
Spark垃圾邮件分类(scala+java)
|
Java程序 |
|
import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.mllib.classification.LogisticRegressionModel; import org.apache.spark.mllib.classification.LogisticRegressionWithSGD; import org.apache.spark.mllib.feature.HashingTF; import org.apache.spark.mllib.linalg.Vector; import org.apache.spark.mllib.regression.LabeledPoint; /** * Created by hui on 2017/11/29. */ public class MLlib { public static void main(String[] args) { SparkConf sparkConf = new SparkConf().setAppName("JavaBookExample").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(sparkConf); // Load 2 types of emails from text files: spam and ham (non-spam). // Each line has text from one email. JavaRDD<String> spam = sc.textFile("files/spam.txt"); JavaRDD<String> ham = sc.textFile("files/ham.txt"); // Create a HashingTF instance to map email text to vectors of 100 features. final HashingTF tf = new HashingTF(100); // Each email is split into words, and each word is mapped to one feature. // Create LabeledPoint datasets for positive (spam) and negative (ham) examples. JavaRDD<LabeledPoint> positiveExamples = spam.map(new Function<String, LabeledPoint>() { @Override public LabeledPoint call(String email) { return new LabeledPoint(1, tf.transform(Arrays.asList(email.split(" ")))); } }); JavaRDD<LabeledPoint> negativeExamples = ham.map(new Function<String, LabeledPoint>() { @Override public LabeledPoint call(String email) { return new LabeledPoint(0, tf.transform(Arrays.asList(email.split(" ")))); } }); JavaRDD<LabeledPoint> trainingData = positiveExamples.union(negativeExamples); trainingData.cache(); // Cache data since Logistic Regression is an iterative algorithm. // Create a Logistic Regression learner which uses the LBFGS optimizer. LogisticRegressionWithSGD lrLearner = new LogisticRegressionWithSGD(); // Run the actual learning algorithm on the training data. LogisticRegressionModel model = lrLearner.run(trainingData.rdd()); // Test on a positive example (spam) and a negative one (ham). // First apply the same HashingTF feature transformation used on the training data. Vector posTestExample = tf.transform(Arrays.asList("O M G GET cheap stuff by sending money to ...".split(" "))); Vector negTestExample = tf.transform(Arrays.asList("Hi Dad, I started studying Spark the other ...".split(" "))); // Now use the learned model to predict spam/ham for new emails. System.out.println("Prediction for positive test example: " + model.predict(posTestExample)); System.out.println("Prediction for negative test example: " + model.predict(negTestExample)); sc.stop(); } } |
|
Scala程序 |
|
import org.apache.spark.mllib.classification.LogisticRegressionWithSGD import org.apache.spark.mllib.feature.HashingTF import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.{SparkConf, SparkContext} /** * Created by hui on 2017/11/23. */ object email { def main(args:Array[String]): Unit = { val conf = new SparkConf().setAppName(s"Book example: Scala").setMaster("local") val sc = new SparkContext(conf) // Load 2 types of emails from text files: spam and ham (non-spam). // Each line has text from one email. val spam = sc.textFile("files/spam.txt") val ham = sc.textFile("files/ham.txt") // Create a HashingTF instance to map email text to vectors of 100 features. val tf = new HashingTF(numFeatures = 100) // Each email is split into words, and each word is mapped to one feature. val spamFeatures = spam.map(email => tf.transform(email.split(" "))) val hamFeatures = ham.map(email => tf.transform(email.split(" "))) // Create LabeledPoint datasets for positive (spam) and negative (ham) examples. val positiveExamples = spamFeatures.map(features => LabeledPoint(1, features)) val negativeExamples = hamFeatures.map(features => LabeledPoint(0, features)) val trainingData = positiveExamples ++ negativeExamples trainingData.cache() // Cache data since Logistic Regression is an iterative algorithm. // Create a Logistic Regression learner which uses the LBFGS optimizer. val lrLearner = new LogisticRegressionWithSGD() // Run the actual learning algorithm on the training data. val model = lrLearner.run(trainingData) // Test on a positive example (spam) and a negative one (ham). // First apply the same HashingTF feature transformation used on the training data. val posTestExample = tf.transform("O M G GET cheap stuff by sending money to ...".split(" ")) val negTestExample = tf.transform("Hi Dad, I started studying Spark the other ...".split(" ")) // Now use the learned model to predict spam/ham for new emails. println(s"Prediction for positive test example: ${model.predict(posTestExample)}") println(s"Prediction for negative test example: ${model.predict(negTestExample)}") sc.stop() } } |
|
运行结果 |
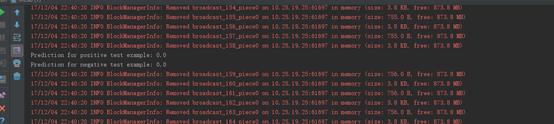 |
