Transformer 从零解读
B站课程 Transformer从零详细解读(可能是你见过最通俗易懂的讲解) 的上课笔记
1. Transformer 模型概述
- Transformer(TRM) 是一种基于自注意力机制的模型,广泛应用于自然语言处理领域。
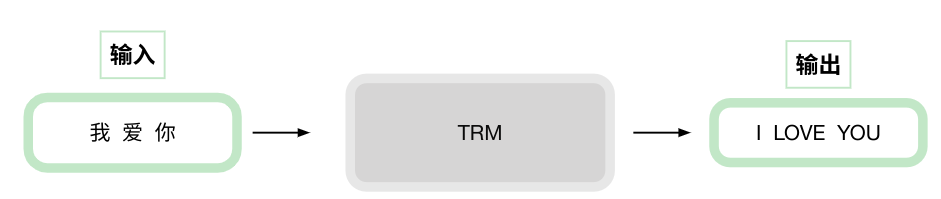
结构简述
transformer主要可以分为编码器encoder和解码器decoder两部分
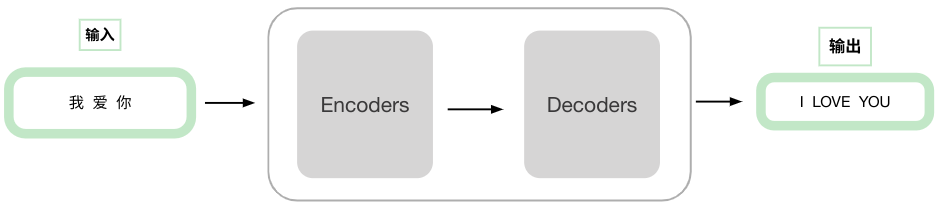
具体来说,transformer 拥有多个结构相同的 encoder和decoder(注:encoder和decoder之间结构不相同)。
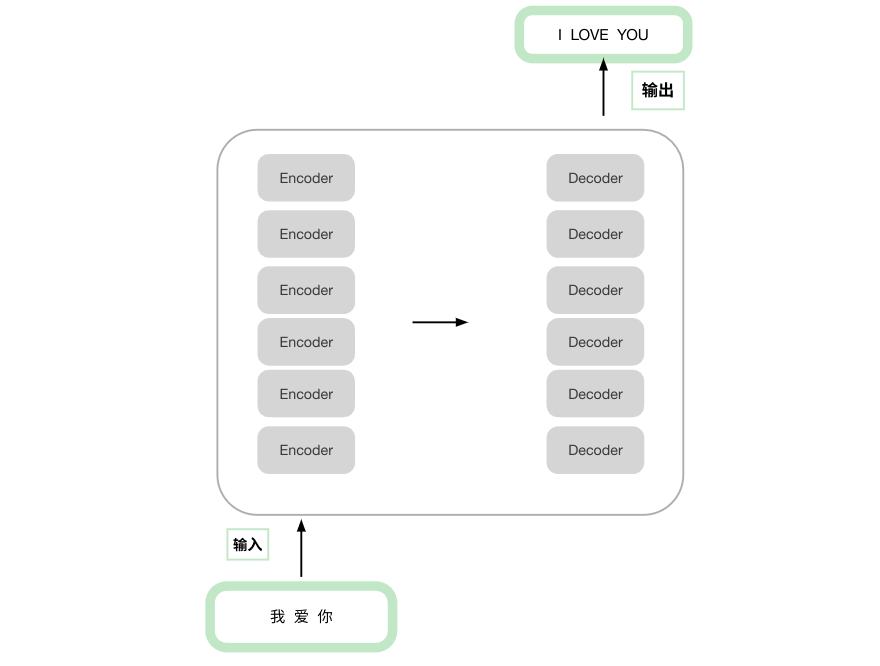
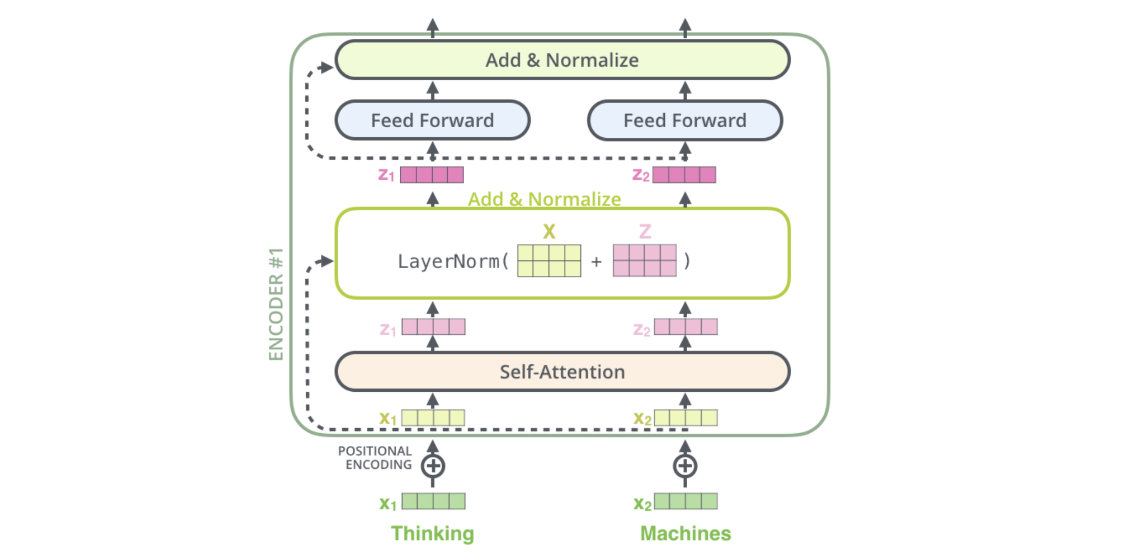
transformer 论文的结构如下图,可以看到主要部分就是encoder和decoder,此外还有位置编码positional encoding,linear,softmax等操作。
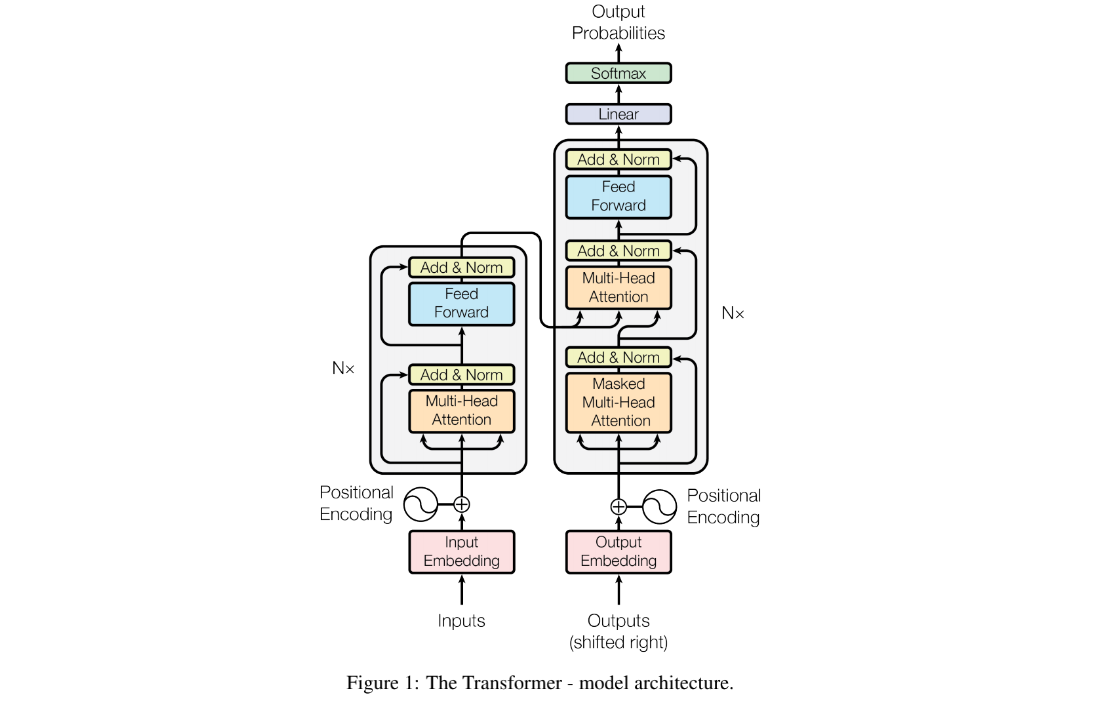
原论文中的图,Nx为个数,左部分是encode ,右部分是decode。右半部分多了一层被掩盖的多头注意力机制。
Encoder
encoder 由 N 个完全相同的大模块堆叠而成(原论文N=6)。
这个结构怎么理解?这个构造就需要我们确保每一个模块的输入和输出维度是相同的,在实现代码的时候,我们只需要完成一个模块的代码的构造就可以。
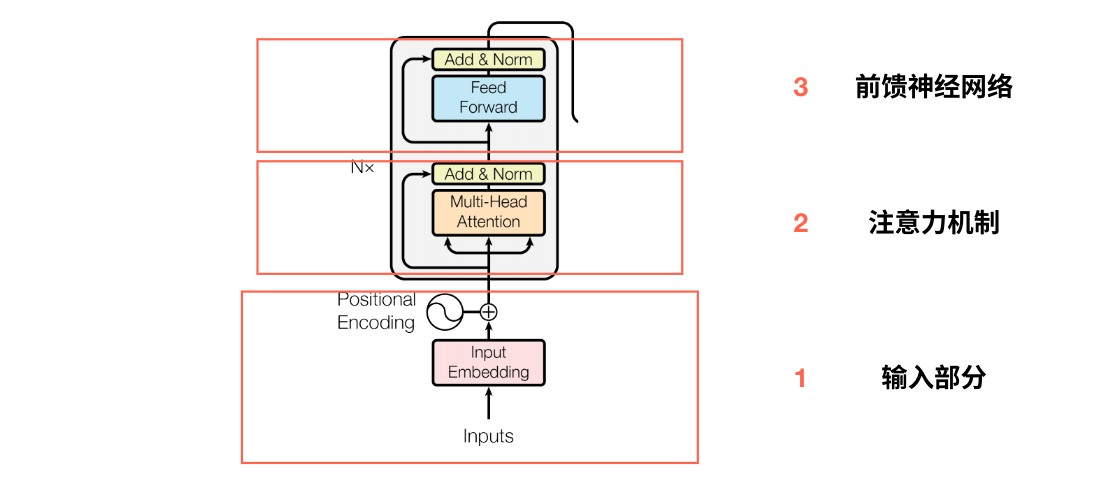
具体来说每个encoder模块可以分为三部分:
- 输入部分:文本嵌入Embedding+位置编码Positional Encoding
- 注意力机制:识别到哪部分数据是关键信息,学习输入序列中元素之间的依赖关系。
- 前反馈神经网络:将输入映射到更高维度的空间,并通过非线性变换融合不同的特征信息。
encoder 的输出需要注意的细节点在于它需要和 decoder做交互,所以它的输出为 K/V 矩阵,记住这个细节点,Q 矩阵来自decoder模块,K/V矩阵来自encoder。
输入部分
输入部分包含embedding和position coding,TRM将两者结合后,做为输入。
文本嵌入层Embedding
Embedding作用:
将输入的文本中词汇表示转变为向量表示,希望在这样的高维空间捕捉词汇间的关系。
什么是Embedding?
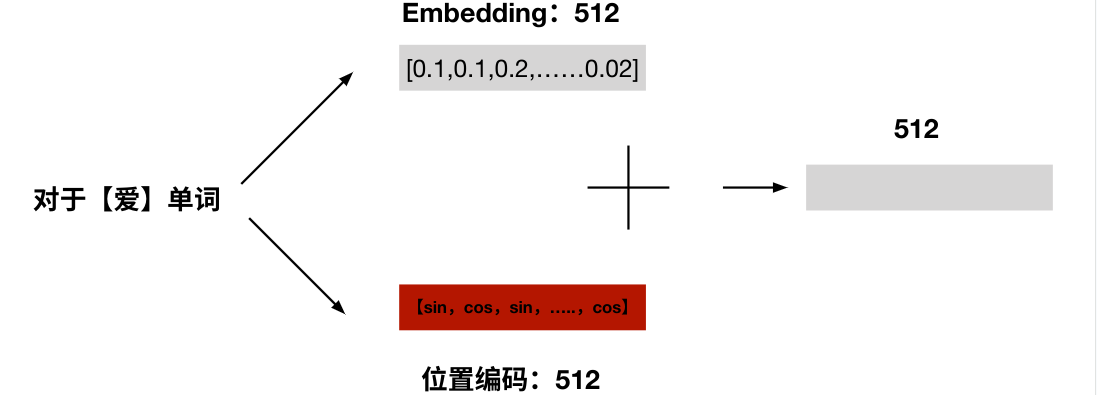
就是把文字转化为向量表示,具体的方法有很多,转化后的向量大小可以自定义。比如下图就是将我爱你...共12个字转化为一个12*512的矩阵(每个字对应512维度的字向量)。

简单理解后,需要用到时,详细信息可看:Transformer输入嵌入:Input Embedding
位置编码
为什么TRM需要位置编码
为什么TRM需要位置编码,而传统的RNN不需要?
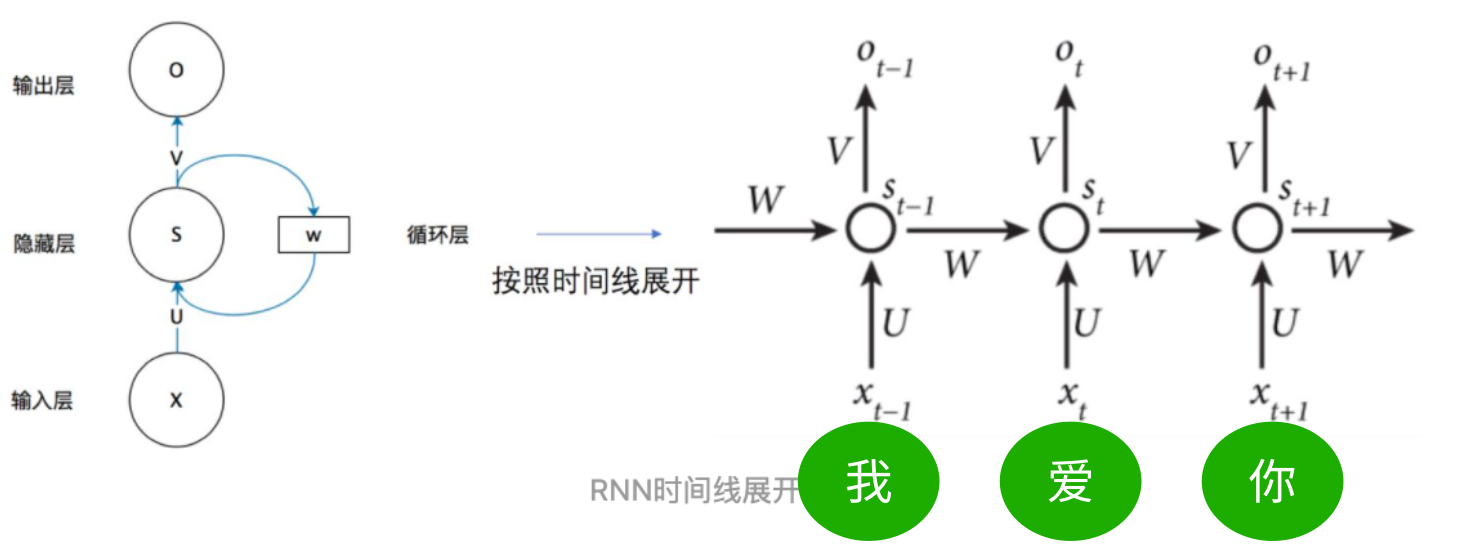
RNN的结构如下,可以看到RNN的输入有两部分:前一个数据的部分信息 和 本数据的原始输入。
如:我爱你三个字中的爱字RNN输入的变量可以理解为是: 我字处理后的数据 + 爱字
也就是说 RNN是一个一个接着处理的,有天然的时序关系。
我们可以主观的理解到单词在句子中的位置是重要的,因此模型需要理解单词在句子中的位置关系。而Transformer处理单词是并行处理的 ,所以transformer对比RNN就缺少了单词的先后关系,这个时候就需要位置编码。
位置编码简述
位置编码的作用:
因为在Transformer的编码器结构中,并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同面能会产生不同语义的信息加入到词嵌入张量中,以弥补位置信息的缺失。
position encoding的含意
position encoding 表示的是绝对位置,相对位置信息和不同的处理有关。
位置编码公式:使用正弦和余弦函数为每个单词添加位置信息。
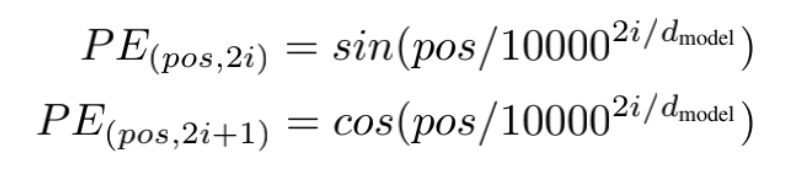
引申一下为什么位置嵌入会有用
但是这种相对位置信息会在注意力机制那里消失

注意力机制
encoder 的输出需要注意的细节点在于它需要和 decoder做交互,所以它的输出为 K/V 矩阵,记住这个细节点,Q 矩阵来自decoder模块,K/V矩阵来自encoder。
注意力机制的理解
基本的注意力机制作用:识别到哪部分数据是关键信息,学习输入序列中元素之间的依赖关系(模型能够关注输入序列中不同位置的信息)。
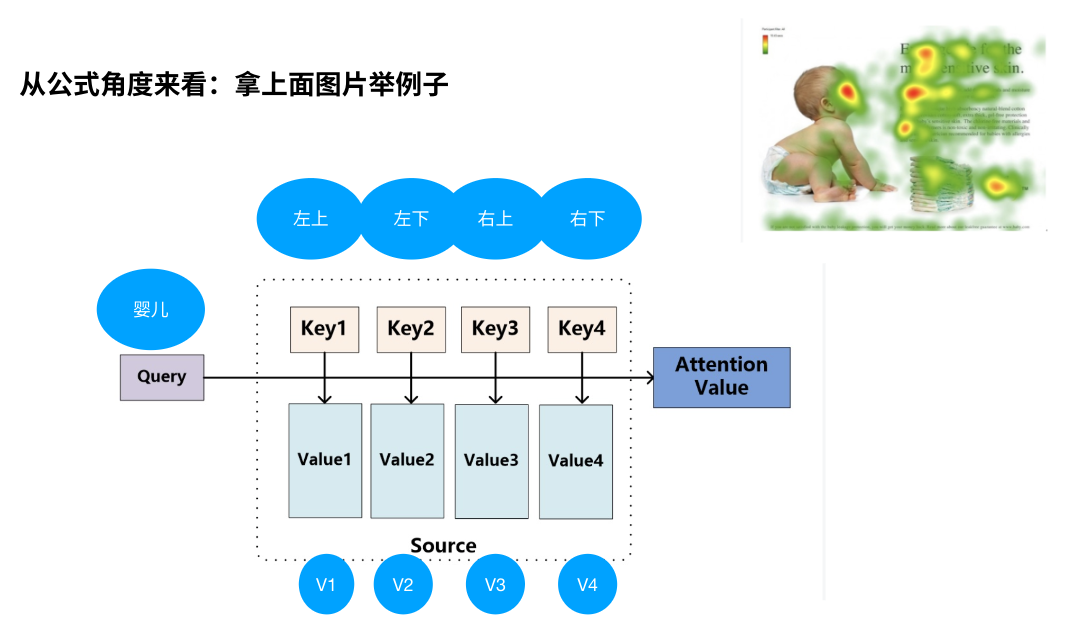
注意力机制本质: 识别到哪部分数据是关键信息,比如下图问‘婴儿在干嘛?’红色部分就是人类集中观察的地方。

注意力机制的公式
注意力机制的公式如下
附:Softmax操作是对向量做归一化的一种操作,是固定流程;d和k都是常量,\(K^T\)是指K的转置矩阵。只需要关心QKV即可。
转置矩阵介绍如下:
\(如果 X = \left[ \begin{matrix} \mathbf{x}_{0} \\ \mathbf{x}_{1} \\ \vdots \\ \mathbf{x}_{n} \end{matrix} \right] \ 则 X^\top = \left[ \begin{matrix} \mathbf{x}_{0}^\top & \mathbf{x}_{1}^\top & \cdots & \mathbf{x}_{n}^\top \end{matrix} \right]\)
为什么除以\(\sqrt{d_k}\) ?
对相似度矩阵每个元素除以\(\sqrt{d_k}\),\(d_k\)为K的维度大小。这个除法被称为Scale。当\(d_k\)很大时,\(QK^T\)的乘法结果方差变大,进行Scale可以使方差变小,训练时梯度更新更稳定。
Softmax
是对向量做归一化, 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1,得到了一个归一化之后的权重矩阵,矩阵中,某个值的权重越大,表示相似度越高。
拿上面图片朴素的理解公式:Q代表Query,Key代表不同位置的评分(如何获取这个评分先不用管),V先不用管。那“婴儿”的attention value就是在不同位置的评分。
再从npl实际应用中来看,attention value就是“爱”对于其他字“我不爱你”重要程度的评分。
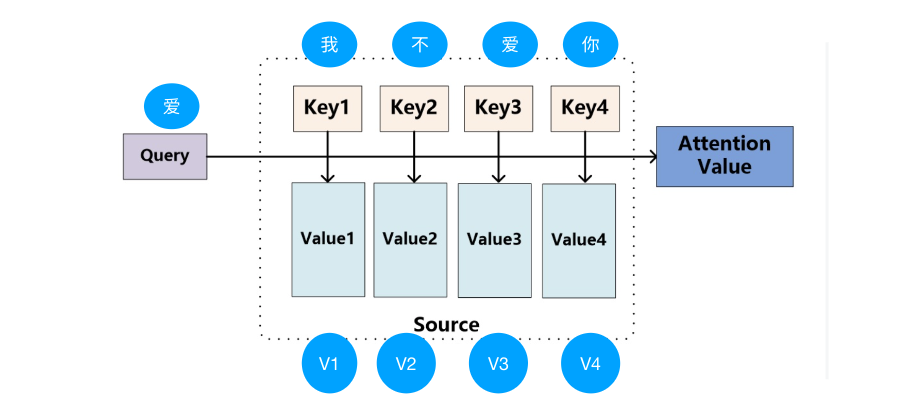
很明显注意力机制的关键就是怎么获取 QKV
TRM中的注意力计算
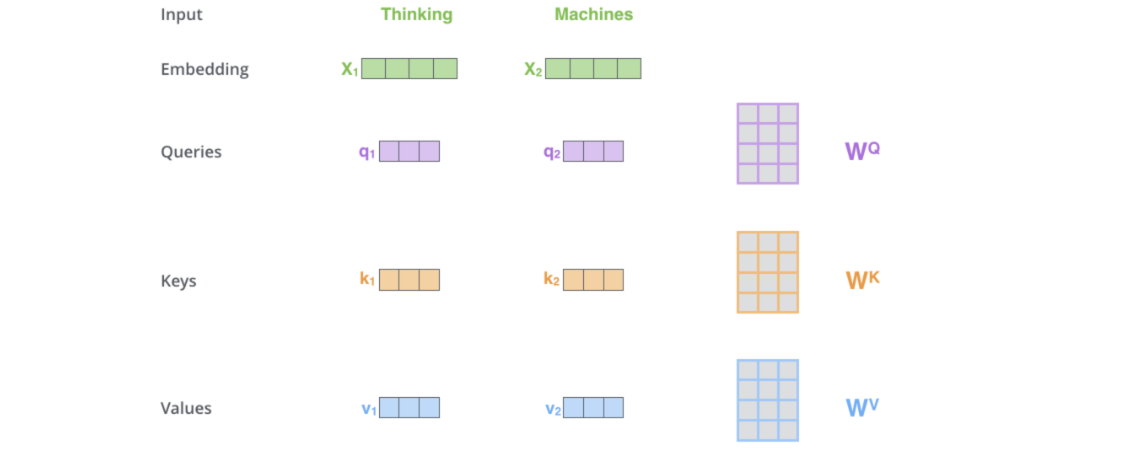
如何获取QKV: 在只有单词向量的情况下,,如下图,只需要让输入\(X_i\)和训练出来的\(W^Q\),\(W^K\),\(W^V\)叉乘即可得到\(q_i\),\(k_i\),\(v_i\)。
⚠️提醒: 虽然\(W^Q\),\(W^K\),\(W^V\) 是可训练的参数矩阵,在这里可以认为是已知的常量。
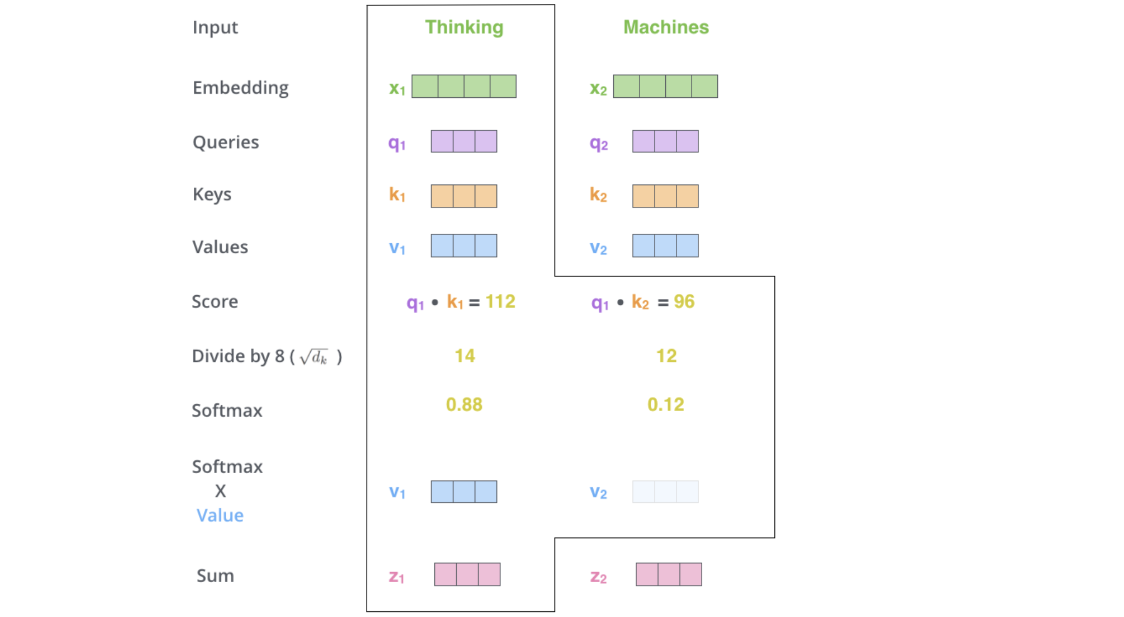
计算attention值过程如下:
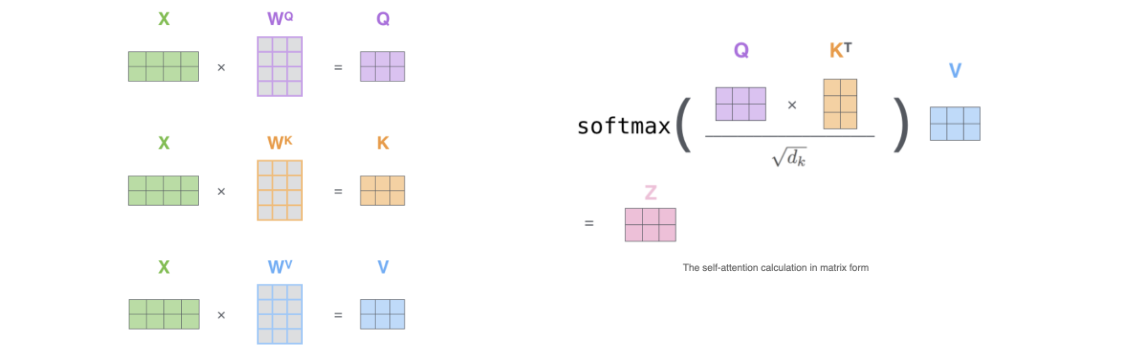
实际代码使用矩阵,方便并行
多头注意力机制
实际训练中,TRM会使用一个叫多头注意力机制的东西。
多头注意力: 允许模型在多个表示子空间中并行地学习信息。反映到代码就是让输入与不同的几组QKV进行运算,最后再contact成一个变量。如下图:
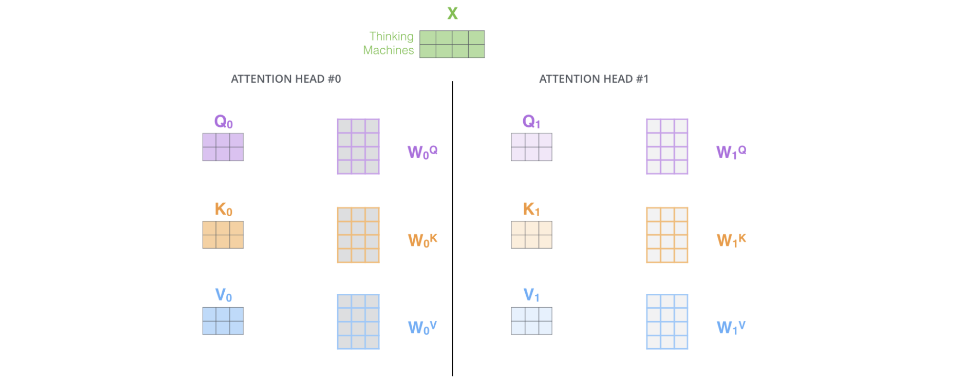
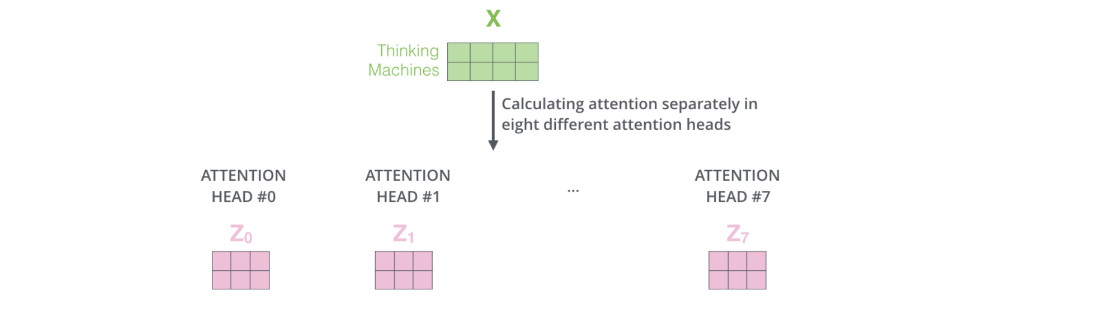
多个头就会有多个输出,需要合在一起输出
残差连接和层归一化 Add&LayerNorm
Add残差连接:将一部分的前一层的信息无差的传递到下一层(\(f(x)+x\)),减少梯度消失的问题。
Layer Normalization层归一化:对同一个样本的不同特征做归一化。
Add残差连接
残差连接操作:就是将经过weight layer后的f(x)再加上x,如下图所示。
作用: 减少梯度消失的问题,帮助梯度在深层网络中流动。
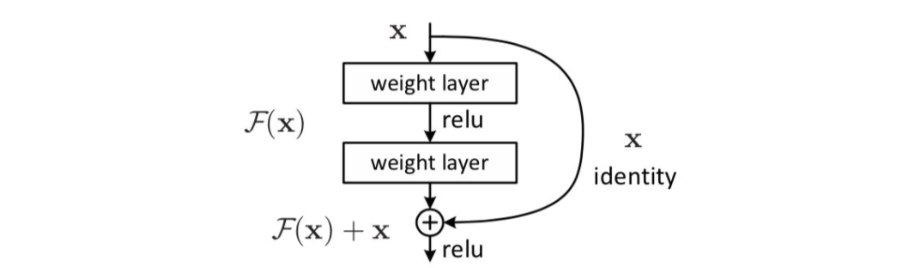
为什么残差有作用

Layer Normalization层归一化
Layer Normalization:对样本的不同特征进行归一化。(而不是像batch normalization(BN)取的是不同样本的同一个特征进行归一化)NLP领域中,LN更为合适。

进阶:
理解为什么LayerNorm单独对一个样本的所有单词做缩放可以起到效果。看文章:transfomer的组成-残差连接和层归一化
前馈神经网络
前反馈神经层很简单。是一个两层的全连接层,对每个位置的向量进行非线性变换,引入更多的非线性能力,将输入映射到更高维度的空间,并通过非线性变换融合不同的特征信息。
Decoder
encoder 的输出需要注意的细节点在于它需要和 decoder做交互,所以它的输出为 K/V 矩阵,记住这个细节点,Q 矩阵来自decoder模块,K/V矩阵来自encoder。
decoder模块的东西很多都是讲过的,所以直说与encoder不同的地方。
每个decoder模块由三个子层连接结构组成
- 注意力机制:和encoder不同,需要对当前单词和之后的单词做masked。
- 注意力机制(交互层) ( 使用Encoder 的输出C计算得到K,V )
- 前反馈神经层
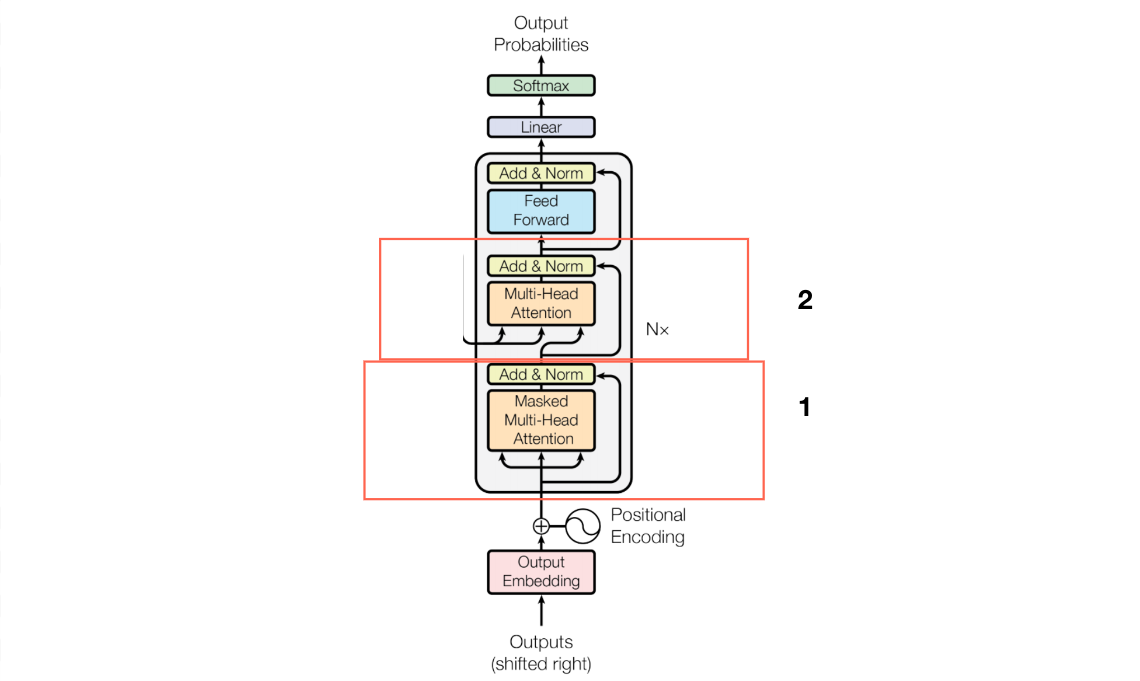
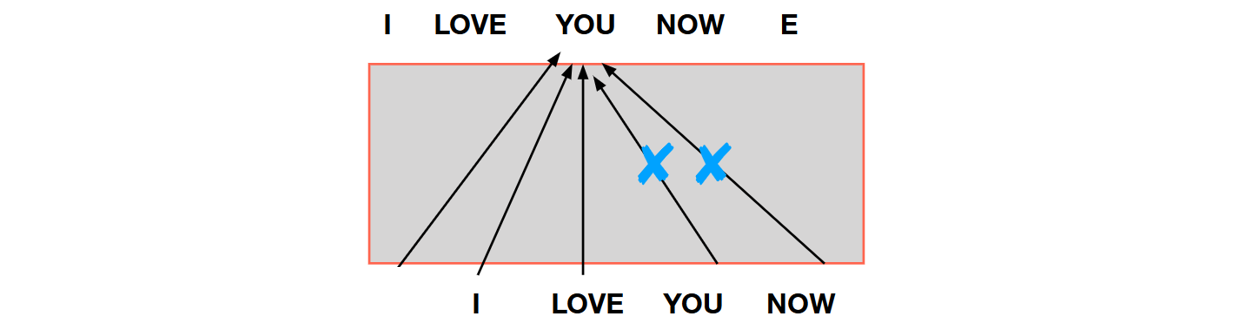
为什么需要Mask
可以看到第一层需要对当前单词和之后的单词做mask。
mask作用: 在解码器中,为了防止信息泄露,需要对尚未生成的单词进行Mask操作。
那为什么需要Mask?
在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。实际翻译时候 模型不知道后面数据的信息,因此decoder训练的时候就模仿这个模式进行训练。
通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。