


Mycat 简介
1、相关概念
schema:逻辑库,与MySQL中的Database(数据库)对应,一个逻辑库中定义了所包括的Table。
table:表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表格需要声明其所存储的逻辑数据节点DataNode,这是通过表格的分片规则定义来实现的,table可以定义其所属的“子表(childTable)”,子表的分片依赖于与“父表”的具体分片地址,简单的说,就是属于父表里某一条记录A的子表的所有记录都与A存储在同一个分片上。
分片规则:是一个字段与函数的捆绑定义,根据这个字段的取值来返回所在存储的分片(DataNode)的序号,每个表格可以定义一个分片规则,分片规则可以灵活扩展,默认提供了基于数字的分片规则,字符串的分片规则等。
dataNode: MyCAT的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上,一般来说,为了高可用性,每个DataNode都设置两个DataSource,一主一从,当主节点宕机,系统自动切换到从节点。
dataHost:定义某个物理库的访问地址,用于捆绑到dataNode上。
MyCAT目前通过配置文件的方式来定义逻辑库和相关配置:
MYCAT_HOME/conf/schema.xml中定义逻辑库,表、分片节点等内容;
MYCAT_HOME/conf/rule.xml中定义分片规则;
MYCAT_HOME/conf/server.xml中定义用户以及系统相关变量,如端口等。
关系图:

2、垂直切分
根据业务的不同,将不同业务的表放到不同的数据库中。示例:
schema.xml文件:

<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://org.opencloudb/"> <!-- schema逻辑数据库 --> <schema name="mycat1" checkSQLschema="false" sqlMaxLimit="100" dataNode="mycat1" /> <schema name="mycat2" checkSQLschema="false" sqlMaxLimit="100" dataNode="mycat2" /> <schema name="mycat3" checkSQLschema="false" sqlMaxLimit="100" dataNode="mycat3" /> <!--使用dataNode将实际数据库和逻辑数据库映射--> <dataNode name="mycat1" dataHost="mycat" database="mycat1" /> <dataNode name="mycat2" dataHost="mycat" database="mycat2" /> <dataNode name="mycat3" dataHost="mycat" database="mycat3" /> <dataHost name="mycat" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <!--写上数据库链接信息--> <writeHost host="hostM1" url="ip1:3306" user="root" password="123456" /> <writeHost host="hostM2" url="ip2:3306" user="root" password="123456" /> <writeHost host="hostM3" url="ip3:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
server.xml文件:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mycat:server SYSTEM "server.dtd"> <mycat:server xmlns:mycat="http://org.opencloudb/"> <system> <property name="defaultSqlParser">druidparser</property> </system> <!--帐号密码以及所链接的逻辑库--> <user name="test"> <property name="password">test</property> <property name="schemas">mycat1,mycat2,mycat3</property> </user> <!--只读的用户信息--> <user name="user"> <property name="password">user</property> <property name="schemas">mycat1,mycat2,mycat3</property> <property name="readOnly">true</property> </user> </mycat:server>
以上配置是将mycat1,mycat2和mycat3数据库分别放在ip1,ip2和ip3对应的数据库实例中。
优点:
- 拆分后业务清晰,拆分规则明确;
- 系统之间整合或扩展容易;
- 数据维护简单。
缺点:
- 部分业务表无法 join,只能通过接口方式解决,提高了系统复杂度;
- 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高;
- 事务处理复杂。
3、水平拆分
对数据量很大的表进行拆分,把这些表按照某种规则将数据存放到不同的数据库中。示例:
schema.xml文件:
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://org.opencloudb/"> <!-- tb_class和tb_student有外键关联关系,可以测试join --> <schema name="test" checkSQLschema="false" sqlMaxLimit="100"> <table name="tb_user" dataNode="dn1,dn2" rule="rule1" primaryKey="id"/> </schema> <dataNode name="dn1" dataHost="mycat1" database="mycat1" /> <dataNode name="dn2" dataHost="mycat2" database="mycat2" /> <dataHost name="mycat1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="host1" url="ip1:3306" user="root" password="123456" /> </dataHost> <dataHost name="mycat2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="host3" url="ip2:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
server.xml文件:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mycat:server SYSTEM "server.dtd"> <mycat:server xmlns:mycat="http://org.opencloudb/"> <system> <property name="defaultSqlParser">druidparser</property> </system> <!--帐号密码以及所链接的逻辑库--> <user name="test"> <property name="password">test</property> <property name="schemas">test</property> </user> <!--只读的用户信息--> <user name="user"> <property name="password">user</property> <property name="schemas">test</property> <property name="readOnly">true</property> </user> </mycat:server>
rule.xml文件:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mycat:rule SYSTEM "rule.dtd"> <mycat:rule xmlns:mycat="http://org.opencloudb/"> <tableRule name="rule1"> <!--安装id规则,将id除于1024然后取余,如果余数落在0~512就将数据写到第一个数据库,如果是在512~1024就放到第二个数据库--> <rule> <columns>id</columns> <algorithm>func1</algorithm> </rule> </tableRule> <!--分成两片,每片的区间是512,两个相乘必须是1024--> <function name="func1" class="org.opencloudb.route.function.PartitionByLong"> <property name="partitionCount">2</property> <property name="partitionLength">512</property> </function> </mycat:rule>
以上配置是把id在0~512的数据放在ip1对应的数据库mycat1中的tb_user表中,512~1024的数据放在ip2对应的数据库mycat2中的tb_user表中。
优点 :
- 拆分规则抽象好,join 操作基本可以数据库做;
- 不存在单库大数据,高并发的性能瓶颈;
- 应用端改造较少;
- 提高了系统的稳定性跟负载能力。
缺点 :
- 拆分规则难以抽象;
- 分片事务一致性难以解决;
- 数据多次扩展难度跟维护量极大;
- 跨库 join 性能较差
4、各类数据库中间件
中间件种类很多种,如下图:
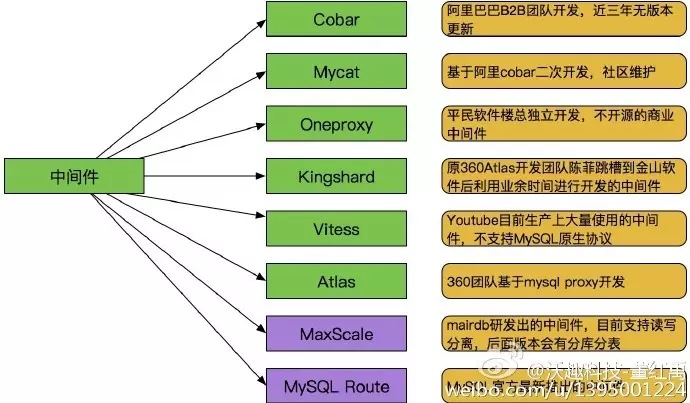
Cobar:
阿里巴巴B2B开发的关系型分布式系统,管理将近3000个MySQL实例。 在阿里经受住了考验,后面由于作者的走开的原因cobar没有人维护 了,阿里也开发了tddl替代cobar。
MyCAT:
社区爱好者在阿里cobar基础上进行二次开发,解决了cobar当时存 在的一些问题,并且加入了许多新的功能在其中。目前MyCAT社区活 跃度很高,目前已经有一些公司在使用MyCAT。
OneProxy:
数据库界大牛,前支付宝数据库团队领导楼总开发,基于mysql官方 的proxy思想利用c进行开发的,OneProxy是一款商业收费的中间件,专注在性能和稳定性上。
Vitess:
这个中间件是Youtube生产在使用的,但是架构很复杂。 与以往中间件不同,使用Vitess应用改动比较大要使用他提供语言的API接口。
Kingshard:
Kingshard是前360Atlas中间件开发团队的陈菲利用业务时间用go语言开发的,目前在不断完善。
Atlas:
360团队基于mysql proxy 把lua用C改写。原有版本是支持分表, 目前已经放出了分库分表版本。
MaxScale与MySQL Route:
MaxScale是mariadb 研发的,目前版本不支持分库分表。MySQL Route是现在MySQL 官方Oracle公司发布出来的一个中间件。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2018-03-30 MySQL-Access denied for user 'username'@'localhost' (using password: YES) 解决