
Oracle 汉字在不同字符集下所占字节
今天发现了一个问题,一个长度设置为2000字节的字段,插入一条长度为1000的汉字数据,竟然报错了。
一个汉字占两个字节,按理说刚好是2000个字节。但通过查看日志,发现插入数据的长度为3000字节。
百度了一下,原来是不同的字符集造成的。
一般情况下,数据库的NLS_CHARACTERSET 为AL32UTF8或UTF8,即一个汉字占用三到四个字节。如果NLS_CHARACTERSET为ZHS16GBK,则一个字符占用两个字节。
而公司的运行环境上是AL32UTF8,因此一个汉字占到了3个字节。
1. 使用lengthb方法查看当前数据库中文字符的字节数

可以看到当前数据库汉字是占了3个字节。
2. varchar2类型:对于VARCHAR2字符要用几个字节存储,要看数据库使用的字符集,比如GBK,汉字就会占两个字节,英文1个。如果是UTF-8,汉字一般占3个字节,英文还是1个。 所以,varchar2长度的定义,最多可达4000(可存储4000个英文字符),但实际能储存的长度,取决于字符集。
nvarchar2类型:对于NVARCHAR2字符,所有字符都会按照2个字节进行存储,因此最多只能定义到2000的长度。同时,对于纯英文的存储,那么就会多耗费一倍空间(因为英文在varchar2类型里只要1个字节的空间)。但对于汉字的存储其实是更合适的,这样能保证汉字存储得最多(2000个)。
下面是一个例子:
首先分别创建两个表,均只有一个字段,tblvarchar2的字段长度为20,类型为varchar2。tblnvarchar2的字段长度为20,类型为nvarchar2。
然后插入长度为20的中文。
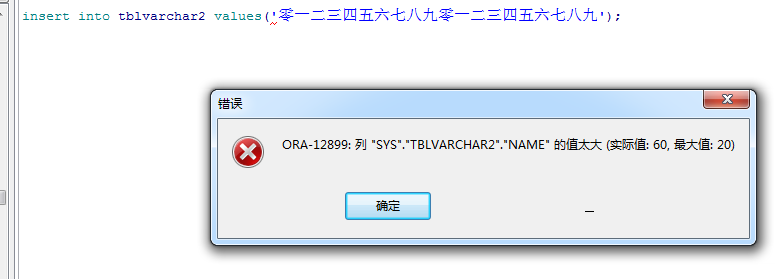

可见nvarchar2的长度确实为字符能插入的最大长度,与字符集本身无关。
查询结果:

分类:
Oracle & PL/SQL


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现