
Sentinel系列之SlotChain、NodeSelectorSlot、ClusterBuilderSlot分析
本文基于Sentinel 1.8.6版本分析
1. SlotChain
我们从入口com.alibaba.csp.sentinel.SphU#entry(java.lang.String) 开始分析。
一路走读下来,会进入到这个方法com.alibaba.csp.sentinel.CtSph#lookProcessChain,查找该资源对应的Slot Chain。
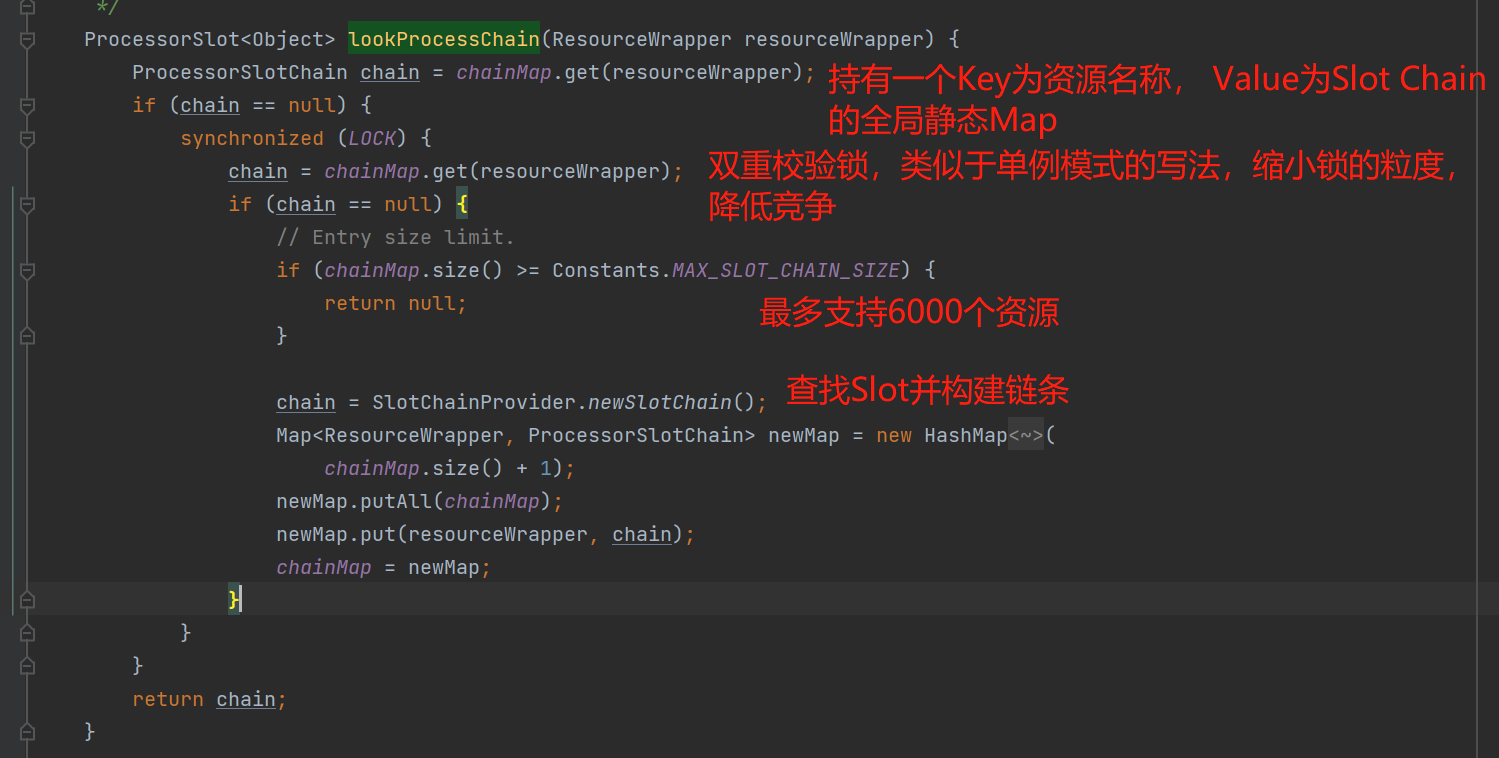
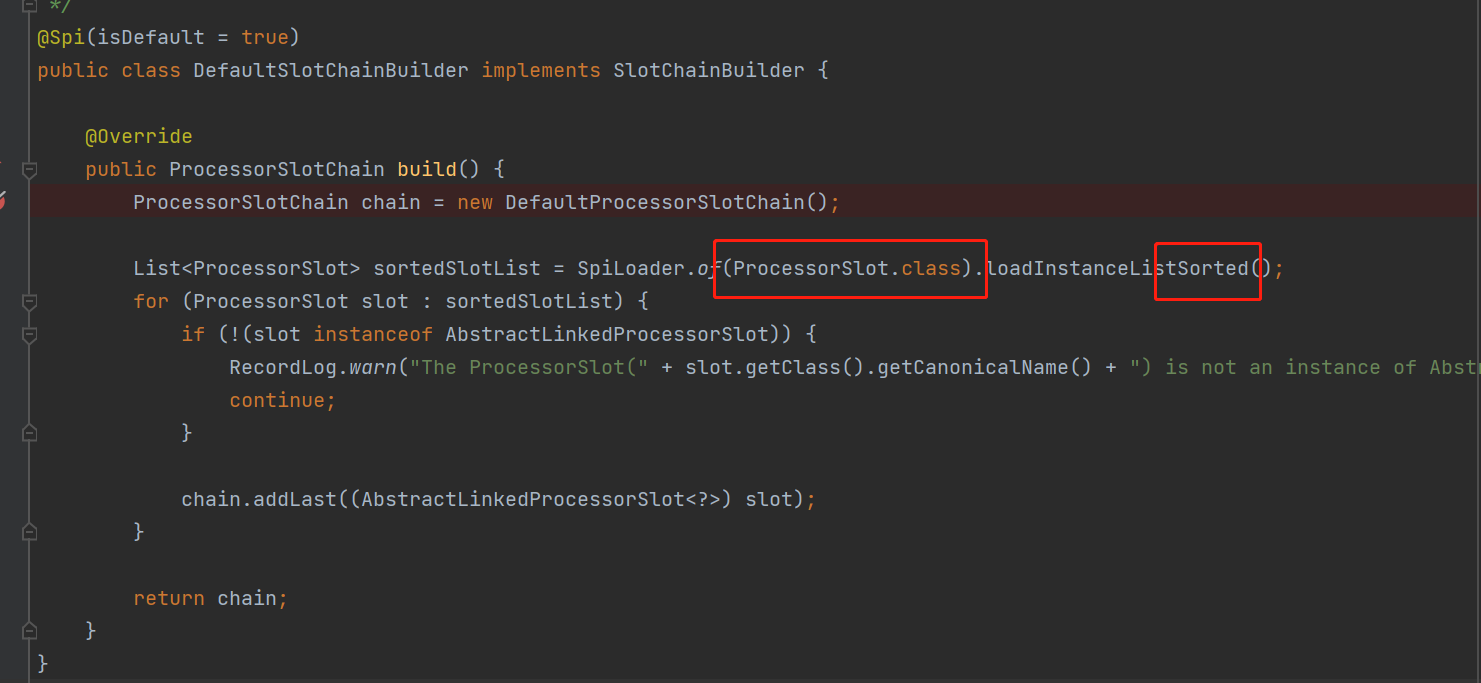
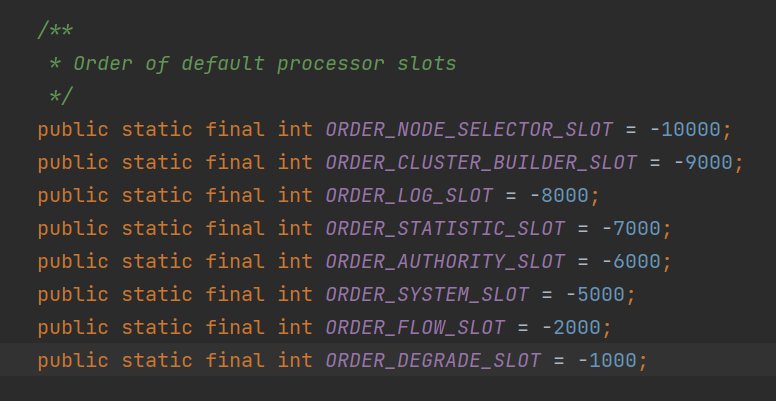
接下来看如何构建这个Slot Chain. Sentinel实现了自己的一套SPI机制,提供了缓存和排序等功能。在@Spi注解上有一个order字段,支持按order从小到大排序。
2. Slot
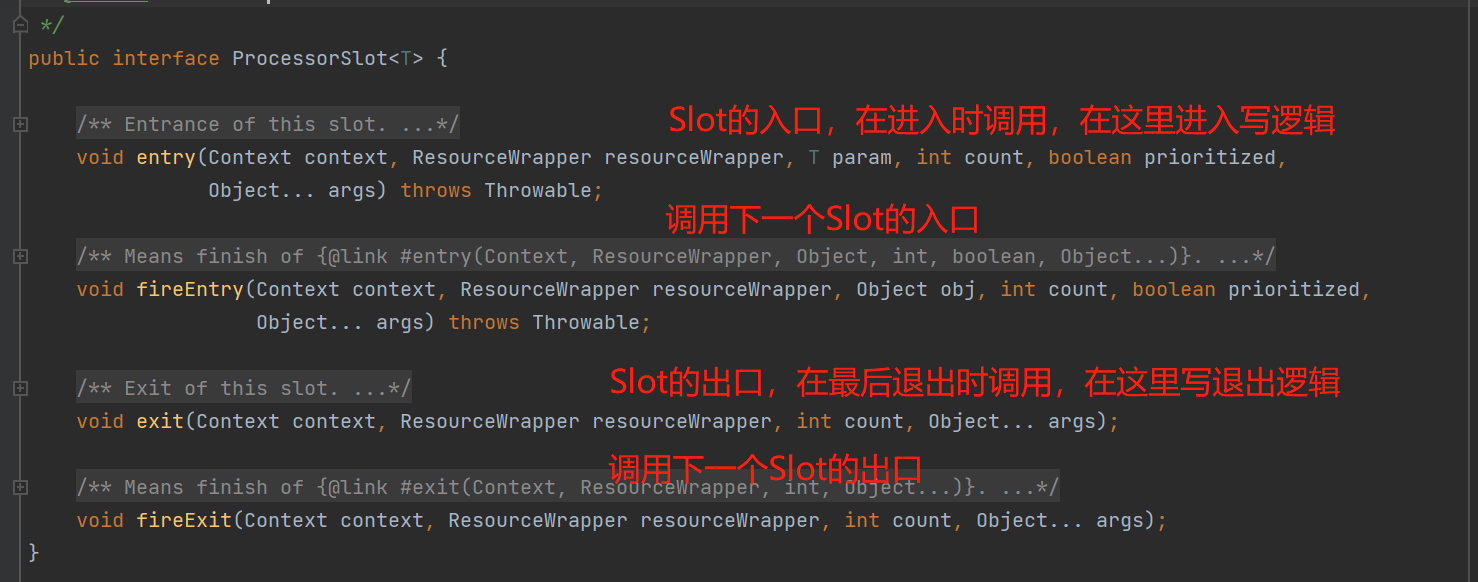
插槽的接口叫ProcessorSlot,它有4个方法,分别对应入口、出口时自己运行逻辑及调用下一个Slot的入口或出口。
Slot Chain也是插槽的一个实现,作为链条的入口 ,比较特殊的点在于它持有了其他的Slot。
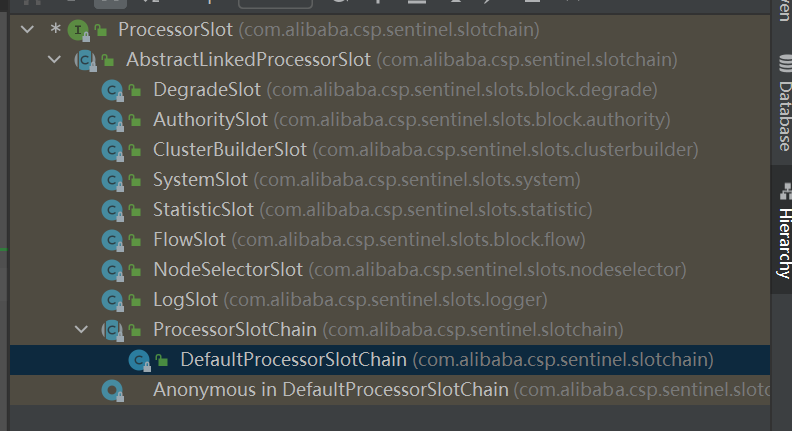
2.1. NodeSelectorSlot
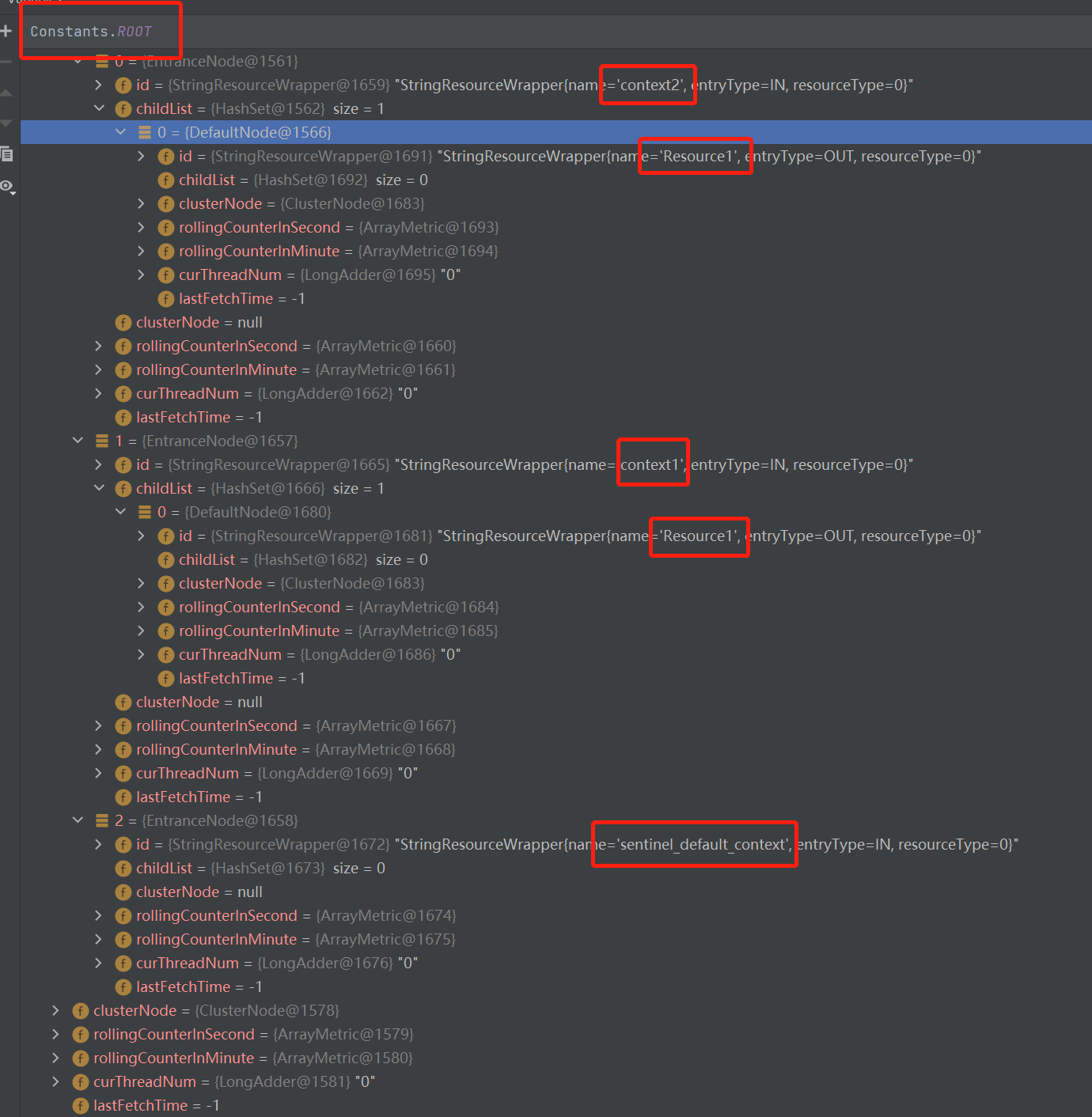
NodeSelectorSlot 负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;
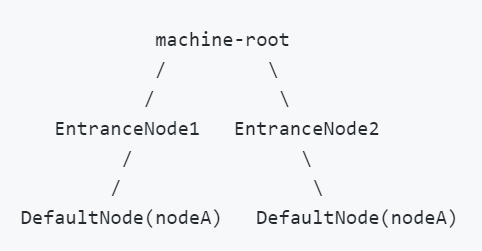
首先了解一下Node的类继承关系
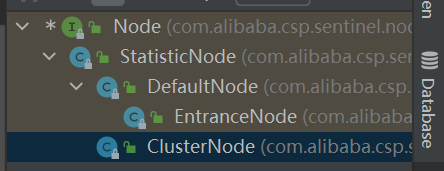
有三种不同的节点:
Root: 根节点,全局唯一,所有调用的入口,值固定为machine-root,承载在com.alibaba.csp.sentinel.Constants#ROOT字段。它的实现类是EntranceNode.
EntranceNode:DefaultNode的子类,入口节点,一个Context会有一个入口节点,用于统计当前Context的总体流量数据,统计维度为Context。可以调用com.alibaba.csp.sentinel.context.ContextUtil#enter(java.lang.String)设置,若无设置,默认值为sentinel_default_context。它的实现类也是EntranceNode.
DefaultNode:默认节点,用于统计一个resource在当前Context中的流量数据,DefaultNode持有指定的Context和指定的Resource的统计数据,意味着DefaultNode是以Context和Resource为维度的统计节点。它的实现类是DefaultNode.
通过这个调用链路,就可以实现基于调用链路限流。
public class ChainStrategyDemo {
private static final String RESOURCE_1 = "Resource1";
private static final Logger logger = LoggerFactory.getLogger(ChainStrategyDemo.class);
public static void initFlowRules(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule1 = new FlowRule();
// 绑定资源
rule1.setResource(RESOURCE_1);
rule1.setGrade(RuleConstant.FLOW_GRADE_QPS);
// 可以只对某个链路生效
rule1.setCount(2);
rule1.setStrategy(RuleConstant.STRATEGY_CHAIN);
rule1.setRefResource("context1");
rules.add(rule1);
FlowRuleManager.loadRules(rules);
}
public static void method(String contextName) {
// 定义资源
try(Entry entry = SphU.entry(RESOURCE_1)){
logger.info("Visit resource 1");
}catch (BlockException e) {
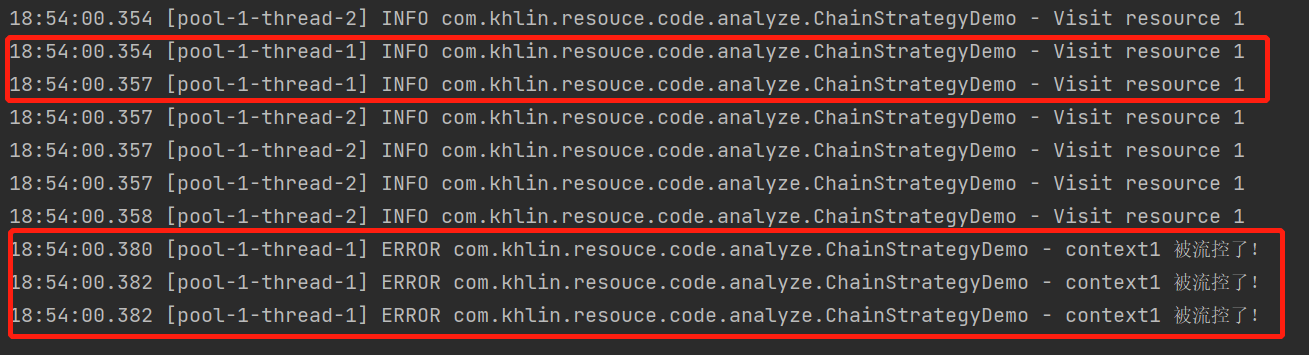
logger.error("{} 被流控了!", contextName);
}
}
public static void main(String[] args) throws InterruptedException {
initFlowRules();
ExecutorService executor = Executors.newFixedThreadPool(2);
executor.submit(new Task("context1"));
executor.submit(new Task("context2"));
Thread.sleep(10_000L);
executor.shutdown();
}
public static class Task implements Runnable{
private String contextName;
public Task(String contextName) {
this.contextName = contextName;
}
@Override
public void run() {
ContextUtil.enter(contextName);
for(int i = 0; i <= 4; i++){
method(contextName);
}
}
}
}
通过上面的分析,可以得出如下的调用链路。
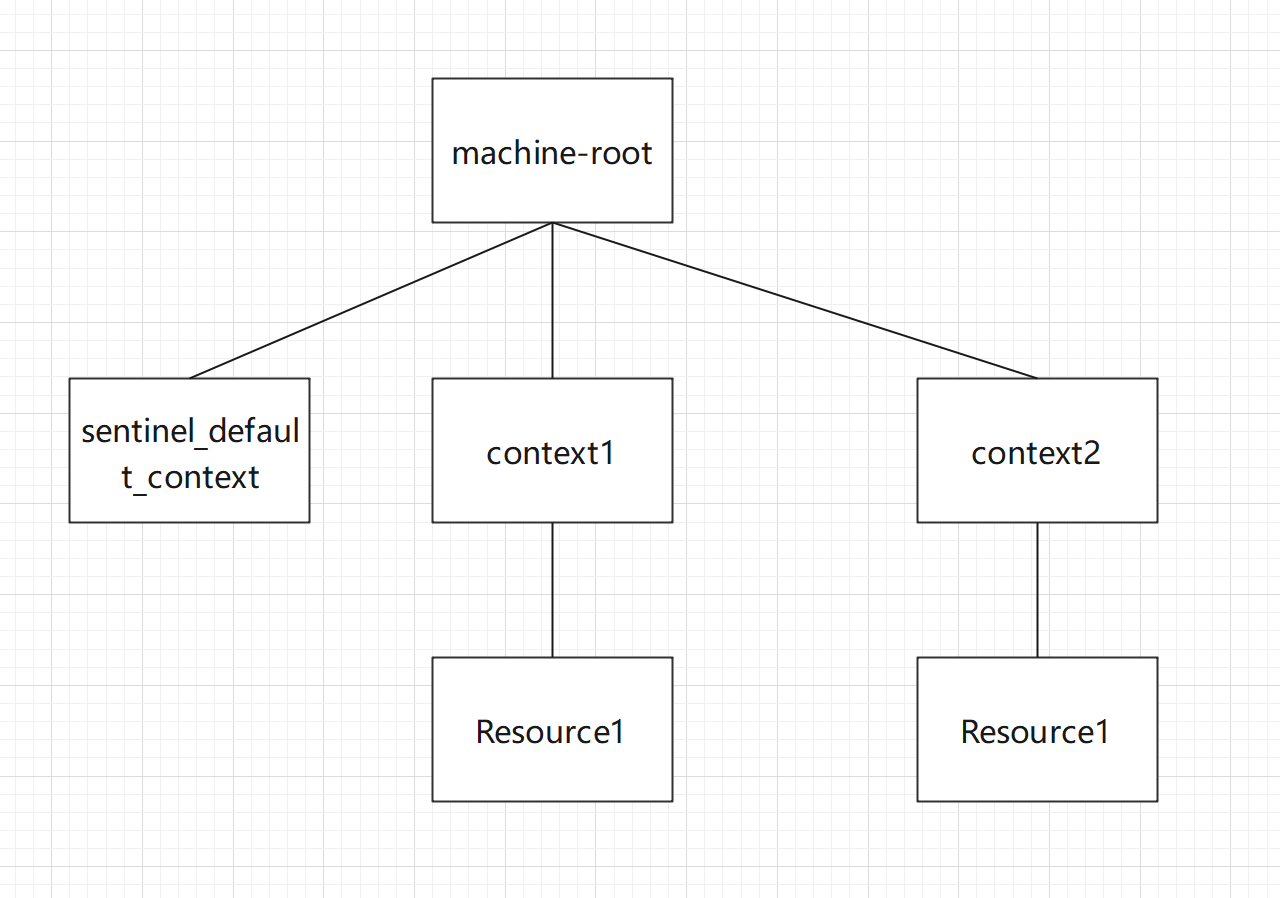
使用Debug方式,在调用完成后,查看内存中的调用链路
运行结果,只对context1限流
需要注意的是,这里的调用关系并不是代码的调用链路,而是关注调用入口和资源的关系。
再来看下面这个例子,method2嵌套了method1。
public static void main(String[] args) throws InterruptedException {
initFlowRules();
method1();
method2();
System.out.println("Finished!");
}
public static void method1() {
// 定义资源
try(Entry entry = SphU.entry(RESOURCE_1)){
System.out.println("Visit resource 1");
}catch (BlockException e) {
System.out.println("被流控了!");
}
}
public static void method2() {
// 定义资源
try(Entry entry = SphU.entry(RESOURCE_2)){
System.out.println("Visit resource 1");
method1();
}catch (BlockException e) {
System.out.println("被流控了!");
}
}
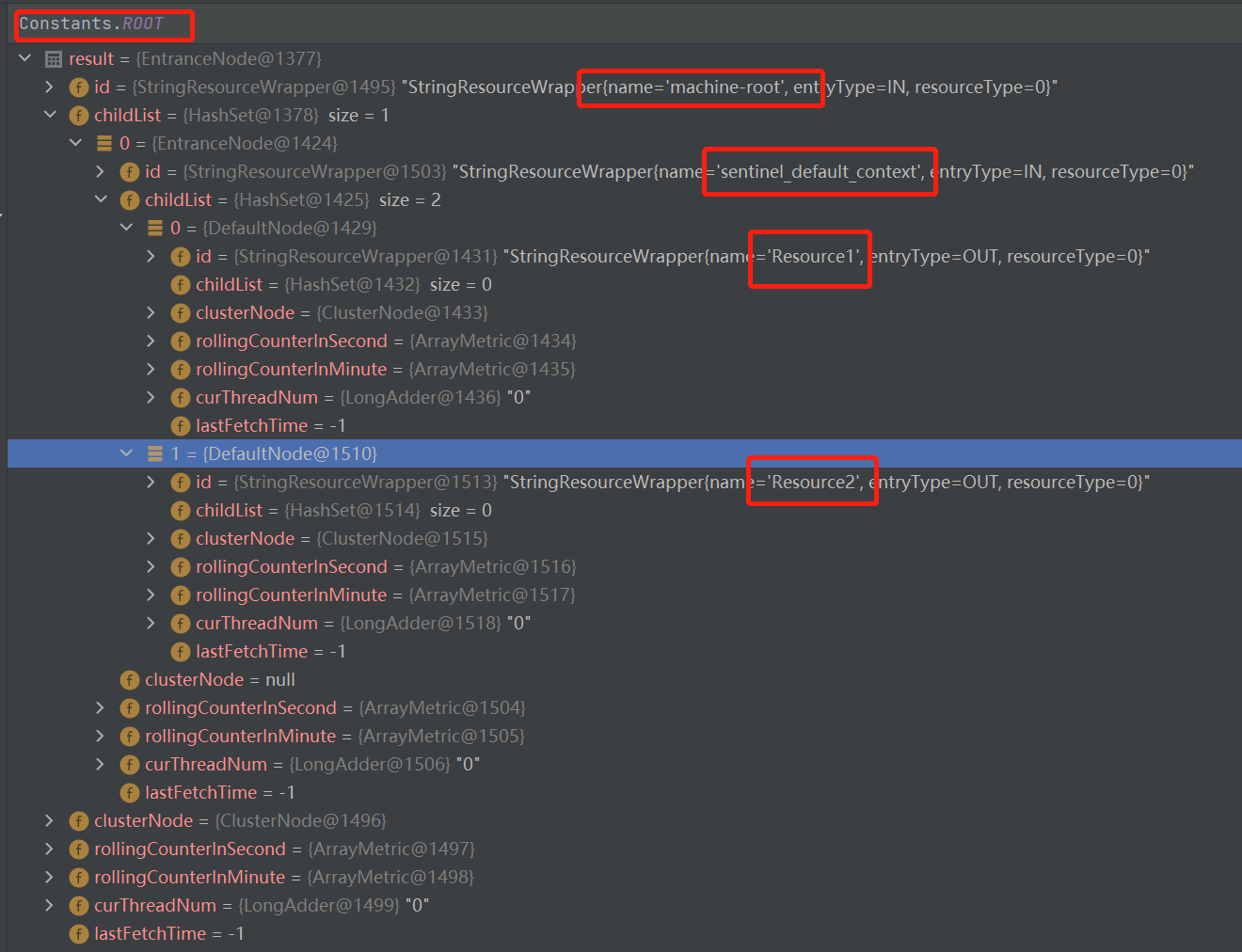
2.2 ClusterBuilderSlot
如果想要以资源的维度来限流,那么必须对调用链路的DefaultNode,以资源的维度做一次汇总,ClusterBuilderSlot正是这个作用。
此插槽用于构建资源的 ClusterNode 以及调用来源节点。ClusterNode 保持资源运行统计信息(响应时间、QPS、block 数目、线程数、异常数等)以及原始调用者统计信息列表。来源调用者的名字由 ContextUtil.enter(contextName,origin) 中的 origin 标记。
ClusterNode: 资源唯一标识的 ClusterNode 的 runtime 统计。它的实现类是ClusterNode.
Origin: 根据来自不同调用者的统计信息,在ClusterNode中有一个Map,专门按Origin调用来源统计不同的数据,默认是空字符串。在访问资源前,可以通过com.alibaba.csp.sentinel.context.ContextUtil#enter(java.lang.String, java.lang.String)指定调用来源。它的实现类是StatisticNode.
所以,完整的关系图如下,绿色表示这些节点存储了不同维度的统计数据
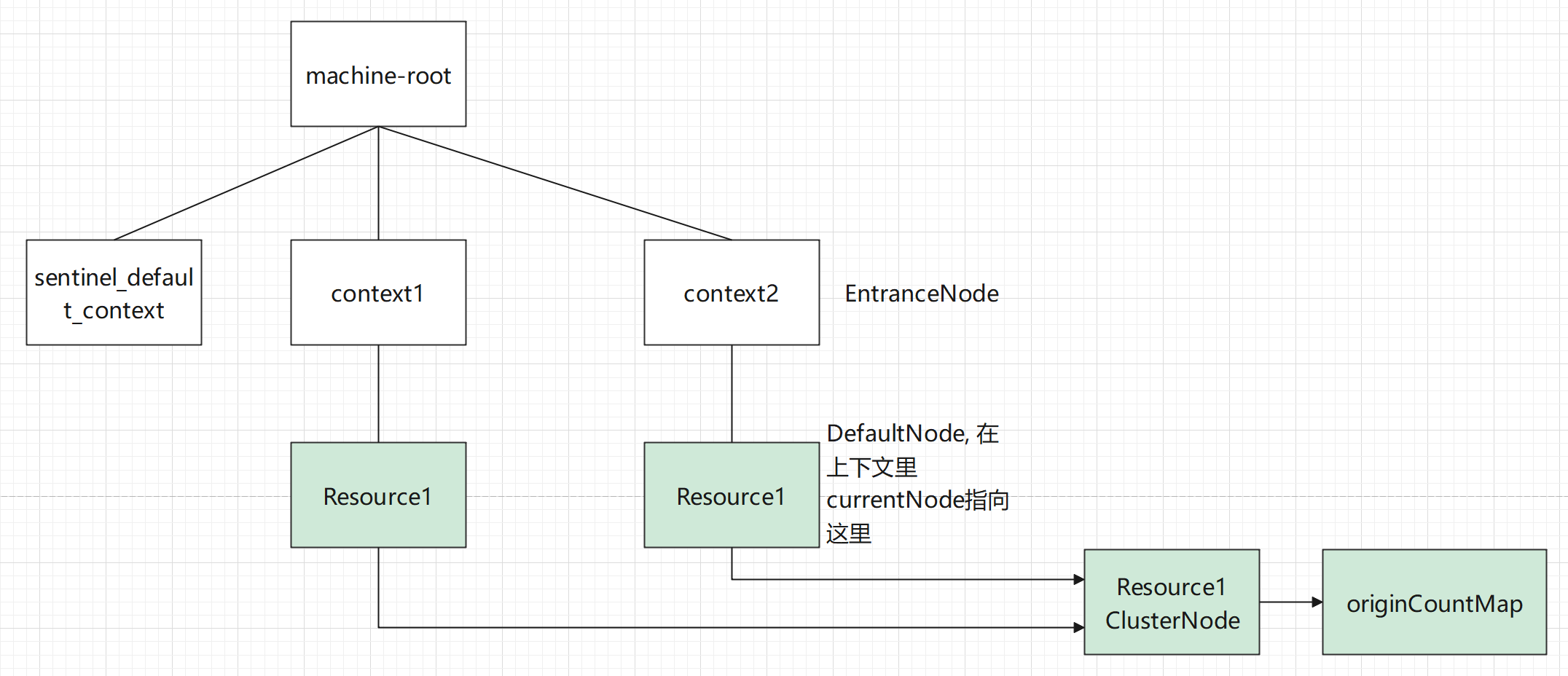
通过LimitApp,就可以实现基于调用来源的限流。
public static void initFlowRules() {
List<FlowRule> rules = new ArrayList<>();
FlowRule rule1 = new FlowRule();
// 绑定资源
rule1.setResource(RESOURCE_1);
rule1.setGrade(RuleConstant.FLOW_GRADE_QPS);
// 可以只对某个来源生效
rule1.setCount(2);
// 默认也是这个值
rule1.setStrategy(RuleConstant.STRATEGY_DIRECT);
rule1.setLimitApp(DEFAULT_LIMIT_APP);
rules.add(rule1);
FlowRuleManager.loadRules(rules);
}
public static void method(String origin) {
// 定义资源
try (Entry entry = SphU.entry(RESOURCE_1)) {
logger.info("Visit resource 1");
} catch (BlockException e) {
logger.error("{} 被流控了!", origin);
}
}
public static void main(String[] args) throws InterruptedException {
initFlowRules();
ExecutorService executor = Executors.newFixedThreadPool(2);
executor.submit(new Task(DEFAULT_LIMIT_APP));
executor.submit(new Task("AnotherLimitApp"));
Thread.sleep(10_000L);
executor.shutdown();
}
public static class Task implements Runnable {
private String origin;
public Task(String origin) {
this.origin = origin;
}
@Override
public void run() {
for (int i = 0; i <= 4; i++) {
ContextUtil.enter(DEFAULT_ENTRANCE, origin);
method(origin);
}
}
}
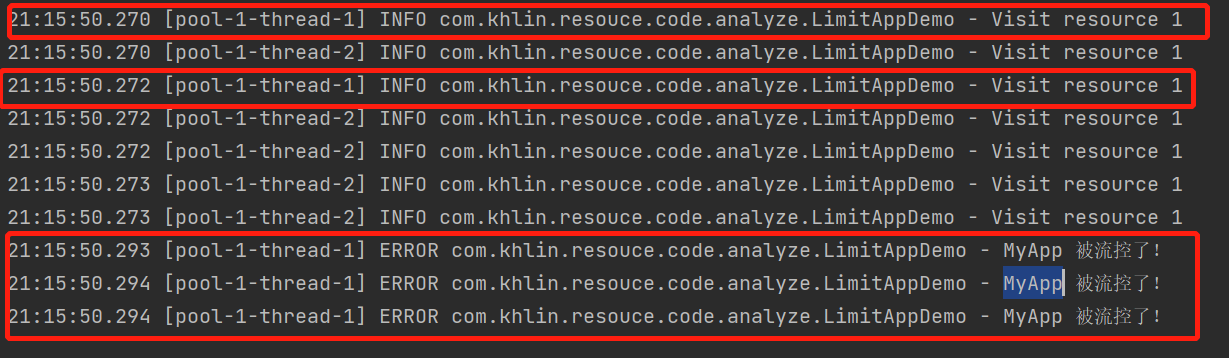
通过上面的介绍,我们知道了有不同的Node,并且流量控制有不同的策略Strategy,还有可以通过调用来源来限制,那么不同的情况下会使用什么节点进行限流判断呢?
在进行限流判断前,会调用这个方法选择合适的节点 com.alibaba.csp.sentinel.slots.block.flow.FlowRuleChecker#selectNodeByRequesterAndStrategy
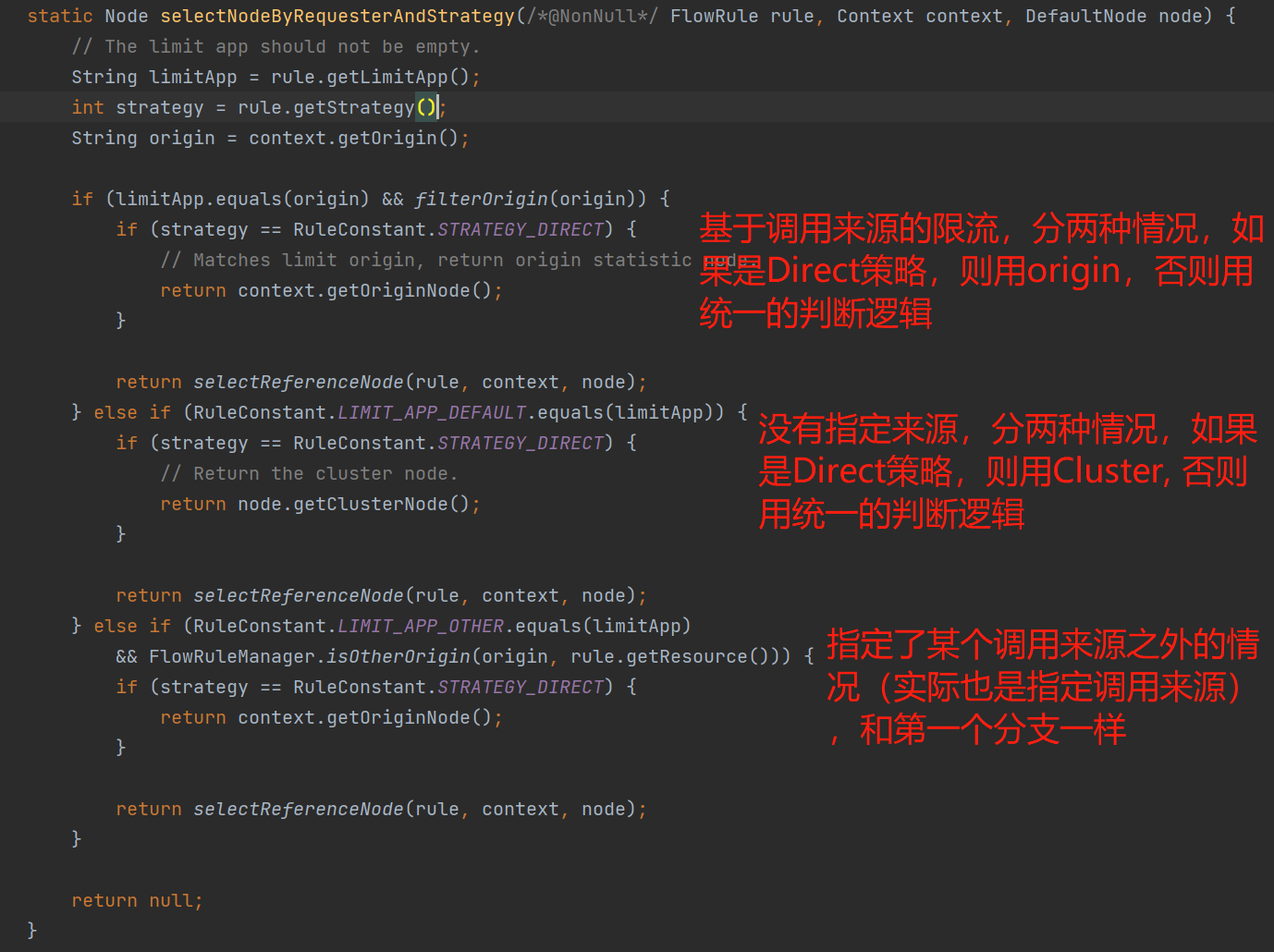
| 调用来源/策略 | Direct | Relate | Chain |
|---|---|---|---|
| 指定来源 | origin | cluster | current(当前节点就是链路第三层的DefaultNode) |
| 不指定来源 | cluster | cluster | current(当前节点就是链路第三层的DefaultNode) |
| 指定来源之外(Other,其实也是指定来源) | origin | cluster | current(当前节点就是链路第三层的DefaultNode) |
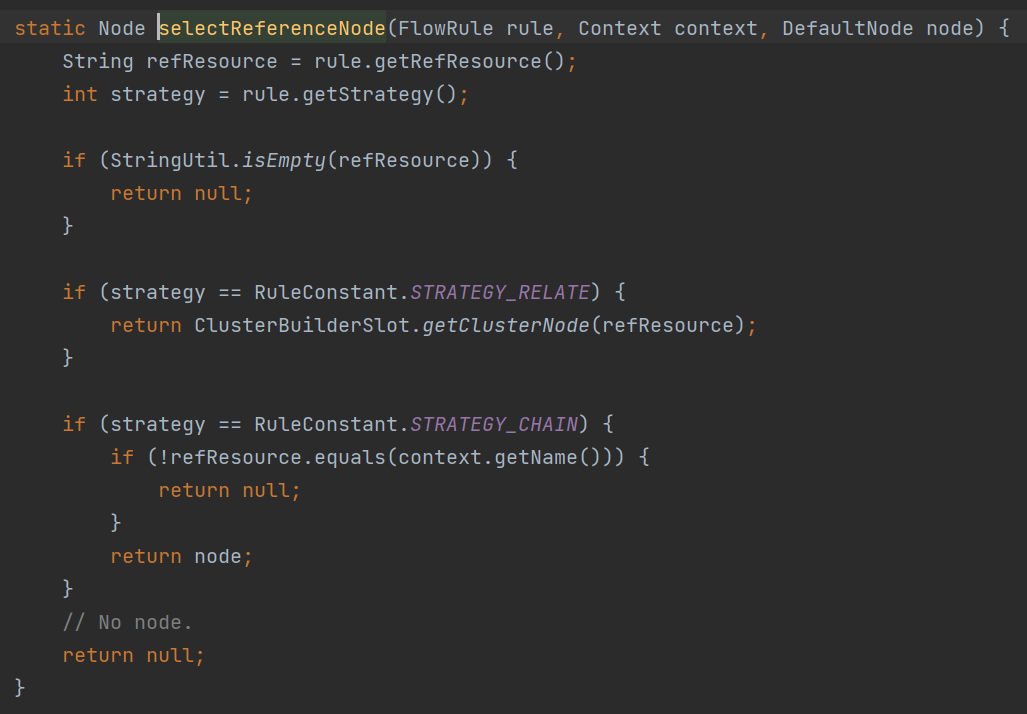
可以看到,如果选择了Chain基于链路限流,则肯定是使用当前节点,无法指定来源;如果选择了Relate基于关联关系,则肯定是使用cluster; 如果选择了Direct,就要看有没有指定来源,若指定了则使用origin,否则还是使用cluster.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现