题 给定 n 个元素( n 非常大)的无序序列 A ,已知至少有一半元素大于 k ,我们想找到任一个元素值大于 k 的序列下标
对于上面问题,Las Vegas算法和Monte Carlo算法两种算法的设计如下:
Las Vegas 算法: 赌时间而不赌正确性,要么一定返回正确解,要么无解
repeat
j ← RANDOM(1, n)
until A [ j ] > k
return j
Monte Carlo 算法: 赌正确性而不赌时间。一定返回解,但可能不正确
for i ← 1 to m do // m 远小于 n
j ← RANDOM(1, n)
if A [ j ] > k
return j
return 0 // 0 表示未找到
Las Vegas算法
Las Vegas算法是一种结果可靠、时间不确定的随机化算法。该算法始终保证输出结果是正确的,但运行时间可能会有所不同,取决于随机选择的情况。
特点
-
结果保证正确:要么返回正确的解,要么随机决策导致一个僵局
-
若陷入僵局,使用同一实例运行同一算法,有独立的机会求出解
-
运行时间不确定:,成功的概率随着执行时间的增加而增加
算法的一般形式
OBSTINATE(x)//x:输入实例 y :返回值
repeat
LV(x , y , success)//success:布尔值指示执行成功 失败
until success
return y
设 \(t(x)\) 是算法 OBSTINATE 找到一个正确解的期望时间,则
- p (x):对于实例 x ,单次 LV 算法成功的概率
- s (x):对于实例 x ,单次 LV 算法成功时的期望时间
- e (x):对于实例 x ,单次 LV 算法失败时的期望时间
因此,若要最小化\(t(x)\),则需在 p(x), s(x) 和 e(x) 之间进行某种折衷。
(1 - p(x)) * (e(x) + t(x)),为什么在这里加\(t(x)\) ?
算法最终要until success,因此 当 LV(x, y) 失败时,不仅需要加上它本身的失败时间 e(x),还要考虑到 OBSTINATE(x) 算法继续运行的时间,即 t(x)。所以在计算失败时的期望时间时,必须将失败的时间 e(x) 和重新执行的期望时间 t(x) 加在一起。
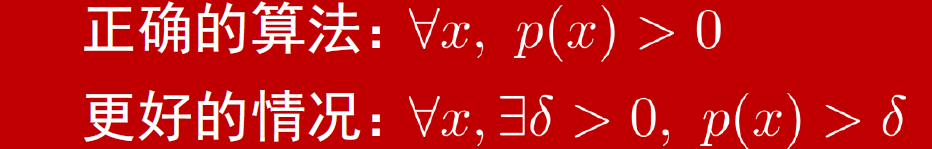
适用场景
Las Vegas算法适用于需要确保结果正确的场景。例如,在数据排序、图算法或几何问题中,Las Vegas算法可以利用随机性加快计算,但始终保证结果的准确性。
应用:八皇后问题
http://liujunming.top/2016/10/29/八皇后问题与Las-Vegas算法的结合/
问题描述
在8×8的国际象棋棋盘上放置8个皇后,使得任意两个皇后都不能互相攻击,即任意两个皇后都不能处于同一行、同一列或同一对角线上。
易得:
- 45°斜线:行列号之差相等(i-j或j-i相等)
- 135°斜线:行列号之和相等(i+j相等)
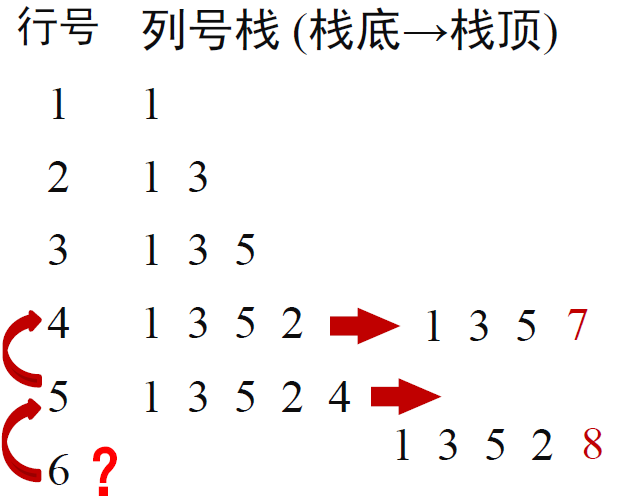
BACKTRACK 方法 伪代码
QUEENS_BACKTRACK()
i ← 1, j ← 1
while i ≤ 8 do //当前行号 i ≤ 8
从当前列 j 起向后逐列试探,寻找安全列号
if 找到安全列号
将列号 j 入栈 //i , j 位置放置皇后
i ← i + 1 //将下一行置为当前行
j ← 1 //当前列置为 1
else
i ← i - 1 //回溯到上一行
j 赋值为栈顶值,并退栈 ///移除当前皇后
j ← j + 1 //下一列作为当前列
Las Vegas 算法思路
- 逐行放置: 从第1行(k=0)逐行放置皇后。
- 随机挑选正确位置: 对当前行的每一列(i)进行判断,如果安全,则增加安全位置计数 count。然后随机挑选一个安全位置,作为当前i列的放置位置。
- 重复尝试: 如果当前的放置方式无解,则重新开始,直到找到一个无冲突的解。
伪代码:
-
col、diag45、diag135:分别用来记录列、左对角线和右对角线上已经放置的皇后
45°斜线:行列号之差相等(i-j或j-i相等)
135°斜线:行列号之和相等(i+j相等) -
k:当前放置的皇后数量 = 行号 -
count:当前行可放置皇后的数量 -
try:一个数组,用来记录每个皇后放置的行置了皇后的位置
try [i] 表示第 i 个皇后放在 (i , try [i]) 位置上
\(try [1..k]\)称为k-promising。即:k个皇后的位置(0≤k ≤8): (1,try[1]), (2,try[2]), ..., (k,try[k])互相不攻击,则称try[1..k]是k-promising的.
对于八皇后问题,解是 8-promising 的
QUEENS_LV(success) //若success=true,则try[1..8]包含8后问题的一个解
col, diag45, diag135 ←0 //冲突列及两斜线集合初始为空
k ← 0 //行号
repeat//try[1..k]是k-promising,考虑放第k+1个皇后, 等价于while(1)
count←0 //计数器,count值为第k+1个皇后的安全位置总数
for i ← 1 to 8 do //i是列号,试探(k+1,i)是否安全
if i ∉ col and i-(k+1) ∉ diag45 and i+(k + 1) ∉ diag135
count ← count + 1
*************key**************
*** if RANDOM(1, count) = 1***//以1/count概率在count个安全位置上
*** j ← i ***//随机选择1个位置放置皇后
*************key**************
if count > 0//count=0时无安全位置,第k个皇后尚未放好
k ← k + 1//try[1..k+1]是(k+1)-promising
try[k] ← j
col ← col ∪ {j}
diag45 ← diag45 ∪ {j-k}
diag135 ← diag135 ∪ {j + k}
until count = 0 or k=8 //当前皇后位置搜索失败或8-promising时结束
success (count > 0)
解释:
"暴力+随机化" 的结合,它通过随机化降低了一些传统暴力搜索的计算复杂度。
- 在传统暴力搜索中,通常会按固定顺序选择安全位置(比如总是选择第一个安全位置)。
- 通过引入了
RANDOM(1, count),确保每个安全位置都能以等概率被选中,避免总是按照固定规则探索解空间。
点击查看 详细代码解释
1. 初始化: 冲突集合 col, diag45, diag135 和行号 k 初始化为空和0。
2. 循环:
- 开始尝试从第1行(k=0)放置皇后。
- 对当前行的每一列(i)进行判断:
- 如果安全,则增加安全位置计数 count。然后随机挑选一个安全位置,作为当前i列的放置位置。
3. 判断:
- 如果 count > 0(存在安全位置),并更新冲突集合;行号 k 加1,尝试下一行的皇后。
- 如果 count = 0,表示当前行无安全位置(放置失败)。
- 如果 k = 8:表示所有8个皇后已经成功放置。返回结果
算法分析
-
p QUEENS_LV 算法一次成功的概率
-
s :成功时搜索的结点的平均数
-
e :失败时搜索的结点的平均数
-
p 和 e 理论上难计算,用计算机实验可计算出:
p = 0.1293
e =6.971 -
重复上述算法,直至成功时所搜索的平均结点数:
\(t = s + \frac{1-p}{p}e = 55.927\)
大大优于回溯法,回溯法约为 114 个结点才能求出一个解
算法存在的问题及改进
-
消极: LV 算法过于消极 ,一旦失败,从头再来
-
乐观: 回溯法过于乐观 ,一旦放置某个皇后失败,就进行系统回退一步的策略,而这一步往往不一定有效
折中: 先用 LV 方法随机地放置前 k 个皇后,然后使用回溯法放置后 (8 - k) 个皇后,但不考虑重放前 k 个结点。
- 若前面的随机选择位置不好,可能使得后面的位置不成功
- 随机放置的皇后越多,后续回溯阶段的平均时间就越少,失败的概率也越大
经验:一半略少的皇后随机放置较好
改进:先进行Las Vegas算法选择前k个皇后,然后回溯算法后几个皇后
伪代码:
//origin
until count = 0 or k = 8 当前皇后位置搜索失败或 8 promising 时结束
success ← (count >0)
//now
until count = 0 or k = stepVegas
if count > 0 //已随机放好 stepVegas 个皇后
QUEENS_BACKTRACK( k , col , diag 45, diag 135, success)
else success ← false
Monte Carlo算法
Monte Carlo算法是一种时间确定、结果可能不准确的随机化算法。它通过增加随机性以控制运行时间,允许在有限时间内快速得到近似解,因此有时输出的结果可能不是100%准确。
特点
- 偶尔会出错,但对任何实例均能以高概率找到正确解
- 算法运行次数越多,得到正确解的概率越高
- 时间相对确定:Monte Carlo算法通常在预设的时间或计算步骤内结束。
基本概念
设 p 是一个实数,且 1/2 < p < 1 。
若一个 Monte Carlo 算法以不小于 p 的概率返回一个正确的解,则该 MC 算法称为p 正确 ,算法的优势 (advantage) 是 \(p - 1/2\)
若一个 Monte Carlo 算法对同一实例决不给出两个不同的正确解,则该算法称是 相容 的 (consistent) 或 一致 的
为了增加一个一致的、p 正确算法成功的概率,只需多次调用同一算法,然后选择出现次数最多的解。
偏真算法
求解判定问题 的 MC(x),如果:
- 返回 true 总是正确
- 返回 false :可能出错
那么有:
-
没有必要返回频数最高的解,一次 true 超过任何次数的 false
-
重复调用 k 次一致、 p 正确、偏真的 MC 算法,可得到一个\((1 –(1 – p) ^k)\) 正确的算法
对于 55% 正确的偏真算法:重复调用 4 次可得到 95% 正确的算法,
重复调用 6 次重复就可得到 99% 正确的算法,且 p > 1/2 的要求可放
宽到 p > 0
适用场景
Monte Carlo算法常用于模拟、数值积分、统计推断等问题。在许多复杂的优化问题或多维积分问题中,Monte Carlo算法可以快速得到近似解,满足时间有限的要求。
Monte Carlo算法
蒙特卡罗(MC)算法的相关术语和结论如下:
(1)p正确(p-correct):设如果一个MC算法对于问题的任一实例得到正确解的概率不小于p,p是一个实数,且1/2≤p<1。且称p-1/2是该算法的优势(advantage)。
(2)一致的(consistent):如果对于同一实例,蒙特卡罗算法不会给出2个不同的正确解答。
(3)偏真(true-biased)算法:当MC是求解判定问题的算法,算法MC返回true时解总是正确的,当它返回false不一定正确。反之称为偏假(flase-biased)算法。
(4)偏y0算法(y0-biased):更一般的情况,所讨论的问题不一定是一个判定问题,一个算法MC是偏y0的算法(y0是某个特定解),即如果存在问题实例的子集X使得:
当xX时,则算法MC(x)返回的解总是正确的(无论返回y0还是非y0);
当xX时,正确解是y0,但MC并非对所有这样的实例x都返回正确解y0。
(5)重复调用一个一致的,p正确偏y0蒙特卡罗算法k次,可得到一个(1-(1-p)k)正确的蒙特卡罗算法,且所得算法仍是一个一致的偏y0蒙特卡罗算法。
应用:抽奖问题
设抽奖箱中有 不少于 \(a\) \((0 < a < 1)\)比例的一等奖,有放回的抽奖多少次可以保证抽到一等奖的概率不小于 \(b\) \((0 < b < 1)\)
对立事件:至少抽到一次一等奖 vs. 抽到的全部不是一等奖
假设抽奖 k 次,至少抽到一次一等奖的概率\(≥ 1 –(1-a)^k ≥ b\)
即 \(k ≥ log_{1-a}(1-b)\)
假设a =1%, b =0.9 ,则 k≈230
应用:解主元素问题
主元素问题是指在一个数组中找到出现次数超过一半的元素。如果这样的元素存在,则称之为主元素。
问题:设 \(A[1..n]\) 是含有 n 个元素的数组,若 A 中等于 x 的元素个数大于 n /2 ,则称 x 是数组 A 的主元素
- 注:若存在,则只可能有 1 个主元素
例:数组 A ={3, 2, 3, 2, 3, 3, 5},共 7 个元素,其中元素 3 出现 4 次,占一半以上,因此 A 存在主元素 3
伪代码
MAJ(A)
i ← RANDOM(1, n) //随机挑选下标
x ← A[i]
k ← 0
for j ← 1 to n do
if A[j] = x
k ← k + 1
return (k > n /2)
-
返回 true A 含有主元素 x ,算法一定正确
-
返回 false :元素 x 不是 A 的主元素,算法可能错误
(仅包含主元素时出错) -
A 确实包含一个主元素时, x为主元素的概率大于 1/2
所以:MAJ是偏真 1/2 正确的算法
算法改进:通过重复调用技术降低错误概率
MAJ2(A)
if MAJ(A)
return true
else
return MAJ( A
MAJ2 也是一个偏真算法
A 存在主元素时, MAJ2 返回 true 的概率:
- MAJ 第一次返回 true 的概率 p > 1/2
- MAJ 第一次返回 false 且第二次返回true 的概率 p(1-p)
- 总概率:\(p + p(1-p) = 1 –(1–p)^2 > 3/4\)
所以:MAJ2是偏真 3/4 正确的算法
算法改进:通过重复调用技术降低错误概率 (多次)
重复调用 MAJ 的结果是相互独立的
当 A 含有主元素时, k 次重复调用 MAJ 均返回 false 的概率为 \((1 – p) ^k = 2^{-k}\)
在 k 次调用中,只要有一次 MAJ 返回 true ,即可判定 A有主元素
当需要控制算法出错概率小于 ε > 0 时,相应算法调用MAJ 的次数为:由\(\epsilon=2^{-k}\)得\(k = ⌈lg(\frac{1}{ε})⌉\)
MAJMC(A, ε)
k ← ⌈lg(1/ε)⌉
for i ← 1 to k do
if MAJ( A )
return true
return false
时间复杂度为\(O( n lg(1/ε))\)
⚠️注意,这里只是用此问题来说明MC 算法,实际上对于判定主元素问题存在 \(O(n)\) 的确定性算法。
总结
蒙特卡洛算法解决主元素问题的核心思想是:随机抽样。
- 随机抽取元素: 从数组中随机抽取一个元素。
- 计数: 统计数组中与抽取元素相同的元素个数。
- 判断: 如果计数超过数组长度的一半,则该元素很可能是主元素。
算法通过随机选择数组中的元素 \(x\),由于数组 \(T\) 中非主元素的个数小于 \(n/2\),所以 \(x\) 不是主元素的概率小于 \(1/2\)。因此,判定数组 \(T\) 是否存在主元素的算法具有偏真(bias)且正确率为 \(1/2\)。50%的错误概率通常是不可接受的。因此,采用重复调用技术可以将错误概率降低到任意可接受的范围内。对于任何给定的 \(\epsilon > 0\),重复调用算法 majority \(\log(1/\epsilon)\) 次。该算法是一个偏真蒙特卡洛算法,且其错误概率小于 \(\epsilon\)。所需的计算时间为 \(O(n \log(1/\epsilon))\)。
应用:检验矩阵乘法
问题:设 A , B , C 为 n × n 矩阵,如何判定 \(AB=C\) 是否正确?
通过 A · B 的结果与 C 比较
- 传统方法: O n 3
- 当 n 非常大时,确定性算法: \(Ω( n^{2.37})\)
Monte Carlo 算法
-
可在 \(O(n^2)\) 内解此问题,但存在一个 很小的误差 \(\varepsilon\)
-
设 X 是一个长度为 n 的 0/1 二值行向量,将判断 AB=C改为判断 XAB=XC

设随机建立一个N×1的矩阵R,若A·(B·R) = C·R,则A·B = C,而这一算法时间复杂度为O(n^2)
GOODPRODUCT(A, B, C, n)
for i ← 1 to n do
X[i] ← RANDOM(0,1)
if (XA)B = XC
return true
else return false
-
返回 false :算法一定正确
-
返回 true :仅对 X i =1 的对应行进行了求和验证,算法可能错误
-
若 A · B 与 C 的第 i 行不同且 X i =0 则出错,误判 AB C ,出错概率不超过 1/2
是一个偏假算法。
时间复杂度分析\(O(n^2)\)
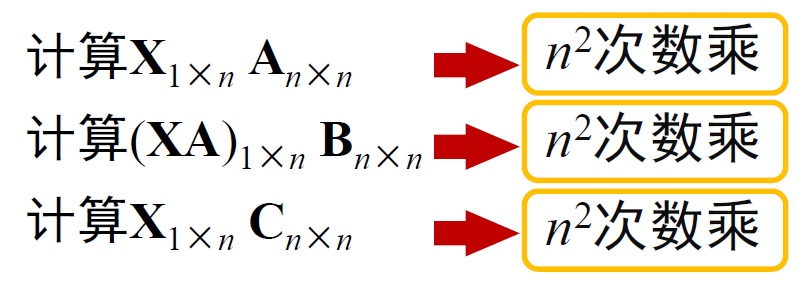
算法改进
REPEAT_GOODPRODUCT(A, B, C, n , ε ) //出错概率 ε
k ← ⌈lg(1/ε)⌉
for i ← 1 to k do //重复 k 次
if GOODPRODUCT(A, B, C, n) = false
return false
return true
时间复杂度为\(O(n^2 lg(1/ ε))\)
出错概率 \(ε ≤ 2^{-k}\)
REPEAT_GOODPRODUCT 是偏假 \((1-ε)\) 正确的算法
LV和MC算法的比较
| 特性 | Las Vegas算法 | Monte Carlo算法 |
|---|---|---|
| 结果准确性 | 总是准确 | 可能有误差 |
| 运行时间 | 不确定 | 相对确定 |
| 随机性 | 控制计算路径,但不影响结果 | 控制结果准确性 |
| 适用场景 | 需要精确解的问题,但对运行时间不敏感 | 允许近似解的问题,或模拟复杂系统 |
| 成功概率 | 与随机数生成有关 | 通过增加采样次数提高 |
总结
- Las Vegas算法利用随机性来优化计算路径,保证正确结果,但运行时间可能不确定。
- Monte Carlo算法通过随机采样快速得到近似解,运行时间较稳定,但可能有一定误差。
这两类算法根据需求不同,广泛应用于各种优化、模拟和复杂计算问题。
伪代码示例
拉斯维加斯算法
Obstinate(x)
{
repeat
LV(x, y, success);
until success;
return y;
}
(以随机快速排序为例)
随机快速排序(A, p, r)
如果 p >= r
返回
q ← 随机选择p和r之间的索引
将A[q]作为主元,将A[p...r]划分成两部分A[p...q-1] ≤ A[q] ≤ A[q+1...r]
随机快速排序(A, p, q-1)
随机快速排序(A, q+1, r)
解释:
- 随机选择一个元素作为主元,而不是总是选择第一个或最后一个元素,可以有效避免最坏情况的发生。
- 递归地对左右两部分进行排序。
- 由于随机性的引入,每次运行的结果可能不同,但最终得到的排序结果一定是正确的。
蒙特卡洛算法(以蒙特卡洛积分为例)
蒙特卡洛积分(f, a, b, N)
sum ← 0
对于 i 从 1 到 N
x ← 随机生成a和b之间的数
sum ← sum + f(x)
返回 (b-a)/N * sum
解释:
f是要积分的函数,a和b是积分区间。- 通过随机生成
N个点,计算函数值,并求平均值,来近似计算定积分的值。 N越大,结果越接近真实值。
习题🌟
答案原文:https://blog.csdn.net/hxz_qlh/article/details/18419571
问题描述:
称一个序列为几乎有序是指:序列中至少90%的数据是有序的,即可删除其中不超过10%的数据使得剩下的序列有序。例如序列[1, 2, 3, 4, 5, 10, 6, 7, 8.9]是几乎有序的,序列[1,2,5,3,4,10,6,7,8,9]中需删除5和10才有序,仅80%数据有序,不满足几乎有序。
现需设计算法检查一个序列是否几乎有序,输入为一个不包含重复元素的序列,其输出如下:如果序列已完全排序,则总是返回true; 如果序列没有90%排序,则以至少2/3的概率返回false。
问题1
(1)假设箱子中总共有个球,其中至少10%的球是蓝色球,剩下的球是红色球。现有放回地随机抽球,则需要抽取多少次才能以不少于2/3的概率抽到一个蓝色球?

问题2
(2)给定如下二分搜索算法 BINARY_SEARCH:
BINARY_SEARCH(A, key, left, right) if left==right return left else mid ← ⌈ left+right)/2 ⌉ if kev < A[mid] return BINARY_SEARCH(A, key, left, mid-1) else return BINARY_SEARCH(A, key, mid, right)假设在序列中查找的key值为 \(key_1\) 时算法返回下标 i 、查找 \(key_2\) 值时算法返回下标 j ,且 \(A\) 并非有序。证明如下结论:若\(i<j\),则\(key<=key2\)。
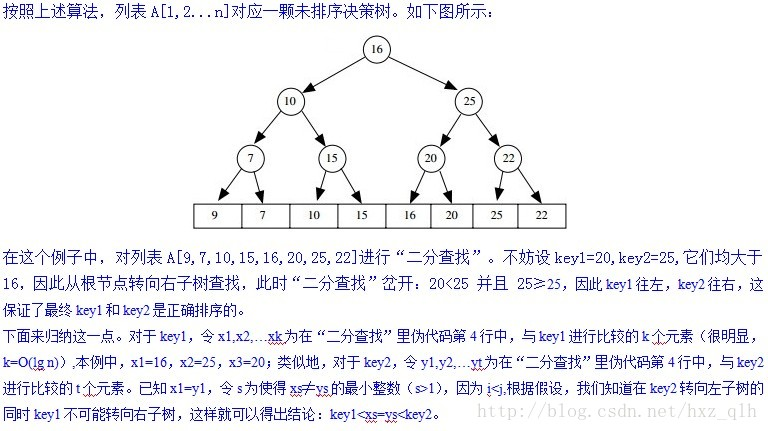
问题3
(3)现有如下概率算法 IS_ALMOST_SORTED 判断一个序列是否几乎有序:
IS_ALMOST_SORTED(4. n. k) for r ← 1 to k do i ← RANDOM(1, η) j ← BINARY_SEARCH(A, A[i], 1, n) if i≠j return false return true其中RANDOM(1,n)函数用于在闭区间[1,n]中独立均匀地随机选择一个数。试依次证明如下结论从而说明算法的正确性:
- 如果序列已完全排序,则算法总是返回true;
我们为列表中每一个元素贴上一个“good”或“bad”的标签,表示它通过“二分查找”的返回的下标是否和它经正确排序后的下标一致:
要判断哪些元素是“good”或“bad”并不是那么直观,有些元素可能是已排序正确的,但也有可能因为其它元素的乱序导致最终它们也是乱序的,类似的,有些元素可能完全就是乱序,但也有可能是阴差阳错地刚好处于某个正确的位置。关键点是一个糟糕的排序结果会导致很多“bad”元素。
- 定义算法第2行随机选择的下标\(i\)对应的元素\(A[i]\)为“好数”或“坏数”:若 i=BINARY_SEARCH(A,A[i],1,n) 则称为“好数”,若i≠BINARY_SEARCH(A,A[i],1,n)则称为“坏数”,注意:“好数”和有序并不直接对应。
需证明的结论为:若序列并非90%排序,则至少10%的数为“坏数”;
反证法:
假设“bad”元素不超过10%,那么至少有90%的元素是“good”。
回想一下一个列表90%已排序的定义:如果去除掉那些排序结果不明确的10%元素,那么我们认为,余下的元素都是已排序正确的。考虑余下的“good”元素中任意两个元素,key1和key2,key1的坐标为 i,key2的坐标为 j.如果i<j,根据(c)可知,kwy1<key2,也就是说这两个元素是排序正确的。既然任意两个元素都是排序正确的,那么数组中所有的“good”元素是排序正确的,即列表A是90%已排序的,与已知矛盾,故假设不正确,因此命题得证。
- 若序列没有90%排序,则以至少2/3的概率返回false。
证明:根据上述(2)知道,至少有10%的元素是“bad”元素,从(b)又知,如果选择 k>lg(1/3)/lg 0.9,那么找到一个“bad”元素的概率至少为2/3,因此,得出结论:如果列表不是90%已排序的,那么算法至少以2/3的概率返回false。
问题4
试想一下,斯内普教授想要确定一个列表是否是以 1- e 已排序的,对某个0<e<1(在之前的部分 e=0.10)。对大数 n,确定其合适的渐近 k 值,证明该算法是正确的。它的总体运行时间是多少?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号