
torch.nn.Embedding的导入与导出
简介及导入转自:torch.nn.Embedding使用
在RNN模型的训练过程中,需要用到词嵌入,使用torch.nn.Embedding可以快速的完成:只需要初始化torch.nn.Embedding(n,m)即可(n是单词总数,m是词向量的维度)(n是嵌入字典的大小,m是嵌入向量的维度。)。
注意: embedding开始是随机的,在训练的时候会自动更新。
简单使用
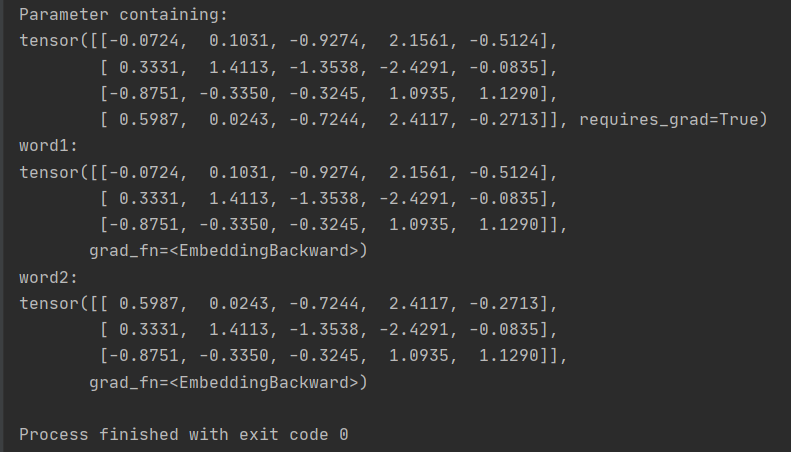
举个简单的例子:
- 输入:word1和word2是两个长度为3的句子,保存的是单词所对应的词向量的索引号。
- 输出:随机生成(4,5)维度大小的embedding,可以通过embedding.weight查看embedding的内容。
- 过程:输入word1时,embedding会输出第0、1、2行词向量的内容; word2同理。
import torch word1 = torch.LongTensor([0, 1, 2]) word2 = torch.LongTensor([3, 1, 2]) embedding = torch.nn.Embedding(4, 5) print(embedding.weight) print('word1:') print(embedding(word1)) print('word2:') print(embedding(word2))
导出
创建一个嵌入层并将其导出为numpy数组。
import torch import numpy as np # 创建嵌入层 embedding = torch.nn.Embedding(10, 5) # 将权重转换为numpy数组 embedding_weights = embedding.weight.data.numpy() # 保存权重到文件 np.savetxt("embedding_weights.txt", embedding_weights)
导入
导入已经训练好的词向量,需要设置训练过程中不更新(固定embedding)。
如下所示,emb是已经训练得到的词向量,先初始化等同大小的embedding,然后将emb的数据复制过来,最后一定要设置weight.requires_grad为False。
self.embedding = torch.nn.Embedding(emb.size(0), emb.size(1)) self.embedding.weight = torch.nn.Parameter(emb) # 固定embedding self.embedding.weight.requires_grad = False
本文作者:kingwzun
本文链接:https://www.cnblogs.com/kingwz/p/18411016
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
2022-09-12 2984. 线段
2022-09-12 2983. 玩具 _ 计算几何
2022-09-12 UML _ 包图
2021-09-12 快速幂算法+取模
2021-09-12 补题*总结题21/9/11